Forecasting what Matters: Decision-Focused RL for Controlled EV Charging with Unknown Departure Times
Pith reviewed 2026-06-26 21:24 UTC · model grok-4.3
The pith
Training a forecaster end-to-end with RL policy feedback improves EV charging decisions when departure times are unknown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
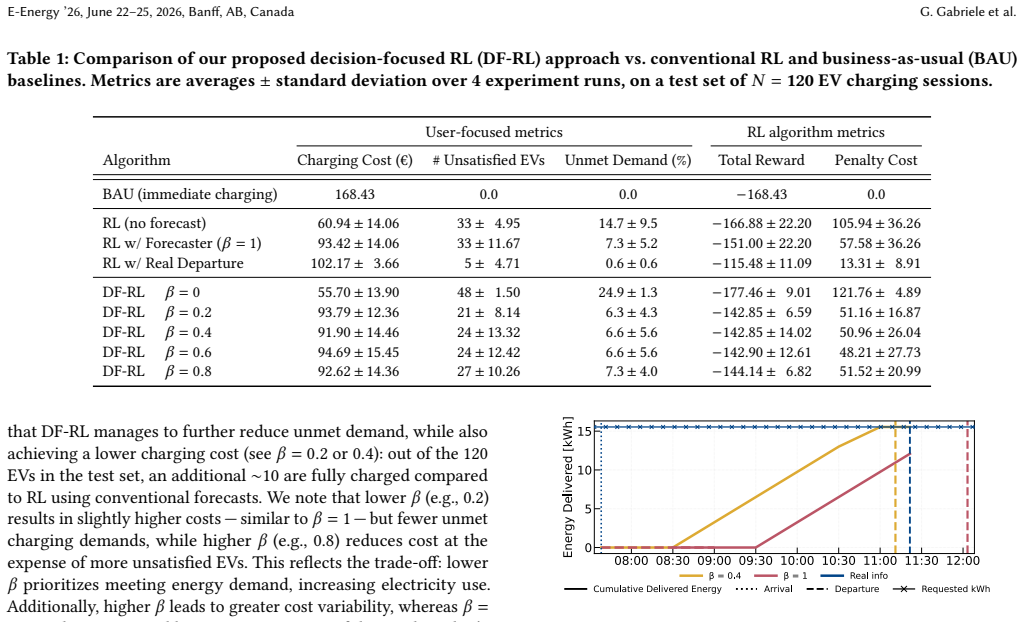
By training the forecaster end-to-end with feedback from the charging policy actions taken by the RL agent, the DF-RL framework produces higher-quality charging decisions than baselines, achieving up to a 14% improvement in total reward and a 55% reduction of unsupplied energy relative to the RL method without departure time forecasting.
What carries the argument
The decision-focused RL framework in which the forecaster receives direct feedback from the RL agent's charging policy actions.
If this is right
- Charging decisions improve relative to baselines that train the forecaster separately.
- Total reward increases by up to 14 percent compared with RL that ignores departure-time forecasting.
- Unsupplied energy drops by up to 55 percent because the policy better anticipates when an EV will leave.
- The same joint-training structure can be applied to any other missing feature that affects downstream control quality.
Where Pith is reading between the lines
- The method could reduce reliance on highly accurate standalone forecasters in other RL domains that involve timing uncertainty.
- End-to-end training may allow simpler forecaster architectures if their only job is to support good decisions rather than minimize every error.
- Similar feedback loops might help in power-system problems where forecasts of load or generation feed into real-time control policies.
Load-bearing premise
The forecaster trained with direct feedback from the RL policy actions will produce forecasts that generalize to new situations without the joint training introducing instability or overfitting that cancels the gains.
What would settle it
Running the DF-RL controller on a held-out set of real EV charging sessions with unknown departure times and checking whether the 14% reward gain and 55% unsupplied-energy reduction still appear.
Figures

read the original abstract
The recent growth of EV adoption poses challenges for power systems, including increased peak demand and potential grid instability. Smart control of EV charging -- e.g., based on reinforcement learning (RL) -- can alleviate these issues by learning temporal and contextual patterns from historical data. Yet, in real-world scenarios, key features, such as departure time, often are unavailable. This, in turn, makes it harder for an RL agent to learn and execute an effective charging policy. To mitigate this uncertainty, a trained forecaster can approximate the unknown features from available data. However, since these forecasting models are typically trained for accuracy (rather than their impact on a downstream agent's decision quality), their errors may propagate and hinder the overall performance of a controller that is using the forecasts. To avoid this, we propose a decision-focused RL (DF-RL) framework in which the forecaster is trained end-to-end, i.e., with feedback from the charging policy actions taken by the RL agent. Such joint training of both the forecaster and controller ultimately results in higher-quality actions: our proposed DF-RL method yields superior charging decisions compared to other baselines, achieving up to a 14% improvement in total reward and a 55% reduction of unsupplied energy (i.e., charging that failed to happen because the EV already left), relative to the RL method without departure time forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a decision-focused RL (DF-RL) framework for EV charging control under unknown departure times. A forecaster is trained end-to-end with direct feedback from the RL policy actions rather than on forecast accuracy alone, with the claim that this yields superior decisions: up to 14% higher total reward and 55% lower unsupplied energy relative to standard RL without departure-time forecasting.
Significance. If the empirical gains hold under proper controls for generalization and statistical robustness, the work would demonstrate the practical value of decision-focused training in RL applications with missing features, particularly for energy-system control. The approach directly targets a real deployment issue in EV charging and could influence how forecasting modules are integrated into learned controllers.
major comments (2)
- [§5] §5 (Results) and abstract: the headline performance claims (14% reward lift, 55% unsupplied-energy reduction) are presented without reported standard deviations across random seeds, number of independent trials, or statistical tests comparing DF-RL to the separate-forecaster baseline. This information is load-bearing for the central empirical claim given the stress-test concern about overfitting to the training departure-time distribution.
- [Method] Method section: the joint training procedure is described at a high level with no explicit objective function, loss combining forecast and policy terms, or description of the gradient path from RL actions back to the forecaster parameters. Without this, it is impossible to verify that the end-to-end training is stable and does not simply memorize training-set departure statistics.
minor comments (2)
- The abstract would be strengthened by a one-sentence summary of the experimental protocol (e.g., simulator used, train/test split on departure times) to allow readers to assess the numerical claims at a glance.
- [Introduction] Notation for the state features available to the forecaster versus the RL policy could be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater statistical rigor in the results and more explicit details on the joint training procedure. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: §5 (Results) and abstract: the headline performance claims (14% reward lift, 55% unsupplied-energy reduction) are presented without reported standard deviations across random seeds, number of independent trials, or statistical tests comparing DF-RL to the separate-forecaster baseline. This information is load-bearing for the central empirical claim given the stress-test concern about overfitting to the training departure-time distribution.
Authors: We agree that standard deviations, trial counts, and statistical tests are necessary to substantiate the central claims. In the revision we will report results aggregated over multiple random seeds (including the exact number of independent trials), include standard deviations or confidence intervals, and add statistical significance tests comparing DF-RL to the baseline. These additions will also help address potential overfitting concerns. revision: yes
-
Referee: Method section: the joint training procedure is described at a high level with no explicit objective function, loss combining forecast and policy terms, or description of the gradient path from RL actions back to the forecaster parameters. Without this, it is impossible to verify that the end-to-end training is stable and does not simply memorize training-set departure statistics.
Authors: We agree that an explicit formulation of the combined objective and the gradient flow is required for reproducibility and to demonstrate that training is decision-focused rather than memorization. We will revise the method section to state the joint loss (RL policy gradient term plus any auxiliary forecast term), specify how the forecaster parameters receive gradients through the policy actions, and clarify the training stability mechanisms. revision: yes
Circularity Check
No circularity: empirical comparison of training regimes with no derivation chain
full rationale
The paper describes an empirical RL framework for EV charging where a forecaster is trained end-to-end with policy feedback. No equations, derivations, or first-principles results are presented that could reduce to inputs by construction. Performance claims (14% reward, 55% unsupplied energy) rest on experimental comparisons of training regimes rather than any self-definitional, fitted-input, or self-citation load-bearing step. The method is self-contained as a standard end-to-end optimization experiment; no load-bearing premise collapses to a prior self-citation or ansatz.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ali Saadon Al-Ogaili, Tengku Juhana Tengku Hashim, Nur Azzammudin Rahmat, Agileswari K. Ramasamy, Marayati Binti Marsadek, Mohammad Faisal, and Ma- hammad A. Hannan. 2019. Review on Scheduling, Clustering, and Forecasting Strategies for Controlling Electric Vehicle Charging: Challenges and Recommen- dations.IEEE Access7 (2019), 128353–128371. https://doi....
-
[2]
Lucian Busoniu, Robert Babuska, Bart De Schutter, and Damien Ernst. 2017. Reinforcement learning and dynamic programming using function approximators. CRC press
2017
-
[3]
Guibin. Chen and Xiaoying. Shi. 2022. A Deep Reinforcement Learning-Based Charging Scheduling Approach with Augmented Lagrangian for Electric Vehicle. arXiv:2209.09772 [cs.AI] https://arxiv.org/abs/2209.09772
arXiv 2022
-
[4]
Guibin Chen, Lun Yang, and Xiaoyu Cao. 2025. A deep reinforcement learning- based charging scheduling approach with augmented Lagrangian for electric vehicles.Applied Energy378 (2025), 124706
2025
-
[5]
Ivo Grondman, Lucian Busoniu, Gabriel AD Lopes, and Robert Babuska. 2012. A survey of actor-critic reinforcement learning: Standard and natural policy gradients.IEEE Transactions on Systems, Man, and Cybernetics, part C (applications and reviews)42, 6 (2012), 1291–1307
2012
-
[6]
Ivo Grondman, Lucian Busoniu, Gabriel A. D. Lopes, and Robert Babuska. 2012. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gradients.IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applica- tions and Reviews)42, 6 (2012), 1291–1307. https://doi.org/10.1109/TSMCC.2012. 2218595
-
[7]
Chengyang Gu, Yuxin Pan, Ruohong Liu, and Yize Chen. 2024. Learning and Optimization for Price-based Demand Response of Electric Vehicle Charging. arXiv:2404.10311 [eess.SY] https://arxiv.org/abs/2404.10311
arXiv 2024
-
[8]
Chengyang Gu, Yuxin Pan, Ruohong Liu, and Yize Chen. 2024. Learning and Optimization for Price-Based Demand Response of Electric Vehicle Charging. In 2024 American Control Conference (ACC). 3625–3630. https://doi.org/10.23919/ ACC60939.2024.10644254
arXiv 2024
-
[9]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv:1801.01290 [cs.LG] https://arxiv.org/abs/1801.01290
Pith/arXiv arXiv 2018
-
[10]
Wenxian Hao, Jingxiang Wang, and Zhaojian Wang. 2025. Day-Ahead V2G Station Arbitrage Scheduling: A Decision-Focused Approach. In2025 37th Chinese Control and Decision Conference (CCDC). 1531–1537. https://doi.org/10.1109/ CCDC65474.2025.11090572
arXiv 2025
-
[11]
Seyed Soroush Karimi Madahi, Giuseppe Gabriele, Bert Claessens, and Chris Develder. 2025. Scalable Attention-based Reinforcement Learning Method for Multi-asset Control. InICML 2025 CO-BUILD Workshop on Computational Opti- mization of Buildings. https://openreview.net/forum?id=3h0v1Ht73L
2025
-
[12]
Jayanta Mandi, James Kotary, Senne Berden, Maxime Mulamba, Victor Bucarey, Tias Guns, and Ferdinando Fioretto. 2024. Decision-focused learning: Founda- tions, state of the art, benchmark and future opportunities.Journal of Artificial Intelligence Research80 (2024), 1623–1701
2024
-
[13]
Graham McClone, Avik Ghosh, Adil Khurram, Byron Washom, and Jan Kleissl
-
[14]
Hybrid machine learning forecasting for online mpc of work place electric vehicle charging.IEEE Transactions on Smart Grid15, 2 (2023), 1891–1901
2023
-
[15]
Hesam Mosalli, Saba Sanami, Yu Yang, Hen-Geul Yeh, and Amir G Aghdam
-
[16]
In2025 IEEE International systems Conference (SysCon)
Dynamic Load Balancing for EV Charging Stations Using Reinforcement Learning and Demand Prediction. In2025 IEEE International systems Conference (SysCon). IEEE, 1–7
-
[17]
Matteo Muratori, Marcus Alexander, Doug Arent, Morgan Bazilian, Pierpaolo Cazzola, Ercan M Dede, John Farrell, Chris Gearhart, David Greene, Alan Jenn, et al. 2021. The rise of electric vehicles—2020 status and future expectations. Progress in Energy3, 2 (2021), 022002
2021
-
[18]
Keonwoo Park and Ilkyeong Moon. 2022. Multi-agent deep reinforcement learn- ing approach for EV charging scheduling in a smart grid.Applied energy328 (2022), 120111
2022
-
[19]
Martin L Puterman. 1990. Markov decision processes.Handbooks in operations research and management science2 (1990), 331–434
1990
-
[20]
Sanket Shah, Kai Wang, Bryan Wilder, Andrew Perrault, and Milind Tambe. 2022. Decision-focused learning without decision-making: Learning locally optimized decision losses.Advances in Neural Information Processing Systems35 (2022), 1320–1332
2022
-
[21]
Sakib Shahriar, Abdul-Rahman Al-Ali, Ahmed H Osman, Salam Dhou, and Mais Nijim. 2021. Prediction of EV charging behavior using machine learning.Ieee Access9 (2021), 111576–111586
2021
-
[22]
Muddsair Sharif and Huseyin Seker. 2024. Smart EV charging with context- awareness: Enhancing resource utilization via deep reinforcement learning.IEEE Access12 (2024), 7009–7027
2024
-
[23]
Felix Tuchnitz, Niklas Ebell, Jonas Schlund, and Marco Pruckner. 2021. Devel- opment and evaluation of a smart charging strategy for an electric vehicle fleet based on reinforcement learning.Applied Energy285 (2021), 116382
2021
-
[24]
Weilun Wang and Lei Wu. 2024. A semi-decentralized real-time charging sched- uling scheme for large EV parking lots considering uncertain EV arrival and departure.IEEE Transactions on Smart Grid15, 6 (2024), 5871–5884
2024
-
[25]
Lei Yang, Xinbo Geng, Xiaohong Guan, and Lang Tong. 2024. EV Charging Scheduling Under Demand Charge: A Block Model Predictive Control Approach. IEEE Transactions on Automation Science and Engineering21, 2 (2024), 2125–2138. https://doi.org/10.1109/TASE.2023.3260804
-
[26]
Jin Zhang, Liang Che, and Mohammad Shahidehpour. 2023. Distributed training and distributed execution-based Stackelberg multi-agent reinforcement learning for EV charging scheduling.IEEE Transactions on Smart Grid14, 6 (2023), 4976– 4979. A Price Profile Figure 2: Daily price profile considered in our experiments
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.