FoMoE: Breaking the Full-Replica Barrier with a Federation of MoEs
Pith reviewed 2026-06-26 21:23 UTC · model grok-4.3
The pith
FoMoE trains large MoEs across ordinary links by partitioning experts and skipping non-resident ones instead of full replicas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
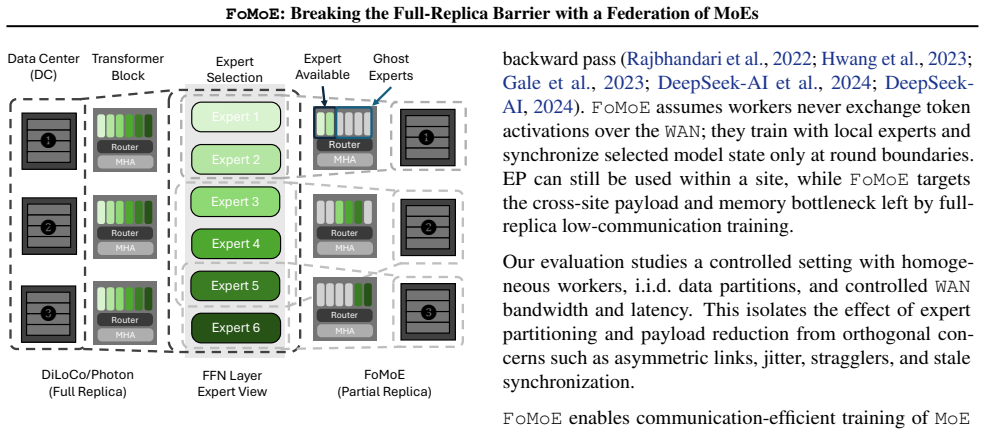
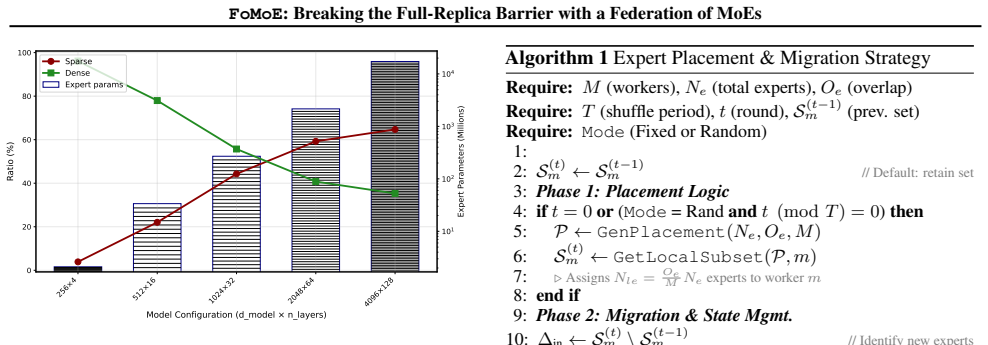
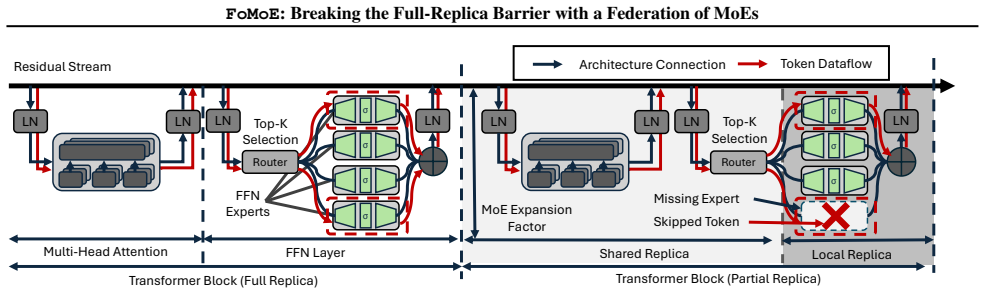
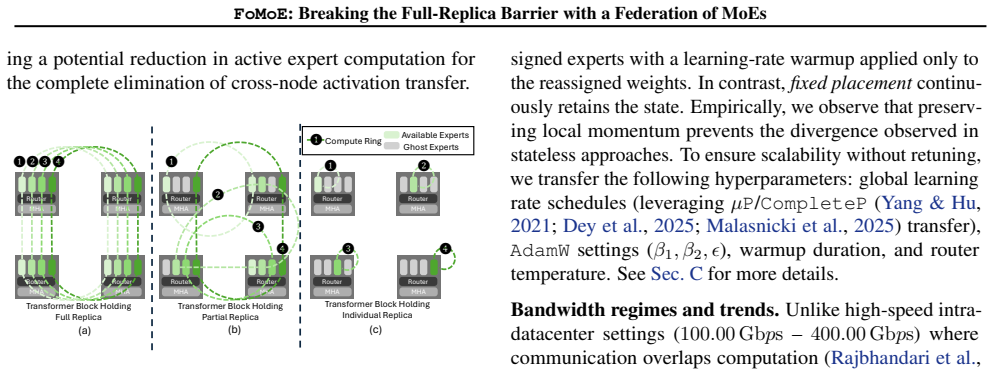
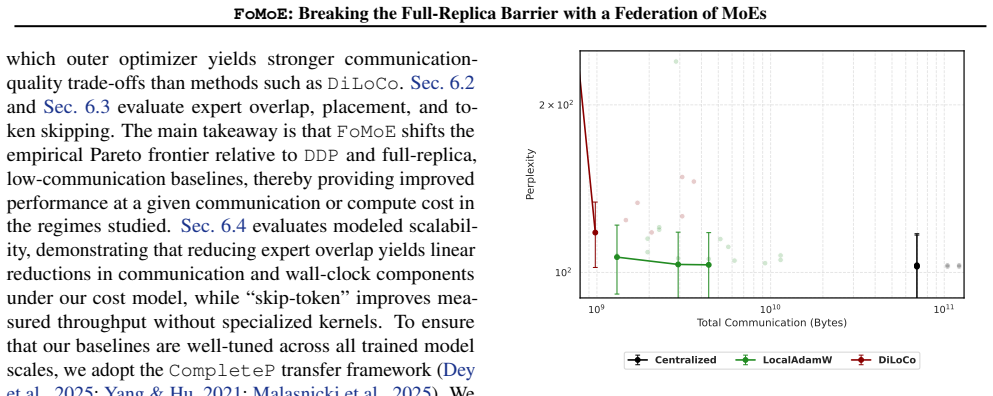
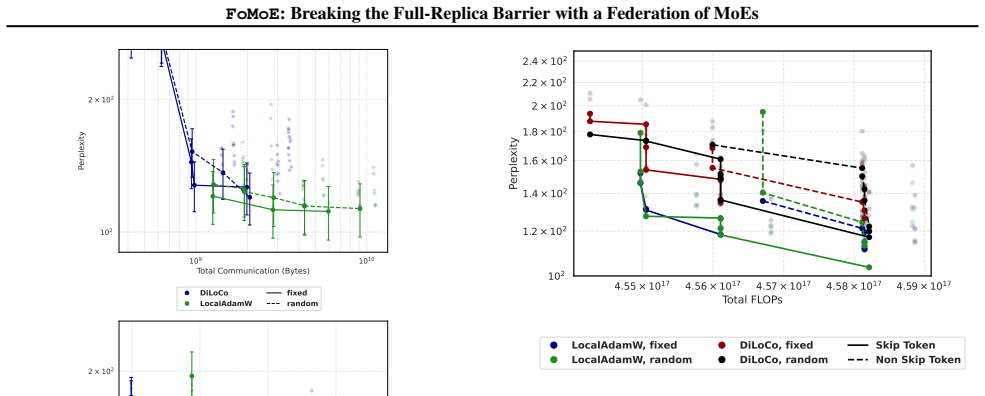
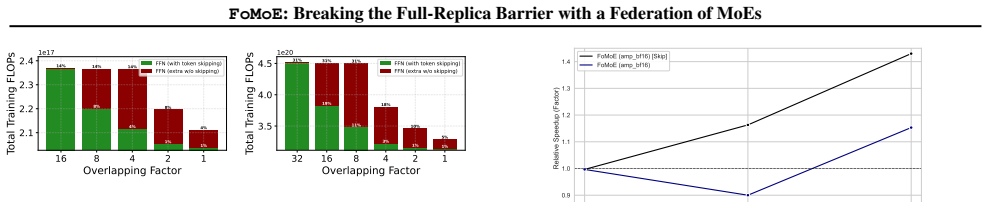
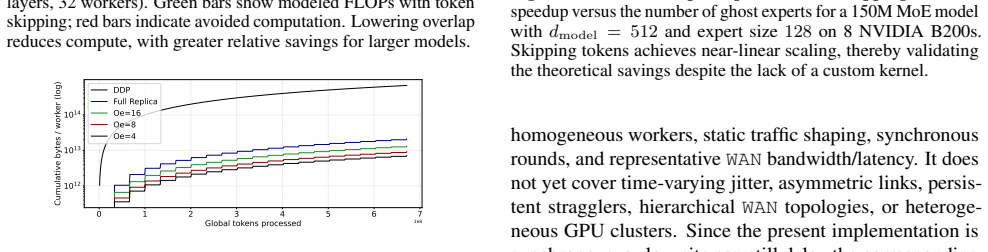
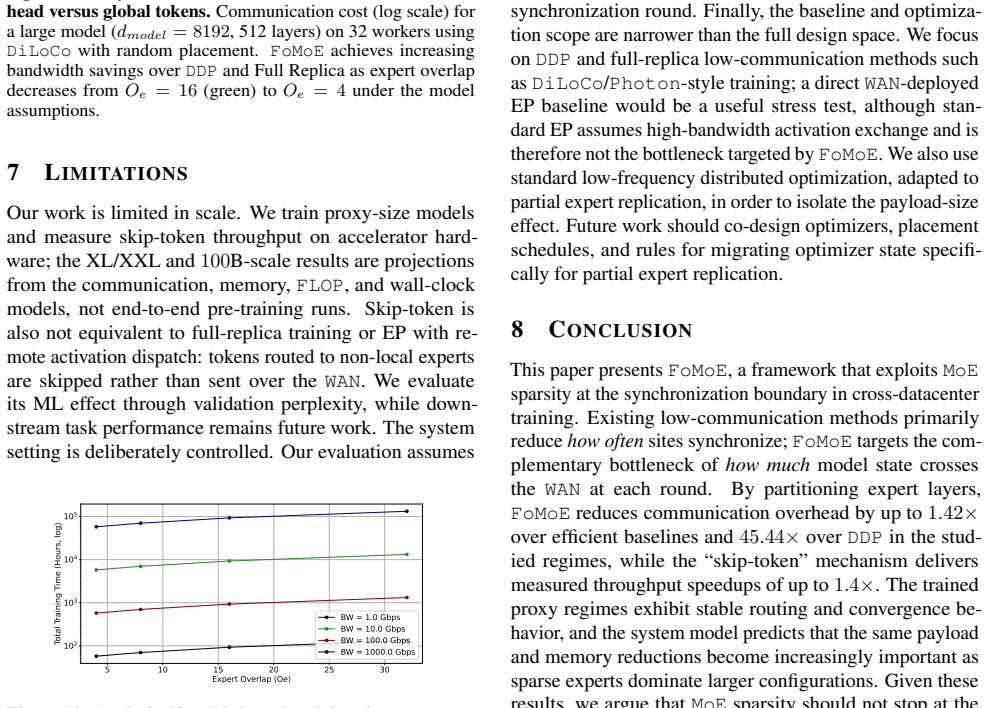
FoMoE breaks the full-replica paradigm by partitioning expert layers across workers and skipping non-resident experts during local training. In controlled regimes this yields communication reductions of up to 1.42 times versus efficient baselines and 45.44 times versus Distributed Data Parallelism, empirical throughput gains of up to 1.4 times from the skip-token step, and stable routing behavior, with system modeling indicating the same pattern extends to 100-billion-parameter scales.
What carries the argument
The skip-token mechanism that drops tokens requiring experts not present on the local worker during each training step, paired with partial expert replication across the federation of sites.
If this is right
- Communication volume falls by up to 1.42 times relative to prior low-communication baselines and by 45.44 times relative to standard data-parallel training.
- Throughput rises by as much as 1.4 times because the local worker never waits for missing experts.
- Routing decisions remain stable once training completes in the tested settings.
- The same partial-replication pattern projects to 100-billion-parameter models with continued memory and bandwidth savings.
Where Pith is reading between the lines
- Geographically scattered machines could now contribute to a single large MoE run without a dedicated high-speed fabric connecting them.
- The same token-skipping idea might transfer to other sparse activation patterns that currently assume every parameter is reachable everywhere.
- If skipping proves neutral, it questions whether every expert must be resident at every site for the routing network to learn correctly.
Load-bearing premise
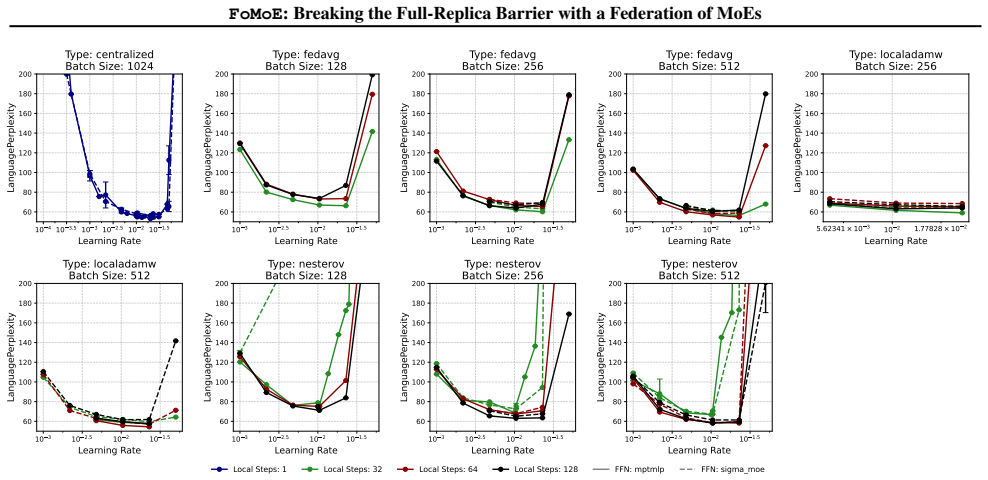
Skipping tokens that need non-resident experts leaves model quality and expert routing unbiased enough for convergence to continue normally.
What would settle it
A side-by-side training run in which final perplexity or downstream accuracy falls measurably when the skip-token rule is active versus an otherwise identical full-replica baseline.
Figures


read the original abstract
Pre-training Large Language Models (LLMs) typically demands large-scale infrastructure with tightly coupled hardware accelerators. Mixture-of-Experts (MoEs) architectures partially decouple model capacity from per-token compute. This efficiency alone does not make MoE training feasible over ordinary Internet links or loosely connected commodity hardware since active expert routing still assumes high-speed datacenter fabrics. Low-communication methods such as DiLoCo and Photon reduce synchronization frequency across distributed sites, mitigating bandwidth constraints, yet still require full model replicas at every site. This creates a mismatch: modern MoEs have sparse data paths, but their distributed training infrastructure remains communication-dense and memory-inefficient, limiting attempts to pool geographically distributed compute. In this work, we introduce FoMoE, a system that breaks the full-replica paradigm by partitioning expert layers across workers and skipping non-resident experts during local training. We demonstrate that FoMoE: (I) reduces communication costs by up to 1.42x over efficient baselines and 45.44x over Distributed Data Parallelism (DDP) via partial expert replication in controlled regimes; (II) achieves empirical throughput speedups of up to 1.4x through the skip-token mechanism; and (III) shows stable routing in the trained regimes and projects the communication/memory benefits to 100B-scale configurations through system modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FoMoE, a federated training approach for Mixture-of-Experts (MoE) models that partitions expert layers across workers and skips tokens requiring non-resident experts during local training. It claims communication cost reductions of up to 1.42x over efficient baselines and 45.44x over Distributed Data Parallelism via partial expert replication, empirical throughput speedups of up to 1.4x from the skip-token mechanism, stable routing in trained regimes, and projected benefits at 100B-scale via system modeling.
Significance. If the empirical measurements and the assumption that token skipping preserves model quality hold under the reported conditions, the work would enable MoE pre-training over lower-bandwidth links without requiring full model replicas at every site, addressing a key barrier for geographically distributed or commodity hardware setups.
minor comments (2)
- [Abstract] Abstract: the reported factors (1.42x communication reduction, 1.4x throughput) are presented without error bars, dataset names, model sizes, or hardware configurations, which limits independent assessment of the measurements.
- [Abstract] Abstract: no mention of ablation experiments or conditions under which the skip-token policy was validated, leaving the central assumption about preserved routing stability and convergence without explicit falsification tests.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript. We are encouraged by the positive assessment of significance, conditional on the empirical results and token-skipping assumption holding. No specific major comments were enumerated in the provided report, so we have no point-by-point rebuttals to offer at this stage. We remain available to supply additional experiments, clarifications, or revisions should the referee raise concrete concerns.
Circularity Check
No significant circularity detected
full rationale
The paper presents a systems contribution with empirical measurements of communication reduction (1.42x/45.44x), throughput speedup (1.4x), and routing stability under partial expert replication and token skipping. No equations, fitted parameters, derivation chains, or load-bearing self-citations appear in the abstract or described claims. All reported gains are direct experimental outcomes rather than quantities derived from other fitted quantities or prior self-citations within the paper. The system modeling projection for 100B-scale is noted but does not alter the empirical core.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Learning with Differential Privacy , booktitle =
Mart. Deep Learning with Differential Privacy , booktitle =
-
[2]
Dan Alistarh and Demjan Grubic and Jerry Li and Ryota Tomioka and Milan Vojnovic , title =
-
[3]
EuroSys , pages =
Sanjith Athlur and Nitika Saran and Muthian Sivathanu and Ramachandran Ramjee and Nipun Kwatra , title =. EuroSys , pages =
-
[4]
Bonawitz and Vladimir Ivanov and Ben Kreuter and Antonio Marcedone and H
Kallista A. Bonawitz and Vladimir Ivanov and Ben Kreuter and Antonio Marcedone and H. Brendan McMahan and Sarvar Patel and Daniel Ramage and Aaron Segal and Karn Seth , title =
-
[5]
CoRR , volume =
Pietro Cagnasso and Eugene Belilovsky and Edouard Oyallon , title =. CoRR , volume =. 2026 , doi =
2026
-
[6]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo , author =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[7]
2016 , eprint =
Training Deep Nets with Sublinear Memory Cost , author =. 2016 , eprint =
2016
-
[8]
Tiancheng Chen and Ales Kubicek and Langwen Huang and Torsten Hoefler , title =
-
[9]
Ziheng Cheng and Margalit Glasgow , title =
-
[10]
Approximating Two-Layer Feedforward Networks for Efficient Transformers , booktitle =
R. Approximating Two-Layer Feedforward Networks for Efficient Transformers , booktitle =
-
[11]
CoRR , volume =
Nolan Dey and Bin Claire Zhang and Lorenzo Noci and Mufan Bill Li and Blake Bordelon and Shane Bergsma and Cengiz Pehlevan and Boris Hanin and Joel Hestness , title =. CoRR , volume =
-
[12]
Rusu and Rachita Chhaparia and Yani Donchev and Adhiguna Kuncoro and Marc'Aurelio Ranzato and Arthur Szlam and Jiajun Shen , title =
Arthur Douillard and Qixuan Feng and Andrei A. Rusu and Rachita Chhaparia and Yani Donchev and Adhiguna Kuncoro and Marc'Aurelio Ranzato and Arthur Szlam and Jiajun Shen , title =. CoRR , volume =. 2023 , doi =
2023
-
[13]
Rusu and Adhiguna Kuncoro and Yani Donchev and Rachita Chhaparia and Ionel Gog and Marc'Aurelio Ranzato and Jiajun Shen and Arthur Szlam , title =
Arthur Douillard and Qixuan Feng and Andrei A. Rusu and Adhiguna Kuncoro and Yani Donchev and Rachita Chhaparia and Ionel Gog and Marc'Aurelio Ranzato and Jiajun Shen and Arthur Szlam , title =. CoRR , volume =
-
[14]
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch , journal =
Arthur Douillard and Yanislav Donchev and Keith Rush and Satyen Kale and Zachary Charles and Zachary Garrett and Gabriel Teston and Dave Lacey and Ross McIlroy and Jiajun Shen and Alexandre Ram. Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch , journal =
-
[15]
Dai and Simon Tong and Dmitry Lepikhin and Yuanzhong Xu and Maxim Krikun and Yanqi Zhou and Adams Wei Yu and Orhan Firat and Barret Zoph and Liam Fedus and Maarten P
Nan Du and Yanping Huang and Andrew M. Dai and Simon Tong and Dmitry Lepikhin and Yuanzhong Xu and Maxim Krikun and Yanqi Zhou and Adams Wei Yu and Orhan Firat and Barret Zoph and Liam Fedus and Maarten P. Bosma and Zongwei Zhou and Tao Wang and Yu Emma Wang and Kellie Webster and Marie Pellat and Kevin Robinson and Kathleen S. Meier. GLaM: Efficient Scal...
-
[16]
William Fedus and Barret Zoph and Noam Shazeer , title =. J. Mach. Learn. Res. , volume =
-
[17]
MLSys , publisher =
Trevor Gale and Deepak Narayanan and Cliff Young and Matei Zaharia , title =. MLSys , publisher =
-
[18]
2021 , doi =
Guo, Binbin and Mei, Yuan and Xiao, Danyang and Wu, Weigang , booktitle =. 2021 , doi =
2021
-
[19]
PPoPP , pages =
Jiaao He and Jidong Zhai and Tiago Antunes and Haojie Wang and Fuwen Luo and Shangfeng Shi and Qin Li , title =. PPoPP , pages =
-
[20]
Rae and Oriol Vinyals and Laurent Sifre , title =
Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Eric...
-
[21]
Le and Yonghui Wu and Zhifeng Chen , title =
Yanping Huang and Youlong Cheng and Ankur Bapna and Orhan Firat and Dehao Chen and Mia Xu Chen and HyoukJoong Lee and Jiquan Ngiam and Quoc V. Le and Yonghui Wu and Zhifeng Chen , title =. NeurIPS , pages =
-
[22]
MLSys , publisher =
Changho Hwang and Wei Cui and Yifan Xiong and Ziyue Yang and Ze Liu and Han Hu and Zilong Wang and Rafael Salas and Jithin Jose and Prabhat Ram and Joe Chau and Peng Cheng and Fan Yang and Mao Yang and Yongqiang Xiong , title =. MLSys , publisher =
-
[23]
Shen and Xinchi Qiu and Dongqi Cai and Yan Gao and Nicholas Donald Lane , title =
Alex Iacob and Lorenzo Sani and Meghdad Kurmanji and William F. Shen and Xinchi Qiu and Dongqi Cai and Yan Gao and Nicholas Donald Lane , title =
-
[24]
CoRR , volume =
Alex Iacob and Lorenzo Sani and Mher Safaryan and Paris Giampouras and Samuel Horv. CoRR , volume =
-
[25]
Jacobs and Michael I
Robert A. Jacobs and Michael I. Jordan and Steven J. Nowlan and Geoffrey E. Hinton , title =. Neural Comput. , volume =
-
[26]
CoRR , volume =
Sami Jaghouar and Jack Min Ong and Johannes Hagemann , title =. CoRR , volume =
-
[27]
Jordan and Robert A
Michael I. Jordan and Robert A. Jacobs , title =. Neural Comput. , volume =
-
[28]
Brendan McMahan and Brendan Avent and Aur
Peter Kairouz and H. Brendan McMahan and Brendan Avent and Aur. Advances and Open Problems in Federated Learning , journal =
-
[29]
Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =
Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess and Rewon Child and Scott Gray and Alec Radford and Jeffrey Wu and Dario Amodei , title =. CoRR , volume =
-
[30]
CoRR , volume =
Ahmed Khaled and Satyen Kale and Arthur Douillard and Chi Jin and Rob Fergus and Manzil Zaheer , title =. CoRR , volume =
-
[31]
Scaling Laws for Fine-Grained Mixture of Experts , booktitle =
Jan Ludziejewski and Jakub Krajewski and Kamil Adamczewski and Maciej Pi. Scaling Laws for Fine-Grained Mixture of Experts , booktitle =
-
[32]
Dmitry Lepikhin and HyoukJoong Lee and Yuanzhong Xu and Dehao Chen and Orhan Firat and Yanping Huang and Maxim Krikun and Noam Shazeer and Zhifeng Chen , title =
-
[33]
Mike Lewis and Shruti Bhosale and Tim Dettmers and Naman Goyal and Luke Zettlemoyer , title =
-
[34]
MLSys , publisher =
Tian Li and Anit Kumar Sahu and Manzil Zaheer and Maziar Sanjabi and Ameet Talwalkar and Virginia Smith , title =. MLSys , publisher =
-
[36]
Hwijoon Lim and Juncheol Ye and Sangeetha Abdu Jyothi and Dongsu Han , title =
-
[37]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Xudong Lu and Qi Liu and Yuhui Xu and Aojun Zhou and Siyuan Huang and Bo Zhang and Junchi Yan and Hongsheng Li , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , doi =
2024
-
[38]
DeepSeek-V2:
DeepSeek. DeepSeek-V2:. CoRR , volume =
-
[39]
Ilya Loshchilov and Frank Hutter , title =
-
[40]
CoRR , volume =
Jan Malasnicki and Kamil Ciebiera and Mateusz Borun and Maciej Pi. CoRR , volume =
-
[41]
Communication-Efficient Learning of Deep Networks from Decentralized Data , booktitle =
Brendan McMahan and Eider Moore and Daniel Ramage and Seth Hampson and Blaise Ag. Communication-Efficient Learning of Deep Networks from Decentralized Data , booktitle =
-
[43]
Diamos and Erich Elsen and David Garc
Paulius Micikevicius and Sharan Narang and Jonah Alben and Gregory F. Diamos and Erich Elsen and David Garc. Mixed Precision Training , booktitle =
-
[44]
Oberman and Mohammad Shoeybi and Michael Y
Paulius Micikevicius and Dusan Stosic and Neil Burgess and Marius Cornea and Pradeep Dubey and Richard Grisenthwaite and Sangwon Ha and Alexander Heinecke and Patrick Judd and John Kamalu and Naveen Mellempudi and Stuart F. Oberman and Mohammad Shoeybi and Michael Y. Siu and Hao Wu , title =. CoRR , volume =
-
[45]
Devanur and Gregory R
Deepak Narayanan and Aaron Harlap and Amar Phanishayee and Vivek Seshadri and Nikhil R. Devanur and Gregory R. Ganger and Phillip B. Gibbons and Matei Zaharia , title =
-
[46]
Pitch Patarasuk and Xin Yuan , title =. J. Parallel Distributed Comput. , volume =
-
[47]
CoRR , volume =
Ji Qi and WenPeng Zhu and Li Li and Ming Wu and YingJun Wu and Wu He and Xun Gao and Jason Zeng and Michael Heinrich , title =. CoRR , volume =
-
[48]
International Conference on Computational Science , series =
Rolf Rabenseifner , title =. International Conference on Computational Science , series =
-
[49]
Samyam Rajbhandari and Jeff Rasley and Olatunji Ruwase and Yuxiong He , title =
-
[50]
Samyam Rajbhandari and Conglong Li and Zhewei Yao and Minjia Zhang and Reza Yazdani Aminabadi and Ammar Ahmad Awan and Jeff Rasley and Yuxiong He , title =
-
[51]
Reddi and Zachary Charles and Manzil Zaheer and Zachary Garrett and Keith Rush and Jakub Kone
Sashank J. Reddi and Zachary Charles and Manzil Zaheer and Zachary Garrett and Keith Rush and Jakub Kone. Adaptive Federated Optimization , booktitle =
-
[52]
CoRR , volume =
Matthias Reisser and Christos Louizos and Efstratios Gavves and Max Welling , title =. CoRR , volume =
-
[53]
Scaling Vision with Sparse Mixture of Experts , booktitle =
Carlos Riquelme and Joan Puigcerver and Basil Mustafa and Maxim Neumann and Rodolphe Jenatton and Andr. Scaling Vision with Sparse Mixture of Experts , booktitle =
-
[54]
NeurIPS , pages =
Stephen Roller and Sainbayar Sukhbaatar and Arthur Szlam and Jason Weston , title =. NeurIPS , pages =
-
[55]
Advances in Neural Information Processing Systems , volume =
Towards Crowdsourced Training of Large Neural Networks Using Decentralized Mixture-of-Experts , author =. Advances in Neural Information Processing Systems , volume =. 2020 , doi =
2020
-
[56]
Proceedings of the 40th International Conference on Machine Learning , series =
Max Ryabinin and Tim Dettmers and Michael Diskin and Alexander Borzunov , title =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , url =
2023
-
[57]
Communication Efficient
Amir Sarfi and Benjamin Th. Communication Efficient. CoRR , volume =. 2025 , doi =
2025
-
[58]
Lane , booktitle =
Lorenzo Sani and Alex Iacob and Zeyu Cao and Royson Lee and Bill Marino and Yan Gao and Wanru Zhao and Dongqi Cai and Zexi Li and Xinchi Qiu and Nicholas D. Lane , booktitle =. Photon: Federated. 2025 , url =
2025
-
[59]
International Workshop on Federated Foundation Models in Conjunction with NeurIPS 2024 , year =
The Future of Large Language Model Pre-training is Federated , author =. International Workshop on Federated Foundation Models in Conjunction with NeurIPS 2024 , year =
2024
-
[60]
Le and Geoffrey E
Noam Shazeer and Azalia Mirhoseini and Krzysztof Maziarz and Andy Davis and Quoc V. Le and Geoffrey E. Hinton and Jeff Dean , title =
-
[61]
CoRR , volume =
Mohammad Shoeybi and Mostofa Patwary and Raul Puri and Patrick LeGresley and Jared Casper and Bryan Catanzaro , title =. CoRR , volume =
-
[62]
Proceedings of the 15th ACM International Conference on Future and Sustainable Energy Systems , pages =
Advancing accuracy in energy forecasting using mixture-of-experts and federated learning , author =. Proceedings of the 15th ACM International Conference on Future and Sustainable Energy Systems , pages =
-
[63]
Stich , title =
Sebastian U. Stich , title =
-
[64]
ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning , year =
Revisiting Sparse Mixture of Experts for Resource-adaptive Federated Fine-tuning Foundation Models , author =. ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning , year =
2025
-
[65]
Gomez and Lukasz Kaiser and Illia Polosukhin , title =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =
-
[66]
Patterson , title =
Samuel Williams and Andrew Waterman and David A. Patterson , title =. Commun
-
[67]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
dFLMoE: Decentralized Federated Learning via Mixture of Experts for Medical Data Analysis , author =. Proceedings of the Computer Vision and Pattern Recognition Conference , pages =
-
[68]
Hu , title =
Greg Yang and Edward J. Hu , title =
-
[69]
Specialized Federated Learning Using a Mixture of Experts , journal =
Edvin Listo Zec and Olof Mogren and John Martinsson and Leon Ren. Specialized Federated Learning Using a Mixture of Experts , journal =. 2020 , doi =
2020
-
[70]
Mingshu Zhai and Jiaao He and Zixuan Ma and Zan Zong and Runqing Zhang and Jidong Zhai , title =
-
[71]
Zhao and Andrew M
Yanqi Zhou and Tao Lei and Hanxiao Liu and Nan Du and Yanping Huang and Vincent Y. Zhao and Andrew M. Dai and Zhifeng Chen and Quoc V. Le and James Laudon , title =. NeurIPS , year =
-
[72]
Padmanabhan , title =
Palak and Tella Rajashekhar Reddy and Bhaskar Kataria and Rohan Gandhi and Karan Tandon and Debopam Bhattacherjee and Venkata N. Padmanabhan , title =. CoRR , volume =. 2024 , doi =
2024
-
[73]
CoRR , volume =
Gheorghe Comanici and Eric Bieber and Mike Schaekermann and Ice Pasupat and Noveen Sachdeva and others , title =. CoRR , volume =. 2025 , doi =
2025
-
[74]
Jeonghoon Kim and Byeongchan Lee and Cheonbok Park and Yeontaek Oh and Beomjun Kim and Taehwan Yoo and Seongjin Shin and Dongyoon Han and Jinwoo Shin and Kang Min Yoo , title =
-
[75]
2025 , url=
Could decentralized training solve AI’s power problem? , author=. 2025 , url=
2025
-
[76]
Inside the world’s most powerful AI Datacenter , url=
Guthrie, Scott , year=. Inside the world’s most powerful AI Datacenter , url=. Official Microsoft Blog , publisher=
-
[77]
Jianlin Su and Murtadha H. M. Ahmed and Yu Lu and Shengfeng Pan and Wen Bo and Yunfeng Liu , title =. Neurocomputing , volume =
-
[78]
2025 , journal=
Kimi K2: Open Agentic Intelligence , author=. 2025 , journal=
2025
-
[79]
CoRR , volume =
OpenAI , title =. CoRR , volume =
-
[80]
2024 , url =
Ben Allal, Loubna and Lozhkov, Anton and Penedo, Guilherme and Wolf, Thomas and von Werra, Leandro , title =. 2024 , url =
2024
-
[81]
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention , booktitle =
R. SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention , booktitle =
-
[82]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , volume =. 2020 , url =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.