Displacement Is Not Direction: Evaluating Fidelity Metrics for Quantized LLM Deployment
Pith reviewed 2026-06-26 20:56 UTC · model grok-4.3
The pith
KL divergence correlates with LLM benchmark scores overall but loses all correlation near the full-precision baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
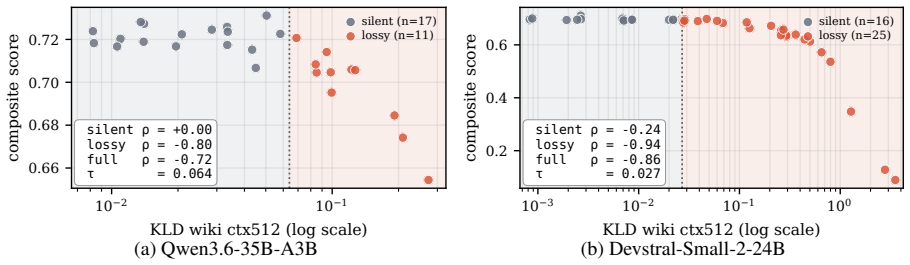
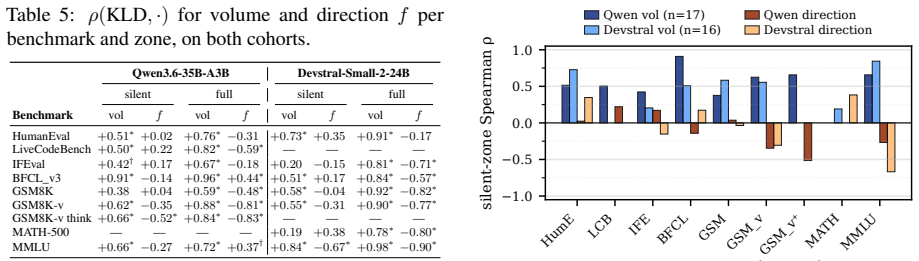
KLD is strongly correlated with benchmark score over the full cohort (ρ=-0.72 on Qwen and ρ=-0.86 on Devstral, both with p<0.001). However, this relationship collapses to non-significance in the near-baseline silent zone (ρ=+0.00 on Qwen and ρ=-0.24, p=0.36, on Devstral). KLD primarily measures the volume of disagreement with the reference, with silent-zone composite ρ=+0.94 (p<0.001) on Qwen and +0.55 (p=0.03) on Devstral, while its relationship to the direction of those disagreements is weak and task-conditional.
What carries the argument
The volume-versus-direction decomposition of per-token KL divergence, separating the extent of token-level probability changes from whether those changes improve or degrade task accuracy.
If this is right
- KLD cannot reliably rank or select among near-lossless quantizations.
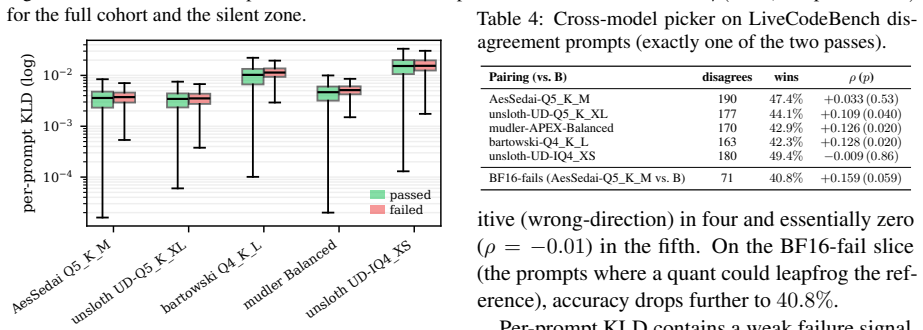
- Per-prompt KLD shows only weak power to flag individual prompt failures on code tasks.
- Using KLD to route between models on disagreement prompts yields accuracy only slightly above random.
- The loss of predictive power holds for multiple KLD aggregations, perplexity variants, and calibration settings.
Where Pith is reading between the lines
- Deployment decisions in the high-fidelity regime may need metrics that explicitly track error direction rather than total displacement.
- Direct benchmark sweeps remain necessary when candidate models differ only in small distributional ways.
- Task-specific or direction-aware fidelity measures could be developed by weighting disagreements according to their effect on labeled examples.
Load-bearing premise
The chosen downstream benchmarks and the definition of the near-baseline silent zone supply an unbiased ground truth for whether small distributional shifts affect task performance.
What would settle it
Re-running the correlation analysis on a fresh set of near-baseline quantizations or models and obtaining a statistically significant negative correlation between KLD and benchmark scores.
Figures
read the original abstract
Fidelity metrics, such as per-token KL divergence (KLD) against a high-precision reference, are often used in practice as low-cost proxies for benchmark quality. We test this practice on a 28-quant cohort of Qwen3.6-35B-A3B and a 41-quant cohort of Devstral-Small-2-24B, evaluated across a suite of downstream benchmarks. We find that KLD is strongly correlated with benchmark score over the full cohort ($\rho=-0.72$ on Qwen and $\rho=-0.86$ on Devstral, both with $p<0.001$). However, this relationship collapses to non-significance in the near-baseline silent zone ($\rho=+0.00$ on Qwen and $\rho=-0.24$, $p=0.36$, on Devstral). This collapse persists across 14 measurement variants, including different KLD aggregations, perplexity formulations, top-1 agreement, calibration corpora, and context lengths. At the per-prompt level, KLD has only weak failure-prediction power on code, with failed-vs-passed geometric-mean ratios in $[1.08,1.22]$ across five models on LiveCodeBench, and fails as a cross-model router, achieving only $42.3\%-49.4\%$ accuracy on disagreement prompts. We trace the collapse to a structural decomposition: KLD primarily measures the volume of disagreement with the reference, with silent-zone composite $\rho=+0.94$ ($p<0.001$) on Qwen and $+0.55$ ($p=0.03$) on Devstral, while its relationship to the direction of those disagreements is weak and task-conditional.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates fidelity metrics such as per-token KL divergence (KLD) as proxies for downstream benchmark performance in quantized LLMs. Using cohorts of 28 and 41 quantized variants of Qwen3.6-35B-A3B and Devstral-Small-2-24B respectively, it reports strong negative correlations between KLD and benchmark scores over the full cohorts (ρ = -0.72 and -0.86, p < 0.001), but finds these correlations collapse to non-significance inside a 'near-baseline silent zone' (ρ = 0.00 and -0.24, p = 0.36). The collapse is claimed to persist across 14 measurement variants (different KLD aggregations, perplexity, top-1 agreement, corpora, context lengths). Additional results show weak per-prompt failure prediction on LiveCodeBench and poor cross-model routing accuracy (42.3–49.4%). The authors decompose KLD into a volume-of-disagreement component (strongly correlated with the zone composite) versus a direction component (weak and task-conditional).
Significance. If the central empirical observation holds after addressing definitional issues, the work would be significant for quantized LLM deployment practice: it supplies concrete evidence that common low-cost proxies like KLD lose predictive value precisely in the low-error regime that matters most for production use. The volume-versus-direction decomposition offers a reusable conceptual lens. The study is strengthened by its use of two distinct model families, explicit correlation coefficients with p-values, and explicit testing across multiple measurement variants; these elements make the reported attenuation falsifiable and reproducible in principle.
major comments (2)
- [Abstract, §3] Abstract and §3 (silent-zone construction): the 'near-baseline silent zone' is introduced without a pre-specified threshold, variance cutoff, or hold-out procedure for its boundaries. Because the full-cohort ρ is driven by the tail of severely degraded quantizations, restricting analysis to the low-variance interior can mechanically attenuate the correlation even if KLD continues to track residual differences; the claim that the collapse 'persists across 14 measurement variants' does not mitigate this, as all variants share the same post-selected subset.
- [Abstract] Abstract: the per-prompt failure-prediction results (geometric-mean ratios [1.08,1.22] on LiveCodeBench) and routing accuracy (42.3–49.4%) are presented as supporting evidence that KLD fails as a fine-grained signal, yet no ablation is shown that isolates whether these weak numbers arise from the same volume/direction decomposition or from benchmark-specific noise; without that link the per-prompt findings remain only loosely connected to the headline correlation-collapse claim.
minor comments (2)
- Table or figure captions should explicitly state the exact cohort sizes (28 and 41) and the precise benchmark suite used for the reported ρ values.
- Notation for the 14 variants is summarized in the abstract but would benefit from a single consolidated table listing each variant, its aggregation method, and the resulting silent-zone ρ.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the silent-zone construction and the linkage of per-prompt results. We address each point below with plans for revision where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (silent-zone construction): the 'near-baseline silent zone' is introduced without a pre-specified threshold, variance cutoff, or hold-out procedure for its boundaries. Because the full-cohort ρ is driven by the tail of severely degraded quantizations, restricting analysis to the low-variance interior can mechanically attenuate the correlation even if KLD continues to track residual differences; the claim that the collapse 'persists across 14 measurement variants' does not mitigate this, as all variants share the same post-selected subset.
Authors: We agree that the zone definition was post-hoc and could introduce selection bias. In revision we will pre-specify the silent zone via a fixed criterion (benchmark degradation ≤2% relative to FP16 baseline) and add sensitivity analyses using alternative thresholds plus a hold-out procedure for zone boundaries. This will test whether the correlation collapse holds independently of the shared subset. revision: yes
-
Referee: [Abstract] Abstract: the per-prompt failure-prediction results (geometric-mean ratios [1.08,1.22] on LiveCodeBench) and routing accuracy (42.3–49.4%) are presented as supporting evidence that KLD fails as a fine-grained signal, yet no ablation is shown that isolates whether these weak numbers arise from the same volume/direction decomposition or from benchmark-specific noise; without that link the per-prompt findings remain only loosely connected to the headline correlation-collapse claim.
Authors: We acknowledge the connection is not explicit. The per-prompt results illustrate KLD's practical shortcomings, but we did not ablate their relation to the volume/direction split. In revision we will add a discussion paragraph noting that the volume component (high correlation with the zone composite) likely explains the weak per-prompt signal, while direction remains task-conditional; we will also flag benchmark noise as a possible confounder. revision: partial
Circularity Check
No circularity; direct empirical measurement study
full rationale
The paper reports empirical correlations (ρ values) between KLD and benchmark scores on fixed quantization cohorts, with a post-hoc partition into a 'near-baseline silent zone' based on proximity to the unquantized reference. No equations, derivations, fitted parameters, or self-citations are present that reduce any reported result to an input by construction. The correlation collapse is a measured outcome on the partitioned data, not a self-definitional or fitted-input prediction. This matches the default case of a self-contained empirical study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Pearson correlation and associated p-values are appropriate for relating KLD values to benchmark scores under the observed data distributions.
- domain assumption The selected downstream benchmarks serve as valid ground-truth measures of model quality for the purpose of evaluating fidelity metrics.
Reference graph
Works this paper leans on
-
[1]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Accuracy is Not All You Need , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[2]
``Give Me BF 16 or Give Me Death''? Accuracy-Performance Trade-Offs in LLM Quantization
Kurtic, Eldar and Marques, Alexandre Noll and Pandit, Shubhra and Kurtz, Mark and Alistarh, Dan. ``Give Me BF 16 or Give Me Death''? Accuracy-Performance Trade-Offs in LLM Quantization. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1304
-
[3]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[4]
2025 , url=
Naman Jain and King Han and Alex Gu and Wen-Ding Li and Fanjia Yan and Tianjun Zhang and Sida Wang and Armando Solar-Lezama and Koushik Sen and Ion Stoica , booktitle=. 2025 , url=
2025
-
[5]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[6]
Gonzalez , booktitle=
Shishir G Patil and Huanzhi Mao and Fanjia Yan and Charlie Cheng-Jie Ji and Vishnu Suresh and Ion Stoica and Joseph E. Gonzalez , booktitle=. The Berkeley Function Calling Leaderboard (. 2025 , url=
2025
-
[7]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[8]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[9]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[10]
2024 IEEE International Symposium on Circuits and Systems (ISCAS) , title=
Nikoli. 2024 IEEE International Symposium on Circuits and Systems (ISCAS) , title=. 2024 , volume=
2024
-
[11]
Zhen Zheng and Xiaonan Song and Chuanjie Liu , year=. 2412.14590 , archivePrefix=
-
[12]
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song , booktitle=
-
[13]
Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song , booktitle =
-
[14]
2023 , url =
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , booktitle =. 2023 , url =
2023
-
[15]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Exploring the Trade-Offs: Quantization Methods, Task Difficulty, and Model Size in Large Language Models From Edge to Giant , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month = aug, note =. doi:10.24963/ijcai.2025/902 , url =
-
[16]
Fan Yuan and Yuchen Yan and Yifan Jiang and Haoran Zhao and Tao Feng and Jinyan Chen and Yanwei Lou and Wenqi Zhang and Yongliang Shen and Weiming Lu and Jun Xiao and Yueting Zhuang , year=. 2509.25160 , archivePrefix=
-
[17]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[18]
Deiseroth, Bj. Divergent Token Metrics: Measuring degradation to prune away LLM components -- and optimize quantization. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.377
-
[19]
Compressing
Ajay Kumar Jaiswal and Zhe Gan and Xianzhi Du and Bowen Zhang and Zhangyang Wang and Yinfei Yang , booktitle=. Compressing. 2024 , url=
2024
-
[20]
2023 , url=
llama.cpp , author=. 2023 , url=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.