Physical Atari: A Robust and Accessible Platform for Real-time Reinforcement Learning on Robots
Pith reviewed 2026-06-28 21:56 UTC · model grok-4.3
The pith
Reinforcement learning algorithms can learn directly on physical robots using an affordable Atari controller platform, but even small distribution shifts between learning and deployment significantly degrade policy performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
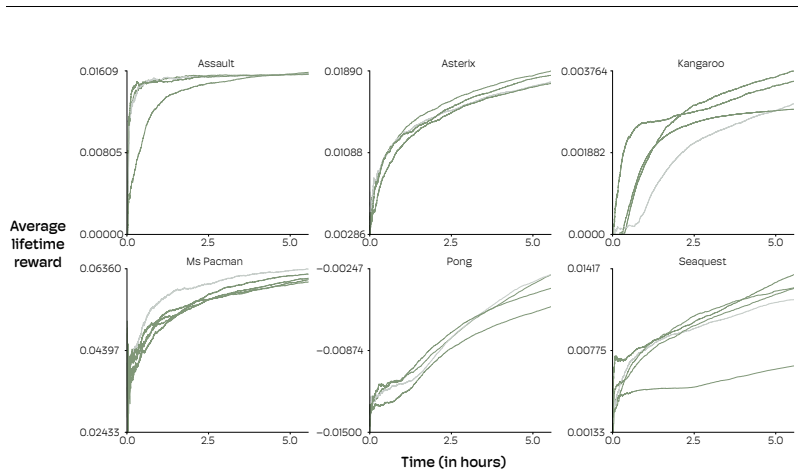
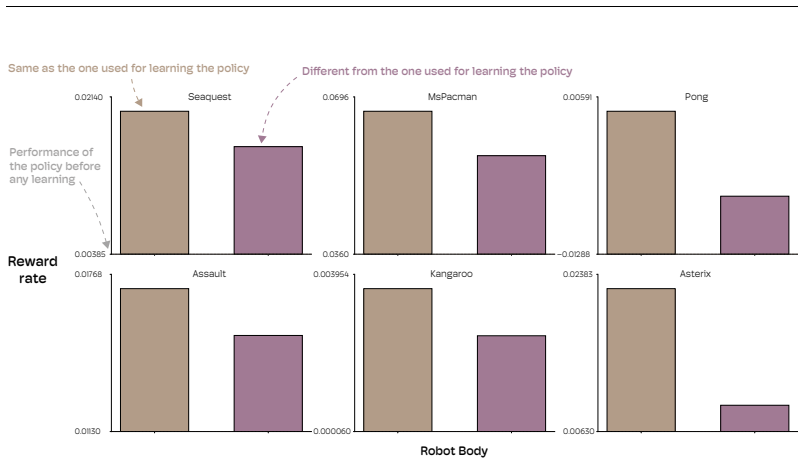
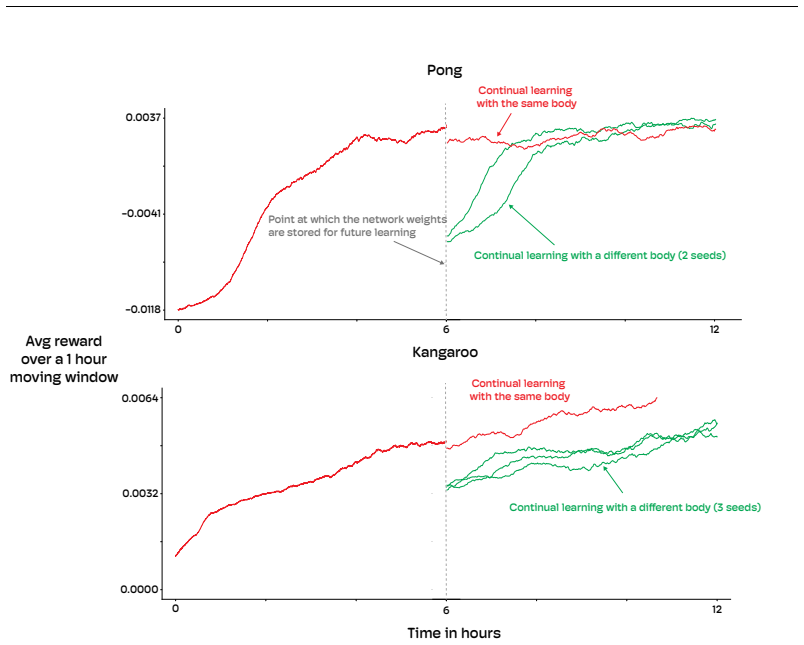
The Physical Atari system, consisting of the Robotroller and Atari Devbox together with a camera and desktop computer, forms a robust and accessible platform for studying reinforcement learning in the physical world. The authors used it to validate that reinforcement learning algorithms can learn directly on robots. They also show that even small distribution shifts between learning and deployment can significantly degrade the performance of policies, which underscores the importance of on-device adaptation for strong performance on robots.
What carries the argument
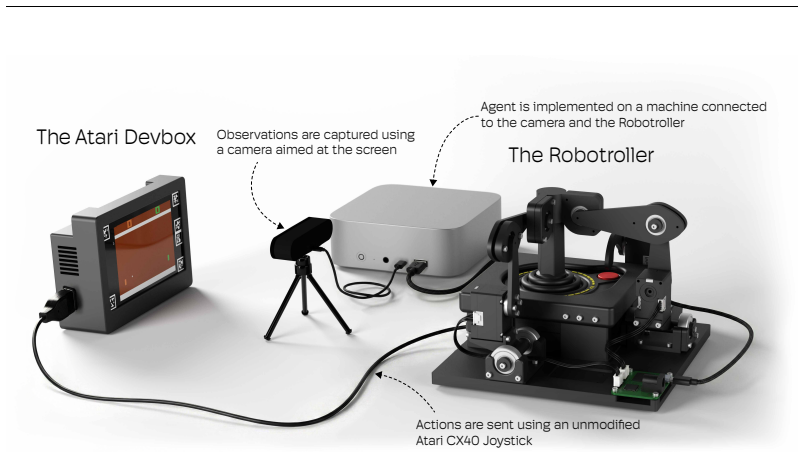
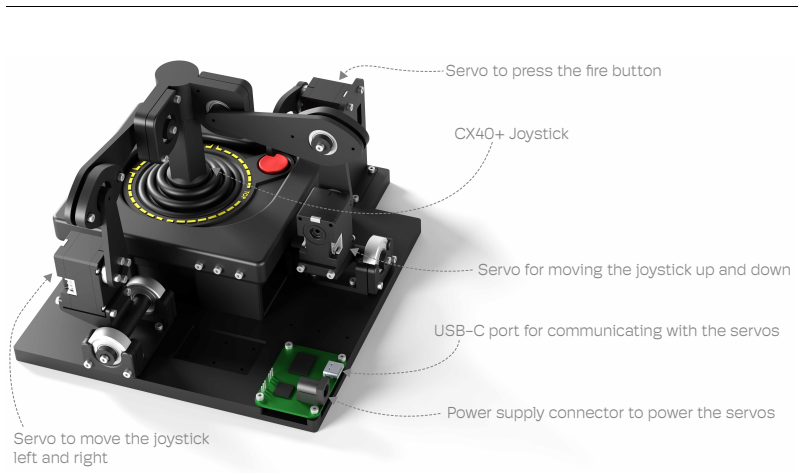
The Robotroller, a bearing-mounted servo actuator for the Atari CX40+ controller with high-frequency state monitoring software to limit stress, combined with the Atari Devbox that renders game frames and rewards.
If this is right
- Reinforcement learning algorithms can train policies directly on physical robots using this platform.
- Small distribution shifts between learning and deployment cause significant degradation in policy performance.
- On-device adaptation is required for strong performance on robots.
- The platform supports continuous operation for weeks without mechanical failures.
- The full system can be built for under $1000 using off-the-shelf and 3D-printed parts.
Where Pith is reading between the lines
- The same low-cost physical interface approach could support direct learning on other button-based or controller-driven tasks.
- Isolating hardware variability from distribution shift would require additional controlled comparisons not reported here.
- Extending the platform to multiple robots could test whether adaptation needs scale with hardware differences.
Load-bearing premise
The performance drop is caused by distribution shift between learning and deployment rather than by hardware variability, camera noise, or servo inconsistencies in the robot itself.
What would settle it
Running the same learning and deployment phases with every measurable hardware state, lighting, and camera condition held identical and checking whether policy performance still degrades.
Figures




read the original abstract
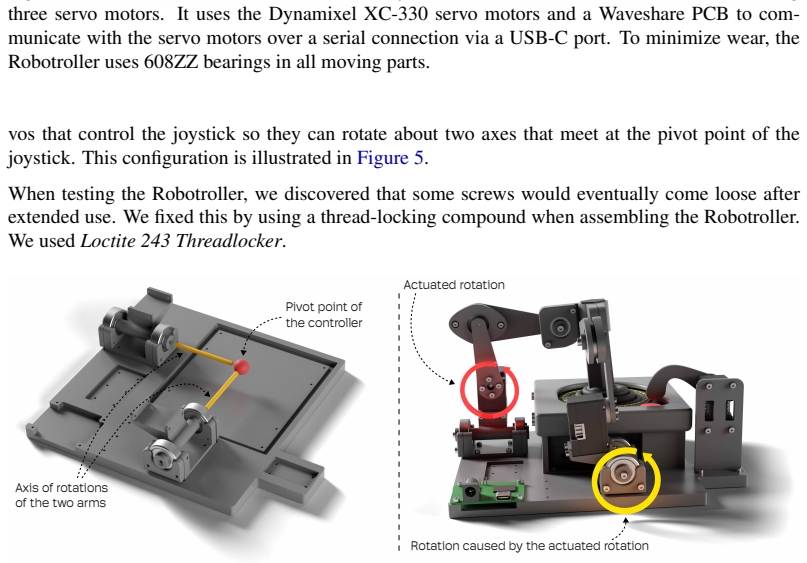
We built a robot called the Robotroller that actuates an Atari CX40+ controller and a device called the Atari Devbox that renders the game frame and the reward signal from the Arcade Learning Environment on a screen. The Robotroller and the Atari Devbox, together with an off-the-shelf camera and a desktop computer, constitute a system that can be used to study reinforcement learning algorithms in the physical world. We call the full system Physical Atari. In this paper, we detail the key decisions that make Physical Atari a robust and accessible platform. To make the system robust, we designed the Robotroller so that all movement is done through bearings, which reduces wear. Additionally, we wrote software that monitors the state of the servos at a high frequency and intervenes to limit stress. To make the system accessible, we used affordable off-the-shelf components and parts that can be manufactured using consumer 3D printers. Physical Atari can be built for under $1,000 and has been used for weeks of non-stop reinforcement learning experiments without any mechanical failures. We used it to validate that reinforcement learning algorithms can learn directly on robots and show that even small distribution shifts between learning and deployment can significantly degrade the performance of policies. Our results underscore the importance of on-device adaptation for strong performance on robots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes Physical Atari, a physical platform for real-time RL consisting of the Robotroller (a bearing-based servo actuator for the Atari CX40+ controller) and Atari Devbox (which renders ALE game frames and reward signals on-screen). Combined with an off-the-shelf camera and desktop computer, the system is presented as robust (bearings reduce wear; high-frequency servo monitoring limits stress) and accessible (under $1000 using consumer 3D-printed and off-the-shelf parts). The paper claims the platform has supported weeks of continuous RL experiments without mechanical failure and reports experiments showing that RL algorithms can learn directly on the physical robot while small distribution shifts between training and deployment significantly degrade policy performance, underscoring the value of on-device adaptation.
Significance. If the reported experiments are supported by quantitative data and controls, the platform would provide an affordable, reproducible testbed for studying physical RL issues such as distribution shift, potentially enabling broader empirical work on on-robot learning that is currently hindered by hardware barriers.
major comments (2)
- [Abstract] Abstract: the claim that experiments 'validated learning on robots and distribution-shift effects' is unsupported by any quantitative results, error bars, trial counts, or data-exclusion criteria. This absence prevents verification that the data actually support the central empirical claim.
- [Experiments section] Experiments section (and design claims): the attribution of performance degradation to distribution shift between learning and deployment is not isolated from potential Robotroller hardware confounds. No trial-to-trial statistics on servo state, bearing friction, camera variability, or reward noise are reported, nor are ablations or statistical tests separating these factors from the intended shift variable.
minor comments (1)
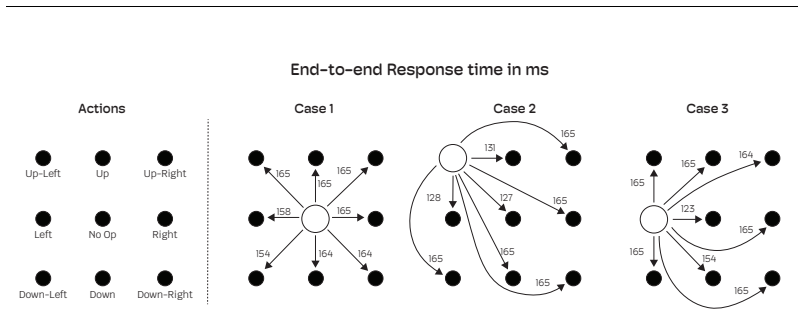
- [Figures] Figure captions and system diagrams would benefit from explicit labels for all components (e.g., servo mounting, camera placement) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript on Physical Atari. We address the two major comments point by point below, indicating where revisions are planned.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'validated learning on robots and distribution-shift effects' is unsupported by any quantitative results, error bars, trial counts, or data-exclusion criteria. This absence prevents verification that the data actually support the central empirical claim.
Authors: We agree that the abstract claim would be more verifiable with explicit quantitative support. The experiments section describes successful on-robot learning and the impact of distribution shifts on policy performance, but we will revise the abstract to reference specific results (including trial counts, performance metrics, and variability measures) and add the requested details to the experiments section in the revised manuscript. revision: yes
-
Referee: [Experiments section] Experiments section (and design claims): the attribution of performance degradation to distribution shift between learning and deployment is not isolated from potential Robotroller hardware confounds. No trial-to-trial statistics on servo state, bearing friction, camera variability, or reward noise are reported, nor are ablations or statistical tests separating these factors from the intended shift variable.
Authors: The Robotroller design uses bearings for all motion and high-frequency servo monitoring to limit stress, choices intended to reduce mechanical variability; the system completed weeks of continuous operation without failure. These features provide supporting evidence for robustness, but we did not record or analyze the specific trial-to-trial statistics on servo state, friction, camera variability, or reward noise, nor conduct the suggested ablations or statistical tests, because the experimental focus was on RL policy behavior rather than hardware metrology. revision: no
- Trial-to-trial statistics on servo state, bearing friction, camera variability, and reward noise, along with ablations or statistical tests isolating distribution shift from hardware factors, as these data were not collected during the reported experiments.
Circularity Check
No circularity: hardware platform and empirical results have no derivation chain
full rationale
The paper is a description of a physical robot platform (Robotroller + Atari Devbox) for running RL experiments, with claims resting on mechanical construction details, cost, runtime reliability, and reported performance under distribution shifts. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text or abstract. The central empirical observation (performance degradation under shifts) is presented as a direct experimental outcome rather than a mathematical reduction; any concerns about unmeasured hardware confounds are issues of experimental isolation, not circularity in a derivation. The work is self-contained as a platform report with no load-bearing steps that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bearings and high-frequency servo monitoring software are sufficient to prevent mechanical wear and stress during weeks of continuous operation.
Reference graph
Works this paper leans on
-
[1]
Abbeel, P., Coates, A., Quigley, M., & Ng, A. Y . (2006). An application of reinforcement learning to aerobatic helicopter flight.Advances in Neural Information Processing Systems,
2006
-
[2]
Solving Rubik's Cube with a Robot Hand
OpenAI, Akkaya, I., Andrychowicz, M., Chociej, M., Chiek, M., Boby, A., Baker, B., ... & Zaremba, W. (2019). Solving Rubik’s cube with a robot hand.arXiv Preprint arXiv:1910.07113. Benbrahim, H., Doleac, J., Franklin, J., & Selfridge, O. (1992, June). Real-time learning: A ball on a beam. InInternational Joint Conference on Neural Networks. Brockman, G., ...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[3]
& Silver, D
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., ... & Silver, D. (2020). Mastering Atari, Go, Chess and Shogi by planning with a learned model.Nature. Schwarzer, M., Obando-Ceron, J., Courville, A., Bellemare, M. G., Agarwal, R., & Castro, P. S. (2023). Bigger, better, faster: Human-level Atari with human-level efficie...
2020
-
[4]
A Deeper Look at Experience Replay
Wu, P., Escontrela, A., Hafner, D., Abbeel, P., & Goldberg, K. (2023, March). Daydreamer: World models for physical robot learning. InConference on Robot Learning. PMLR. 12 Zhao, T. Z., Kumar, V ., Levine, S., & Finn, C. (2023, July). Learning fine-grained bimanual manip- ulation with low-cost hardware. InProceedings of Robotics: Science and Systems. Zhan...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Finally, exploration is managed via anϵ-greedy strategy with a fixedϵof2 −6 (Exploration), and new actions are selected everyPolicy Skip(2) frames
frames. Finally, exploration is managed via anϵ-greedy strategy with a fixedϵof2 −6 (Exploration), and new actions are selected everyPolicy Skip(2) frames. E Robotroller and Camera Hyperparameters This section details the specific configuration used for the Robotroller and the camera in our experi- ments. E.1 Camera Configuration The camera is configured ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.