JustDiag!: A Diagnostic Justification Engine for Accountable Root Cause Analysis
Pith reviewed 2026-06-26 19:50 UTC · model grok-4.3
The pith
JustDiag maintains an explicit process state over evidence, hypotheses and conflicts to produce more accountable root cause analyses than fluent final answers alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
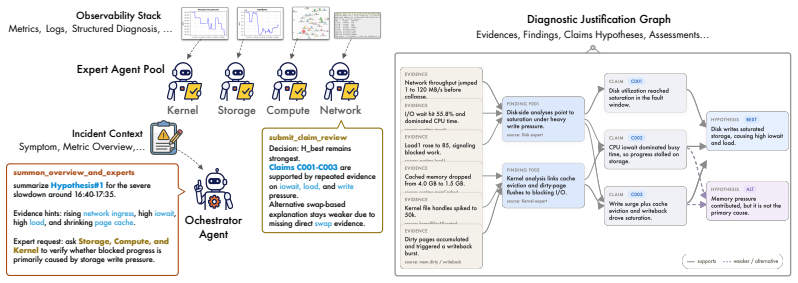
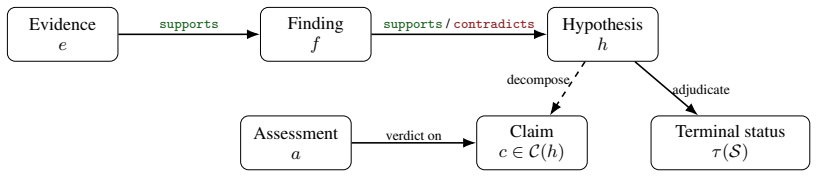
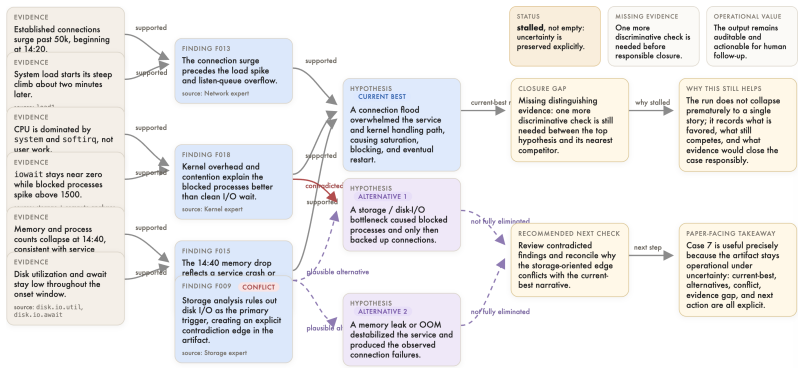
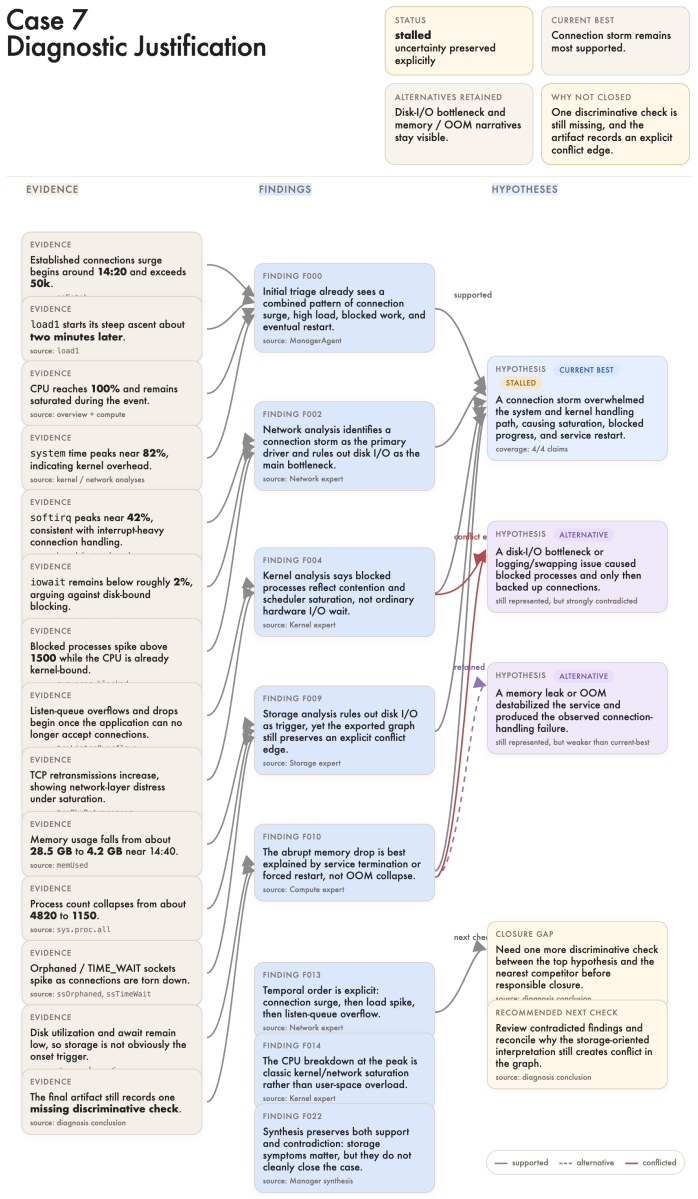
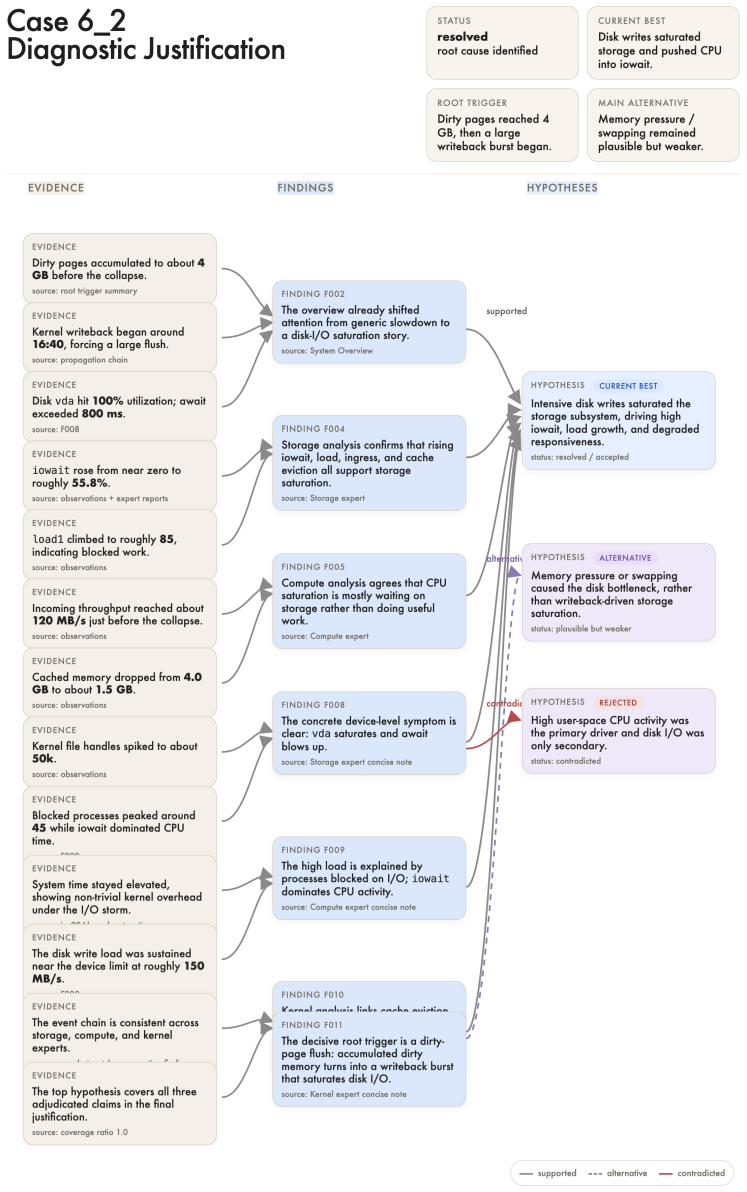
JustDiag is a diagnostic justification engine that maintains an explicit process state over evidence, findings, competing hypotheses, conflicts, and next checks. On 66 real-world incidents, it achieved stronger outcome and process scores than a matched control without diagnostic justification, while accepting slightly lower terminal completion due to more calibrated non-closure. The results show that accountable root cause analysis requires explicit diagnostic justification artifacts and process-aware evaluation, not only fluent final answers.
What carries the argument
JustDiag, the diagnostic justification engine that maintains an explicit process state over evidence, findings, competing hypotheses, conflicts, and next checks.
If this is right
- Accountable RCA can be produced by maintaining explicit records of evidence, hypotheses, and conflicts rather than only a final diagnosis.
- Process-aware evaluation reveals strengths that final-answer scoring alone misses.
- Systems that track unresolved conflicts produce more calibrated decisions to leave cases open instead of forcing closure.
- Explicit justification artifacts support better oversight in high-stakes operations by making the reasoning trail inspectable.
Where Pith is reading between the lines
- The same explicit-state approach could be tested on other sequential diagnostic domains such as medical or legal reasoning.
- Integrating justification state maintenance might reduce overconfident errors in deployed incident tools.
- Process-quality scoring could be automated to provide ongoing feedback during diagnosis rather than only post-hoc evaluation.
Load-bearing premise
The two-layer protocol that separately scores final-answer quality and process quality is a valid and sufficient measure of accountability in root cause analysis.
What would settle it
A controlled study in which incident responders rate systems with and without explicit justification artifacts on real accountability criteria and find no difference or a reversal in preference.
Figures

read the original abstract
Large language models can produce fluent root cause analyses, but fluent final answers alone are insufficient evidence for accountability in high-stakes operations. In real incident response, engineers need to know what evidence supported a diagnosis, which alternatives were considered, where contradictions remained, and whether the system resolved the case or preserved uncertainty. We address this gap with JustDiag, a diagnostic justification engine for RCA that maintains an explicit process state over evidence, findings, competing hypotheses, conflicts, and next checks. We evaluated the system on 66 real-world incidents using a two-layer protocol that separately scores final-answer quality and process quality. Relative to a matched control without diagnostic justification, JustDiag achieved stronger outcome and process scores, while accepting slightly lower terminal completion due to more calibrated non-closure. These results suggest that accountable RCA requires explicit diagnostic justification artifacts and process-aware evaluation, not only fluent final answers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces JustDiag, a diagnostic justification engine for root cause analysis that maintains explicit process state over evidence, findings, competing hypotheses, conflicts, and next checks. It reports results from a two-layer evaluation protocol (separately scoring final-answer quality and process quality) on 66 real-world incidents, claiming stronger outcome and process scores relative to a matched control without the justification features, at the cost of slightly lower terminal completion due to more calibrated non-closure. The authors conclude that accountable RCA requires explicit diagnostic justification artifacts and process-aware evaluation rather than fluent final answers alone.
Significance. If the evaluation protocol is shown to be valid, the work would usefully demonstrate that structured justification mechanisms can improve process quality in AI-supported RCA on real incidents. The comparative design against a matched control and the focus on real incidents are strengths that could inform accountable systems in operations. However, the absence of protocol validation details limits the strength of the accountability interpretation.
major comments (2)
- [Evaluation] The central claim that JustDiag produces stronger outcome and process scores (supporting the need for explicit justification) rests on the two-layer scoring protocol, yet the manuscript provides no details on rubric development, inter-rater reliability, blinding procedures, or correlation with external criteria such as expert judgment of decision quality (Evaluation section / abstract results paragraph). Without this grounding, the protocol risks measuring fluency or verbosity rather than accountability.
- [Evaluation] The reported results on 66 incidents lack any description of scoring criteria, how the matched control was constructed, statistical tests, or potential selection biases. This prevents assessment of whether the stronger scores are robust or whether the slightly lower terminal completion reflects genuine calibration (abstract and Evaluation section).
minor comments (1)
- [Abstract] The abstract introduces terms such as 'terminal completion' and 'calibrated non-closure' without brief definitions, which could be clarified for readers unfamiliar with the protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the importance of evaluation transparency. These points directly affect the interpretability of our claims regarding accountable RCA. We respond to each major comment below and will revise the manuscript to address the identified gaps.
read point-by-point responses
-
Referee: [Evaluation] The central claim that JustDiag produces stronger outcome and process scores (supporting the need for explicit justification) rests on the two-layer scoring protocol, yet the manuscript provides no details on rubric development, inter-rater reliability, blinding procedures, or correlation with external criteria such as expert judgment of decision quality (Evaluation section / abstract results paragraph). Without this grounding, the protocol risks measuring fluency or verbosity rather than accountability.
Authors: We agree that the manuscript lacks sufficient detail on the scoring protocol's development and validation. In the revised Evaluation section we will add: the rubric development process (iterative refinement with incident response experts), inter-rater reliability statistics, blinding procedures, and any correlations with external expert judgments of decision quality. These additions will better demonstrate that the protocol targets accountability elements such as evidence tracking and hypothesis management rather than fluency. revision: yes
-
Referee: [Evaluation] The reported results on 66 incidents lack any description of scoring criteria, how the matched control was constructed, statistical tests, or potential selection biases. This prevents assessment of whether the stronger scores are robust or whether the slightly lower terminal completion reflects genuine calibration (abstract and Evaluation section).
Authors: We concur that additional reporting details are required. The revised manuscript will include explicit scoring criteria for both layers, a description of matched-control construction (by incident type, complexity, and data availability), the statistical tests applied with results, and discussion of selection biases and mitigations. This will allow readers to evaluate the robustness of the reported improvements and the calibration interpretation of completion rates. revision: yes
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The paper presents an empirical system description and evaluation on 66 incidents using a two-layer scoring protocol. No mathematical derivation, parameter fitting, or first-principles claim is made that reduces to its own inputs. The central suggestion follows from comparative scores against a matched control; the protocol is introduced as an evaluation method rather than derived from the system itself. No self-citations, ansatzes, or uniqueness theorems are invoked in the provided text to support load-bearing premises. The evaluation is self-contained against external benchmarks (real incidents) without reducing predictions to fitted inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Faultinsight: Interpreting hyperscale data center host faults
Tingzhu Bi, Zhang Yang, Yicheng Pan, Yu Zhang, Meng Ma, Xinrui Jiang, Linlin Han, Feng Wang, Xian Liu, and Ping Wang. Faultinsight: Interpreting hyperscale data center host faults. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 141–152, 2024
2024
-
[2]
Reviewable automated decision- making: A framework for accountable algorithmic systems.Computer Law & Security Review, 41:105523, 2021
Jennifer Cobbe, Michelle Seng Ah Lee, and Jatinder Singh. Reviewable automated decision- making: A framework for accountable algorithmic systems.Computer Law & Security Review, 41:105523, 2021
2021
-
[3]
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C. Wallace. ERASER: A benchmark to evaluate rationalized NLP models. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4443–4458, 2020
2020
-
[4]
Towards A Rigorous Science of Interpretable Machine Learning
Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Root cause analysis of failures in microservices through causal discovery.Advances in Neural Information Processing Systems, 35:31158–31170, 2022
Azam Ikram, Sarthak Chakraborty, Subrata Mitra, Shiv Saini, Saurabh Bagchi, and Murat Kocaoglu. Root cause analysis of failures in microservices through causal discovery.Advances in Neural Information Processing Systems, 35:31158–31170, 2022
2022
-
[6]
Joshua A. Kroll. Outlining traceability: A principle for operationalizing accountability in computing systems. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021
2021
-
[7]
Kroll, Joanna Huey, Solon Barocas, Edward W
Joshua A. Kroll, Joanna Huey, Solon Barocas, Edward W. Felten, Joel R. Reidenberg, David G. Robinson, and Harlan Yu. Accountable algorithms.University of Pennsylvania Law Review, 165(3), 2017
2017
-
[8]
Bowman, and Ethan Perez
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil ˙e Lukoši¯ut˙e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Lar- son, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy ...
2023
-
[9]
Causal inference-based root cause analysis for online service systems with intervention recognition
Mingjie Li, Zeyan Li, Kanglin Yin, Xiaohui Nie, Wenchi Zhang, Kaixin Sui, and Dan Pei. Causal inference-based root cause analysis for online service systems with intervention recognition. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3230–3240, 2022
2022
-
[10]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023. 10
2023
-
[11]
Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence, 267:1–38, 2019
Tim Miller. Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence, 267:1–38, 2019
2019
-
[12]
AI risk management framework (AI RMF 1.0), 2023
National Institute of Standards and Technology. AI risk management framework (AI RMF 1.0), 2023
2023
-
[13]
GPT-4 system card, 2023
OpenAI. GPT-4 system card, 2023
2023
-
[14]
Faster, deeper, easier: crowdsourcing diagnosis of microservice kernel failure from user space
Yicheng Pan, Meng Ma, Xinrui Jiang, and Ping Wang. Faster, deeper, easier: crowdsourcing diagnosis of microservice kernel failure from user space. InISSTA ’21: 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event, Denmark, July 11-17, 2021, pages 646–657. ACM, 2021
2021
-
[15]
Flow-of-action: Sop enhanced llm-based multi-agent system for root cause analysis
Changhua Pei, Zexin Wang, Fengrui Liu, Zeyan Li, Yang Liu, Xiao He, Rong Kang, Tieying Zhang, Jianjun Chen, Jianhui Li, et al. Flow-of-action: Sop enhanced llm-based multi-agent system for root cause analysis. InCompanion Proceedings of the ACM on Web Conference 2025, pages 422–431, 2025
2025
-
[16]
White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes
Inioluwa Deborah Raji, Andrew Smart, Rebecca N. White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pages 33–44, 2020
2020
-
[17]
Exploring llm-based agents for root cause analysis
Devjeet Roy, Xuchao Zhang, Rashi Bhave, Chetan Bansal, Pedro Las-Casas, Rodrigo Fonseca, and Saravan Rajmohan. Exploring llm-based agents for root cause analysis. InCompanion pro- ceedings of the 32nd ACM international conference on the foundations of software engineering, pages 208–219, 2024
2024
-
[18]
Exploring LLM-based agents for root cause analysis
Devjeet Roy, Xuchao Zhang, Rashi Bhave, Chetan Bansal, Pedro Las-Casas, Rodrigo Fonseca, and Saravan Rajmohan. Exploring LLM-based agents for root cause analysis. InCompan- ion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, pages 208–219, 2024
2024
-
[19]
ϵ-diagnosis: Unsupervised and real-time diagnosis of small-window long-tail latency in large-scale microservice platforms
Huasong Shan, Yuan Chen, Haifeng Liu, Yunpeng Zhang, Xiao Xiao, Xiaofeng He, Min Li, and Wei Ding. ϵ-diagnosis: Unsupervised and real-time diagnosis of small-window long-tail latency in large-scale microservice platforms. InThe World Wide Web Conference, pages 3215–3222, 2019
2019
-
[20]
Jatinder Singh, Jennifer Cobbe, and Chris Norval. Decision provenance: Harnessing data flow for accountable systems.arXiv preprint arXiv:1804.05741, 2019
-
[21]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[22]
Towards llm-based failure localization in production-scale networks
Chenxu Wang, Xumiao Zhang, Runwei Lu, Xianshang Lin, Xuan Zeng, Xinlei Zhang, Zhe An, Gongwei Wu, Jiaqi Gao, Chen Tian, et al. Towards llm-based failure localization in production-scale networks. InProceedings of the ACM SIGCOMM 2025 Conference, pages 496–511, 2025
2025
-
[23]
Rcagent: Cloud root cause analysis by autonomous agents with tool-augmented large language models
Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. Rcagent: Cloud root cause analysis by autonomous agents with tool-augmented large language models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 4966–4974, 2024
2024
-
[24]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
2023
-
[25]
Lingzhe Zhang, Yunpeng Zhai, Tong Jia, Chiming Duan, Siyu Yu, Jinyang Gao, Bolin Ding, Zhonghai Wu, and Ying Li. Thinkfl: Self-refining failure localization for microservice systems via reinforcement fine-tuning.arXiv preprint arXiv:2504.18776, 2025. 11
-
[26]
Wei Zhang, Hongcheng Guo, Jian Yang, Zhoujin Tian, Yi Zhang, Chaoran Yan, Zhoujun Li, Tongliang Li, Xu Shi, Liangfan Zheng, et al. mabc: multi-agent blockchain-inspired collabora- tion for root cause analysis in micro-services architecture.arXiv preprint arXiv:2404.12135, 2024. 12 A Diagnostic Justification Artifact Schema The central object in our method...
-
[27]
Evidence before narrative.Final explanations should be grounded in explicit evidence and findings rather than written directly as free-form stories
-
[28]
Competition before commitment.Candidate hypotheses should compete under claim-level adjudication rather than being accepted in first-write fashion
-
[29]
Conflicts should be preserved.Contradictory findings and unresolved tensions are part of accountable reasoning and should remain visible in the exported artifact
-
[30]
Uncertainty is a first-class outcome.Unresolved states such as stalled or need_more_evidenceare legitimate outputs when discriminative support is insufficient. These principles motivate the specific mechanisms evaluated in our ablation study: evidence ground- ing, claim adjudication, hypothesis competition, and coverage-based termination control. B.3 From...
-
[31]
After each investigation cycle, use check_termination_conditions
-
[32]
If termination conditions are met for resolved or provisionally_resolved, you MUST immediately use propose_termination
-
[33]
Refresh or refine the hypotheses once if requested; otherwise terminate only with insufficient_information
If the tool indicates stalled, do NOT present it as a clean success. Refresh or refine the hypotheses once if requested; otherwise terminate only with insufficient_information
-
[34]
", source=
Do not rely on free-text phrases to imply alternatives or contradictions; encode them in structured fields. Prompt excerpt C: evidence-grounding and whiteboard discipline **CRITICAL REQUIREMENTS:** - Evidence Chain: All findings must be supported by structured evidence. - Whiteboard Central: All diagnostic progress tracked on the diagnostic whiteboard. - ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.