PorTEXTO: A European Portuguese Benchmark for Visual Text Extraction
Pith reviewed 2026-07-02 22:15 UTC · model grok-4.3
The pith
PorTEXTO shows specialized multilingual data improves European Portuguese OCR more than larger models or higher resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
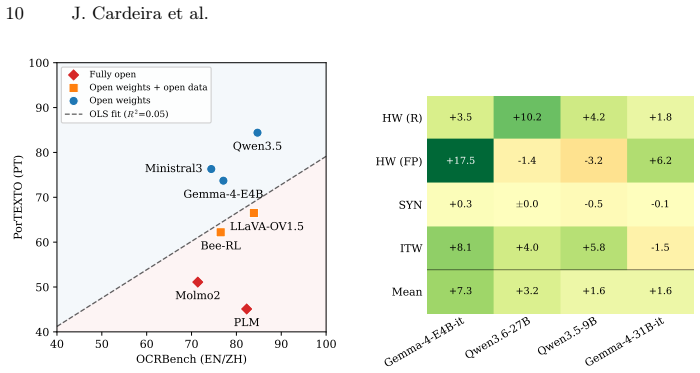
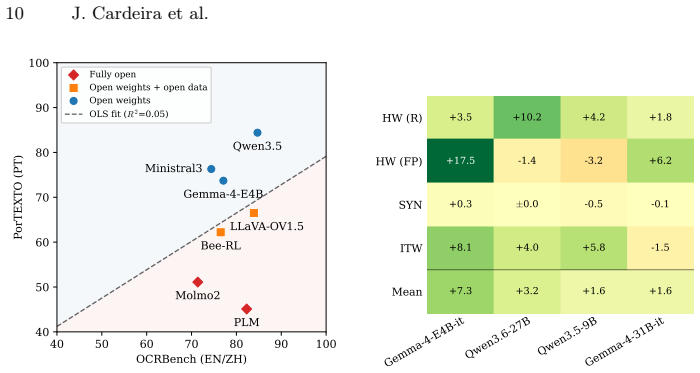
PorTEXTO is presented as the first benchmark for contemporary European Portuguese visual text extraction. An annotation process that starts with frontier large vision-language model transcriptions and adds exhaustive native-speaker review supplies the ground truth. Evaluation across models reveals a sharp drop from synthetic to real samples and identifies specialized multilingual data as the stronger driver of pt-PT performance compared with model size or resolution budget, which motivates the release of open pt-PT OCR resources.
What carries the argument
The PorTEXTO benchmark dataset, which supplies paired real and synthetic pt-PT images for measuring visual text extraction accuracy.
If this is right
- Specialized multilingual training data yields higher accuracy on pt-PT text than equivalent gains in model size.
- Resolution increases alone do not close the performance gap observed on real pt-PT samples.
- Synthetic-only training hides limitations that appear once models encounter authentic images.
- Open release of pt-PT OCR resources follows directly from the observed data advantage.
Where Pith is reading between the lines
- The same data-over-scale pattern may appear in benchmarks for other underrepresented languages if similar evaluation splits are used.
- The LVLM-plus-native-review annotation method could be reused to create comparable benchmarks without requiring large new annotation teams.
- Document-processing applications in Portuguese-speaking regions stand to gain from models tuned on the released resources.
Load-bearing premise
The annotation pipeline that combines frontier LVLM transcriptions with exhaustive native-speaker review produces ground truth accurate enough for reliable model comparisons.
What would settle it
A model trained without specialized multilingual data but with substantially larger size or resolution achieving higher accuracy on PorTEXTO real-world samples than models that use such data would challenge the central claim.
Figures




read the original abstract
European Portuguese (pt-PT) is largely absent from OCR benchmarks, which skew toward high-resource languages. The few benchmarks that cover pt-PT focus on historical artifacts and literature. This work addresses modern OCR applications, introducing PorTEXTO, the first benchmark for contemporary and culturally relevant pt-PT visual text extraction. To ascertain quality, we employ an annotation pipeline combining transcriptions from a frontier LVLM with exhaustive review by native speakers. We observe a sharp performance drop from synthetic to real world samples in most models, and find that, currently, specialized multilingual data is a better driver for pt-PT performance than model size or resolution budget, motivating the release of open pt-PT OCR resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PorTEXTO, the first benchmark for contemporary European Portuguese (pt-PT) visual text extraction in modern OCR applications. It employs an annotation pipeline of frontier LVLM transcriptions followed by exhaustive native-speaker review, reports a sharp performance drop from synthetic to real-world samples across models, and concludes that specialized multilingual data currently drives pt-PT performance more effectively than model size or resolution budget, motivating the release of open pt-PT OCR resources.
Significance. If the ground-truth quality can be quantitatively validated, the work would usefully demonstrate the value of language-specific data over scaling for low-resource languages in vision-language tasks and provide a needed modern benchmark to complement existing historical pt-PT resources. The explicit release of open resources is a concrete positive contribution.
major comments (2)
- [Annotation Pipeline] Annotation Pipeline section: the pipeline is asserted to produce high-quality labels via LVLM transcription plus native-speaker review, yet no quantitative validation is reported (inter-annotator agreement, sampled error rates, or disagreement-resolution protocol). Because the central claims rest on measured gaps between synthetic and real samples and on the relative importance of data versus scale, the absence of these checks is load-bearing.
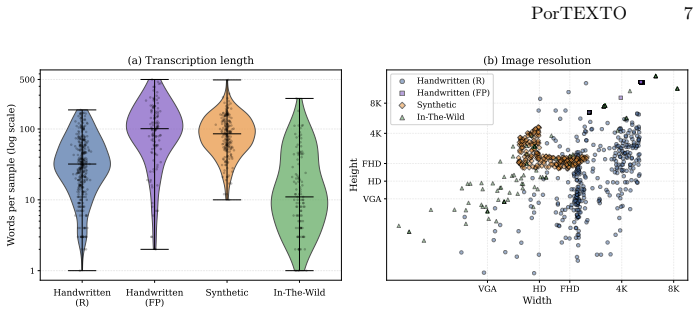
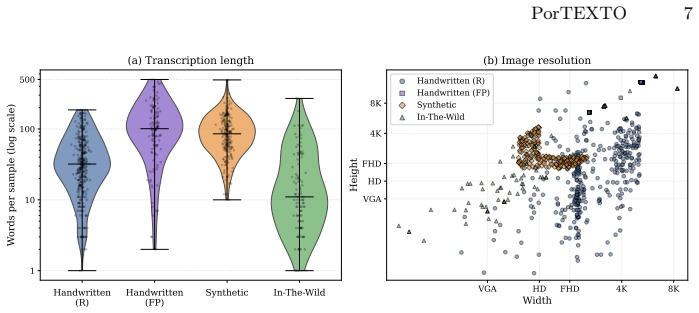
- [Results and Evaluation] Results and Evaluation sections: the abstract states a performance drop and the superiority of specialized multilingual data, but the manuscript provides neither dataset statistics (e.g., number of real vs. synthetic samples, character distributions) nor detailed ablation tables separating data specialization from model size and resolution. Without these, the comparative claim cannot be verified.
minor comments (1)
- [Figures] Figure captions and axis labels could more explicitly distinguish synthetic from real-world test sets to aid quick interpretation of the reported drop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional quantitative support would strengthen the manuscript. We address each point below and commit to revisions that incorporate the requested elements.
read point-by-point responses
-
Referee: [Annotation Pipeline] Annotation Pipeline section: the pipeline is asserted to produce high-quality labels via LVLM transcription plus native-speaker review, yet no quantitative validation is reported (inter-annotator agreement, sampled error rates, or disagreement-resolution protocol). Because the central claims rest on measured gaps between synthetic and real samples and on the relative importance of data versus scale, the absence of these checks is load-bearing.
Authors: We agree that the absence of quantitative validation metrics is a limitation. Although the pipeline combines frontier LVLM transcriptions with exhaustive native-speaker review, we will add inter-annotator agreement scores on a sampled subset of annotations, sampled error rates, and a description of the disagreement-resolution protocol to the revised Annotation Pipeline section. revision: yes
-
Referee: [Results and Evaluation] Results and Evaluation sections: the abstract states a performance drop and the superiority of specialized multilingual data, but the manuscript provides neither dataset statistics (e.g., number of real vs. synthetic samples, character distributions) nor detailed ablation tables separating data specialization from model size and resolution. Without these, the comparative claim cannot be verified.
Authors: We acknowledge that explicit dataset statistics and detailed ablations are required for full verifiability of the claims. The manuscript contains comparative results, but we will add a dedicated table reporting the number of real versus synthetic samples, character distributions, and expanded ablation tables that isolate the effects of specialized multilingual data from model size and resolution in the revised Results and Evaluation sections. revision: yes
Circularity Check
No significant circularity; empirical benchmark creation and evaluation are self-contained
full rationale
The paper introduces PorTEXTO as a new benchmark for pt-PT visual text extraction, describes an annotation pipeline (LVLM transcription plus native-speaker review), and reports empirical performance comparisons across models on synthetic vs. real samples. The central claim—that specialized multilingual data outperforms model size or resolution—is presented as an observation from these measurements rather than a derivation. No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, uniqueness theorems, or ansatzes appear in the provided abstract or described structure. The evaluation chain consists of direct metric computation on newly created data and does not reduce to its inputs by construction. Absence of inter-annotator metrics is a potential evidence-quality concern but does not constitute circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The combination of LVLM-generated transcriptions and native speaker review yields accurate annotations
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., et al.: LLaVA-OneVision-1.5: Fully open framework for democratized mul- timodal training. arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: ICCV (2019)
Biten, A.F., et al.: Scene text visual question answering. In: ICCV (2019)
2019
-
[3]
Advances in Neural Information Processing Systems (2026)
Cho, J.H., et al.: Perceptionlm: Open-access data and models for detailed visual understanding. Advances in Neural Information Processing Systems (2026)
2026
-
[4]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Clark, C., et al.: Molmo2: Open weights and data for vision-language models with video understanding and grounding. arXiv:2601.10611 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Deshmukh, A.S., et al.: Nvidia nemotron nano v2 vl. arXiv:2511.03929 (2025)
-
[6]
https://deepmind.google/models/ model-cards/gemini-3-1-pro/ (2026)
Google DeepMind: Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/ (2026)
2026
-
[7]
https://ai.google.dev/gemma/docs/ core/model_card_4 (2026)
Google DeepMind: Gemma 4 model card. https://ai.google.dev/gemma/docs/ core/model_card_4 (2026)
2026
-
[8]
Hong, W., et al.: Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv:2507.01006 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Huang, A., et al.: Step3-vl-10b technical report. arXiv:2601.09668 (2026)
-
[10]
In: ECCV (2022)
Kim, G., et al.: OCR-free document understanding transformer. In: ECCV (2022)
2022
-
[11]
In: MT (2005), https://www.statmt.org/europarl/
Koehn, P.: Europarl: A parallel corpus for statistical machine translation. In: MT (2005), https://www.statmt.org/europarl/
2005
-
[12]
IJCV (2020)
Kuznetsova, A., et al.: The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. IJCV (2020)
2020
-
[13]
Liu, A.H., et al.: Ministral 3. arXiv:2601.08584 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
NVIDIA, https://huggingface.co/blog/nvidia/nemotron-ocr-v2 (2026)
Liu, B., et al.: Building a fast multilingual OCR model with synthetic data. NVIDIA, https://huggingface.co/blog/nvidia/nemotron-ocr-v2 (2026)
2026
-
[15]
Science China Information Sciences (2024)
Liu, Y., et al.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences (2024)
2024
-
[16]
In: CVPR (2019)
Marino, K., et al.: OK-VQA: A visual question answering benchmark requiring external knowledge. In: CVPR (2019)
2019
-
[17]
In: WACV (2021)
Mathew, M., et al.: DocVQA: A dataset for VQA on document images. In: WACV (2021)
2021
-
[18]
In: WACV (2022) 12 J
Mathew, M., et al.: InfographicVQA. In: WACV (2022) 12 J. Cardeira et al
2022
-
[19]
Journal of Imaging (2025)
Matos, A., et al.: iForal: Automated handwritten text transcription for historical medieval manuscripts. Journal of Imaging (2025)
2025
-
[20]
Hugging Face, https://huggingface.co/ datasets/mazafard/portuguese-ocr-dataset (2025)
mazafard: Portuguese OCR dataset. Hugging Face, https://huggingface.co/ datasets/mazafard/portuguese-ocr-dataset (2025)
2025
-
[21]
In: ICDAR (2024)
Neto, A.F.S., et al.: BRESSAY: A Brazilian Portuguese dataset for offline hand- written text recognition. In: ICDAR (2024)
2024
-
[22]
In: SIGIR (2021)
de Oliveira, L.L., et al.: REGIS: A test collection for geoscientific documents in Portuguese. In: SIGIR (2021)
2021
-
[23]
In: CIKM (2025)
Osório, T.F., et al.: Portuguese post-OCR resources for text optimisation. In: CIKM (2025)
2025
-
[24]
In: CVPR (2025)
Ouyang, L., et al.: OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive annotations. In: CVPR (2025)
2025
-
[25]
In: ACL (2002)
Papineni, K., et al.: BLEU: a method for automatic evaluation of machine trans- lation. In: ACL (2002)
2002
-
[26]
INESC TEC, https://episa
Project, E.: Typewritten digital representations of Portuguese cultural heritage documents from the 20th century (EPISA dataset). INESC TEC, https://episa. inesctec.pt/outcomes/ (2022)
2022
-
[27]
https://qwen.ai/blog? id=qwen3.5 (2026)
Qwen Team: Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog? id=qwen3.5 (2026)
2026
-
[28]
https: //qwen.ai/blog?id=qwen3.6-27b (2026)
Qwen Team: Qwen3.6-27B: Flagship-level coding in a 27B dense model. https: //qwen.ai/blog?id=qwen3.6-27b (2026)
2026
-
[29]
In: ICDAR (2023)
Santos, M.K., et al.: ESTER-Pt: An evaluation suite for TExt recognition in Por- tuguese. In: ICDAR (2023)
2023
-
[30]
In: CVPR (2019)
Singh, A., et al.: Towards VQA models that can read. In: CVPR (2019)
2019
-
[31]
Smart, D.S., et al.: Encoder vs decoder: Comparative analysis of encoder and decoder language models on multilingual nlu tasks. arXiv:2406.13469 (2024)
-
[32]
In: ACL Findings (2025)
Tang, J., et al.: MTVQA: Benchmarking multilingual text-centric visual question answering. In: ACL Findings (2025)
2025
-
[33]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., et al.: Internvl3. 5: Advancing open-source multimodal models in ver- satility, reasoning, and efficiency. arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
arXiv preprint arXiv:2601.20552 (2026)
Wei, H., et al.: Deepseek-ocr 2: Visual causal flow. arXiv:2601.20552 (2026)
-
[35]
HuggingFace Datasets (2023), https://huggingface.co/datasets/wikimedia/wikipedia
Wikimedia Foundation: Wikimedia wikipedia (20231101.pt). HuggingFace Datasets (2023), https://huggingface.co/datasets/wikimedia/wikipedia
2023
-
[36]
In: ICCV (2025)
Yang, Z., et al.: CC-OCR: A comprehensive and challenging OCR benchmark for evaluating large multimodal models in literacy. In: ICCV (2025)
2025
-
[37]
In: NAACL (2025)
Zhang, K., et al.: Lmms-eval: Reality check on the evaluation of large multimodal models. In: NAACL (2025)
2025
-
[38]
Zhang, Y., et al.: Bee: A high-quality corpus and full-stack suite to unlock advanced fully open MLLMs. arXiv:2510.13795 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.