Where Will They Go? Modelling Multimodal Pedestrian Manoeuvres from Ego-centric Videos
Pith reviewed 2026-06-26 21:49 UTC · model grok-4.3
The pith
Separating pedestrian paths into crossing and non-crossing modes avoids implausible mixed predictions from ego-centric video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that future pedestrian trajectories form two semantically distinct distributions—one conditioned on crossing the road and one on not crossing—and that modeling these distributions separately inside a CVAE, while conditioning on behavior-aware interaction features, produces samples that remain within plausible motion patterns rather than averaging across modes.
What carries the argument
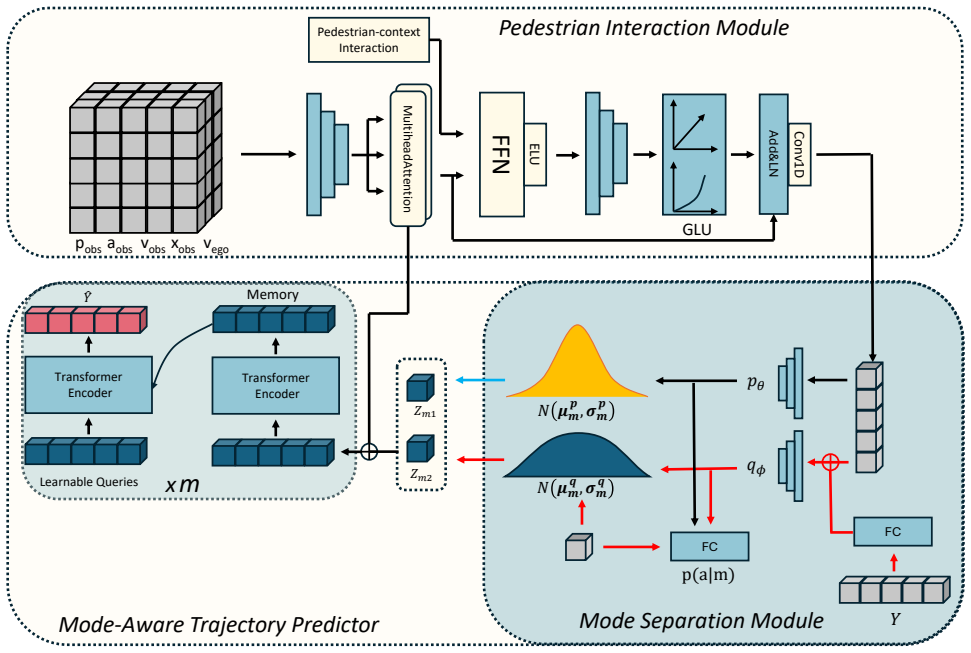
The Mode-aware Trajectory Predictor (MTP), a CVAE that maintains separate latent distributions for crossing and non-crossing modes together with a query-based decoder that enforces mode consistency at generation time.
If this is right
- Trajectory samples no longer fall between distinct motion patterns and therefore remain closer to observed ground-truth paths.
- The MTP module can be inserted unchanged into existing predictors such as BiTrap-NP and SGNet-ED and raises their reported accuracy.
- The new data-driven validation protocol that matches predictions to spatio-temporally consistent ground-truth trajectories records lower frame-wise displacement errors than prior matching schemes.
- Explicit use of gaze, head, and hand gestures inside the interaction module supplies additional signal for distinguishing the two modes.
Where Pith is reading between the lines
- The same mode-separation idea could be tested on other discrete intent labels such as turning left versus continuing straight.
- Because the module is model-agnostic, it offers a lightweight way to add multimodal structure to any trajectory network that currently uses a single latent variable.
- Lower frame-wise errors under the new validation protocol suggest that downstream planners receive trajectory sets whose uncertainty better reflects real behavioral branches.
- The approach assumes ego-centric video; its value on fixed surveillance cameras or bird's-eye views remains untested in the paper.
Load-bearing premise
That the binary distinction between crossing and non-crossing supplies enough structure to capture the main modes of pedestrian motion without leaving important behaviors unmodeled.
What would settle it
A controlled experiment in which a single shared latent distribution, trained and decoded identically otherwise, matches or exceeds the separate-mode version on both average displacement error and the fraction of trajectories that match ground-truth crossing labels on the same PIE and JAAD test splits.
Figures

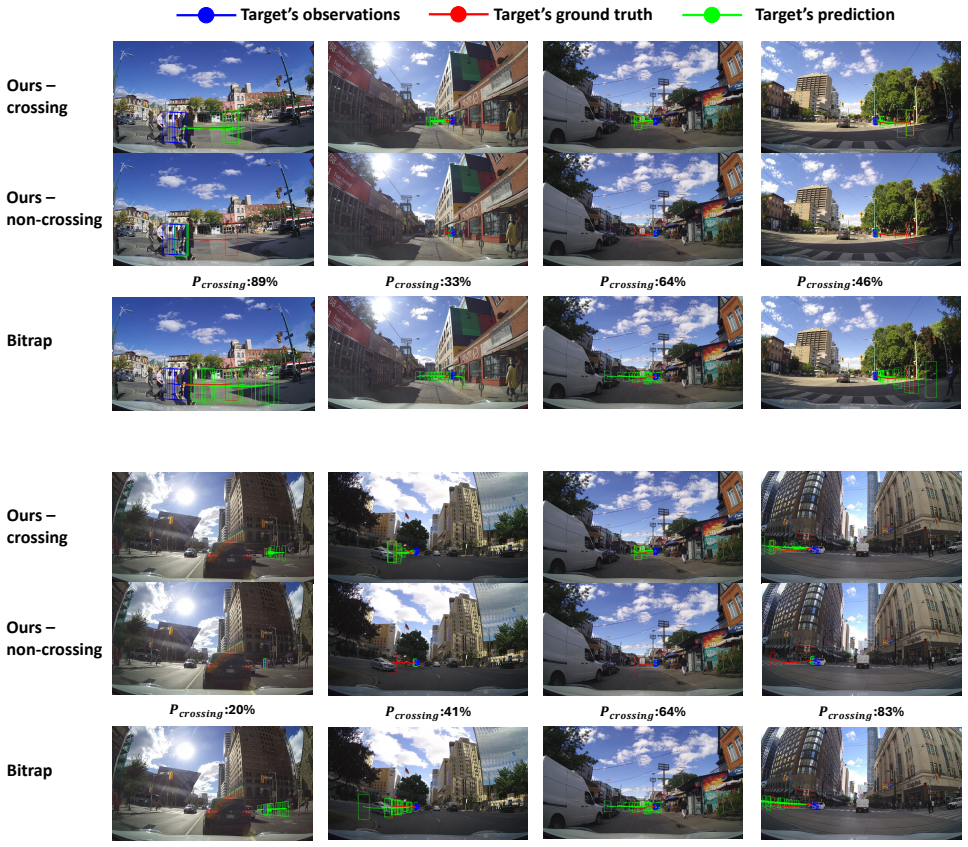
read the original abstract
Pedestrian trajectory prediction from an ego-centric camera is challenging since it depends on complex interactions with vehicles and scene context, as well as the intention of the pedestrian. By modelling correlation and intent from the historical and future trajectories of the pedestrian, it will usually result in a multimodal (i.e. multiple modes) distribution. Existing stochastic predictors often sample multiple futures from a single unimodal distribution, which can yield sub-optimal 'mixed-mode' trajectories that lie between distinct motion patterns and become implausible in real scenes. In this paper, we propose MMPM, a mode-aware framework that separately models future trajectory distributions into semantically meaningful modes based on the pedestrian's crossing behavior. MMPM consists of two modules: behavior-aware Pedestrian Interaction Module (PIM) that jointly captures pedestrian-vehicle and pedestrian-environment interactions by introducing gaze, head and hand gesture, and a CVAE-based Mode-aware Trajectory Predictor (MTP) module to model the future trajectory distributions on two modes, crossing and non-crossing the road, separately. A query-based decoder further enforces mode consistency during decoding. Experiments on PIE and JAAD datasets show that our method surpasses state-of-the-art baselines. Our proposed MTP is model-agnostic, which can be integrated into existing frameworks such as BiTrap-NP and SGNet-ED to further improve future trajectory prediction performance. We additionally introduce a data-driven validation protocol that matches predictions to spatio-temporally consistent ground-truth trajectories, demonstrating improved frame-wise displacement errors over previous work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MMPM, a mode-aware framework for multimodal pedestrian trajectory prediction from ego-centric videos. It introduces a behavior-aware Pedestrian Interaction Module (PIM) that jointly models pedestrian-vehicle and pedestrian-environment interactions using gaze, head, and hand gesture cues, and a CVAE-based Mode-aware Trajectory Predictor (MTP) that separately models future trajectory distributions for crossing and non-crossing modes, with a query-based decoder to enforce mode consistency. Experiments on the PIE and JAAD datasets report that the method surpasses state-of-the-art baselines; the MTP module is presented as model-agnostic and integrable into frameworks such as BiTrap-NP and SGNet-ED; a new data-driven validation protocol is introduced that matches predictions to spatio-temporally consistent ground-truth trajectories and reports improved frame-wise displacement errors.
Significance. If the reported gains hold under rigorous evaluation, the explicit separation into semantically meaningful crossing/non-crossing modes addresses a known limitation of unimodal stochastic predictors that produce implausible mixed-mode samples. The model-agnostic design of MTP and the proposed validation protocol are concrete strengths that could be adopted more broadly. The work builds on public datasets and standard CVAE techniques while adding targeted interaction cues, which supports incremental progress in ego-centric pedestrian prediction.
major comments (2)
- [§5] §5 (Experiments), Table 2: the claim that MMPM surpasses SOTA baselines on PIE and JAAD is presented without error bars, multiple random seeds, or statistical significance tests; this is load-bearing for the central performance claim and prevents assessment of whether the reported improvements are reliable.
- [§4.2] §4.2 (MTP module): the construction assumes that future crossing behavior provides a sufficient and semantically meaningful partitioning of trajectory modes, yet the inference procedure for selecting or weighting modes from past observations alone is not derived in detail; this directly affects whether the separate CVAE distributions can be deployed without oracle future labels.
minor comments (3)
- [§1] The abstract and §1 refer to 'multimodal (i.e. multiple modes) distribution' but the notation for the number of modes and the exact conditioning variables in the CVAE is introduced only later; a consolidated notation table would improve clarity.
- [Figure 3] Figure 3 (architecture diagram) uses abbreviations (PIM, MTP, CVAE) without an accompanying legend in the caption; this reduces readability for readers unfamiliar with the acronyms.
- [§5.3] The new validation protocol is described in §5.3 but lacks a formal algorithmic listing or pseudocode; adding one would make the spatio-temporal matching procedure reproducible.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments. We address each major comment below and will incorporate clarifications and additional results in the revised manuscript.
read point-by-point responses
-
Referee: §5 (Experiments), Table 2: the claim that MMPM surpasses SOTA baselines on PIE and JAAD is presented without error bars, multiple random seeds, or statistical significance tests; this is load-bearing for the central performance claim and prevents assessment of whether the reported improvements are reliable.
Authors: We agree that reporting variability is important for assessing reliability. In the revised manuscript we will rerun the experiments with multiple random seeds, report mean and standard deviation in Table 2, and include paired statistical significance tests (e.g., Wilcoxon signed-rank) against the strongest baselines to substantiate the performance gains. revision: yes
-
Referee: §4.2 (MTP module): the construction assumes that future crossing behavior provides a sufficient and semantically meaningful partitioning of trajectory modes, yet the inference procedure for selecting or weighting modes from past observations alone is not derived in detail; this directly affects whether the separate CVAE distributions can be deployed without oracle future labels.
Authors: The mode (crossing vs. non-crossing) is treated as a latent variable that is predicted at inference time from past observations. The PIM module, which processes gaze, head pose and hand gestures, produces an intent embedding that is used to select or weight the appropriate CVAE branch; the query-based decoder then enforces consistency with the chosen mode. We will expand §4.2 with the precise inference equations and a diagram showing how the mode is obtained without future labels. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces MMPM with PIM (capturing interactions via gaze/gesture cues) and MTP (CVAE-based separate modeling of crossing/non-crossing modes) plus a query decoder, all as architectural choices trained end-to-end. Performance claims rest on empirical evaluation against external baselines on public PIE/JAAD datasets, with MTP shown integrable into unrelated prior frameworks (BiTrap-NP, SGNet-ED). No equation or module reduces by construction to its own fitted inputs, no self-citation chain bears the central claim, and no prediction is statistically forced from a subset of the same data; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bifold and semantic reasoning for pedestrian behavior prediction,
A. Rasouli, M. Rohani, and J. Luo, “Bifold and semantic reasoning for pedestrian behavior prediction,”2021 IEEE/CVF International Confer- ence on Computer Vision (ICCV), pp. 15 580–15 590, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:236956521
2021
-
[2]
Joint intention and trajectory prediction based on transformer,
Z. Sui, Y . Zhou, X. Zhao, A. Chen, and Y . Ni, “Joint intention and trajectory prediction based on transformer,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 7082–7088
2021
-
[3]
Social aware multi- modal pedestrian crossing behavior prediction,
X. Zhai, Z. Hu, D. Yang, L. Zhou, and J. Liu, “Social aware multi- modal pedestrian crossing behavior prediction,” inProceedings of the Asian Conference on Computer Vision, 2022, pp. 4428–4443
2022
-
[4]
Bitrap: Bi-directional pedestrian trajectory prediction with multi-modal goal estimation,
Y . Yao, E. M. Atkins, M. Johnson-Roberson, R. Vasudevan, and X. Du, “Bitrap: Bi-directional pedestrian trajectory prediction with multi-modal goal estimation,”IEEE Robotics and Automation Letters, vol. 6, pp. 1463–1470, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:220845847
2020
-
[5]
Stepwise goal-driven networks for trajectory prediction,
C. Wang, Y . Wang, M. Xu, and D. J. Crandall, “Stepwise goal-driven networks for trajectory prediction,”IEEE Robotics and Automation Letters, vol. PP, pp. 1–1, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:232380341
2021
-
[6]
Hierarchical transformer-based red-light running prediction model for two-wheelers with multitask learning,
Y . Lian, K. Zhang, M. Li, and J. Lin, “Hierarchical transformer-based red-light running prediction model for two-wheelers with multitask learning,”IEEE Transactions on Intelligent Vehicles, pp. 1–15, 2024
2024
-
[7]
Crossmodal transformer based generative framework for pedestrian trajectory prediction,
Z. Su, G. Huang, S. Zhang, and W. Hua, “Crossmodal transformer based generative framework for pedestrian trajectory prediction,”2022 International Conference on Robotics and Automation (ICRA), pp. 2337–2343, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:250507293
2022
-
[8]
Agentformer: Agent- aware transformers for socio-temporal multi-agent forecasting,
Y . Yuan, X. Weng, Y . Ou, and K. Kitani, “Agentformer: Agent- aware transformers for socio-temporal multi-agent forecasting,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9793–9803, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:232352504
2021
-
[9]
Social-transmotion: Promptable human trajectory prediction,
S. Saadatnejad, Y . Gao, K. Messaoud, and A. Alahi, “Social-transmotion: Promptable human trajectory prediction,” ArXiv, vol. abs/2312.16168, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:266551223
-
[10]
Tra- jectron++: Dynamically-feasible trajectory forecasting with heteroge- neous data,
T. Salzmann, B. Ivanovic, P. Chakravarty, and M. Pavone, “Tra- jectron++: Dynamically-feasible trajectory forecasting with heteroge- neous data,” inEuropean Conference on Computer Vision, 2020. [On- line]. Available: https://api.semanticscholar.org/CorpusID:214802528
2020
-
[11]
Modeling multimodal dynamic spatiotemporal graphs,
B. Ivanovic and M. Pavone, “Modeling multimodal dynamic spatiotemporal graphs,”ArXiv, vol. abs/1810.05993, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:53115162
-
[12]
Pedestrian and ego- vehicle trajectory prediction from monocular camera,
L. Neumann and A. Vedaldi, “Pedestrian and ego- vehicle trajectory prediction from monocular camera,”2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10 199–10 207, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:235719781
2021
-
[13]
Pedformer: Pedestrian behavior prediction via cross-modal attention modulation and gated multitask learning,
A. Rasouli and I. Kotseruba, “Pedformer: Pedestrian behavior prediction via cross-modal attention modulation and gated multitask learning,”2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9844–9851, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:252907322
2023
-
[14]
Goal-driven self-attentive recurrent networks for trajectory prediction,
L. F. Chiara, P. Coscia, S. Das, S. Calderara, R. Cucchiara, and L. Ballan, “Goal-driven self-attentive recurrent networks for trajectory prediction,”2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 2517–2526, 2022. [On- line]. Available: https://api.semanticscholar.org/CorpusID:248377731
2022
-
[15]
Hierarchical latent structure for multi-modal vehicle trajectory forecasting,
D. Choi and K. Min, “Hierarchical latent structure for multi-modal vehicle trajectory forecasting,” inEuropean Conference on Computer Vision, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:250425801
2022
-
[16]
C2f-tp: A coarse-to-fine denoising framework for uncertainty-aware trajectory prediction,
Z. Wang, H. Miao, S. Wang, R. Wang, J. Wang, and J. Zhang, “C2f-tp: A coarse-to-fine denoising framework for uncertainty-aware trajectory prediction,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 12, 2025, pp. 12 810–12 817
2025
-
[17]
Stochastic trajectory prediction via motion indeterminacy diffusion,
T. Gu, G. Chen, J. Li, C. Lin, Y . Rao, J. Zhou, and J. Lu, “Stochastic trajectory prediction via motion indeterminacy diffusion,” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 17 092–17 101, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:247748591
2022
-
[18]
Leapfrog diffusion model for stochastic trajectory prediction,
W. Mao, C. Xu, Q. Zhu, S. Chen, and Y . Wang, “Leapfrog diffusion model for stochastic trajectory prediction,” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5517–5526, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257631504
2023
-
[19]
Temporal attention with gated residual network for stepwise multimodal trajectory prediction,
C.-H. Chiu, Y .-C. Lin, and Y .-J. Chen, “Temporal attention with gated residual network for stepwise multimodal trajectory prediction,”IEEE Transactions on Instrumentation and Measurement, vol. 74, pp. 1–9, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:276948460
2025
-
[20]
A novel benchmarking paradigm and a scale- and motion-aware model for egocentric pedestrian trajectory prediction,
A. Rasouli, “A novel benchmarking paradigm and a scale- and motion-aware model for egocentric pedestrian trajectory prediction,”2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 5630–5636, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:264145930
2024
-
[21]
Ms-tip: Imputation aware pedestrian trajectory prediction,
P. S. Chib, A. Nath, P. Kabra, I. Gupta, and P. Singh, “Ms-tip: Imputation aware pedestrian trajectory prediction,” inInternational Conference on Machine Learning, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:272330450
2024
-
[22]
Destine: Dynamic goal queries with temporal transductive alignment for trajectory prediction,
R. Karim, S. M. A. Shabestary, and A. Rasouli, “Destine: Dynamic goal queries with temporal transductive alignment for trajectory prediction,”2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 2230–2237, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:263834714
2024
-
[23]
Groupnet: Multiscale hypergraph neural networks for trajectory prediction with relational reasoning,
C. Xu, M. Li, Z. Ni, Y . Zhang, and S. Chen, “Groupnet: Multiscale hypergraph neural networks for trajectory prediction with relational reasoning,”2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6488–6497, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:248239810
2022
-
[24]
Socialcircle: Learning the angle-based social interaction representation for pedestrian trajectory prediction,
C. Wong, B. Xia, and X. You, “Socialcircle: Learning the angle-based social interaction representation for pedestrian trajectory prediction,” 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19 005–19 015, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:263829662
2024
-
[25]
Interaction- aware decision-making for automated vehicles using social value orientation,
L. Crosato, H. P. H. Shum, E. S. L. Ho, and C. Wei, “Interaction- aware decision-making for automated vehicles using social value orientation,”IEEE Transactions on Intelligent Vehicles, vol. 8, no. 2, pp. 1339–1349, 2023
2023
-
[26]
Human-centric autonomous driving in an av-pedestrian interactive environment using svo,
L. Crosato, C. Wei, E. S. L. Ho, and H. P. H. Shum, “Human-centric autonomous driving in an av-pedestrian interactive environment using svo,” in2021 IEEE 2nd International Conference on Human-Machine Systems (ICHMS), 2021, pp. 1–6
2021
-
[27]
Pedestrian graph +: A fast pedestrian crossing prediction model based on graph convolutional networks,
P. R. G. Cadena, Y . Qian, C. Wang, and M. Yang, “Pedestrian graph +: A fast pedestrian crossing prediction model based on graph convolutional networks,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, pp. 21 050–21 061, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:248789262
2022
-
[28]
Hierarchical transformer-based red-light running prediction model for two-wheelers with multitask learning,
Y . Lian, K. Zhang, M. Li, and J. Lin, “Hierarchical transformer-based red-light running prediction model for two-wheelers with multitask learning,”IEEE Transactions on Intelligent Vehicles, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:270716362
2024
-
[29]
Future person localization in first-person videos,
T. Yagi, K. Mangalam, R. Yonetani, and Y . Sato, “Future person localization in first-person videos,”2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7593–7602, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:4406882
2018
-
[30]
Br- gan: A pedestrian trajectory prediction model combined with behavior recognition,
S. M. Pang, J. X. Cao, M. Y . Jian, J. Lai, and Z. Y . Yan, “Br- gan: A pedestrian trajectory prediction model combined with behavior recognition,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 12, pp. 24 609–24 620, 2022
2022
-
[31]
Demo: Decoupling motion forecasting into directional intentions and dynamic states,
B. Zhang, N. Song, and L. Zhang, “Demo: Decoupling motion forecasting into directional intentions and dynamic states,”ArXiv, vol. abs/2410.05982, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:273228276
-
[32]
Perception of human interaction based on motion trajectories: From aerial videos to decontextualized animations,
T. Shu, Y . Peng, L. Fan, H. Lu, and S.-C. Zhu, “Perception of human interaction based on motion trajectories: From aerial videos to decontextualized animations,”Topics in cognitive science, vol. 10 1, pp. 225–241, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:26105917
2018
-
[33]
Temporal fusion transformers for interpretable multi-horizon time series forecasting,
B. Lim, S. ¨O. Arik, N. Loeff, and T. Pfister, “Temporal fusion transformers for interpretable multi-horizon time series forecasting,”ArXiv, vol. abs/1912.09363, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:209414891
-
[34]
Fast and accurate deep network learning by exponential linear units (elus),
D.-A. Clevert, T. Unterthiner, and S. Hochreiter, “Fast and accurate deep network learning by exponential linear units (elus),”arXiv: Learning, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:5273326
2015
-
[35]
GLU Variants Improve Transformer
N. Shazeer, “Glu variants improve transformer,” ArXiv, vol. abs/2002.05202, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:211096588
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[36]
End- to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,”ArXiv, vol. abs/2005.12872, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:218889832
-
[37]
Accurate and diverse sampling of sequences based on a
A. Bhattacharyya, B. Schiele, and M. Fritz, “Accurate and diverse sampling of sequences based on a ”best of many” sample objective,”2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8485–8493, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:49319880
2018
-
[38]
Pie: A large-scale dataset and models for pedestrian intention estimation and trajectory prediction,
A. Rasouli, I. Kotseruba, T. Kunic, and J. K. Tsotsos, “Pie: A large-scale dataset and models for pedestrian intention estimation and trajectory prediction,”2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 6261–6270, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:204959605
2019
-
[39]
Joint attention in autonomous driving (jaad),
I. Kotseruba, A. Rasouli, and J. K. Tsotsos, “Joint attention in autonomous driving (jaad),”ArXiv, vol. abs/1609.04741, 2016. [Online]. Available: https://api.semanticscholar.org/CorpusID:4816620
-
[40]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Fixing weight decay regularization in adam,”ArXiv, vol. abs/1711.05101, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:3312944
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Action- based contrastive learning for trajectory prediction,
M. Halawa, O. Hellwich, and P. Bideau, “Action- based contrastive learning for trajectory prediction,” ArXiv, vol. abs/2207.08664, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:250627278
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.