Scaling Self-Play for End-to-End Driving
Pith reviewed 2026-06-26 20:20 UTC · model grok-4.3
The pith
End-to-end driving policies trained via self-play in a simplified pixel simulator transfer competitively to real sensor data without any human trajectory supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Policies trained through self-play DAgger inside Gigapixel and then adapted to real sensor data achieve competitive performance on the HUGSIM and NAVSIM-v2 benchmarks without human trajectory supervision; scaling the amount of self-play training produces proportional improvements in policy performance.
What carries the argument
Gigapixel, a high-throughput batched simulator that renders perspective views of a simplified bounding-box world, paired with self-play DAgger that distills pixel policies from a privileged RL teacher before lightweight perception adaptation to real data.
If this is right
- End-to-end driving models can be trained without any human trajectory data.
- Closed-loop self-play supplies the state coverage and interaction feedback missing from offline datasets.
- Performance of the final policy improves in direct proportion to the amount of self-play training performed.
- A simplified non-photorealistic simulator is sufficient for the training stage when followed by perception adaptation.
Where Pith is reading between the lines
- The same self-play-plus-adaptation pipeline could be applied to other robotic control problems that currently rely on human demonstrations.
- Further increases in simulator throughput or model scale would be expected to continue raising benchmark scores.
- Edge cases that depend on fine visual detail not captured by bounding boxes may still require additional real-world adaptation steps.
- Removing the privileged teacher entirely and training the pixel policy directly with RL could test how much the distillation step contributes.
Load-bearing premise
The simplified bounding-box world rendered by Gigapixel preserves enough scene structure that policies trained inside it can be transferred to real sensor data through lightweight perception adaptation.
What would settle it
If increasing the scale of self-play training inside Gigapixel produces no measurable improvement on HUGSIM or NAVSIM-v2 after perception adaptation, or if the adapted policies fall substantially below the performance of human-supervised baselines on those benchmarks.
Figures
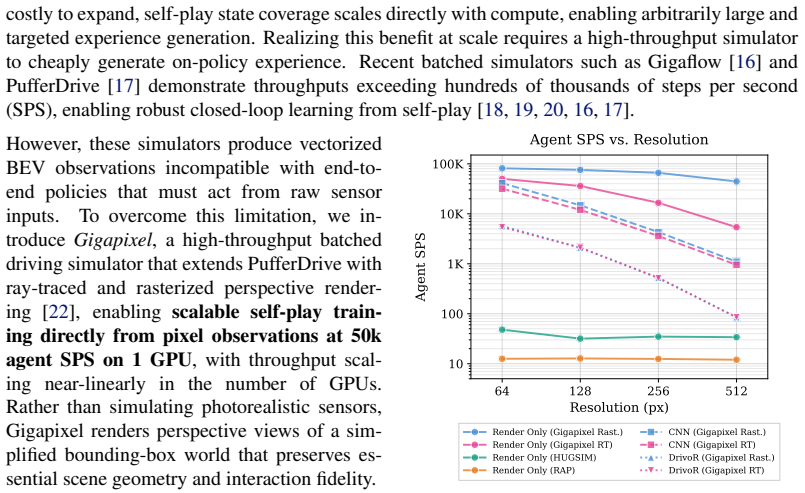
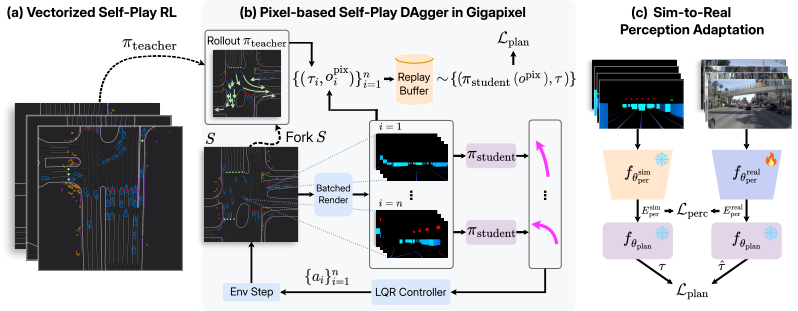
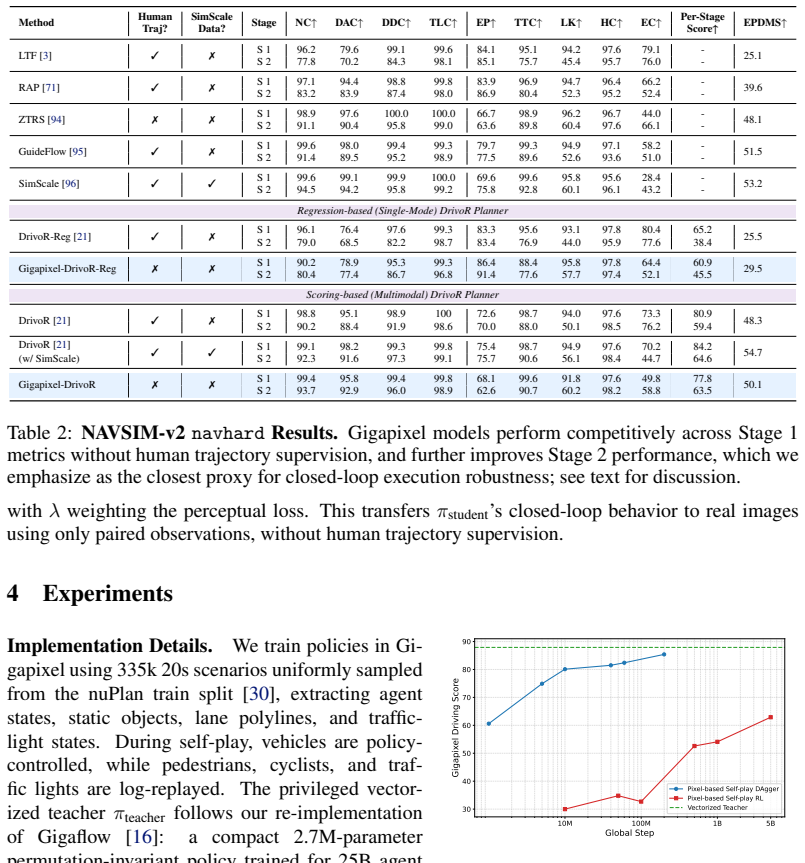




read the original abstract
End-to-end autonomous driving models are typically trained on offline human-demonstration datasets that provide limited state coverage and often no closed-loop feedback, making them prone to compounding errors when deployed in closed-loop and brittle to long-tail agent interactions. To overcome these limitations, we propose an alternative strategy for training end-to-end driving models: large-scale self-play directly from pixels in simulation. While prior self-play approaches have shown promising transfer to real-world driving, they typically assume vectorized Bird's-Eye-View (BEV) observations that are incompatible with end-to-end policies operating directly on sensor observations. To this end, we introduce Gigapixel, a high-throughput batched driving simulator with perspective rendering, enabling scalable self-play directly from pixel observations. Rather than targeting compute-costly photorealistic sensor simulation, Gigapixel renders a simplified bounding-box world that preserves essential scene structure while achieving throughput at 50k agent steps per second. Since direct pixel-space self-play RL is prohibitively sample-inefficient at end-to-end model scale, we propose self-play DAgger training: we train pixel-based policies in self-play via on-policy distillation from a privileged RL teacher. To bridge the sim-to-real gap, we subsequently transfer the self-play trained policies to real-world sensor data through lightweight perception adaptation. Policies trained in Gigapixel and adapted to real-world sensor data achieve competitive performance on the HUGSIM and NAVSIM-v2 benchmarks without human trajectory supervision. Moreover, scaling self-play training yields proportional gains in policy performance, establishing self-play as a practical and scalable strategy for training end-to-end models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Gigapixel, a high-throughput batched simulator that renders simplified bounding-box worlds (50k agent steps/s) to support large-scale self-play for pixel-based end-to-end driving policies. It trains via self-play DAgger by distilling from a privileged RL teacher, then applies lightweight perception adaptation to real sensor data. The central claims are that the resulting policies achieve competitive closed-loop performance on the HUGSIM and NAVSIM-v2 benchmarks without any human trajectory supervision, and that increasing self-play training scale produces proportional gains in policy performance.
Significance. If the sim-to-real transfer holds, the result would be significant: it offers a scalable route to end-to-end driving policies that avoids the state-coverage and compounding-error limitations of offline human datasets while using only simplified rendering rather than photorealistic simulation. The reported scaling behavior, if quantitatively documented, would also be a useful empirical finding for the community.
major comments (2)
- [Abstract and Gigapixel / transfer description] The headline claim (competitive benchmark performance after transfer) rests on the untested assumption that Gigapixel's bounding-box rendering retains sufficient scene structure for pixel policies once the privileged teacher is removed. The manuscript provides no quantitative ablations or metrics (e.g., closed-loop score degradation when photometric cues are removed, or comparison against a photorealistic baseline) that would demonstrate the domain gap is bridgeable by lightweight adaptation alone, particularly in long-tail interactions.
- [Abstract] The abstract asserts 'competitive performance' and 'proportional gains' from scaling but supplies no numerical scores, baselines, error bars, or ablation tables. Without these data in the results section, it is impossible to evaluate whether the self-play DAgger + adaptation pipeline actually surpasses or merely matches existing methods on HUGSIM/NAVSIM-v2.
minor comments (2)
- [Methods] Clarify the exact architecture and training details of the 'lightweight perception adaptation' step (e.g., which layers are updated, domain-randomization parameters) so readers can reproduce the sim-to-real bridge.
- [Experiments] Define the precise notion of 'scaling self-play training' (number of agents, episodes, or compute) and report the functional form of the performance-vs-scale curve with confidence intervals.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below with clarifications from the manuscript and indicate revisions where the feedback identifies opportunities to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract and Gigapixel / transfer description] The headline claim (competitive benchmark performance after transfer) rests on the untested assumption that Gigapixel's bounding-box rendering retains sufficient scene structure for pixel policies once the privileged teacher is removed. The manuscript provides no quantitative ablations or metrics (e.g., closed-loop score degradation when photometric cues are removed, or comparison against a photorealistic baseline) that would demonstrate the domain gap is bridgeable by lightweight adaptation alone, particularly in long-tail interactions.
Authors: The manuscript demonstrates that policies trained via self-play DAgger in the simplified bounding-box renderer achieve competitive closed-loop scores on HUGSIM and NAVSIM-v2 after lightweight perception adaptation, without any human trajectory data. This outcome indicates that the retained geometric structure is sufficient for the pixel policy to learn transferable behaviors from the privileged teacher. We agree that explicit ablations would make this more rigorous and will add quantitative comparisons (e.g., closed-loop degradation when removing specific visual elements in simulation) in the revised manuscript. A direct photorealistic baseline comparison is not feasible within the current experimental scope given the throughput focus, but we will expand the discussion of domain-gap limitations. revision: partial
-
Referee: [Abstract] The abstract asserts 'competitive performance' and 'proportional gains' from scaling but supplies no numerical scores, baselines, error bars, or ablation tables. Without these data in the results section, it is impossible to evaluate whether the self-play DAgger + adaptation pipeline actually surpasses or merely matches existing methods on HUGSIM/NAVSIM-v2.
Authors: The results section contains the requested numerical benchmark scores, baseline comparisons, error bars across runs, and scaling curves with ablation tables. To improve clarity, we will revise the abstract to incorporate the key quantitative results (specific closed-loop metrics and scaling trends) so that the claims are self-contained and directly supported by the reported data. revision: yes
Circularity Check
No circularity: empirical method evaluated on external benchmarks
full rationale
The paper proposes an empirical training pipeline (self-play DAgger in Gigapixel simulator followed by lightweight perception adaptation) and reports closed-loop performance on HUGSIM and NAVSIM-v2. No derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All central claims reduce to experimental outcomes on independent benchmarks rather than algebraic identities or self-referential definitions. This is a standard non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simplified bounding-box rendering preserves essential scene structure for policy transfer.
invented entities (1)
-
Gigapixel simulator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
P. S. Chib and P. Singh. Recent advancements in end-to-end autonomous driving using deep learning: A survey.IEEE Transactions on Intelligent Vehicles, 9(1):103–118, 2023
2023
-
[2]
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
2024
-
[3]
Chitta, A
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
2022
-
[4]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 17853–17862, 2023
2023
-
[5]
Jiang, S
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang. Vad: Vectorized scene representation for efficient autonomous driving. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[6]
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
Pith/arXiv arXiv 2024
-
[7]
L. Rowe, R. de Schaetzen, R. Girgis, C. Pal, and L. Paull. Poutine: Vision-language-trajectory pre-training and reinforcement learning post-training enable robust end-to-end autonomous driving.arXiv preprint arXiv:2506.11234, 2025
arXiv 2025
- [8]
-
[9]
Naumann, X
A. Naumann, X. Gu, T. Dimlioglu, M. Bojarski, A. Degirmenci, A. Popov, D. Bisla, M. Pavone, U. Muller, and B. Ivanovic. Data scaling laws for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2571– 2582, 2025
2025
-
[10]
M. Baniodeh, K. Goel, S. Ettinger, C. Fuertes, A. Seff, T. Shen, C. Gulino, C. Yang, G. Jerfel, D. Choe, et al. Scaling laws of motion forecasting and planning–technical report.arXiv preprint arXiv:2506.08228, 2025
arXiv 2025
-
[11]
Le Mero, D
L. Le Mero, D. Yi, M. Dianati, and A. Mouzakitis. A survey on imitation learning tech- niques for end-to-end autonomous vehicles.IEEE Transactions on Intelligent Transportation Systems, 23(9):14128–14147, 2022
2022
-
[12]
Ljungbergh, A
W. Ljungbergh, A. Tonderski, J. Johnander, H. Caesar, K. Åström, M. Felsberg, and C. Peters- son. Neuroncap: Photorealistic closed-loop safety testing for autonomous driving.European Conference on Computer Vision (ECCV), 2024. 11
2024
-
[13]
Karkus, M
P. Karkus, M. Igl, Y . Chen, K. Chitta, J. Packer, B. Douillard, R. Tian, A. Naumann, G. Garcia-Cobo, S. Tan, et al. Beyond behavior cloning in autonomous driving: a survey of closed-loop training techniques.Authorea Preprints, 2025
2025
-
[14]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[15]
Codevilla, E
F. Codevilla, E. Santana, A. M. López, and A. Gaidon. Exploring the limitations of behavior cloning for autonomous driving. InProceedings of the IEEE/CVF international conference on computer vision, pages 9329–9338, 2019
2019
-
[16]
Cusumano-Towner, D
M. Cusumano-Towner, D. Hafner, A. Hertzberg, B. Huval, A. Petrenko, E. Vinitsky, E. Wij- mans, T. W. Killian, S. Bowers, O. Sener, et al. Robust autonomy emerges from self-play. In International Conference on Machine Learning, pages 11710–11737. PMLR, 2025
2025
-
[17]
Cornelisse, S
D. Cornelisse, S. Cheng, P. Mandavilli, J. Hunt, K. Joseph, W. Doulazmi, V . Charraut, A. Gupta, J. Suarez, and E. Vinitsky. PufferDrive: A fast and friendly driving simulator for training and evaluating RL agents, 2025. URLhttps://github.com/Emerge-Lab/ PufferDrive
2025
-
[18]
Cornelisse and E
D. Cornelisse and E. Vinitsky. Human-compatible driving agents through data-regularized self-play reinforcement learning. InReinforcement Learning Conference, 2024
2024
-
[19]
D. Cornelisse, A. Pandya, K. Joseph, J. Suárez, and E. Vinitsky. Building reliable sim driving agents by scaling self-play.arXiv preprint arXiv:2502.14706, 2025
arXiv 2025
-
[20]
Zhang, S
C. Zhang, S. Biswas, K. Wong, K. Fallah, L. Zhang, D. Chen, S. Casas, and R. Urtasun. Learning to drive via asymmetric self-play. InEuropean Conference on Computer Vision, pages 149–168. Springer, 2024
2024
- [21]
-
[22]
L. G. Rosenzweig, B. Shacklett, W. Xia, and K. Fatahalian. High-throughput batch rendering for embodied ai. InSIGGRAPH Asia 2024 Conference Papers, pages 1–9, 2024
2024
-
[23]
Agarwal, N
R. Agarwal, N. Vieillard, Y . Zhou, P. Stanczyk, S. R. Garea, M. Geist, and O. Bachem. On- policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
2024
-
[24]
Y . Wang, W. Luo, J. Bai, Y . Cao, T. Che, K. Chen, Y . Chen, J. Diamond, Y . Ding, W. Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
Pith/arXiv arXiv 2025
-
[25]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
- [26]
-
[27]
H. Zhou, L. Lin, J. Wang, Y . Lu, D. Bai, B. Liu, Y . Wang, A. Geiger, and Y . Liao. Hugsim: A real-time, photo-realistic and closed-loop simulator for autonomous driving.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 2025. 12
2025
-
[28]
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y . Miron, M. Aiello, H. Li, I. Gilitschenski, et al. Pseudo-simulation for autonomous driving. InConference on Robot Learning, pages 4709–4722. PMLR, 2025
2025
-
[29]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Bal- dan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[30]
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810, 2021
Pith/arXiv arXiv 2021
-
[31]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 2446–2454, 2020
2020
-
[32]
R. Xu, H. Lin, W. Jeon, H. Feng, Y . Zou, L. Sun, J. Gorman, E. Tolstaya, S. Tang, B. White, et al. Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios. arXiv preprint arXiv:2510.26125, 2025
arXiv 2025
-
[33]
H. Arai, K. Miwa, K. Sasaki, K. Watanabe, Y . Yamaguchi, S. Aoki, and I. Yamamoto. Covla: Comprehensive vision-language-action dataset for autonomous driving. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1933–1943. IEEE, 2025
1933
-
[34]
F. Ghilotti, E. Palladin, S. Brucker, A. Sigal, M. Bijelic, and F. Heide. Truckdrive: Long-range autonomous highway driving dataset.arXiv preprint arXiv:2603.02413, 2026
arXiv 2026
-
[35]
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone. Para-drive: Parallelized archi- tecture for real-time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024
2024
-
[36]
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu, et al. Hydra- mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
Pith/arXiv arXiv 2024
-
[37]
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
2025
-
[38]
K. Renz, L. Chen, E. Arani, and O. Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11993–12003, 2025
2025
-
[39]
Z. Zhou, T. Cai, S. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and re- inforcement fine-tuning.Advances in Neural Information Processing Systems, 38:27920– 27956, 2026
2026
-
[40]
De Haan, D
P. De Haan, D. Jayaraman, and S. Levine. Causal confusion in imitation learning.Advances in neural information processing systems, 32, 2019
2019
-
[41]
Dauner, M
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta. Parting with misconceptions about learning-based vehicle motion planning. InConference on Robot Learning, pages 1268–
-
[42]
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, and P. Pérez. Deep reinforcement learning for autonomous driving: A survey.IEEE transactions on intel- ligent transportation systems, 23(6):4909–4926, 2021
2021
-
[43]
J. Chen, B. Yuan, and M. Tomizuka. Model-free deep reinforcement learning for urban au- tonomous driving. In2019 IEEE intelligent transportation systems conference (ITSC), pages 2765–2771. IEEE, 2019
2019
-
[44]
Toromanoff, E
M. Toromanoff, E. Wirbel, and F. Moutarde. End-to-end model-free reinforcement learning for urban driving using implicit affordances. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7153–7162, 2020
2020
-
[45]
Chekroun, M
R. Chekroun, M. Toromanoff, S. Hornauer, and F. Moutarde. Gri: General reinforced imita- tion and its application to vision-based autonomous driving.Robotics, 12(5):127, 2023
2023
-
[46]
Zhang, R
C. Zhang, R. Guo, W. Zeng, Y . Xiong, B. Dai, R. Hu, M. Ren, and R. Urtasun. Rethinking closed-loop training for autonomous driving. InEuropean Conference on Computer Vision, pages 264–282. Springer, 2022
2022
-
[47]
H. Gao, S. Chen, B. Jiang, B. Liao, Y . Shi, X. Guo, Y . Pu, X. Li, W. Liu, Q. Zhang, et al. Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning.Ad- vances in Neural Information Processing Systems, 38:32551–32576, 2026
2026
-
[48]
C. Ni, G. Zhao, X. Wang, Z. Zhu, W. Qin, X. Chen, G. Jia, G. Huang, and W. Mei. Recondreamer-rl: Enhancing reinforcement learning via diffusion-based scene reconstruc- tion.arXiv preprint arXiv:2508.08170, 2025
arXiv 2025
-
[49]
Zhang, P
Z. Zhang, P. Karkus, M. Igl, W. Ding, Y . Chen, B. Ivanovic, and M. Pavone. Closed-loop supervised fine-tuning of tokenized traffic models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5422–5432, 2025
2025
-
[50]
J. Zhang and K. Cho. Query-efficient imitation learning for end-to-end autonomous driving. arXiv preprint arXiv:1605.06450, 2016
Pith/arXiv arXiv 2016
-
[51]
Prakash, A
A. Prakash, A. Behl, E. Ohn-Bar, K. Chitta, and A. Geiger. Exploring data aggregation in policy learning for vision-based urban autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11763–11773, 2020
2020
-
[52]
G. Garcia-Cobo, M. Igl, P. Karkus, Z. Zhang, M. Watson, Y . Chen, B. Ivanovic, and M. Pavone. Road: Rollouts as demonstrations for closed-loop supervised fine-tuning of au- tonomous driving policies.arXiv preprint arXiv:2512.01993, 2025
arXiv 2025
-
[53]
S. Z. Zhao, L. Wang, H. Ruan, Y . Bao, Y . Chen, Z. Leng, A. Ravichandran, H. He, Z. Zhou, X. Han, et al. Bridgesim: Unveiling the ol-cl gap in end-to-end autonomous driving.arXiv preprint arXiv:2604.10856, 2026
Pith/arXiv arXiv 2026
- [54]
-
[55]
Dosovitskiy, G
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun. CARLA: An open urban driving simulator. InConference on Robot Learning, pages 1–16. PMLR, 2017
2017
-
[56]
Coelho, M
D. Coelho, M. Oliveira, and V . Santos. Rlad: Reinforcement learning from pixels for au- tonomous driving in urban environments.IEEE Transactions on Automation Science and Engineering, 21(4):7427–7435, 2023
2023
-
[57]
Osi ´nski, A
B. Osi ´nski, A. Jakubowski, P. Zi˛ ecina, P. Miło ´s, C. Galias, S. Homoceanu, and H. Michalewski. Simulation-based reinforcement learning for real-world autonomous driv- ing. In2020 IEEE international conference on robotics and automation (ICRA), pages 6411–
-
[58]
Gulino, J
C. Gulino, J. Fu, W. Luo, G. Tucker, E. Bronstein, Y . Lu, J. Harb, X. Pan, Y . Wang, X. Chen, et al. Waymax: An accelerated, data-driven simulator for large-scale autonomous driving research.Advances in Neural Information Processing Systems, 36, 2023
2023
-
[59]
Vinitsky, N
E. Vinitsky, N. Lichtlé, X. Yang, B. Amos, and J. Foerster. Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world.Advances in Neural Information Processing Systems, 35:3962–3974, 2022
2022
-
[60]
Kazemkhani, A
S. Kazemkhani, A. Pandya, D. Cornelisse, B. Shacklett, and E. Vinitsky. GPUDrive: Data- driven, multi-agent driving simulation at 1 million FPS. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, 2025
2025
-
[61]
Wymann, E
B. Wymann, E. Espié, C. Guionneau, C. Dimitrakakis, R. Coulom, and A. Sumner. Torcs, the open racing car simulator.Software available at http://torcs. sourceforge. net, 4(6):2, 2000
2000
-
[62]
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE transactions on pattern analysis and machine intelligence, 45(3):3461–3475, 2022
2022
-
[63]
Z. Yang, Y . Chen, J. Wang, S. Manivasagam, W.-C. Ma, A. J. Yang, and R. Urtasun. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 1389–1399, 2023
2023
-
[64]
Tonderski, C
A. Tonderski, C. Lindström, G. Hess, W. Ljungbergh, L. Svensson, and C. Petersson. Neurad: Neural rendering for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14895–14904, 2024
2024
-
[65]
NVIDIA, Y . Cao, R. de Lutio, S. Fidler, G. G. Cobo, Z. Gojcic, M. Igl, B. Ivanovic, P. Karkus, J. M. Esturo, M. Pavone, A. Smith, E. Tanimura, M. Tyszkiewicz, M. Watson, Q. Wu, and L. Zhang. Alpasim: A modular, lightweight, and data-driven research simulator for au- tonomous driving, October 2025. URLhttps://github.com/NVlabs/alpasim
2025
-
[66]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
Pith/arXiv arXiv 2023
-
[67]
L. Russell, A. Hu, L. Bertoni, G. Fedoseev, J. Shotton, E. Arani, and G. Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
Pith/arXiv arXiv 2025
-
[68]
J. Yang, K. Chitta, S. Gao, L. Chen, Y . Shao, X. Jia, H. Li, A. Geiger, X. Yue, and L. Chen. ReSim: Reliable world simulation for autonomous driving.arXiv preprint arXiv:2506.09981, 2025
Pith/arXiv arXiv 2025
-
[69]
X. Yang, L. Wen, T. Wei, Y . Ma, J. Mei, X. Li, W. Lei, D. Fu, P. Cai, M. Dou, et al. Drivearena: A closed-loop generative simulation platform for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26933–26943, 2025
2025
-
[70]
T. Yan, D. Wu, W. Han, J. Jiang, X. Zhou, K. Zhan, C.-z. Xu, and J. Shen. Drivingsphere: Building a high-fidelity 4d world for closed-loop simulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27531–27541, 2025
2025
-
[71]
L. Feng, Y . Gao, E. Zablocki, Q. Li, W. Li, S. Liu, M. Cord, and A. Alahi. RAP: 3d rasteriza- tion augmented end-to-end planning. InThe Fourteenth International Conference on Learn- ing Representations, 2026. URLhttps://openreview.net/forum?id=a9bOgeqbdB
2026
-
[72]
Shacklett, L
B. Shacklett, L. G. Rosenzweig, Z. Xie, B. Sarkar, A. Szot, E. Wijmans, V . Koltun, D. Batra, and K. Fatahalian. An extensible, data-oriented architecture for high-performance, many- world simulation.ACM Transactions on Graphics (TOG), 42(4):1–13, 2023. 15
2023
-
[73]
H. X. Liu and S. Feng. Curse of rarity for autonomous vehicles.nature communications, 15 (1):4808, 2024
2024
-
[74]
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis. Mastering chess and shogi by self-play with a general reinforcement learning algorithm.arXiv preprint arXiv:1712.01815, 2017
Pith/arXiv arXiv 2017
-
[75]
Silver, J
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y . Chen, T. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis. Mastering the game of Go without human knowledge.Nature, 550(7676):354–359, 2017
2017
-
[76]
M. Jaderberg, W. M. Czarnecki, I. Dunning, L. Marris, G. Lever, A. García Castañeda, C. Beattie, N. C. Rabinowitz, A. S. Morcos, A. Ruderman, N. Sonnerat, T. Green, L. Deason, J. Z. Leibo, D. Silver, D. Hassabis, K. Kavukcuoglu, and T. Graepel. Human-level perfor- mance in first-person multiplayer games with population-based deep reinforcement learning. a...
Pith/arXiv arXiv 2018
-
[77]
Bakhtin, D
A. Bakhtin, D. J. Wu, A. Lerer, J. Gray, A. P. Jacob, G. Farina, A. H. Miller, and N. Brown. Mastering the game of no-press diplomacy via human-regularized reinforcement learning and planning. InThe Eleventh International Conference on Learning Representations, ICLR 2023, 2023
2023
- [78]
-
[79]
Z. Wang, S. Rahmani, D. Cornelisse, B. Sarkar, A. D. Goldie, J. N. Foerster, and S. White- son. Learning to drive in new cities without human demonstrations.arXiv preprint arXiv:2602.15891, 2026
arXiv 2026
-
[80]
A. Distelzweig, F. Janjoš, A. Look, A. Rothenhäusler, D. Jost, O. Scheel, R. Rajan, D. Cor- nelisse, E. Vinitsky, and J. Boedecker. Beyond self-play and scale: A behavior benchmark for generalization in autonomous driving.arXiv preprint arXiv:2605.10034, 2026
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.