StaminaBench: Stress-Testing Coding Agents over 100 Interaction Turns
Pith reviewed 2026-06-26 19:45 UTC · model grok-4.3
The pith
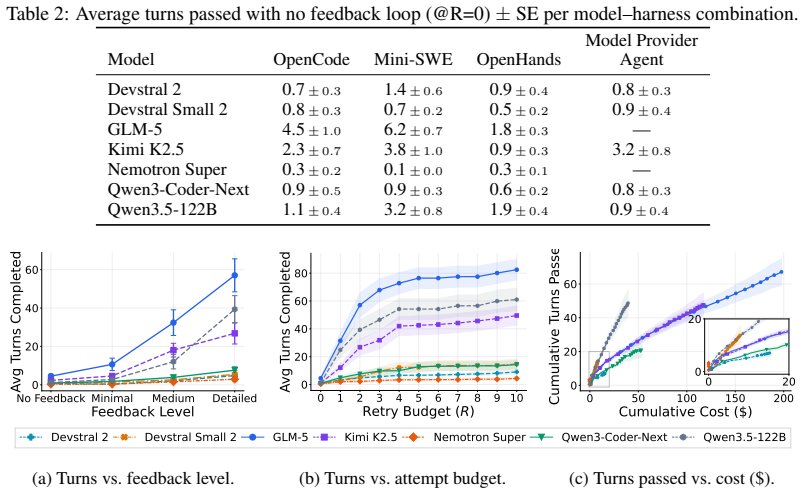
Coding agents fail within 5-6 turns on 100-turn tasks, but passing test feedback extends survival up to 12 times and harness choice creates up to 6 times performance gaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StaminaBench evaluates agent stamina by requiring implementation of a REST API followed by 100 successive valid change requests drawn from structured samplers; across 20 scenarios all tested models fail within 5-6 turns, passing test feedback back to the agent improves the number of passed turns by up to 12x, and stronger models display up to a 6x gap between their best and worst harness while weaker models fail regardless of harness.
What carries the argument
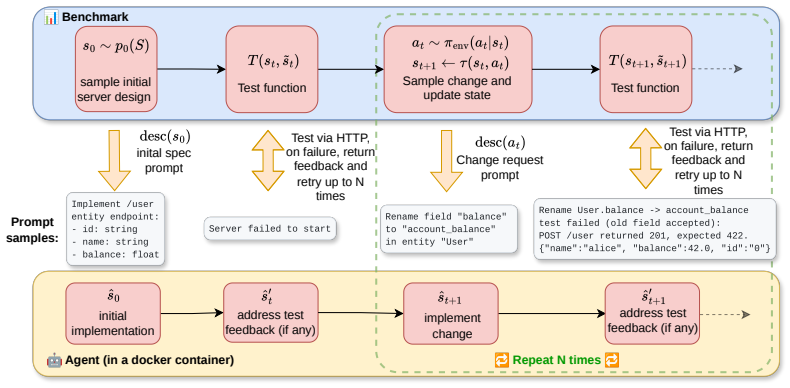
StaminaBench, a black-box benchmark that runs the agent and target server in isolation and communicates via HTTP while applying procedurally generated change sequences from either hardcoded or LLM-driven samplers constrained to a structured action space.
If this is right
- All tested models produce bugs when iterating without external test feedback.
- Including test results in the prompt loop multiplies the number of successful turns by as much as 12.
- Harness design matters more than raw model strength for weaker models and still creates large gaps for stronger ones.
- The benchmark's fully programmatic test generation and isolated HTTP interface enable reproducible, language-agnostic evaluation of multi-turn behavior.
- Releasing the tasks and code supports further work on sustained coding agent performance.
Where Pith is reading between the lines
- Real-world coding sessions may require explicit test integration loops to reach dozens of turns.
- Future agents could be trained or prompted specifically to request and interpret test feedback rather than relying on harnesses.
- The 6x harness gap suggests that interface design between model and environment is a higher-leverage research target than incremental model scaling for this workload.
- If the structured action space limits diversity too much, extending the sampler to include more open-ended change types would test whether the early failure pattern persists.
Load-bearing premise
The procedurally generated change sequences represent the kinds of follow-up requests that actually occur in real development sessions.
What would settle it
Running the same agents on 100-turn sessions drawn from actual recorded developer interactions instead of the benchmark's samplers and measuring whether failure rates remain under 6 turns.
Figures
read the original abstract
We introduce StaminaBench, a benchmark that measures the stamina of coding agents: how many consecutive interaction turns (change requests) they can handle before failing. Unlike the prevailing fraction-of-tasks-solved metric, this matches real vibe-coding where sessions run dozens or hundreds of turns. In StaminaBench, agents implement a REST API server and modify it across a tunable number of procedurally generated follow-up change requests - 100 in our experiments, resulting in codebases of up to 6,000 lines. Tests are generated fully programmatically without LLM involvement, ensuring reproducibility and reliability; change sequences are drawn from either a hardcoded or LLM-driven sampler, both constrained to a structured action space to ensure changes are valid. The agent and the server run in an isolated environment and communicate with the benchmark through HTTP, making testing fully black-box and language-agnostic. We evaluate six agent harnesses paired with seven open-source LLMs across 20 scenarios of 100 turns each and find that: (1) all the tested models fail within 5-6 turns, confirming that vibe-coding-style programming without thorough testing produces bugs; (2) passing test feedback back to the agent and allowing it to retry improves passed turn count by up to 12x; and (3) a good harness is required for strong performance: stronger models exhibit up to a 6x gap between their best and worst harness, while weaker models fail with any harness. We release the benchmark and the generated tasks to enable further research into multi-turn coding agent behavior. Benchmark code and data: github.com/amazon-science/StaminaBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StaminaBench, a benchmark for measuring coding-agent stamina over 100 consecutive interaction turns on implementing and iteratively modifying a REST API server. Change sequences are produced by hardcoded or LLM-driven samplers inside a fixed structured action space; tests are generated fully programmatically. Evaluation of six harnesses paired with seven open-source LLMs across 20 scenarios reports that all models fail within 5-6 turns, that passing test feedback improves passed-turn count by up to 12x, and that harness quality produces up to a 6x performance gap between best and worst harness for stronger models. The benchmark, tasks, and code are released.
Significance. If the synthetic change sequences are representative, the results would demonstrate that current agents cannot sustain long-horizon vibe-coding sessions and would highlight the value of test feedback and harness design. The fully programmatic test generation, black-box HTTP interface, isolated execution environment, and public release of benchmark code and data constitute clear strengths for reproducibility and extensibility.
major comments (2)
- [Abstract] Abstract: the headline claim that the observed 5-6 turn failures 'confirm that vibe-coding-style programming without thorough testing produces bugs' rests on the unvalidated premise that the procedurally generated sequences (hardcoded or LLM-driven samplers inside the structured action space) match the distribution of real multi-turn developer change requests; no empirical comparison to commit histories, issue trackers, or session logs is reported.
- [Abstract / Evaluation] Abstract / §4 (Evaluation): the quantitative claims (5-6 turn failures, 12x improvement from test feedback, 6x harness gap) are presented without reported details on validation of the change samplers, error-handling behavior inside the isolated environment, or statistical significance testing across the 20 scenarios, which are load-bearing for assessing whether the failure modes are robust or artifacts of the synthetic setup.
minor comments (1)
- A table or diagram explicitly enumerating the allowed actions in the structured action space would clarify the constraints under which changes remain valid.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript to improve clarity and temper certain claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the observed 5-6 turn failures 'confirm that vibe-coding-style programming without thorough testing produces bugs' rests on the unvalidated premise that the procedurally generated sequences (hardcoded or LLM-driven samplers inside the structured action space) match the distribution of real multi-turn developer change requests; no empirical comparison to commit histories, issue trackers, or session logs is reported.
Authors: We agree that the change sequences are synthetic by design and that no empirical validation against real commit histories or session logs is provided. The benchmark intentionally uses a constrained, structured action space to guarantee validity and reproducibility rather than attempting to replicate real-world distributions. The abstract phrasing was illustrative of the observed failure modes rather than a distributional claim. We will revise the abstract to remove the word 'confirm' and instead describe the results as demonstrating the difficulty of sustaining long sessions without test feedback. revision: yes
-
Referee: [Abstract / Evaluation] Abstract / §4 (Evaluation): the quantitative claims (5-6 turn failures, 12x improvement from test feedback, 6x harness gap) are presented without reported details on validation of the change samplers, error-handling behavior inside the isolated environment, or statistical significance testing across the 20 scenarios, which are load-bearing for assessing whether the failure modes are robust or artifacts of the synthetic setup.
Authors: We will add explicit details in Sections 3 and 4 on how the samplers enforce validity within the action space, the error-handling and isolation mechanisms (Docker-based black-box HTTP interface), and quantitative variability across the 20 scenarios (different sampler seeds and model pairings). Where raw data permit, we will also report standard deviations or ranges to support the robustness of the reported factors (5-6 turns, 12x, 6x). revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential reductions
full rationale
The paper introduces StaminaBench as an empirical evaluation framework for multi-turn coding agents. It reports direct experimental outcomes (failure within 5-6 turns, 12x improvement from test feedback, 6x harness gaps) from running six harnesses and seven LLMs on 20 procedurally generated 100-turn scenarios. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes appear anywhere in the manuscript. The central claims rest on observed performance metrics rather than any chain that reduces to self-definition or self-citation. The representativeness of the action space to real development is a separate validity question outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opencode
Anomaly. Opencode. https://github.com/anomalyco/opencode. Accessed: 2026-05-05
2026
-
[2]
Claude code
Anthropic. Claude code. https://www.anthropic.com/claude-code, 2025. Accessed: 2026-05-06
2025
-
[3]
Cursor: The ai code editor
Anysphere. Cursor: The ai code editor. https://cursor.com/, 2025. Accessed: 2026-05-06
2025
-
[4]
Program synthesis with large language models, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[5]
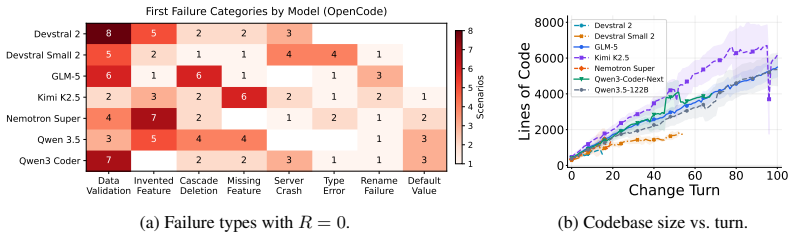
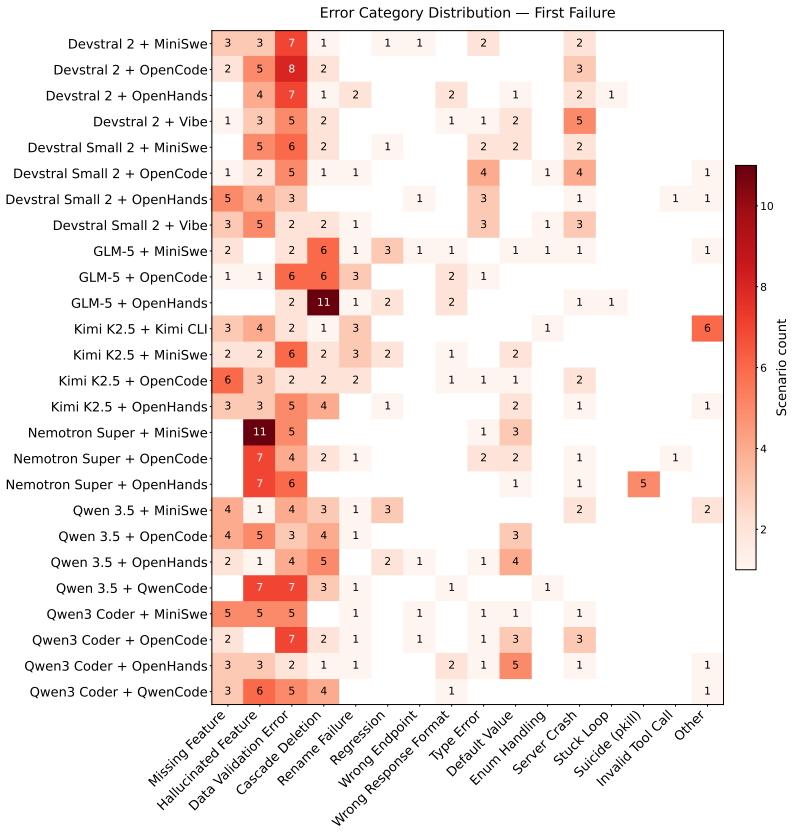
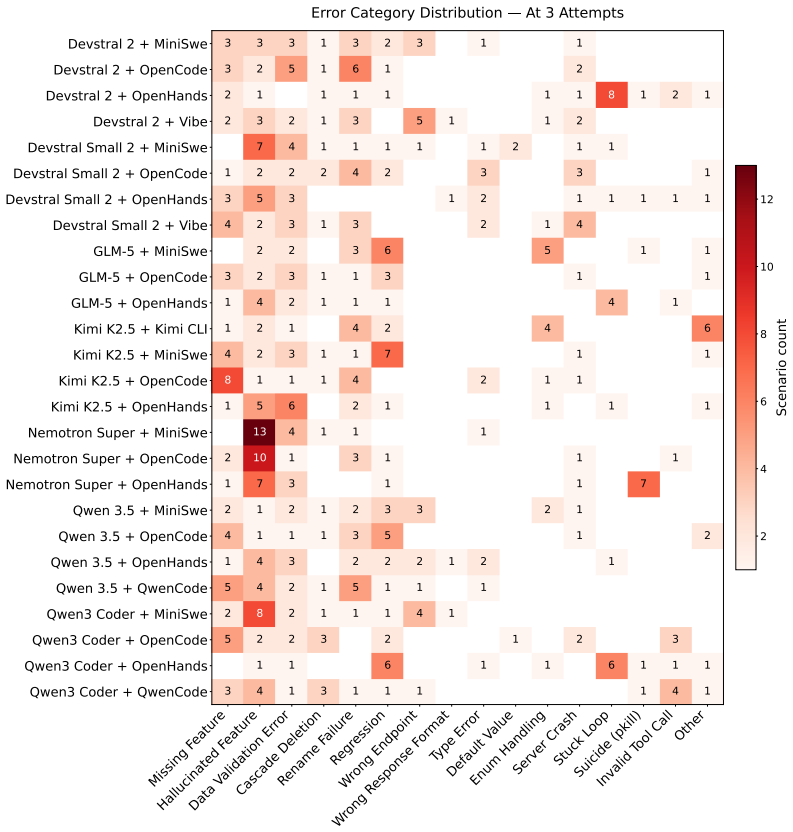
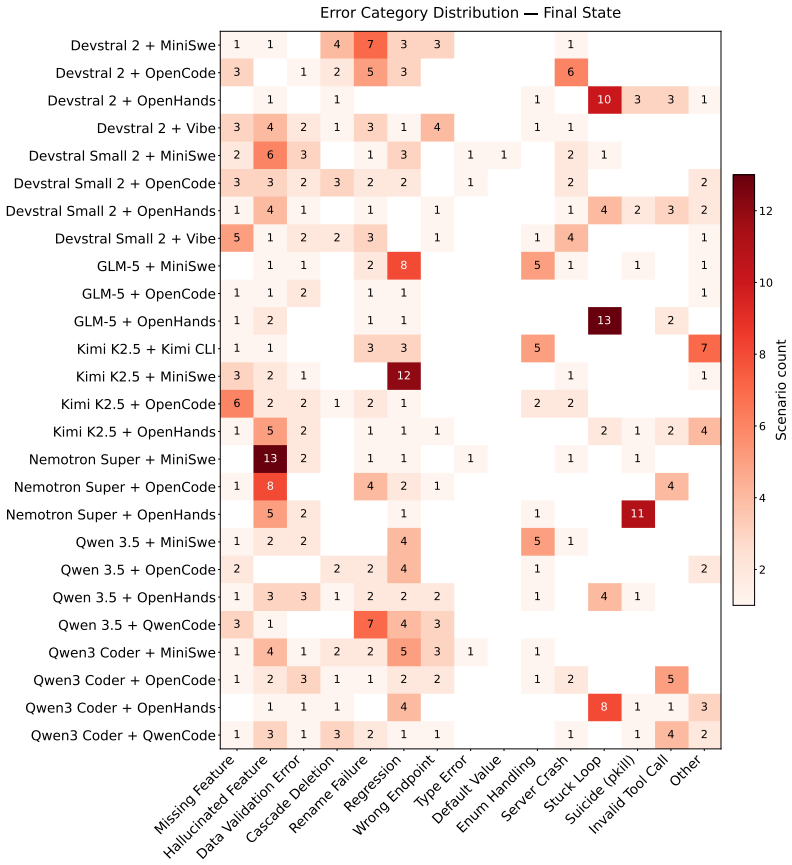
Vending-bench: A benchmark for long-term coherence of autonomous agents, 2025
Axel Backlund and Lukas Petersson. Vending-bench: A benchmark for long-term coherence of autonomous agents, 2025. URLhttps://arxiv.org/abs/2502.15840
arXiv 2025
-
[6]
τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025. URL https://arxiv. org/abs/2506.07982
Pith/arXiv arXiv 2025
-
[7]
Qwen3- coder-next technical report, 2026
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, Zeyao Ma, Kashun Shum, Xuwu Wang, Jinxi Wei, Jiaxi Yang, Jiajun Zhang, Lei Zhang, Zongmeng Zhang, Wenting Zhao, and Fan Zhou. Qwen3- coder-next technical report, 2026. URLhttps://arxiv.org/abs/2603.00729
Pith/arXiv arXiv 2026
-
[8]
Swe-ci: Evaluating agent capabilities in maintaining codebases via continuous integration, 2026
Jialong Chen, Xander Xu, Hu Wei, Chuan Chen, and Bing Zhao. Swe-ci: Evaluating agent capabilities in maintaining codebases via continuous integration, 2026. URL https://arxiv. org/abs/2603.03823
arXiv 2026
-
[9]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[10]
Evoclaw: Evaluating ai agents on continuous software evolution, 2026
Gangda Deng, Zhaoling Chen, Zhongming Yu, Haoyang Fan, Yuhong Liu, Yuxin Yang, Dhruv Parikh, Rajgopal Kannan, Le Cong, Mengdi Wang, Qian Zhang, Viktor Prasanna, Xiangru Tang, and Xingyao Wang. Evoclaw: Evaluating ai agents on continuous software evolution, 2026. URLhttps://arxiv.org/abs/2603.13428
Pith/arXiv arXiv 2026
-
[11]
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
Pith/arXiv arXiv 2025
-
[12]
Nl2repo-bench: Towards long-horizon repository generation evaluation of coding agents, 2026
Jingzhe Ding, Shengda Long, Changxin Pu, Huan Zhou, Hongwan Gao, Xiang Gao, Chao He, Yue Hou, Fei Hu, Zhaojian Li, Weiran Shi, Zaiyuan Wang, Daoguang Zan, Chenchen Zhang, Xiaoxu Zhang, Qizhi Chen, Xianfu Cheng, Bo Deng, Qingshui Gu, Kai Hua, Juntao Lin, Pai Liu, Mingchen Li, Xuanguang Pan, Zifan Peng, Yujia Qin, Yong Shan, Zhewen Tan, Weihao Xie, Zihan Wa...
arXiv 2026
-
[13]
Yukang Feng, Jianwen Sun, Zelai Yang, Jiaxin Ai, Chuanhao Li, Zizhen Li, Fanrui Zhang, Kang He, Rui Ma, Jifan Lin, Jie Sun, Yang Xiao, Sizhuo Zhou, Wenxiao Wu, Yiming Liu, Pengfei Liu, Yu Qiao, Shenglin Zhang, and Kaipeng Zhang. Longcli-bench: A preliminary benchmark and study for long-horizon agentic programming in command-line interfaces, 2026. URLhttps...
arXiv 2026
-
[14]
Publication, University of California, Irvine, 2000
Roy Thomas Fielding.Architectural styles and the design of network-based software architec- tures. Publication, University of California, Irvine, 2000. URL https://www.ics.uci.edu/ ~fielding/pubs/dissertation/top.htm
2000
-
[15]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunx- iang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Z...
Pith/arXiv arXiv 2026
-
[16]
Gemini cli
Google. Gemini cli. https://github.com/google-gemini/gemini-cli, 2025. Accessed: 2026-05-06
2025
-
[17]
Hojae Han, Seung won Hwang, Rajhans Samdani, and Yuxiong He. Convcodeworld: Bench- marking conversational code generation in reproducible feedback environments, 2025. URL https://arxiv.org/abs/2502.19852
arXiv 2025
-
[18]
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2):65–70, 1979. ISSN 03036898, 14679469. URL http://www.jstor.org/ stable/4615733
arXiv 1979
-
[19]
Context rot: How increasing input tokens impacts llm performance
Kelly Hong, Anton Troynikov, and Jeff Huber. Context rot: How increasing input tokens impacts llm performance. Technical report, Chroma, July 2025. URL https://trychroma. com/research/context-rot
2025
-
[20]
Ruler: What’s the real context size of your long-context language models?, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?, 2024. URLhttps://arxiv.org/abs/2404.06654
Pith/arXiv arXiv 2024
-
[21]
R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents, 2025
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2e- gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents, 2025. URLhttps://arxiv.org/abs/2504.07164. 11
arXiv 2025
-
[22]
Llmlingua: Com- pressing prompts for accelerated inference of large language models, 2023
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Com- pressing prompts for accelerated inference of large language models, 2023. URL https: //arxiv.org/abs/2310.05736
arXiv 2023
-
[23]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations (ICLR), 2024. URL https://arxiv. org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[24]
Needle in a haystack - pressure testing llms
Gregory Kamradt. Needle in a haystack - pressure testing llms. https://github.com/ gkamradt/LLMTest_NeedleInAHaystack, 2023. Accessed: 2026-05-06
2023
-
[25]
Holistic agent leaderboard: The missing infrastructure for ai agent evaluation, 2025
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, Kangheng Liu, Botao Yu, Amit Arora, Dongyoon Hahm, Harsh Trivedi, Huan Sun, Juyong Lee, Tengjun Jin, Yifan Mai, Yifei Zhou, Yuxuan Zhu, Rishi Bommasani, Daniel Kang, Da...
arXiv 2025
-
[26]
Ziegler, Elizabeth Barnes, and Lawrence Chan
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney V on Arx, Ryan Bloom, Thomas Broadley, Haoxing Du, Brian Goodrich, Nikola Jurkovic, Luke Harold Miles, Seraphina Nix, Tao Lin, Neev Parikh, David Rein, Lucas Jun Koba Sato, Hjalmar Wijk, Daniel M. Ziegler, Elizabeth Barnes, and Lawrence...
arXiv 2026
-
[27]
Llms get lost in multi-turn conversation, 2025
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. Llms get lost in multi-turn conversation, 2025. URLhttps://arxiv.org/abs/2505.06120
Pith/arXiv arXiv 2025
-
[28]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023. URL https://arxiv.org/abs/2307.03172
Pith/arXiv arXiv 2023
-
[29]
Agentbench: Evaluating llms as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents. InInternational Conference on Learning Representatio...
Pith/arXiv arXiv 2024
-
[30]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
Pith/arXiv arXiv 2026
-
[31]
Mistral vibe
Mistral AI. Mistral vibe. https://github.com/mistralai/mistral-vibe. Accessed: 2026-05-05
2026
-
[32]
Devstral 2 and vibe cli
Mistral AI. Devstral 2 and vibe cli. https://mistral.ai/news/devstral-2-vibe-cli ,
-
[33]
Accessed: 2026-05-05. 12
2026
-
[34]
Kimi cli
Moonshot AI. Kimi cli. https://github.com/MoonshotAI/kimi-cli. Accessed: 2026- 05-05
2026
-
[35]
NVIDIA, :, Aakshita Chandiramani, Aaron Blakeman, Abdullahi Olaoye, Abhibha Gupta, Abhilash Somasamudramath, Abhinav Khattar, Adeola Adesoba, Adi Renduchintala, Adil Asif, Aditya Agrawal, Aditya Vavre, Ahmad Kiswani, Aishwarya Padmakumar, Ajay Hotchandani, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, Aleksandr Shaposhnikov, Alex Gron- skiy, Alex K...
-
[36]
URLhttps://arxiv.org/abs/2604.12374
-
[37]
Openai codex.https://openai.com/codex/, 2025
OpenAI. Openai codex.https://openai.com/codex/, 2025. Accessed: 2026-05-06
2025
-
[38]
Openapi initiative
OpenAPI Initiative. Openapi initiative. https://www.openapis.org/. Accessed: 2026-05- 06
2026
-
[39]
Openhands
OpenHands. Openhands. https://github.com/OpenHands/OpenHands. Accessed: 2026- 05-05
2026
-
[40]
Slopcodebench: Benchmarking how coding agents degrade over long-horizon iterative tasks, 2026
Gabriel Orlanski, Devjeet Roy, Alexander Yun, Changho Shin, Alex Gu, Albert Ge, Dyah Adila, Frederic Sala, and Aws Albarghouthi. Slopcodebench: Benchmarking how coding agents degrade over long-horizon iterative tasks, 2026. URLhttps://arxiv.org/abs/2603. 24755
2026
-
[41]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[42]
Training software engineering agents and verifiers with swe-gym, 2025
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with swe-gym, 2025. URL https: //arxiv.org/abs/2412.21139. 14
Pith/arXiv arXiv 2025
-
[43]
Userbench: An interactive gym environment for user-centric agents, 2025
Cheng Qian, Zuxin Liu, Akshara Prabhakar, Zhiwei Liu, Jianguo Zhang, Haolin Chen, Heng Ji, Weiran Yao, Shelby Heinecke, Silvio Savarese, Caiming Xiong, and Huan Wang. Userbench: An interactive gym environment for user-centric agents, 2025. URL https://arxiv.org/ abs/2507.22034
arXiv 2025
-
[44]
Locobench: A benchmark for long-context large language models in complex software engineering, 2025
Jielin Qiu, Zuxin Liu, Zhiwei Liu, Rithesh Murthy, Jianguo Zhang, Haolin Chen, Shiyu Wang, Ming Zhu, Liangwei Yang, Juntao Tan, Zhepeng Cen, Cheng Qian, Shelby Heinecke, Weiran Yao, Silvio Savarese, Caiming Xiong, and Huan Wang. Locobench: A benchmark for long-context large language models in complex software engineering, 2025. URL https: //arxiv.org/abs/...
arXiv 2025
-
[45]
Qwen code
Qwen Team. Qwen code. https://github.com/QwenLM/qwen-code. Accessed: 2026-05- 05
2026
-
[46]
Qwen Team. Qwen3.5. https://qwen.ai/blog?id=qwen3.5, 2026. Accessed: 2026-05-05
2026
-
[47]
Alfworld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. InInternational Conference on Learning Representations (ICLR), 2021. URL https://arxiv.org/abs/2010.03768
Pith/arXiv arXiv 2021
-
[48]
The illusion of diminishing returns: Measuring long horizon execution in llms
Akshit Sinha, Arvindh Arun, Shashwat Goel, Steffen Staab, and Jonas Geiping. The illusion of diminishing returns: Measuring long horizon execution in llms. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://arxiv.org/abs/2509.09677
arXiv 2026
-
[49]
Mini-swe-agent
SWE-agent Team. Mini-swe-agent. https://github.com/SWE-agent/mini-swe-agent . Accessed: 2026-05-05
2026
-
[50]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
Pith/arXiv arXiv 2026
-
[51]
Minh V . T. Thai, Tue Le, Dung Nguyen Manh, Huy Phan Nhat, and Nghi D. Q. Bui. Swe- evo: Benchmarking coding agents in long-horizon software evolution scenarios, 2026. URL https://arxiv.org/abs/2512.18470
Pith/arXiv arXiv 2026
-
[52]
Ai agentic pro- gramming: A survey of techniques, challenges, and opportunities, 2025
Huanting Wang, Jingzhi Gong, Huawei Zhang, Jie Xu, and Zheng Wang. Ai agentic pro- gramming: A survey of techniques, challenges, and opportunities, 2025. URL https: //arxiv.org/abs/2508.11126
arXiv 2025
-
[53]
Codeflowbench: A multi-turn, iterative benchmark for complex code generation, 2026
Sizhe Wang, Zhengren Wang, Dongsheng Ma, Yongan Yu, Rui Ling, Zhiyu Li, Feiyu Xiong, and Wentao Zhang. Codeflowbench: A multi-turn, iterative benchmark for complex code generation, 2026. URLhttps://arxiv.org/abs/2504.21751
Pith/arXiv arXiv 2026
-
[54]
Mint: Evaluating llms in multi-turn interaction with tools and language feedback, 2024
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. Mint: Evaluating llms in multi-turn interaction with tools and language feedback, 2024. URL https://arxiv.org/abs/2309.10691
arXiv 2024
-
[55]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for ai soft...
Pith/arXiv arXiv 2025
-
[56]
Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80–83,
Frank Wilcoxon. Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80–83,
- [57]
-
[58]
Xueqing Wu, Zihan Xue, Da Yin, Shuyan Zhou, Kai-Wei Chang, Nanyun Peng, and Yeming Wen. Frontalk: Benchmarking front-end development as conversational code generation with multi-modal feedback, 2025. URLhttps://arxiv.org/abs/2601.04203
Pith/arXiv arXiv 2025
-
[59]
Travelplanner: A benchmark for real-world planning with language agents
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. Travelplanner: A benchmark for real-world planning with language agents. In International Conference on Machine Learning (ICML), 2024. URL https://arxiv.org/ abs/2402.01622
arXiv 2024
-
[60]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URL https: //arxiv.org/abs/2...
Pith/arXiv arXiv 2024
-
[61]
John Yang, Carlos E. Jimenez, Alex L. Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R. Narasimhan, Diyi Yang, Sida I. Wang, and Ofir Press. Swe-bench multimodal: Do ai systems generalize to visual software domains?, 2024. URLhttps://arxiv.org/abs/2410.03859. 16
arXiv 2024
-
[62]
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents, 2025. URLhttps://arxiv.org/abs/2504.21798
Pith/arXiv arXiv 2025
-
[63]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024. URL https://arxiv.org/abs/ 2406.12045
Pith/arXiv arXiv 2024
-
[64]
Multi-swe-bench: A multilingual benchmark for issue resolving, 2025
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. Multi-swe-bench: A multilingual benchmark for issue resolving, 2025. URLhttps://arxiv.org/abs/2504.02605
Pith/arXiv arXiv 2025
-
[65]
Commit0: Library generation from scratch, 2024
Wenting Zhao, Nan Jiang, Celine Lee, Justin T Chiu, Claire Cardie, Matthias Gallé, and Alexander M Rush. Commit0: Library generation from scratch, 2024. URL https://arxiv. org/abs/2412.01769
arXiv 2024
-
[66]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2307.13854
Pith/arXiv arXiv 2024
-
[67]
Yang Zhou, Hongyi Liu, Zhuoming Chen, Yuandong Tian, and Beidi Chen. Gsm-infinite: How do your llms behave over infinitely increasing context length and reasoning complexity?, 2025. URLhttps://arxiv.org/abs/2502.05252. A Experiment Cost Per-token pricing used to compute the costs reported in Table 6 is shown in Table 5. Table 5: Per-token pricing used in ...
arXiv 2025
-
[68]
Implement a REST API server that matches the specification and apply user requested changes
-
[69]
All entities must support CRUD operations (Create, Read, Update, Delete)
-
[70]
All operations/analytics endpoints must work correctly
-
[71]
You MUST create a script called ‘run_server.sh‘ that starts the server
-
[72]
The script must accept a port number as the first argument
-
[73]
You must use python programming language, but you can use ANY web framework as long as it is python
-
[74]
UserProfile
You should test your implementation during development to ensure correctness. Required Script: Create a file called ‘run_server.sh‘ that: - Takes a port number as the first argument (e.g., ‘bash run_server.sh 8001‘) - Starts your REST API server on that port - The server should listen on 0.0.0.0 (all interfaces) Example run_server.sh: #!/bin/bash PORT=$1 ...
2024
-
[75]
in which that category caused the first failure. 35 Missing Feature Hallucinated FeatureData Validation Error Cascade DeletionRename Failure Regression Wrong Endpoint Wrong Response Format T ype Error Default ValueEnum Handling Server CrashStuck Loop Suicide (pkill)Invalid T ool Call Other Devstral 2 + MiniSwe Devstral 2 + OpenCode Devstral 2 + OpenHands ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.