Smoothness-Based Derandomization of PAC-Bayes Bounds
Pith reviewed 2026-06-29 05:01 UTC · model grok-4.3
The pith
The generalization cost from Gibbs to deterministic predictors in PAC-Bayes is bounded by the Jensen gap class via its Rademacher complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Passing from the Gibbs predictor to the deterministic predictor at the posterior mean has a precise cost given by the generalization gap of the Jensen gap class. Controlling this class through its Rademacher complexity yields bounds for deterministic predictors that involve flatness quantities expressed in terms of parameter Jacobians and Hessians of the score map. The framework applies to both bounded and unbounded smooth loss functions and specializes to linear predictors and smooth neural networks.
What carries the argument
Jensen gap class, whose Rademacher complexity is bounded using smoothness properties expressed as Jacobians and Hessians of the score map to quantify the derandomization cost.
If this is right
- Deterministic predictors obtain high-probability generalization bounds from PAC-Bayes that explicitly involve flatness measured by Jacobians and Hessians.
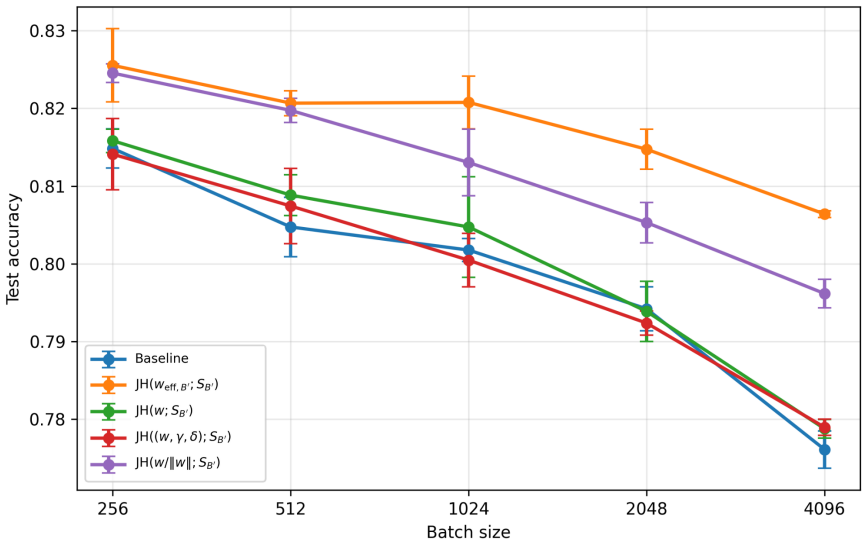
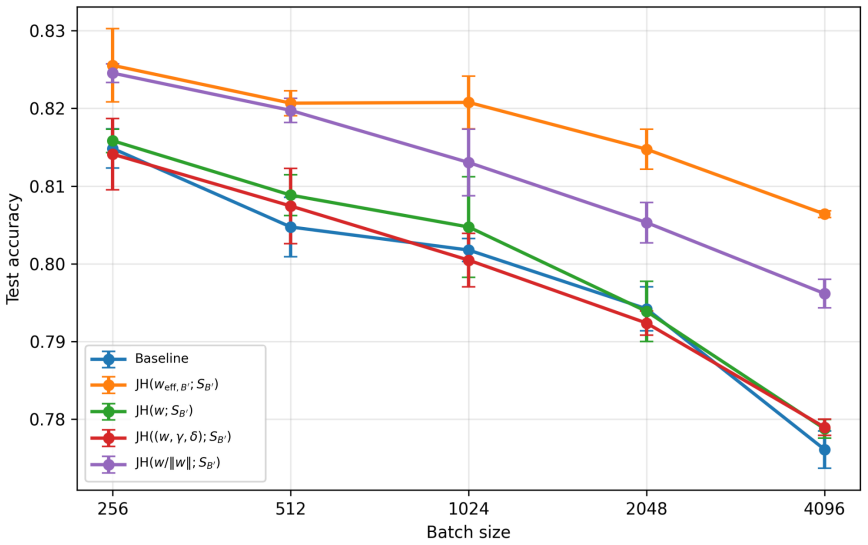
- A regularizer based on the Jacobian and Hessian quantities of the score map can be added to training and computed for BatchNorm networks after folding the transformation into adjacent weights.
- The same smoothness-based control applies to both bounded and unbounded loss functions.
- Specialized bounds exist for linear predictors and for smooth neural networks.
Where Pith is reading between the lines
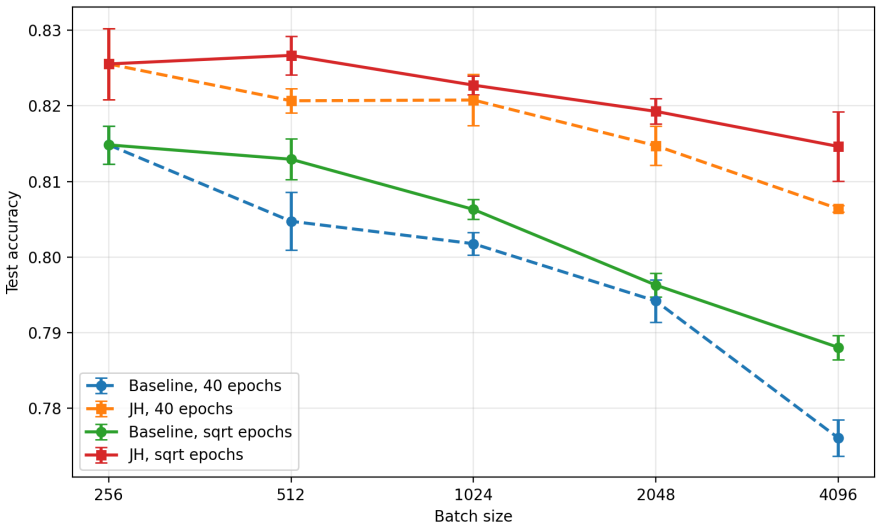
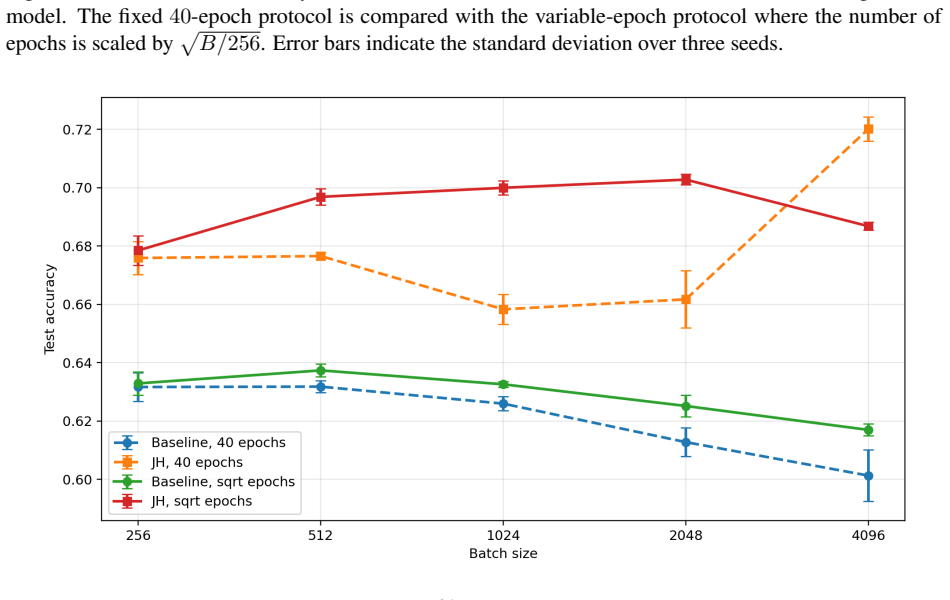
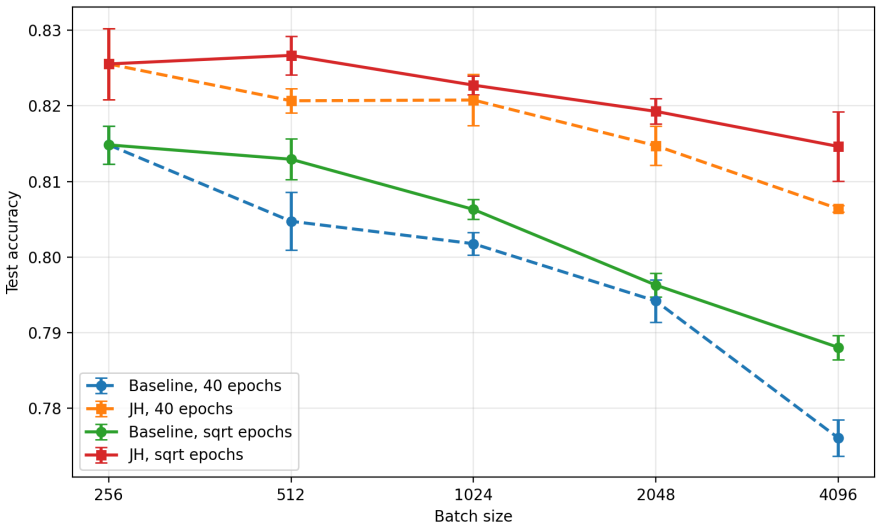
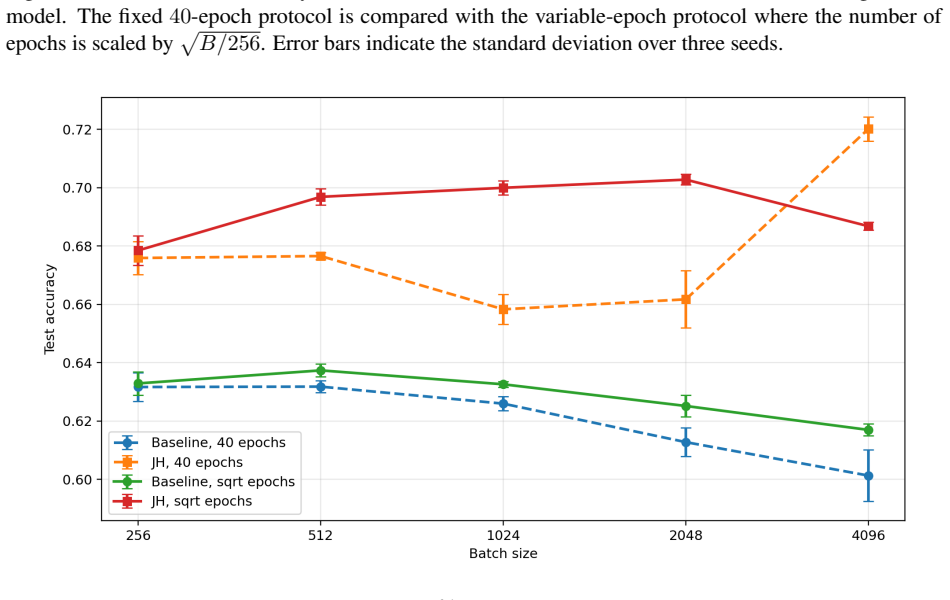
- The regularizer could be evaluated on datasets other than CIFAR-10 to test whether the flatness terms improve generalization when batch size changes.
- The Jacobian-Hessian flatness measures may relate to existing optimization-landscape analyses that track curvature along parameter trajectories.
- The framework might be extended by replacing Rademacher complexity with other complexity measures when smoothness no longer holds.
Load-bearing premise
The Rademacher complexity of the Jensen gap class can be controlled using smoothness properties of the loss and predictor class expressed via Jacobians and Hessians of the score map.
What would settle it
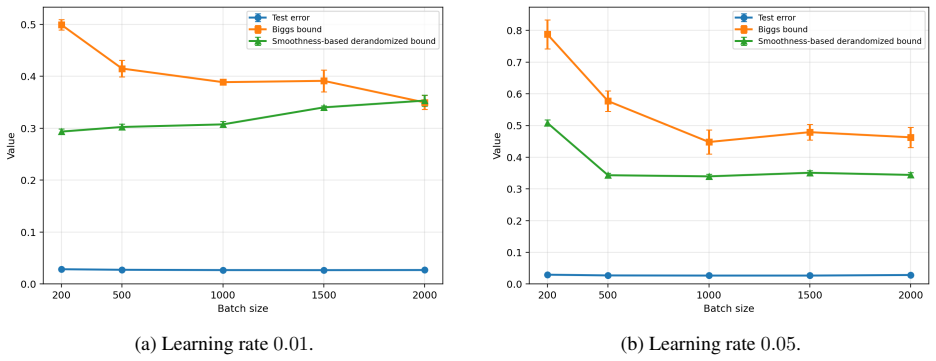
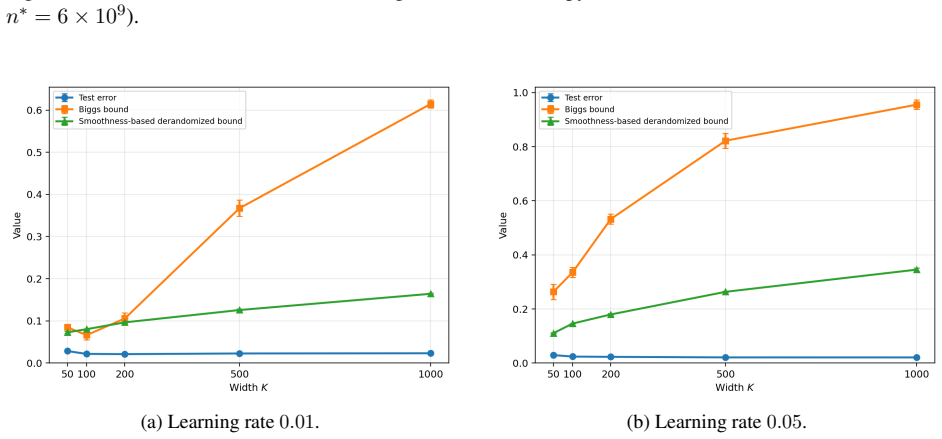
Train a linear predictor on a dataset where the loss is smooth, compute both the actual generalization gap of the deterministic predictor and the bound obtained from the Jensen gap class, then check whether the bound fails to hold when the smoothness parameters are deliberately increased beyond the regime assumed in the derivation.
Figures
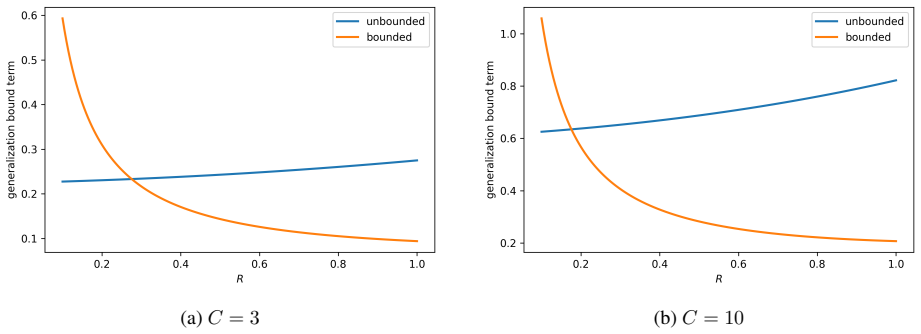
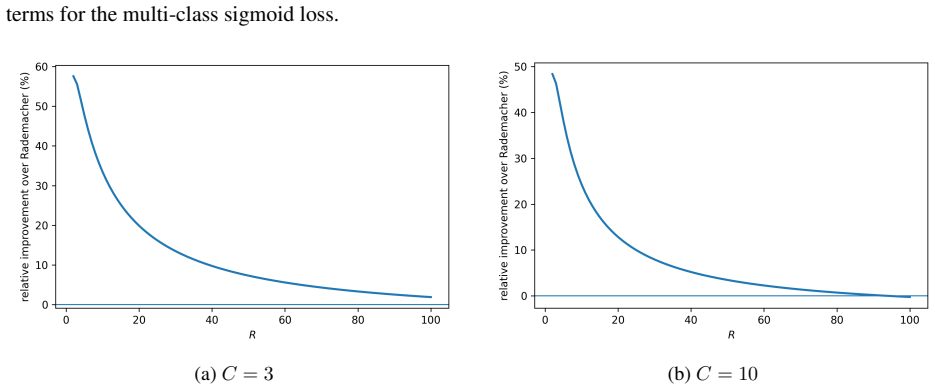
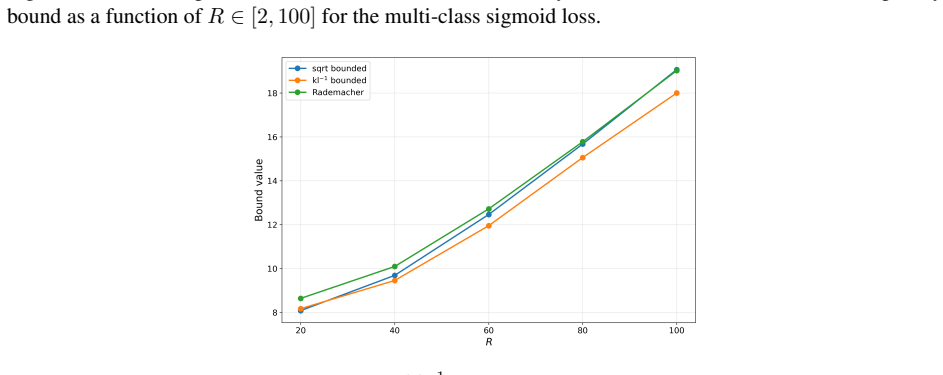
read the original abstract
We study PAC-Bayes derandomization for smooth loss functions. Our goal is to obtain generalization bounds that hold with high probability for deterministic predictors by exploiting smoothness properties of both the loss and the predictor class. We show that passing from the Gibbs predictor to the deterministic predictor at the posterior mean has a precise cost, given by the generalization gap of the Jensen gap class. We control this class through its Rademacher complexity, leading to bounds for deterministic predictors that involve flatness quantities expressed in terms of parameter Jacobians and Hessians of the score map. The framework applies to both bounded and unbounded smooth loss functions, and we specialize the results to linear predictors and smooth neural networks. Finally, the Jacobian and Hessian quantities appearing in the theory motivate a practical regularizer. For BatchNorm networks, we compute this regularizer with respect to effective BatchNorm weights obtained by folding the BatchNorm transformation into the adjacent affine weights. Experiments on CIFAR-10 illustrate the behavior of this regularizer under different batch sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a smoothness-based derandomization of PAC-Bayes bounds for smooth loss functions. It shows that the cost of transitioning from the Gibbs predictor to the deterministic posterior-mean predictor is the generalization gap of the Jensen gap class, which is then bounded using its Rademacher complexity controlled by smoothness properties of the loss and the score map (via Jacobians and Hessians). The framework is specialized to linear predictors and smooth neural networks, motivates a practical regularizer (with BatchNorm folding), and includes experiments on CIFAR-10.
Significance. If the technical derivations hold, this provides a rigorous path to deterministic generalization bounds that incorporate flatness measures without circularity. It extends PAC-Bayes theory in a standard yet useful way and includes a practical application as a regularizer. The handling of unbounded losses and the specialization are notable.
minor comments (1)
- [Abstract] The abstract clearly outlines the contributions but would benefit from a brief indication of the key mathematical objects (e.g., the explicit form of the Rademacher bound or the smoothness assumptions) to better convey the technical content to readers.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of its contributions to PAC-Bayes derandomization via smoothness, and recommendation for minor revision. We appreciate the constructive feedback and will prepare a revised version accordingly.
Circularity Check
No significant circularity in derivation chain
full rationale
The derivation starts from standard PAC-Bayes on the Gibbs predictor, identifies the exact derandomization cost as the generalization gap of the Jensen gap class, and bounds that class via its Rademacher complexity using smoothness of the loss and score map (expressed through Jacobians and Hessians). These steps invoke external complexity tools rather than fitting parameters to the target data or reducing the final bound to a self-citation chain; the resulting flatness quantities are consequences of the analysis, not inputs renamed as outputs. The framework remains self-contained against external benchmarks with no load-bearing self-definition or fitted-input prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Fergus Immanuel Biggs and Benjamin Guedj
URL https: //arxiv.org/abs/2002.09956. Fergus Immanuel Biggs and Benjamin Guedj. On margins and derandomization in pac-bayes. InProceedings of The 25th International Conference on Artificial Intelligence and Statistics (AISTATS),
-
[3]
doi: 10.1214/074921707000000391. Eugenio Clerico, Tyler Farghly, George Deligiannidis, Benjamin Guedj, and Arnaud Doucet. Generalisation under gradient descent via deterministic PAC-Bayes. In Gautam Kamath and Po-Ling Loh, editors, Proceedings of The 36th International Conference on Algorithmic Learning Theory, volume 272 of Proceedings of Machine Learnin...
-
[5]
URL https://arxiv.org/abs/ 2212.00311. Gintare Karolina Dziugaite, Alexandre Drouin, Brady Neal, Nitarshan Rajkumar, Ethan Caballero, Linbo Wang, Ioannis Mitliagkas, and Daniel M. Roy. In search of robust measures of generalization. InAdvances in Neural Information Processing Systems, volume 33, pages 11723–11733. Curran Associates, Inc.,
-
[6]
ACM. doi: 10.1145/1553374.1553419. Pascal Germain, Alexandre Lacasse, François Laviolette, Mario Marchand, and Jean-Francis Roy. Risk bounds for the majority vote: From a pac-bayesian analysis to a learning algorithm.Journal of Machine Learning Research, 16:787–860,
-
[7]
Pac-bayesian theory meets bayesian inference
Pascal Germain, Francis Bach, Alexandre Lacoste, and Simon Lacoste-Julien. Pac-bayesian theory meets bayesian inference. InAdvances in Neural Information Processing Sys- tems 29 (NeurIPS 2016), pages 1–9,
2016
-
[8]
doi: 10.1016/j.neucom.2014.09.081
ISSN 0925-2312. doi: 10.1016/j.neucom.2014.09.081. URL https://doi.org/10.1016/j.neucom.2014.09.081. Maxime Haddouche, Benjamin Guedj, Omar Rivasplata, and John Shawe-Taylor. Pac-bayes unleashed: Generalisation bounds with unbounded losses.arXiv preprint arXiv:2006.07279,
-
[10]
Alexandre Lemire Paquin, Brahim Chaib-Draa, and Philippe Giguère
URL https://arxiv.org/ abs/2510.25569. Alexandre Lemire Paquin, Brahim Chaib-Draa, and Philippe Giguère. Symmetrization of loss functions for robust training of neural networks in the presence of noisy labels,
-
[11]
URL https://arxiv.org/ abs/2605.20347. Gaël Letarte, Pascal Germain, Benjamin Guedj, and François Laviolette. Dichotomize and generalize: PAC-Bayesian binary activated deep neural networks. InAdvances in Neural Information Processing Systems 32, pages 6869–6879. Curran Associates, Inc.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
47 Yucong Liu, Shixing Yu, and Tong Lin. Regularizing deep neural networks with stochastic estimators of Hessian trace.arXiv preprint arXiv:2208.05924,
-
[14]
URLhttp://arxiv.org/abs/1605.00251. David A. McAllester. Some PAC-bayesian theorems. InProceedings of the Eleventh Annual Conference on Computational Learning Theory, pages 230–234. Association for Computing Machinery,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
doi: 10.1145/279943.279989. David A. McAllester. Pac-bayesian model averaging. InProceedings of the 12th Annual Conference on Computational Learning Theory (COLT), pages 164–170. ACM,
-
[16]
A White Paper on Neural Network Quantization
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yelysei Bondarenko, Mart van Baalen, and Tijmen Blankevoort. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
doi: 10.1109/ ICASSP39728.2021.9413771. Omar Rivasplata, Ilja Kuzborskij, Csaba Szepesvári, and John Shawe-Taylor. PAC-Bayes analysis beyond the usual bounds. InAdvances in Neural Information Processing Systems, volume 33,
-
[18]
URL https://arxiv.org/abs/2006.13057. Matthias Seeger. PAC-bayesian generalisation error bounds for gaussian process classification.Journal of Machine Learning Research, 3:233–269, October
-
[19]
Neta Shoham, Tomer Avidor, and Nadav Israel
ISBN 9781107057135. Neta Shoham, Tomer Avidor, and Nadav Israel. An exploration into why output regularization mitigates label noise.arXiv preprint arXiv:2104.12477,
-
[20]
doi: 10.1109/TSP.2017. 2708039. 48 Michel Talagrand.The Generic Chaining: Upper and Lower Bounds of Stochastic Processes. Springer Monographs in Mathematics. Springer, Berlin, Heidelberg,
-
[21]
Gradient Regularization Improves Accuracy of Discriminative Models
URL https: //proceedings.mlr.press/v119/tsuzuku20a.html. Dániel Varga, Adrián Csiszárik, and Zsolt Zombori. Gradient regularization improves accuracy of discrimina- tive models.arXiv preprint arXiv:1712.09936,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Mingyang Yi, Huishuai Zhang, Wei Chen, Zhi-Ming Ma, and Tie-Yan Liu
URL https://arxiv.org/ abs/2102.08649. Mingyang Yi, Huishuai Zhang, Wei Chen, Zhi-Ming Ma, and Tie-Yan Liu. BN-invariant sharpness regularizes the training model to better generalization. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, pages 4164–4170. International Joint Conferences on Artificial Intelligence...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.