Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
Pith reviewed 2026-06-26 21:01 UTC · model grok-4.3
The pith
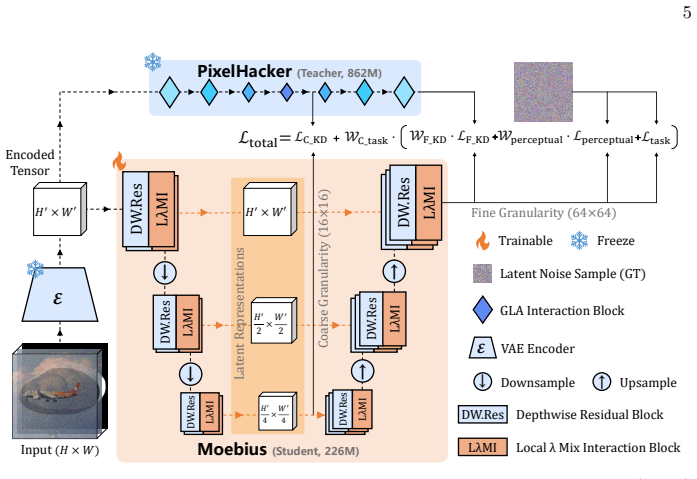
Moebius uses Local-λ Mix Interaction blocks and latent-space distillation to match 11.9B-parameter inpainting quality with a 0.22B model and 15x faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
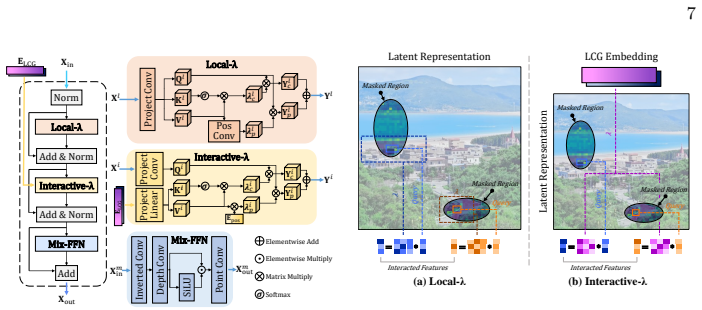
By reconstructing the diffusion backbone with the Local-λ Mix Interaction (LλMI) block—composed of Local-λ and Interactive-λ modules that compress spatial contexts and global semantic priors into fixed-size linear matrices—Moebius preserves complex latent interactions. When combined with an adaptive multi-granularity distillation strategy that balances gradient-based losses strictly inside the latent space, the 0.22B model achieves inpainting quality that rivals or surpasses the 11.9B FLUX.1-Fill-Dev on natural and portrait benchmarks while delivering more than 15× faster total inference time.
What carries the argument
The Local-λ Mix Interaction (LλMI) block, which uses Local-λ and Interactive-λ modules to summarize spatial contexts and global semantic priors into fixed-size linear matrices while preserving latent interactions for inpainting.
If this is right
- High-fidelity inpainting becomes practical on devices with limited compute and memory.
- Task-specific specialists can deliver performance comparable to much larger generalist models in targeted domains.
- Latent-space multi-granularity distillation enables high-fidelity alignment without pixel-space decoding costs.
- The efficiency gains set a new standard that other inpainting systems can be measured against.
Where Pith is reading between the lines
- The matrix-summarization technique could extend to other diffusion tasks such as outpainting or conditional generation.
- Fixed-size linear representations may reduce memory footprint in additional vision backbones beyond inpainting.
- The approach suggests a route toward even smaller models if the distillation balance can be further tuned.
Load-bearing premise
The Local-λ and Interactive-λ modules can compress spatial and semantic information into fixed-size linear matrices without losing the complex latent interactions required for high-fidelity inpainting.
What would settle it
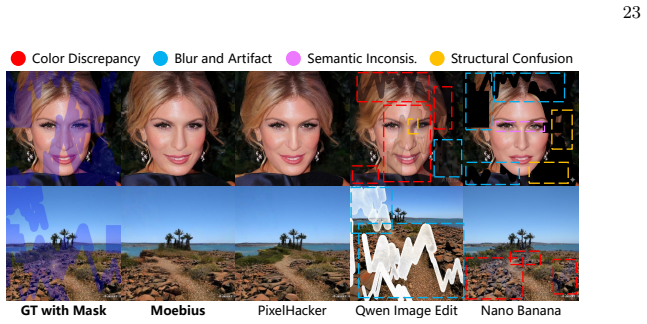
Side-by-side visual or metric evaluation on the same natural and portrait inpainting benchmarks where Moebius produces visibly lower quality or lower scores than FLUX.1-Fill-Dev despite the reported parameter count and speed.
Figures







read the original abstract
While 10B-level industrial foundation models have pushed the boundaries of image inpainting, their prohibitive computational costs severely hinder practical deployment. Constructing a highly optimized task-specific specialist offers a promising solution; however, extreme structural compression inevitably triggers a severe representation bottleneck. To conquer this, we propose Moebius, a highly efficient lightweight inpainting framework. We systematically reconstruct the diffusion backbone by introducing the Local-$\lambda$ Mix Interaction ($L\lambda MI$) block. Comprising Local-$\lambda$ and Interactive-$\lambda$ modules, it elegantly summarizes spatial contexts and global semantic priors into fixed-size linear matrices, preserving complex latent interactions while drastically shedding parameters. Furthermore, to unlock the full representational capacity of this highly compact architecture, we synergistically pair it with an adaptive multi-granularity distillation strategy. Operating strictly within the latent space to avoid expensive pixel-space decoding, this strategy dynamically balances multiple gradient-based losses to achieve high-fidelity alignment. Extensive experiments across natural and portrait benchmarks demonstrate that this optimal synergy enables Moebius to rival or even surpass the generation quality of the 10B-level industrial generalist FLUX.1-Fill-Dev. Remarkably, Moebius achieves this using less than 2\% of the parameters (0.22B vs. 11.9B) while delivering a $>15\times$ acceleration in total inference time, setting a new efficiency standard for high-fidelity inpainting. Project page at https://hustvl.github.io/Moebius.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Moebius, a 0.22B-parameter lightweight image inpainting framework that reconstructs the diffusion backbone via the Local-λ Mix Interaction (LλMI) block (with Local-λ and Interactive-λ modules that compress spatial contexts and global semantic priors into fixed-size linear matrices) and pairs it with an adaptive multi-granularity distillation strategy operating in latent space. It claims this enables performance rivaling or surpassing the 11.9B FLUX.1-Fill-Dev model on natural and portrait benchmarks while using <2% of the parameters and delivering >15× faster inference.
Significance. If the performance claims are substantiated by rigorous experiments, the work would be significant for demonstrating that extreme compression of task-specific inpainting models can match large generalist foundation models without sacrificing fidelity, advancing practical deployment of high-quality generative inpainting under resource constraints. The latent-space distillation approach is a sensible design choice to avoid pixel-space costs.
major comments (1)
- [Abstract] Abstract: The central claim that Moebius 'rivals or even surpasses' FLUX.1-Fill-Dev with 0.22B parameters and >15× acceleration is load-bearing for the entire contribution, yet the abstract (and provided text) supplies no quantitative metrics, tables, ablation studies, baseline comparisons, or error analysis to support it, rendering verification of the claim impossible.
minor comments (1)
- [Abstract] The notation LλMI and the λ modules are introduced without an equation or diagram in the abstract; a formal definition or pseudocode would improve clarity even if present later in the manuscript.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Moebius 'rivals or even surpasses' FLUX.1-Fill-Dev with 0.22B parameters and >15× acceleration is load-bearing for the entire contribution, yet the abstract (and provided text) supplies no quantitative metrics, tables, ablation studies, baseline comparisons, or error analysis to support it, rendering verification of the claim impossible.
Authors: The abstract is a concise high-level summary and conventionally omits specific numerical values, tables, or detailed ablations to respect length constraints. The full manuscript contains all requested elements in the Experiments section, including quantitative metrics and direct baseline comparisons against FLUX.1-Fill-Dev on natural and portrait benchmarks, ablation studies validating the LλMI block and distillation components, inference-time measurements confirming the acceleration factor, and supporting analysis. These sections enable verification of the performance claims. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract and architecture description introduce the LλMI block (with Local-λ and Interactive-λ modules) and adaptive multi-granularity distillation as novel components that summarize contexts into linear matrices and align in latent space. No equations, fitted parameters renamed as predictions, or self-citation chains are present that would reduce the performance claims (rivaling FLUX.1-Fill-Dev at 0.22B params) to definitional equivalence with the inputs. The derivation chain remains self-contained via empirical validation on benchmarks, with no load-bearing reductions of the kind enumerated in the analysis criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2102.08602 (2021)
Bello, I.: Lambdanetworks: Modeling long-range interactions without attention. arXiv preprint arXiv:2102.08602 (2021)
-
[2]
In: Pro- ceedings of the 27th annual conference on Computer graphics and interactive tech- niques
Bertalmio, M., Sapiro, G., Caselles, V., Ballester, C.: Image inpainting. In: Pro- ceedings of the 27th annual conference on Computer graphics and interactive tech- niques. p. 417–424. SIGGRAPH ’00, ACM Press/Addison-Wesley Publishing Co., USA (2000).https://doi.org/10.1145/344779.344972,https://doi.org/10. 1145/344779.344972
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cai, H., Li, J., Hu, M., Gan, C., Han, S.: Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17302–17313 (2023)
2023
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, H., Zhao, Y.: Don’t look into the dark: Latent codes for pluralistic image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7591–7600 (June 2024)
2024
- [5]
-
[6]
In: International Conference on Learning Representations (ICLR) (2024)
Dao, T.: FlashAttention-2: Faster attention with better parallelism and work par- titioning. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[7]
Advances in neural information pro- cessing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information pro- cessing systems35, 16344–16359 (2022)
2022
-
[8]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
- [9]
-
[10]
Fortin, A., Vernade, G., Kampf, K., Reshi, A.: Introducing gemini 2.5 flash im- age, our state-of-the-art image model.https://developers.googleblog.com/en/ introducing-gemini-2-5-flash-image/(2025)
2025
-
[11]
In: CVPR (2019)
Gupta, A., Dollar, P., Girshick, R.: LVIS: A dataset for large vocabulary instance segmentation. In: CVPR (2019)
2019
-
[12]
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017),https://proceeding...
2017
-
[13]
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network (2015),https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [15]
-
[16]
Jordan, K., Jin, Y., Boza, V., Jiacheng, Y., Cesista, F., Newhouse, L., Bernstein, J.: Muon: An optimizer for hidden layers in neural networks (2024),https:// kellerjordan.github.io/posts/muon/
2024
-
[17]
Ju, X., Liu, X., Wang, X., Bian, Y., Shan, Y., Xu, Q.: Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion (2024) 16
2024
-
[18]
In: European Conference on Computer Vision (ECCV) (2024)
Kang, M., Zhang, R., Barnes, C., Paris, S., Kwak, S., Park, J., Shechtman, E., Zhu, J.Y., Park, T.: Distilling Diffusion Models into Conditional GANs. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[19]
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. IEEE Transactions on Pattern Analysis and Machine Intelli- gence43(12), 4217–4228 (2021).https://doi.org/10.1109/TPAMI.2020.2970919
-
[20]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[21]
Li, J., Zhao, R., Huang, J.T., Gong, Y.: Learning small-size dnn with output- distribution-based criteria. In: Interspeech 2014. pp. 1910–1914 (2014).https: //doi.org/10.21437/Interspeech.2014-432
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, R., Yang, T., Guo, S., Zhang, L.: Rorem: Training a robust object remover with human-in-the-loop. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14024–14035 (June 2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
Li, W., Lin, Z., Zhou, K., Qi, L., Wang, Y., Jia, J.: Mat: Mask-aware transformer for large hole image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
2022
-
[24]
In: Proceedings of the IEEE international conference on computer vision (2023)
Li, Y., Hu, J., Wen, Y., Evangelidis, G., Salahi, K., Wang, Y., Tulyakov, S., Ren, J.: Rethinking vision transformers for mobilenet size and speed. In: Proceedings of the IEEE international conference on computer vision (2023)
2023
-
[25]
Lu, C., Song, Y.: Simplifying, stabilizing and scaling continuous-time consistency models (2025),https://arxiv.org/abs/2410.11081
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
In: The Thirteenth International Conference on Learning Repre- sentations (2023)
Manukyan, H., Sargsyan, A., Atanyan, B., Wang, Z., Navasardyan, S., Shi, H.: Hd-painter: high-resolution and prompt-faithful text-guided image inpainting with diffusion models. In: The Thirteenth International Conference on Learning Repre- sentations (2023)
2023
-
[27]
In: The IEEE International Conference on Computer Vision (ICCV) Workshops (Oct 2019)
Nazeri, K., Ng, E., Joseph, T., Qureshi, F., Ebrahimi, M.: Edgeconnect: Struc- ture guided image inpainting using edge prediction. In: The IEEE International Conference on Computer Vision (ICCV) Workshops (Oct 2019)
2019
-
[28]
Scalable Diffusion Models with Transformers
Peebles, W., Xie, S.: Scalable diffusion models with transformers. arXiv preprint arXiv:2212.09748 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis (2023),https://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
arXiv preprint arXiv:2404.10518 (2024)
Qin, D., Leichner, C., Delakis, M., Fornoni, M., Luo, S., Yang, F., Wang, W., Banbury, C., Ye, C., Akin, B., et al.: Mobilenetv4-universal models for the mobile ecosystem. arXiv preprint arXiv:2404.10518 (2024)
-
[31]
Reda, F., Kontkanen, J., Tabellion, E., Sun, D., Pantofaru, C., Curless, B.: Film: Frameinterpolationforlargemotion.In:EuropeanConferenceonComputerVision (ECCV) (2022)
2022
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684– 10695 (June 2022)
2022
-
[33]
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets (2015),https://arxiv.org/abs/1412.6550
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models (2022),https://arxiv.org/abs/2202.00512
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
In: 2018 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Sandler, M., Howard, A.G., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv2: In- verted residuals and linear bottlenecks. In: 2018 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 4510–4520 (2018) 17
2018
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Sargsyan, A., Navasardyan, S., Xu, X., Shi, H.: Mi-gan: A simple baseline for im- age inpainting on mobile devices. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 7335–7345 (October 2023)
2023
-
[37]
Shazeer, N.: Glu variants improve transformer (2020),https://arxiv.org/abs/ 2002.05202
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[38]
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition (2015),https://arxiv.org/abs/1409.1556
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[39]
arXiv (2023)
Song, H., Huang, S., Dong, Y., Tu, W.W.: Robustness and generalizability of deep- fake detection: A study with diffusion models. arXiv (2023)
2023
-
[40]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models (2023),https: //arxiv.org/abs/2303.01469
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
arXiv preprint arXiv:2109.07161 (2021)
Suvorov, R., Logacheva, E., Mashikhin, A., Remizova, A., Ashukha, A., Silvestrov, A., Kong, N., Goka, H., Park, K., Lempitsky, V.: Resolution-robust large mask inpainting with fourier convolutions. arXiv preprint arXiv:2109.07161 (2021)
-
[42]
In: International conference on machine learning
Tan, M., Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks. In: International conference on machine learning. pp. 6105–6114. PMLR (2019)
2019
-
[43]
Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., Chen, Z., Cui, J., Ding, H., Dong, M., Du, A., Du, C., Du, D., Du, Y., Fan, Y., Feng, Y., Fu, K., Gao, B., Gao, H., Gao, P., Gao, T., Gu, X., Guan, L., Guo, H., Guo, J., Hu, H., Hao, X., He, T., He, W., He, W., Hong, C., Hu, Y., Hu, Z., Huang, W., Huang, Z., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
In: International Conference on Learning Representations (ICLR) (2018)
Tero Karras, Timo Aila, S.L., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability and variation. In: International Conference on Learning Representations (ICLR) (2018)
2018
- [45]
-
[46]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[47]
Wan, Z., Zhang, J., Chen, D., Liao, J.: High-fidelity pluralistic image completion with transformers. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4672–4681 (2021).https://doi.org/10.1109/ICCV48922. 2021.00465 18
-
[48]
Wang, C., Chen, D., Mei, J.P., Zhang, Y., Feng, Y., Chen, C.: Semckd: Semantic calibration for cross-layer knowledge distillation. IEEE Transactions on Knowledge and Data Engineering35(6), 6305–6319 (2023).https://doi.org/10.1109/TKDE. 2022.3171571
-
[49]
arXiv preprint arXiv:2212.00490 (2022)
Wang, Y., Yu, J., Zhang, J.: Zero-shot image restoration using denoising diffusion null-space model. arXiv preprint arXiv:2212.00490 (2022)
-
[50]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., Han, S.: Sana: Efficient high-resolution image synthesis with linear diffusion transformer (2024),https://arxiv.org/abs/2410.10629
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [52]
-
[53]
In: Neural Information Processing Systems (NeurIPS) (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. In: Neural Information Processing Systems (NeurIPS) (2021)
2021
- [54]
-
[55]
In: European Conference on Artificial Intelligence
Xu, Z., Zhao, H., Cui, Z., Liu, W., Zheng, C., Wang, X.: Most-dsa: Modeling motion and structural interactions for direct multi-frame interpolation in dsa images. In: European Conference on Artificial Intelligence. pp. 537–544 (2024), https://ebooks.iospress.nl/pdf/doi/10.3233/FAIA240531
-
[56]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xu, Z., Zhao, H., Liu, W., Wang, X.: Garamost: Parallel multi-granularity motion and structural modeling for efficient multi-frame interpolation in dsa images. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 28530– 28538 (2025)
2025
-
[57]
arXiv preprint arXiv:2402.01739 , year=
Xue, F., Zheng, Z., Fu, Y., Ni, J., Zheng, Z., Zhou, W., You, Y.: Openmoe: An early effort on open mixture-of-experts language models. arXiv preprint arXiv:2402.01739 (2024)
-
[58]
In: Proceedings of ICML (2024)
Yang, S., Wang, B., Shen, Y., Panda, R., Kim, Y.: Gated linear attention trans- formers with hardware-efficient training. In: Proceedings of ICML (2024)
2024
-
[59]
Yang, S., Zhang, Y.: Fla: A triton-based library for hardware-efficient implemen- tations of linear attention mechanism (Jan 2024),https://github.com/fla- org/flash-linear-attention
2024
-
[60]
generation: Taming optimization dilemma in latent diffusion models
Yao, J., Yang, B., Wang, X.: Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[61]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yi, Z., Tang, Q., Azizi, S., Jang, D., Xu, Z.: Contextual residual aggregation for ul- tra high-resolution image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7508–7517 (2020)
2020
-
[62]
In: 2017 IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR)
Yim, J., Joo, D., Bae, J., Kim, J.: A gift from knowledge distillation: Fast op- timization, network minimization and transfer learning. In: 2017 IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 7130–7138 (2017). https://doi.org/10.1109/CVPR.2017.754 19
-
[63]
Unsupervised Out-of-Distribution Detection by Maximum Clas- sifier Discrepancy
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T.: Free-form image inpainting with gated convolution. In: 2019 IEEE/CVF International Conference on Com- puter Vision (ICCV). pp. 4470–4479 (2019).https://doi.org/10.1109/ICCV. 2019.00457
-
[64]
Zeng, Y., Fu, J., Chao, H., Guo, B.: Aggregated contextual transformations for high-resolution image inpainting. IEEE Transactions on Visualization and Com- puter Graphics29(7), 3266–3280 (2023).https://doi.org/10.1109/TVCG.2022. 3156949
-
[65]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[66]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolu- tional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6848–6856 (2018)
2018
-
[67]
In: Interna- tional Conference on Learning Representations (ICLR) (2021)
Zhao, S., Cui, J., Sheng, Y., Dong, Y., Liang, X., Chang, E.I., Xu, Y.: Large scale image completion via co-modulated generative adversarial networks. In: Interna- tional Conference on Learning Representations (ICLR) (2021)
2021
-
[68]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2017)
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2017)
2017
-
[69]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhu, L., Huang, Z., Liao, B., Liew, J.H., Yan, H., Feng, J., Wang, X.: Dig: Scalable and efficient diffusion models with gated linear attention. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7664–7674 (June 2025)
2025
-
[70]
IEEE Transactions on Image Processing30, 4855–4866 (2021).https://doi.org/10.1109/TIP.2021
Zhu, M., He, D., Li, X., Li, C., Li, F., Liu, X., Ding, E., Zhang, Z.: Image inpainting by end-to-end cascaded refinement with mask awareness. IEEE Transactions on Image Processing30, 4855–4866 (2021).https://doi.org/10.1109/TIP.2021. 3076310
-
[71]
Zhuang, J., Zeng, Y., Liu, W., Yuan, C., Chen, K.: A task is worth one word: Learning with task prompts for high-quality versatile image inpainting (2023) 20 Supplementary Materials of Moebius Overview In this supplementary material, we provide extensive qualitative results and fur- therempiricalanalysestoreinforcethefindingspresentedinthemainmanuscript. ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.