Confidence is Not Reliability: Rethinking MC Dropout in Brain Tumour Segmentation
Pith reviewed 2026-06-26 21:22 UTC · model grok-4.3
The pith
MC Dropout uncertainty ranks segmentation errors well overall but can be severely miscalibrated on critical tumor sub-regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
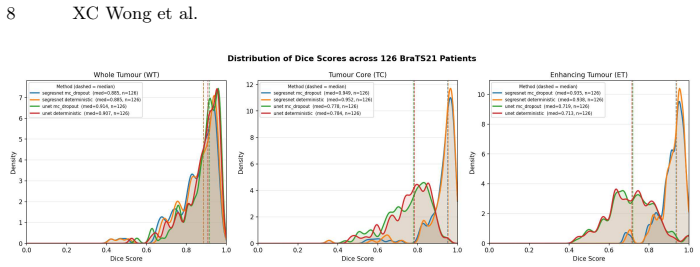
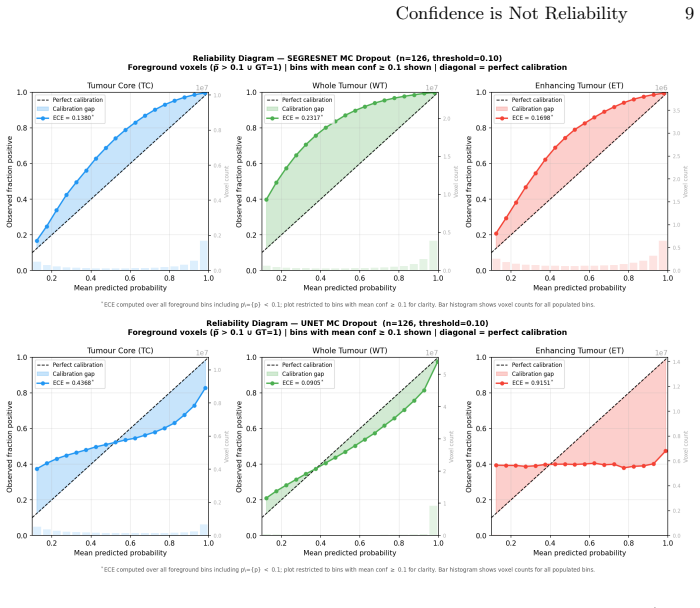
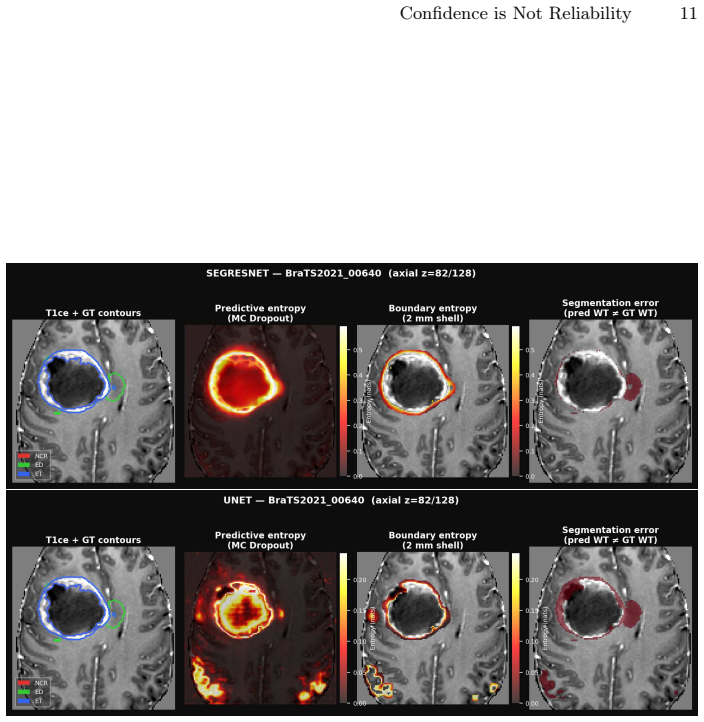
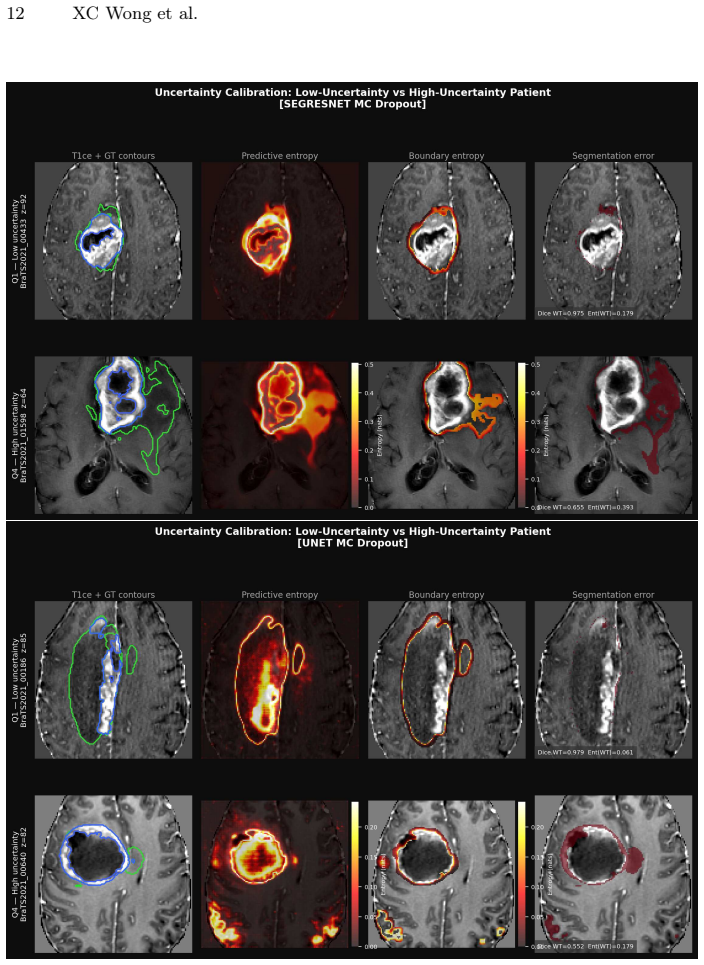
In an empirical two-model case study on 126 BraTS21 patients, MC dropout preserved Dice scores while yielding high AUROC for uncertainty-error alignment, yet the UNet-Res model produced entropy of 0.054 and ECE of 0.915 on enhancing tumor despite a Dice of only 0.714; global alignment metrics therefore mask region-specific miscalibration that standard reporting does not detect.
What carries the argument
Monte Carlo dropout entropy as a voxel-level uncertainty measure, assessed for error-ranking power via AUROC and for calibration via expected calibration error computed separately on tumor sub-regions.
If this is right
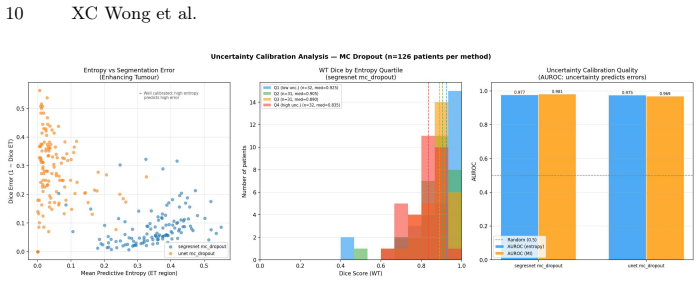
- Entropy-based uncertainty can identify a high-uncertainty patient subgroup with measurably lower whole-tumor Dice performance.
- Strong AUROC for uncertainty-error alignment can coexist with severe miscalibration on a single sub-region.
- Model selection for clinical use requires sub-region-specific calibration assessment in addition to AUROC.
- MC dropout can leave segmentation accuracy unchanged while still producing clinically unsafe confidence estimates on critical areas.
Where Pith is reading between the lines
- Clinical deployment pipelines would need routine per-subregion calibration plots rather than relying solely on aggregate AUROC.
- The observed failure mode could be tested by applying temperature scaling or other post-hoc calibration methods to the same models and re-measuring sub-region ECE.
- Similar region-specific checks may be warranted for uncertainty methods other than MC dropout when used in tumor segmentation.
Load-bearing premise
That the near-zero entropy and high ECE observed on enhancing tumor for the UNet-Res model reflect a general property of MC dropout rather than details specific to that model's training or the dataset.
What would settle it
Repeating the two-model comparison on additional independent datasets and architectures and finding that every MC-dropout model maintains low entropy yet high ECE on enhancing tumor would support the claim; finding consistent low ECE across models would falsify it.
Figures
read the original abstract
Glioma segmentation in multiparametric MRI is a critical component of treatment planning. A segmentation model that fails silently on treatment-critical sub-regions represents a patient safety risk that overlap-based metrics such as Dice scores cannot expose. We ask whether voxel-level uncertainty estimation via Monte Carlo (MC) Dropout can reliably identify segmentation errors in clinically critical sub-regions, and whether calibration failure modes are detectable from standard reporting metrics alone. In an empirical two-model case study on 126 BraTS21 patients, we evaluate a high-performance pretrained SegResNet and a locally trained UNet with residual units (UNet-Res). MC dropout preserved segmentation accuracy ($|\Delta \text{Dice}|$ $<0.01$) while achieving strong uncertainty-error alignment (AUROC for entropy (H) $\approx$0.97), indicating uncertainty correctly ranks erroneous voxels above correct ones. Entropy-based patient stratification identified a high-uncertainty subgroup with substantially lower segmentation performance (median whole-tumour Dice $0.835$ vs. $0.925$), supporting uncertainty as a practical triage signal. However, global alignment can mask important region-specific differences. Despite similar AUROC, UNet-Res exhibited near-zero enhancing tumour entropy ($0.054$) and Expected Calibration Error (ECE) of $0.915$, with a Dice of only $0.714$, indicating severely miscalibrated confidence on the most clinically critical sub-region, a failure mode invisible to standard Dice and AUROC reporting. These findings demonstrate that strong uncertainty-error alignment is necessary but insufficient for clinical safety: sub-region-specific calibration assessment must accompany AUROC evaluation when selecting models for clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a two-model empirical case study on 126 BraTS21 patients comparing a pretrained SegResNet and a locally trained UNet-Res for glioma segmentation. MC Dropout is shown to preserve Dice scores while yielding high AUROC (~0.97) for entropy-based ranking of erroneous voxels. However, the UNet-Res model exhibits near-zero enhancing-tumor entropy (0.054), high ECE (0.915), and lower Dice (0.714), demonstrating that strong uncertainty-error alignment does not guarantee sub-region calibration. The central claim is that AUROC alone is insufficient and that sub-region-specific calibration metrics must accompany it for clinical deployment.
Significance. If the reported counterexample holds, the work has clear practical significance for uncertainty evaluation in medical image segmentation. It supplies a concrete, quantitative illustration that global alignment metrics can mask clinically critical calibration failures on treatment-relevant sub-regions, thereby supporting the recommendation to report region-specific ECE alongside AUROC. The use of public BraTS21 data and explicit numerical results (AUROC, entropy, ECE, Dice) strengthens the empirical grounding.
major comments (2)
- [Methods] Methods / experimental setup: The implementation details of MC Dropout (number of stochastic forward passes, dropout probability during inference, and exact entropy computation) are not specified. These parameters directly determine the reported AUROC ≈0.97, entropy values (0.054), and ECE (0.915), so their absence prevents independent verification of the central counterexample.
- [Results] Results: No statistical significance tests, confidence intervals, or variance estimates are provided for the patient-stratification Dice difference (0.835 vs. 0.925) or the sub-region ECE contrast. Without these, the strength of evidence for the claim that global AUROC masks important failures remains difficult to assess.
minor comments (2)
- [Abstract] Abstract: The notation |Δ Dice| <0.01 should be clarified to indicate whether it refers to absolute or relative change and over which regions it is computed.
- [Abstract] Abstract: The ECE value of 0.915 is reported without stating the number of bins or normalization; a brief note on the ECE formulation used would improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the practical significance of our empirical case study. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Methods] Methods / experimental setup: The implementation details of MC Dropout (number of stochastic forward passes, dropout probability during inference, and exact entropy computation) are not specified. These parameters directly determine the reported AUROC ≈0.97, entropy values (0.054), and ECE (0.915), so their absence prevents independent verification of the central counterexample.
Authors: We agree that these implementation details are essential for reproducibility and independent verification. The revised manuscript will explicitly report the number of stochastic forward passes, the dropout probability applied at inference time, and the exact entropy computation formula used to generate the reported AUROC, entropy, and ECE values. revision: yes
-
Referee: [Results] Results: No statistical significance tests, confidence intervals, or variance estimates are provided for the patient-stratification Dice difference (0.835 vs. 0.925) or the sub-region ECE contrast. Without these, the strength of evidence for the claim that global AUROC masks important failures remains difficult to assess.
Authors: We acknowledge the value of adding statistical support. In the revision we will include bootstrap confidence intervals for the reported median Dice scores and a non-parametric test for the group difference, along with patient-level variance for the ECE values, to better quantify the strength of the observed contrasts. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The manuscript is a two-model empirical case study on public BraTS21 data. It reports direct measurements (AUROC ≈0.97, Dice scores, entropy values such as 0.054, ECE 0.915) without derivations, fitted parameters renamed as predictions, or any load-bearing self-citation chain. The recommendation that sub-region ECE must accompany AUROC follows from the observed counterexample and requires no internal reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aliferis, C., Simon, G.: Overfitting, underfitting and gen eral model overcon- fidence and under-performance pitfalls and best practices i n machine learn- ing and AI. In: Simon, G.J., Aliferis, C. (eds.) Artificial In telligence and Machine Learning in Health Care and Medical Sciences: Best P ractices and Pitfalls, pp. 477–524. Springer International Publish...
-
[2]
Baid, U., Ghodasara, S., Mohan, S., et al., M.: The rsna-as nr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic cla ssification (2021)
2021
-
[3]
Sensors (Basel) 25(6), 1838 (Mar 2025)
Bonato, B., Nanni, L., Bertoldo, A.: Advancing precision : A comprehensive review of MRI segmentation datasets from BraTS challenges (2012-2 025). Sensors (Basel) 25(6), 1838 (Mar 2025)
2012
-
[4]
Camarasa, R., Bos, D., Hendrikse, J., Nederkoorn, P., Koo i, E., van der Lugt, A., de Bruijne, M.: Quantitative Comparison of Monte-Carlo Dropout Uncer- tainty Measures for Multi-class Segmentation. In: Sudre, C .H., Fehri, H., Ar- bel, T., Baumgartner, C.F., Dalca, A., Tanno, R., Van Leempu t, K., Wells, W.M., Sotiras, A., Papiez, B., Ferrante, E., Paris...
-
[5]
Cardoso, M.J., Li, W., Brown, R., Ma, N., , et al.: Monai: An open-source frame- work for deep learning in healthcare (2022), https://arxiv.org/abs/2211.02701
Pith/arXiv arXiv 2022
-
[6]
( eds.) Information Pro- cessing in Medical Imaging
Czolbe, S., Arnavaz, K., Krause, O., Feragen, A.: Is segme ntation uncertainty use- ful? In: Feragen, A., Sommer, S., Schnabel, J., Nielsen, M. ( eds.) Information Pro- cessing in Medical Imaging. pp. 715–726. Springer Internat ional Publishing, Cham (2021)
2021
-
[7]
Dwaracherla, V., Wen, Z., Osband, I., Lu, X., Asghari, S.M ., Roy, B.V.: Ensembles for uncertainty estimation: Benefits of prior functions and bootstrapping (2022), https://arxiv.org/abs/2206.03633
arXiv 2022
-
[8]
In: Proceedings of the 33rd In ternational Confer- ence on International Conference on Machine Learning - Volu me 48
Gal, Y., Ghahramani, Z.: Dropout as a bayesian approximat ion: representing model uncertainty in deep learning. In: Proceedings of the 33rd In ternational Confer- ence on International Conference on Machine Learning - Volu me 48. p. 1050–1059. ICML’16, JMLR.org (2016)
2016
-
[9]
Tomography 11(5), 52 (Apr 2025)
Gao, Y., Jiang, Y., Peng, Y., Yuan, F., Zhang, X., Wang, J.: Medical image seg- mentation: A comprehensive review of deep learning-based m ethods. Tomography 11(5), 52 (Apr 2025)
2025
-
[10]
Jungo, A., Balsiger, F., Reyes, M.: Analyzing the qualit y and challenges of uncer- tainty estimations for brain tumor segmentation. Front. Ne urosci. 14, 282 (Apr 2020)
2020
-
[11]
(eds.) Advances in Neural Inf ormation Processing Systems
Kendall, A., Gal, Y.: What uncertainties do we need in bay esian deep learning for computer vision? In: Guyon, I., Luxburg, U.V., Bengio, S., W allach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Inf ormation Processing Systems. vol. 30. Curran Associates, Inc. (2017) Confidence is Not Reliability 15
2017
-
[12]
Information Scie nces 645, 119356 (2023)
Ledda, E., Fumera, G., Roli, F.: Dropout injection at tes t time for post hoc uncer- tainty quantification in neural networks. Information Scie nces 645, 119356 (2023). https://doi.org/10.1016/j.ins.2023.119356
-
[13]
Mehrtash, A., Wells, W.M., Tempany, C.M., Abolmaesumi, P., Kapur, T.: Confidence Calibration and Predictive Uncertainty Esti mation for Deep Medical Image Segmentation. IEEE transactions on medi cal imaging 39(12), 3868–3878 (Dec 2020). https://doi.org/10.1109/TMI.2020.3006437, https://pmc.ncbi.nlm.nih.gov/articles/PMC7704933/
-
[14]
The journal of machine learning for biomedical imaging 2022, https://www.melba– journal.org/papers/2022:026.html (Aug 2022)
Mehta, R., Filos, A., Baid, U., Sako, C., McKinley, R., Re bsamen, M., , et al.: QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncer tainty in Brain Tumor Segmentation - Analysis of Ranking Scores and Benchma rking Results. The journal of machine learning for biomedical imaging 2022, https://www.melba– journal.org/papers/2022:026.html (Aug 2022)
2020
-
[15]
In: Brainlesion: Glioma, Multiple Sclerosis, Str oke and Traumatic Brain Injuries
Myronenko, A.: 3D MRI brain tumor segmentation using aut oencoder regular- ization. In: Brainlesion: Glioma, Multiple Sclerosis, Str oke and Traumatic Brain Injuries. pp. 311–320. Springer International Publishing , Cham (2019)
2019
-
[16]
Nair, T., Precup, D., Arnold, D.L., Arbel, T.: Exploring uncertainty measures in deep networks for multiple sclerosis lesion detection and s egmentation. Med. Image Anal. 59(101557), 101557 (Jan 2020)
2020
-
[17]
Patel, K., Beluch, W., Zhang, D., Pfeiffer, M., Yang, B.: O n-manifold adver- sarial data augmentation improves uncertainty calibratio n. In: 2020 25th In- ternational Conference on Pattern Recognition (ICPR). pp. 8029–8036 (2021). https://doi.org/10.1109/ICPR48806.2021.9413010
-
[18]
Sakata, A., Fushimi, Y., Oshima, S., Uto, M., Mineharu, Y ., Nakajima, S., Okuchi, S., Yamamoto, T., Otani, S., Ikeda, S., Takada, S., Mizowaki , T., Arakawa, Y., Nakamoto, Y.: RANO 2.0: critical updates and practical cons iderations for ra- diological assessment in neuro-oncology. Jpn. J. Radiol. 43(10), 1557–1574 (Oct 2025)
2025
-
[19]
Sherkatghanad, Z., Abdar, M., Bakhtyari, M., Pławiak, P ., Makarenkov, V.: Baytta: Uncertainty-aware medical image classificatio n with optimized test-time augmentation using bayesian model averaging. Kn ow.-Based Syst. 327(C) (Oct 2025). https://doi.org/10.1016/j.knosys.2025.114123, https://doi.org/10.1016/j.knosys.2025.114123
-
[20]
Signal Transduc t
Singh, S., Dey, D., Barik, D., Mohapatra, I., Kim, S., Sha rma, M., Prasad, S., Wang, P., Singh, A., Singh, G.: Glioblastoma at the crossroa ds: current under- standing and future therapeutic horizons. Signal Transduc t. Target. Ther. 10(1), 213 (Jul 2025)
2025
-
[21]
Zeevi, T., Lieffrig, E.V., Staib, L.H., Onofrey, J.A.: Sp atially-aware evaluation of segmentation uncertainty (2025), https://arxiv.org/abs/2506.16589
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.