REVES: REvision and VErification--Augmented Training for Test-Time Scaling
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
Converting near-miss steps from recovery trajectories into separate revision and verification prompts improves LLM correction on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
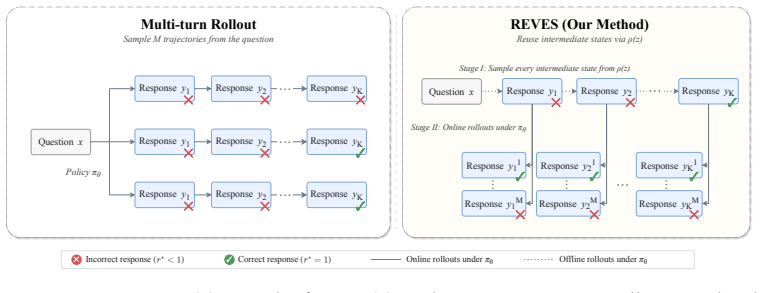
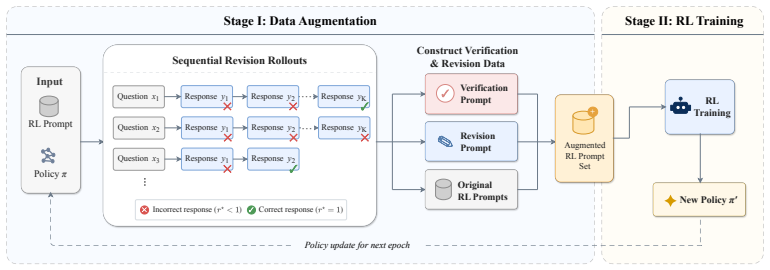
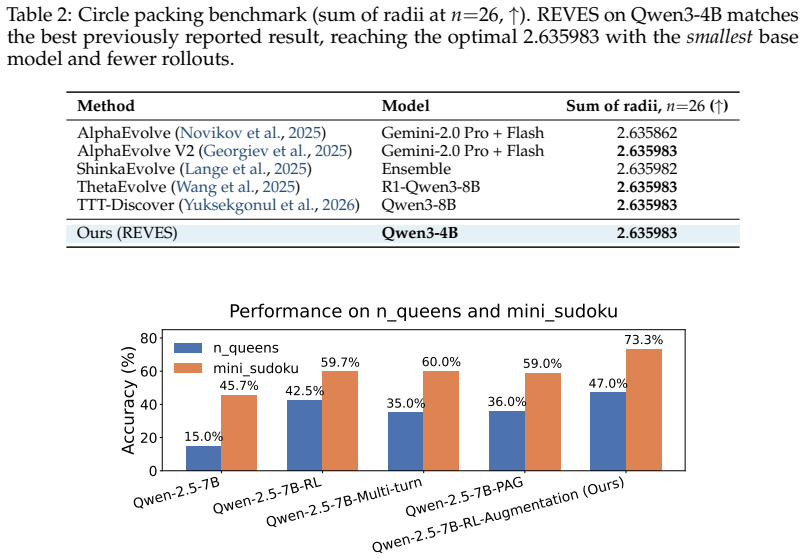
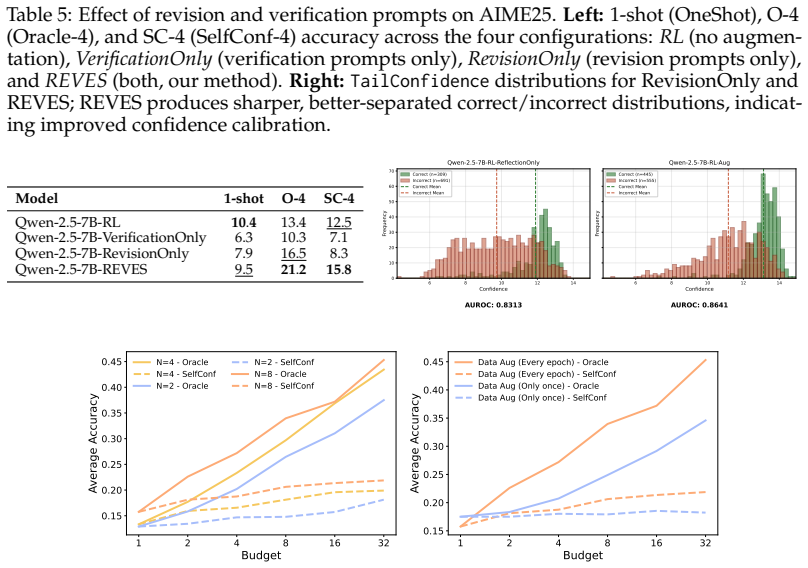
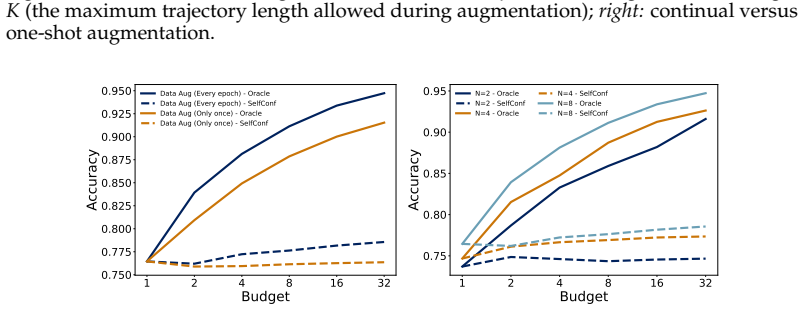
By converting intermediate near-miss answers in successful recovery trajectories into decoupled revision and verification prompts, the two-stage iterative framework concentrates training on effective answer transformation and error identification. This enables efficient off-policy data generation and reduces the computational overhead of long-horizon sampling compared to standard multi-turn RL. On LiveCodeBench the method yields gains of 6.5 points over an RL baseline and 4.0 points over standard multi-turn training when using public test cases as feedback, matches prior SOTA on circle packing with a 4B model and fewer rollouts, and improves correction on math and out-of-distribution puzzles
What carries the argument
Two-stage iterative framework that alternates online data/prompt augmentation and policy optimization by turning near-miss steps into decoupled revision and verification prompts.
If this is right
- Gains of +6.5 points over RL baseline and +4.0 points over standard multi-turn training on LiveCodeBench using public test cases as feedback.
- Matches previously reported SOTA on circle packing while using a 4B base model and far fewer rollouts.
- Improved correction ability on math problems when ground-truth verification is available.
- Generalization to out-of-distribution constraint-satisfaction puzzles such as n-queens and mini-sudoku where correctness follows directly from problem constraints.
Where Pith is reading between the lines
- The decoupling step could be applied to other sequential tasks such as planning or theorem proving to test whether explicit error-identification training transfers.
- If the bias concern does not materialize, smaller models might reach performance levels previously requiring much larger ones by focusing compute on correction rather than raw generation.
- Combining the revision-verification prompts with existing test-time search methods might produce additive improvements that neither technique achieves alone.
Load-bearing premise
The method assumes that near-miss steps from successful trajectories can be turned into decoupled revision and verification prompts that strengthen correction ability without introducing selection bias or losing necessary context.
What would settle it
Running the full method on a held-out reasoning benchmark where near-miss steps are available and finding no gain or a loss relative to standard multi-turn RL would show the conversion step does not reliably improve correction.
Figures





read the original abstract
Test-time scaling via sequential revision has emerged as a powerful paradigm for enhancing Large Language Model (LLM) reasoning. However, standard post-training methods primarily optimize single-shot objectives, creating a fundamental misalignment with multi-step inference dynamics. While recent work treats this as multi-turn reinforcement learning (RL), conventional approaches optimize over the multi-step trajectories directly, failing to further exploit the high-quality mistakes in intermediate steps that model can learn from correcting them. We propose a two-stage iterative framework that alternates between online data/prompt augmentation and policy optimization. By converting the intermediate steps (``near-miss'' answers) in the successful recovery trajectories into decoupled revision and verification prompts, our approach concentrates training on both effective answer transformation and error identification. This approach enables efficient off-policy data generation and reduces the computational overhead of long-horizon sampling compared to standard multi-turn RL. On LiveCodeBench, using publicly available test cases as feedback, we observe gains of +6.5 points over the RL baseline and +4.0 points over standard multi-turn training. Beyond coding, our approach matches the previously reported SOTA result on circle packing while using the smallest base model (4B) and far fewer rollouts than the much larger evolutionary search systems. Math results under ground-truth verification further confirm improved correction ability. It also generalizes to out-of-distribution constraint-satisfaction puzzles such as n\_queens and mini\_sudoku, where correctness is defined entirely by problem constraints. Code is available at https://github.com/yxliu02/REVES.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REVES, a two-stage iterative framework alternating online data/prompt augmentation with policy optimization for test-time scaling in LLMs. It converts intermediate near-miss steps from successful recovery trajectories into decoupled revision and verification prompts to focus training on answer transformation and error identification. This is claimed to enable efficient off-policy data generation with lower overhead than standard multi-turn RL. Empirical results include +6.5 points over an RL baseline and +4.0 over standard multi-turn training on LiveCodeBench (using public test cases as feedback), matching prior SOTA on circle packing with a 4B model and fewer rollouts, plus generalization to math and out-of-distribution constraint puzzles like n-queens and mini-sudoku under ground-truth verification. Code is released at the provided GitHub link.
Significance. If the reported gains prove robust and attributable to the decoupled revision/verification training rather than trajectory filtering, the work could meaningfully advance test-time scaling by addressing misalignment between single-shot post-training and multi-step inference, while offering efficiency advantages over full multi-turn RL. Strengths include public code release (enabling reproducibility) and demonstration of competitive results with a small base model on circle packing. The generalization claims to constraint-satisfaction tasks are potentially valuable if the method's assumptions hold.
major comments (2)
- [Abstract and §4] Abstract and §4 (LiveCodeBench results): the +6.5 / +4.0 point gains are presented without statistical tests, variance across runs, baseline implementation details, or controls for prompt construction and data filtering; this directly undermines attribution of improvements to the REVES framework versus selection effects from restricting to successful-recovery trajectories.
- [Methods] Methods (trajectory conversion procedure): the central assumption that intermediate near-miss steps from successful recoveries can be decoupled into revision/verification prompts without discarding necessary context or introducing bias (relative to error types at test time) is load-bearing for all generalization claims, yet no ablation compares against full trajectories, failed attempts, or alternative filtering rules.
minor comments (2)
- [Methods] Notation for 'near-miss' steps and the two-stage iteration loop could be formalized with a diagram or pseudocode to clarify the off-policy generation process.
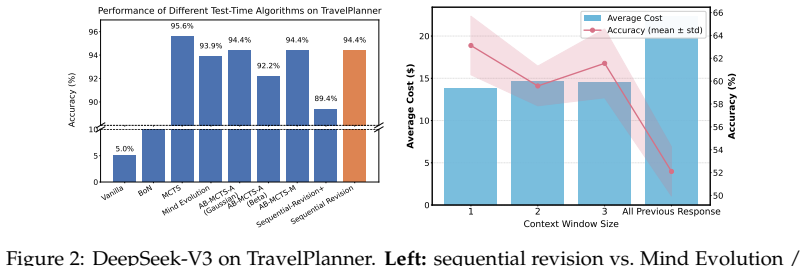
- [Experiments] The circle-packing and math experiments would benefit from explicit comparison tables showing rollout counts and model sizes against the cited prior SOTA systems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, clarifying our position and indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (LiveCodeBench results): the +6.5 / +4.0 point gains are presented without statistical tests, variance across runs, baseline implementation details, or controls for prompt construction and data filtering; this directly undermines attribution of improvements to the REVES framework versus selection effects from restricting to successful-recovery trajectories.
Authors: We agree that the absence of statistical tests, run-to-run variance, and detailed baseline controls weakens the attribution of gains specifically to the REVES decoupling mechanism. In the revised manuscript we will report standard deviations over at least three independent runs, include paired statistical significance tests, expand the baseline implementation details (including exact prompt templates and filtering criteria), and add an explicit control that applies the same successful-trajectory filter without the revision/verification split. These additions will allow readers to assess whether improvements exceed selection effects. revision: yes
-
Referee: [Methods] Methods (trajectory conversion procedure): the central assumption that intermediate near-miss steps from successful recoveries can be decoupled into revision/verification prompts without discarding necessary context or introducing bias (relative to error types at test time) is load-bearing for all generalization claims, yet no ablation compares against full trajectories, failed attempts, or alternative filtering rules.
Authors: The decoupling step is indeed central, and we acknowledge that the original submission did not contain direct ablations against full trajectories or failed attempts. We maintain that the design is motivated by the desire to isolate revision and verification signals, and the observed generalization to math and constraint-satisfaction tasks provides indirect support. Nevertheless, to address the concern directly we will add a targeted ablation in the revision that compares (i) the decoupled prompts against full multi-turn trajectories and (ii) successful-recovery filtering against an alternative that includes failed attempts, using the same compute budget. This will quantify any bias introduced by the conversion procedure. revision: partial
Circularity Check
No circularity: empirical method with independent benchmark results
full rationale
The paper proposes a two-stage iterative training framework that converts near-miss steps from successful trajectories into decoupled revision/verification prompts, reporting empirical gains on LiveCodeBench and other tasks. No equations, parameter-fitting procedures, or self-referential predictions appear in the abstract or described method that would reduce claimed improvements to quantities defined by the inputs themselves. The central results are presented as experimental observations rather than derivations, and no load-bearing self-citations or uniqueness theorems are invoked. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[2]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[3]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[4]
2023 , eprint=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
2023
-
[5]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
Learning to Reason from Feedback at Test-Time , author=. 2025 , eprint=
2025
-
[7]
2024 , eprint=
Training Language Models to Self-Correct via Reinforcement Learning , author=. 2024 , eprint=
2024
-
[8]
2024 , eprint=
Recursive Introspection: Teaching Language Model Agents How to Self-Improve , author=. 2024 , eprint=
2024
-
[9]
2025 , eprint=
LANPO: Bootstrapping Language and Numerical Feedback for Reinforcement Learning in LLMs , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Multi-Turn Code Generation Through Single-Step Rewards , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
Self-rewarding correction for mathematical reasoning , author=. 2025 , eprint=
2025
-
[13]
2025 , eprint=
RefineCoder: Iterative Improving of Large Language Models via Adaptive Critique Refinement for Code Generation , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
Qwen2 Technical Report , author=. 2024 , eprint=
2024
-
[15]
2025 , eprint=
What is the objective of reasoning with reinforcement learning? , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
PAG: Multi-Turn Reinforced LLM Self-Correction with Policy as Generative Verifier , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
Evolving Deeper LLM Thinking , author=. 2025 , eprint=
2025
-
[18]
2025 , eprint=
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search , author=. 2025 , eprint=
2025
-
[19]
2024 , eprint=
Reason for Future, Act for Now: A Principled Framework for Autonomous LLM Agents with Provable Sample Efficiency , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
ReVISE: Learning to Refine at Test-Time via Intrinsic Self-Verification , author=. 2025 , eprint=
2025
-
[21]
Submitted to The Fourteenth International Conference on Learning Representations , year=
Diversity-aware Training for Test-time Scaling , author=. Submitted to The Fourteenth International Conference on Learning Representations , year=
-
[22]
2025 , eprint=
Pass@k Training for Adaptively Balancing Exploration and Exploitation of Large Reasoning Models , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
Pass@K Policy Optimization: Solving Harder Reinforcement Learning Problems , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
Optimizing Language Models for Inference Time Objectives using Reinforcement Learning , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
Building Math Agents with Multi-Turn Iterative Preference Learning , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
Deep Think with Confidence , author=. 2025 , eprint=
2025
-
[28]
2016 , eprint=
Prioritized Experience Replay , author=. 2016 , eprint=
2016
-
[29]
2024 , eprint=
TravelPlanner: A Benchmark for Real-World Planning with Language Agents , author=. 2024 , eprint=
2024
-
[30]
2025 , eprint=
REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning , author=. 2025 , eprint=
2025
-
[32]
2024 , eprint=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. 2024 , eprint=
2024
-
[38]
2026 , eprint=
Learning to Discover at Test Time , author=. 2026 , eprint=
2026
-
[39]
2025 , eprint=
SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning , author=. 2025 , eprint=
2025
-
[40]
2026 , eprint=
POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration , author=. 2026 , eprint=
2026
-
[41]
2026 , eprint=
Critique-GRPO: Advancing LLM Reasoning with Natural Language and Numerical Feedback , author=. 2026 , eprint=
2026
-
[42]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[43]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@k training for adaptively balancing exploration and exploitation of large reasoning models, 2025. URL https://arxiv.org/abs/2508.10751
arXiv 2025
-
[44]
Inference-aware fine-tuning for best-of-n sampling in large language models, 2025
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Sridhar Thiagarajan, Craig Boutilier, Rishabh Agarwal, Aviral Kumar, and Aleksandra Faust. Inference-aware fine-tuning for best-of-n sampling in large language models, 2025. URL https://arxiv.org/abs/2412.15287
arXiv 2025
-
[45]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
Pith/arXiv arXiv 2025
-
[46]
Deep think with confidence, 2025
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence, 2025. URL https://arxiv.org/abs/2508.15260
Pith/arXiv arXiv 2025
-
[47]
Mathematical exploration and discovery at scale
Bogdan Georgiev, Javier G \'o mez-Serrano, Terence Tao, and Adam Zsolt Wagner. Mathematical exploration and discovery at scale. arXiv preprint arXiv:2511.02864, 2025
Pith/arXiv arXiv 2025
-
[48]
Wider or deeper? scaling llm inference-time compute with adaptive branching tree search, 2025
Yuichi Inoue, Kou Misaki, Yuki Imajuku, So Kuroki, Taishi Nakamura, and Takuya Akiba. Wider or deeper? scaling llm inference-time compute with adaptive branching tree search, 2025. URL https://arxiv.org/abs/2503.04412
arXiv 2025
-
[49]
Multi-turn code generation through single-step rewards, 2025
Arnav Kumar Jain, Gonzalo Gonzalez-Pumariega, Wayne Chen, Alexander M Rush, Wenting Zhao, and Sanjiban Choudhury. Multi-turn code generation through single-step rewards, 2025. URL https://arxiv.org/abs/2502.20380
arXiv 2025
-
[50]
Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024. URL https://arxiv.org/abs/2403.07974
Pith/arXiv arXiv 2024
-
[51]
Pag: Multi-turn reinforced llm self-correction with policy as generative verifier, 2025
Yuhua Jiang, Yuwen Xiong, Yufeng Yuan, Chao Xin, Wenyuan Xu, Yu Yue, Qianchuan Zhao, and Lin Yan. Pag: Multi-turn reinforced llm self-correction with policy as generative verifier, 2025. URL https://arxiv.org/abs/2506.10406
arXiv 2025
-
[52]
Training language models to self-correct via reinforcement learning, 2024
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Training language models to self-correct via reinforcement learning, 2024. URL https...
Pith/arXiv arXiv 2024
-
[53]
Shinkaevolve: Towards open-ended and sample-efficient program evolution
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution. arXiv preprint arXiv:2509.19349, 2025
Pith/arXiv arXiv 2025
-
[54]
Revise: Learning to refine at test-time via intrinsic self-verification, 2025 a
Hyunseok Lee, Seunghyuk Oh, Jaehyung Kim, Jinwoo Shin, and Jihoon Tack. Revise: Learning to refine at test-time via intrinsic self-verification, 2025 a . URL https://arxiv.org/abs/2502.14565
arXiv 2025
-
[55]
Evolving deeper llm thinking, 2025 b
Kuang-Huei Lee, Ian Fischer, Yueh-Hua Wu, Dave Marwood, Shumeet Baluja, Dale Schuurmans, and Xinyun Chen. Evolving deeper llm thinking, 2025 b . URL https://arxiv.org/abs/2501.09891
arXiv 2025
-
[56]
Lanpo: Bootstrapping language and numerical feedback for reinforcement learning in llms, 2025 a
Ang Li, Yifei Wang, Zhihang Yuan, Stefanie Jegelka, and Yisen Wang. Lanpo: Bootstrapping language and numerical feedback for reinforcement learning in llms, 2025 a . URL https://arxiv.org/abs/2510.16552
arXiv 2025
-
[57]
Learning to reason from feedback at test-time, 2025 b
Yanyang Li, Michael Lyu, and Liwei Wang. Learning to reason from feedback at test-time, 2025 b . URL https://arxiv.org/abs/2502.15771
arXiv 2025
-
[58]
2022, Science, 378, 1092–1097, doi: 10.1126/science.abq1158
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R \'e mi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, P...
-
[59]
Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning, 2025
Xiao Liang, Zhong-Zhi Li, Yeyun Gong, Yang Wang, Hengyuan Zhang, Yelong Shen, Ying Nian Wu, and Weizhu Chen. Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning, 2025. URL https://arxiv.org/abs/2506.08989
arXiv 2025
-
[60]
Self-refine: Iterative refinement with self-feedback, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/2303.17651
Pith/arXiv arXiv 2023
-
[61]
Alphaevolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ng \^a n V \ u , Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025
Pith/arXiv arXiv 2025
-
[62]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
Pith/arXiv arXiv 2022
-
[63]
Recursive introspection: Teaching language model agents how to self-improve, 2024
Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. Recursive introspection: Teaching language model agents how to self-improve, 2024. URL https://arxiv.org/abs/2407.18219
arXiv 2024
-
[64]
Pope: Learning to reason on hard problems via privileged on-policy exploration, 2026
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. Pope: Learning to reason on hard problems via privileged on-policy exploration, 2026. URL https://arxiv.org/abs/2601.18779
arXiv 2026
-
[65]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[66]
Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards, 2025
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, and Andreas Köpf. Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards, 2025. URL https://arxiv.org/abs/2505.24760
arXiv 2025
-
[67]
Optimizing language models for inference time objectives using reinforcement learning, 2025
Yunhao Tang, Kunhao Zheng, Gabriel Synnaeve, and Rémi Munos. Optimizing language models for inference time objectives using reinforcement learning, 2025. URL https://arxiv.org/abs/2503.19595
arXiv 2025
-
[68]
Pass@k policy optimization: Solving harder reinforcement learning problems, 2025
Christian Walder and Deep Karkhanis. Pass@k policy optimization: Solving harder reinforcement learning problems, 2025. URL https://arxiv.org/abs/2505.15201
Pith/arXiv arXiv 2025
-
[69]
Self-consistency improves chain of thought reasoning in language models, 2023
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023. URL https://arxiv.org/abs/2203.11171
Pith/arXiv arXiv 2023
-
[70]
Thetaevolve: Test-time learning on open problems
Yiping Wang, Shao-Rong Su, Zhiyuan Zeng, Eva Xu, Liliang Ren, Xinyu Yang, Zeyi Huang, Xuehai He, Luyao Ma, Baolin Peng, et al. Thetaevolve: Test-time learning on open problems. arXiv preprint arXiv:2511.23473, 2025
Pith/arXiv arXiv 2025
-
[71]
Travelplanner: A benchmark for real-world planning with language agents, 2024
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. Travelplanner: A benchmark for real-world planning with language agents, 2024. URL https://arxiv.org/abs/2402.01622
arXiv 2024
-
[72]
Building math agents with multi-turn iterative preference learning, 2025
Wei Xiong, Chengshuai Shi, Jiaming Shen, Aviv Rosenberg, Zhen Qin, Daniele Calandriello, Misha Khalman, Rishabh Joshi, Bilal Piot, Mohammad Saleh, Chi Jin, Tong Zhang, and Tianqi Liu. Building math agents with multi-turn iterative preference learning, 2025. URL https://arxiv.org/abs/2409.02392
arXiv 2025
-
[73]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
Pith/arXiv arXiv 2024
-
[74]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[75]
Learning to discover at test time, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time, 2026. URL https://arxiv.org/abs/2601.16175
Pith/arXiv arXiv 2026
-
[76]
Critique-grpo: Advancing llm reasoning with natural language and numerical feedback, 2026
Xiaoying Zhang, Yipeng Zhang, Hao Sun, Kaituo Feng, Chaochao Lu, Chao Yang, and Helen Meng. Critique-grpo: Advancing llm reasoning with natural language and numerical feedback, 2026. URL https://arxiv.org/abs/2506.03106
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.