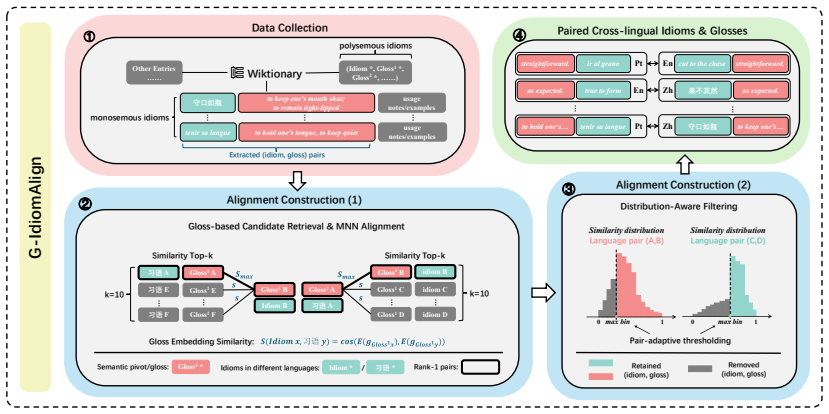
G-IdiomAlign: A Gloss-Pivoted Benchmark for Cross-Lingual Idiom Alignment
Pith reviewed 2026-06-26 20:37 UTC · model grok-4.3
The pith
English Wiktionary glosses improve cross-lingual idiom generation and matching for language models, though gains remain modest and literal biases persist.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
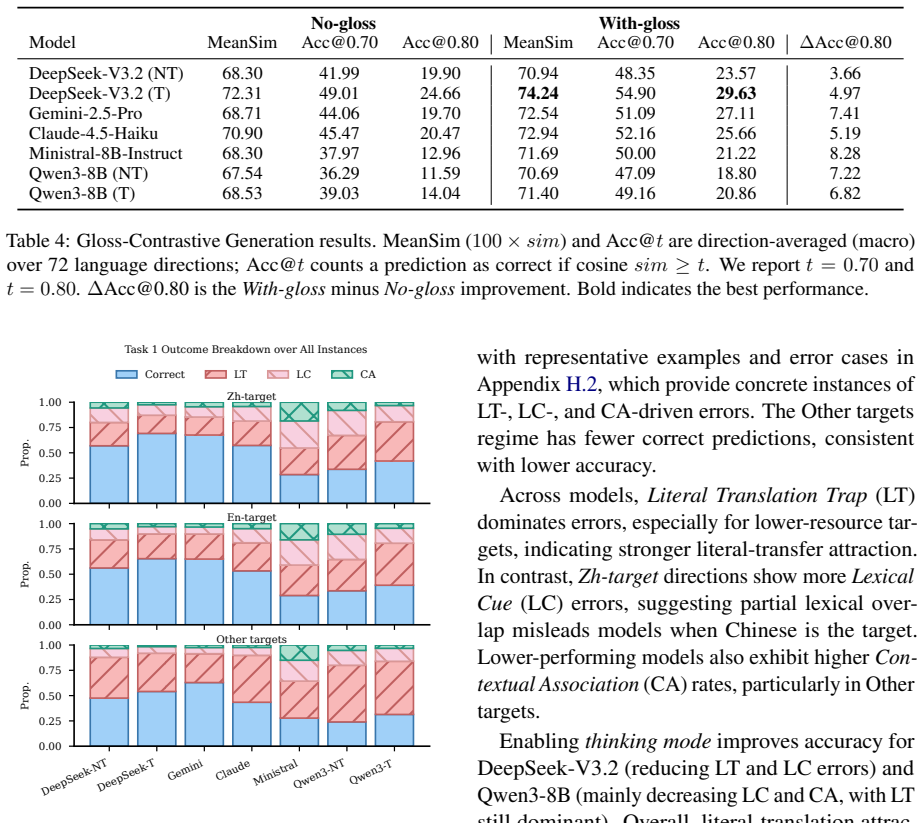
The paper claims that a gloss-pivoted benchmark enables reproducible cross-lingual idiom alignment evaluation, that supplying the English gloss during generation produces measurably better outputs under an embedding-based semantic proxy than the no-gloss condition, and that the resulting performance difference concentrates more in attention heads than across layers, with stronger gloss anchoring linked to higher-quality generations.
What carries the argument
The Gloss-Contrastive Generation protocol that compares model outputs on identical inputs with and without the English gloss to measure the effect of the explicit semantic pivot.
If this is right
- Literal translation remains the dominant error mode and is only partially offset by gloss input.
- Attention-head differences rather than layer-wide changes drive the observed gains in at least one tested model.
- Generations that more strongly reference the gloss tend to receive higher semantic scores.
- The high-confidence reference alignment set supports consistent future comparisons.
- Large headroom remains in open-ended generation even after glosses are supplied.
Where Pith is reading between the lines
- If gloss pivots help here, comparable meaning anchors could be tested on other figurative constructions such as metaphors or proverbs.
- The concentration of effect in attention heads suggests targeted interventions at those positions might amplify the gloss benefit.
- The modest absolute numbers imply that pairing glosses with additional signals such as example sentences could produce larger lifts.
Load-bearing premise
English Wiktionary glosses supply a reliable language-neutral description of idiom meaning that holds across different languages and cultures.
What would settle it
No measurable rise in embedding similarity or drop in literal-translation errors when the gloss is added, across a wider range of models and language pairs than tested here.
Figures

read the original abstract
Idioms are difficult to transfer across languages due to their non-compositionality and weak surface-form grounding, making literal mappings unreliable. We present G-IdiomAlign, a gloss-pivoted benchmark where each idiom is anchored by an English gloss from Wiktionary. We further construct a high-confidence reference alignment set for reproducible evaluation. G-IdiomAlign supports two protocols: (1) a controlled Multiple-Choice Idiom Equivalence with typed distractors for error attribution; and (2) a Gloss-Contrastive Generation contrasting No-gloss and With-gloss inputs to isolate the effect of an explicit semantic pivot. Across diverse LLMs, a bias to literal translation is a dominant failure mode, especially when the target is a low-resource language. Glosses consistently improve Gloss-Contrastive Generation under an embedding-based semantic proxy, but performance remains modest, indicating substantial headroom in the open output space. Subsequent analysis on Qwen3-8B further suggests that cross-condition differences are concentrated more in attention heads than in layers, while better With-gloss generations coincide with stronger gloss anchoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces G-IdiomAlign, a gloss-pivoted benchmark for cross-lingual idiom alignment anchored by English Wiktionary glosses. It constructs a high-confidence reference alignment set and supports two protocols: Multiple-Choice Idiom Equivalence with typed distractors for error analysis, and Gloss-Contrastive Generation contrasting No-gloss and With-gloss inputs. Experiments across LLMs identify literal translation bias as a dominant failure mode (especially for low-resource targets), show consistent but modest gains from glosses under an embedding-based semantic proxy, and report that cross-condition differences in Qwen3-8B are concentrated more in attention heads than layers, with better With-gloss outputs linked to stronger gloss anchoring.
Significance. If the central findings hold, the reproducible high-confidence reference alignment set and the controlled protocols provide a useful standardized resource for evaluating cross-lingual idiom handling in LLMs. The explicit isolation of gloss effects and the attention-head analysis offer concrete directions for mitigating literal bias in non-compositional transfer. The benchmark construction itself, with its focus on error attribution via distractors, strengthens the empirical contribution to multilingual NLP.
major comments (2)
- [Benchmark Construction / Gloss-Contrastive Generation protocol] The claim that glosses improve Gloss-Contrastive Generation under the embedding proxy rests on English Wiktionary glosses serving as reliable language-neutral semantic pivots. No validation of gloss fidelity (e.g., human ratings of meaning preservation across target languages or comparison to native-speaker paraphrases) is described in the benchmark construction or evaluation sections; this is load-bearing because any English-centric bias in the glosses would directly confound the With-gloss vs. No-gloss contrast and the reported modest gains.
- [Benchmark Construction] Details on idiom selection criteria, the construction of the high-confidence reference alignment set, and the exact typing of distractors in the Multiple-Choice task are absent from the high-level description. These omissions prevent assessment of whether the observed literal bias is an artifact of data curation rather than a general LLM property.
minor comments (1)
- [Evaluation / Gloss-Contrastive Generation] The specific embedding model and similarity metric constituting the 'embedding-based semantic proxy' should be stated explicitly, along with any preprocessing steps, to allow exact reproduction of the generation evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below.
read point-by-point responses
-
Referee: [Benchmark Construction / Gloss-Contrastive Generation protocol] The claim that glosses improve Gloss-Contrastive Generation under the embedding proxy rests on English Wiktionary glosses serving as reliable language-neutral semantic pivots. No validation of gloss fidelity (e.g., human ratings of meaning preservation across target languages or comparison to native-speaker paraphrases) is described in the benchmark construction or evaluation sections; this is load-bearing because any English-centric bias in the glosses would directly confound the With-gloss vs. No-gloss contrast and the reported modest gains.
Authors: We agree this is a valid concern. The manuscript uses Wiktionary glosses as provided anchors without reporting cross-lingual fidelity validation. We will revise the benchmark construction section to explicitly discuss this assumption, note its potential to introduce English-centric bias, and add a limitations paragraph on the need for future human validation studies. The reported gains remain tied to the embedding proxy as stated. revision: partial
-
Referee: [Benchmark Construction] Details on idiom selection criteria, the construction of the high-confidence reference alignment set, and the exact typing of distractors in the Multiple-Choice task are absent from the high-level description. These omissions prevent assessment of whether the observed literal bias is an artifact of data curation rather than a general LLM property.
Authors: The full manuscript contains a benchmark construction section with these elements, but we acknowledge the descriptions are insufficiently detailed. We will expand it to specify idiom selection criteria (e.g., Wiktionary coverage and inclusion filters), the exact procedure for building the high-confidence reference alignment set, and the distractor typing scheme (literal, semantic, unrelated). This will enable readers to evaluate whether literal bias is curation-dependent. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation against external references
full rationale
The paper constructs a new benchmark (G-IdiomAlign) anchored to external Wiktionary glosses and evaluates LLMs on multiple-choice and generation tasks. No mathematical derivations, fitted parameters, predictions, or self-citation chains are present in the provided text. The central claims rest on empirical contrasts (with-gloss vs no-gloss) measured against independent embedding proxies and human references, with no reduction of outputs to inputs by construction. This is the expected non-finding for dataset papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MAGPIE : A Large Corpus of Potentially Idiomatic Expressions
Haagsma, Hessel and Bos, Johan and Nissim, Malvina. MAGPIE : A Large Corpus of Potentially Idiomatic Expressions. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[2]
Rolling the DICE on Idiomaticity: How LLM s Fail to Grasp Context
Mi, Maggie and Villavicencio, Aline and Moosavi, Nafise Sadat. Rolling the DICE on Idiomaticity: How LLM s Fail to Grasp Context. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.362
-
[3]
Sentsova, Uliana and Ciminari, Debora and Genabith, Josef Van and Espa \ n a-Bonet, Cristina. M ulti C o PIE : A Multilingual Corpus of Potentially Idiomatic Expressions for Cross-lingual PIE Disambiguation. Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025). 2025. doi:10.18653/v1/2025.mwe-1.8
-
[4]
Prateek Saxena and Soma Paul , year=. 2006.09479 , archivePrefix=
arXiv 2006
-
[5]
A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models
De Luca Fornaciari, Francesca and Altuna, Bego \ n a and Gonzalez-Dios, Itziar and Melero, Maite. A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models. Proceedings of the 4th Workshop on Figurative Language Processing (FigLang 2024). 2024. doi:10.18653/v1/2024.figlang-1.5
-
[6]
ID 10 M : Idiom Identification in 10 Languages
Tedeschi, Simone and Martelli, Federico and Navigli, Roberto. ID 10 M : Idiom Identification in 10 Languages. Findings of the Association for Computational Linguistics: NAACL 2022. 2022. doi:10.18653/v1/2022.findings-naacl.208
-
[7]
Edition 1.2 of the PARSEME Shared Task on Semi-supervised Identification of Verbal Multiword Expressions
Ramisch, Carlos and Savary, Agata and Guillaume, Bruno and Waszczuk, Jakub and Candito, Marie and Vaidya, Ashwini and Barbu Mititelu, Verginica and Bhatia, Archna and I. Edition 1.2 of the PARSEME Shared Task on Semi-supervised Identification of Verbal Multiword Expressions. Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons. 2020
2020
-
[8]
CLIX : Cross-Lingual Explanations of Idiomatic Expressions
Gluck, Aaron and Wense, Katharina Von Der and Pacheco, Maria Leonor. CLIX : Cross-Lingual Explanations of Idiomatic Expressions. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.233
-
[9]
LI dioms: A Multilingual Linked Idioms Data Set
Moussallem, Diego and Sherif, Mohamed Ahmed and Esteves, Diego and Zampieri, Marcos and Ngonga Ngomo, Axel-Cyrille. LI dioms: A Multilingual Linked Idioms Data Set. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[10]
CHENGYU - BENCH : Benchmarking Large Language Models for C hinese Idiom Understanding and Use
Fu, Yicheng and Huang, Zhemin and Yang, Liuxin and Lu, Yumeng and Dai, Zhongdongming. CHENGYU - BENCH : Benchmarking Large Language Models for C hinese Idiom Understanding and Use. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.119
-
[11]
and Doh, Joon Young and Rodan, Eid and Zhu, Kevin and O ' Brien, Sean
Donthi, Sundesh and Spencer, Maximilian and Patel, Om B. and Doh, Joon Young and Rodan, Eid and Zhu, Kevin and O ' Brien, Sean. Improving LLM Abilities in Idiomatic Translation. Proceedings of the First Workshop on Language Models for Low-Resource Languages. 2025
2025
-
[12]
From Neural Machine Translation to Large Language Models: Analysing Translation Quality of Chinese Idioms , author=
-
[13]
Evaluating
Cai Yang and Yao Dou and David Heineman and Xiaofeng Wu and Wei Xu , journal=. Evaluating. 2025 , volume=
2025
-
[14]
Automating Idiom Translation with Cross-Lingual Natural Language Generation Grounded In Semantic Analyses Using Large Language Models
Qian, Ming. Automating Idiom Translation with Cross-Lingual Natural Language Generation Grounded In Semantic Analyses Using Large Language Models. Proceedings of the 16th Conference of the Association for Machine Translation in the Americas (Volume 2: Presentations). 2024
2024
-
[15]
Liu, Emmy and Chaudhary, Aditi and Neubig, Graham. Crossing the Threshold: Idiomatic Machine Translation through Retrieval Augmentation and Loss Weighting. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.933
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Translate Meanings, Not Just Words:. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i17.29817 , abstractNote=
-
[17]
Comparative Study of Multilingual Idioms and Similes in Large Language Models
Khoshtab, Paria and Namazifard, Danial and Masoudi, Mostafa and Akhgary, Ali and Mahdizadeh Sani, Samin and Yaghoobzadeh, Yadollah. Comparative Study of Multilingual Idioms and Similes in Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[18]
On Bilingual Lexicon Induction with Large Language Models
Li, Yaoyiran and Korhonen, Anna and Vuli \'c , Ivan. On Bilingual Lexicon Induction with Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.595
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Enhancing Bilingual Lexicon Induction via Bi-directional Translation Pair Retrieving , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i16.29744 , abstractNote=
-
[20]
Investigating Idiomaticity in Word Representations
He, Wei and Vieira, Tiago Kramer and Garcia, Marcos and Scarton, Carolina and Idiart, Marco and Villavicencio, Aline. Investigating Idiomaticity in Word Representations. Computational Linguistics. 2025. doi:10.1162/coli_a_00546
-
[21]
Evaluating Machine Translation Performance on C hinese Idioms with a Blacklist Method
Shao, Yutong and Sennrich, Rico and Webber, Bonnie and Fancellu, Federico. Evaluating Machine Translation Performance on C hinese Idioms with a Blacklist Method. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[22]
2002 , organization=
Sag, Ivan A and Baldwin, Timothy and Bond, Francis and Copestake, Ann and Flickinger, Dan , booktitle=. 2002 , organization=
2002
-
[23]
A ttention is not E xplanation
Jain, Sarthak and Wallace, Byron C. A ttention is not E xplanation. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1357
-
[24]
Contextualized Embeddings Encode Monolingual and Cross-lingual Knowledge of Idiomaticity
Fakharian, Samin and Cook, Paul. Contextualized Embeddings Encode Monolingual and Cross-lingual Knowledge of Idiomaticity. Proceedings of the 17th Workshop on Multiword Expressions (MWE 2021). 2021. doi:10.18653/v1/2021.mwe-1.4
-
[25]
CLCL : Non-compositional Expression Detection with Contrastive Learning and Curriculum Learning
Zhou, Jianing and Zeng, Ziheng and Bhat, Suma. CLCL : Non-compositional Expression Detection with Contrastive Learning and Curriculum Learning. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.43
-
[26]
PIE : A Parallel Idiomatic Expression Corpus for Idiomatic Sentence Generation and Paraphrasing
Zhou, Jianing and Gong, Hongyu and Bhat, Suma. PIE : A Parallel Idiomatic Expression Corpus for Idiomatic Sentence Generation and Paraphrasing. Proceedings of the 17th Workshop on Multiword Expressions (MWE 2021). 2021. doi:10.18653/v1/2021.mwe-1.5
-
[27]
IEKG : A Commonsense Knowledge Graph for Idiomatic Expressions
Zeng, Ziheng and Cheng, Kellen Tan and Nanniyur, Srihari Venkat and Zhou, Jianing and Bhat, Suma. IEKG : A Commonsense Knowledge Graph for Idiomatic Expressions. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.881
-
[28]
DeepSeek-AI and Aixin Liu and Aoxue Mei and Bangcai Lin and Bing Xue and Bingxuan Wang and Bingzheng Xu and Bochao Wu and Bowei Zhang and Chaofan Lin and Chen Dong and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenhao Xu and Chong Ruan and Damai Dai and Daya Guo and Dejian Yang and Deli Chen and Erhang Li and Fangqi Zhou and Fangyun Lin and Fucon...
-
[29]
2025 , journal =
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. 2025 , journal =
2025
-
[30]
2024 , url=
Un Ministral, des Ministraux , author=. 2024 , url=
2024
-
[31]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[32]
An Yang and Junyang Lin and Jingren Zhou and et al. , year=. Qwen3-Embedding-
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Exposing the Cracks: Vulnerabilities of Retrieval-Augmented LLM-based Machine Translation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Chao and Derek F
Fengying Ye and Shanshan Wang and Lidia S. Chao and Derek F. Wong. Probing Semantic Alignment, Lexical Invariance, and Syntactic Influence in LLM Metaphor Processing. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.