LOKI: Memory-Free Null-Space Constrained Lifelong Knowledge Editing
Pith reviewed 2026-06-26 18:44 UTC · model grok-4.3
The pith
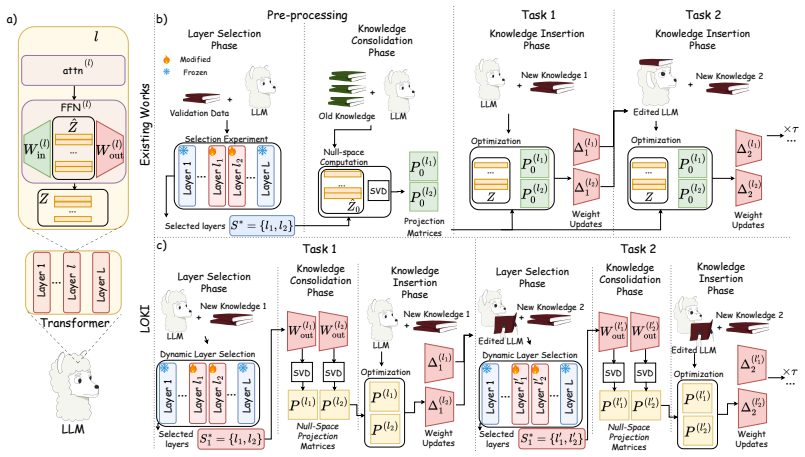
LOKI updates language models sequentially with new knowledge by selecting layers dynamically via HSIC and projecting gradients into the null-space of weights without any prior data access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LOKI achieves superior performance to existing approaches across a wide variety of experiments, achieving up to a 14% improvement in average accuracy, by using HSIC-based dynamic layer selection and projecting gradient updates onto the null-space of the model weights, bypassing the requirement for previous knowledge access.
What carries the argument
Dynamic layer selection via the Hilbert-Schmidt Independence Criterion together with projection of gradient updates onto the null-space of the model weights.
If this is right
- Sequential edits can be performed without storing or replaying any previous knowledge samples.
- Different knowledge updates can modify different layers, avoiding the rigidity of fixed-layer schemes.
- Gradient steps remain orthogonal to existing weight directions, limiting unintended changes to prior edits.
- The method supports editing under strict privacy or storage constraints that bar access to historical data.
Where Pith is reading between the lines
- If null-space projections remain effective over dozens of successive edits, the approach could support very long editing histories without explicit regularization terms.
- HSIC-based selection might be replaced by cheaper proxies such as activation variance if the independence criterion proves expensive at scale.
- The same null-space idea could be tested on non-transformer architectures where weight matrices have different spectral properties.
- One could measure whether the chosen layers correlate with attention heads that encode the edited facts, providing a post-hoc interpretability check.
Load-bearing premise
That projecting gradient updates onto the null-space of model weights, combined with HSIC-based dynamic layer selection, sufficiently prevents interference with previously edited knowledge even without access to any prior data or statistics.
What would settle it
A sequence of edits on a held-out benchmark where accuracy on earlier facts falls below the levels achieved by methods that retain past data, or where average accuracy does not exceed the best baseline by a measurable margin.
Figures

read the original abstract
Lifelong knowledge editing aims to efficiently and sequentially update language models over time, as new knowledge becomes available or when the model makes mistakes, while preserving acceptable performance on past knowledge. One unresolved challenge is that existing methods modify a fixed set of layers for all new knowledge samples, reducing flexibility and increasing catastrophic forgetting. Another is requiring access to previous knowledge and extensive pre-processing to obtain data statistics. To address these challenges, we introduce LOKI, a novel approach that uses dynamic layer selection based on the Hilbert-Schmidt Independence Criterion and projects gradient updates onto the null-space of the model weights, bypassing the requirement for previous knowledge access. We show that LOKI achieves superior performance to existing approaches across a wide variety of experiments, achieving up to a 14\% improvement in average accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LOKI, a memory-free method for lifelong knowledge editing of language models. It dynamically selects layers using the Hilbert-Schmidt Independence Criterion (HSIC) and projects gradient updates onto the null-space of the model weights to enable sequential edits while preserving prior knowledge, without requiring access to previous data or pre-computed statistics. The central claim is that this yields superior performance, with up to 14% higher average accuracy than existing approaches across experiments.
Significance. If the experimental results hold, the contribution would be meaningful for practical lifelong editing: it removes the memory and preprocessing requirements that limit prior methods and adds flexibility via dynamic layer choice. The approach builds on standard tools (HSIC, null-space projection) rather than introducing new primitives, which lowers the barrier to adoption but also means the novelty lies primarily in the combination and the no-memory guarantee.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of up to 14% average-accuracy improvement is presented without any mention of the number of runs, standard deviations, statistical tests, or the precise baselines and editing benchmarks used. This information is load-bearing for the performance claim and must be supplied with concrete numbers and controls.
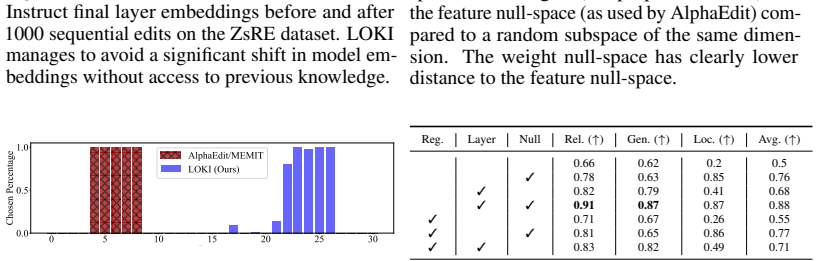
- [§3.2] §3.2 (Null-space projection): the argument that projection onto the null-space of current weights is sufficient to avoid interference with prior edits, even without any stored statistics, requires an explicit argument or bound showing that the projected update cannot alter the previously edited directions. The current description relies on the geometric intuition alone.
minor comments (2)
- Define HSIC on first use and state the precise kernel and regularization choices used in the layer-selection step.
- Add a short pseudocode block or explicit algorithm listing the per-edit steps (HSIC computation, null-space projection, update application) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below and will incorporate revisions to strengthen the experimental reporting and theoretical justification.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of up to 14% average-accuracy improvement is presented without any mention of the number of runs, standard deviations, statistical tests, or the precise baselines and editing benchmarks used. This information is load-bearing for the performance claim and must be supplied with concrete numbers and controls.
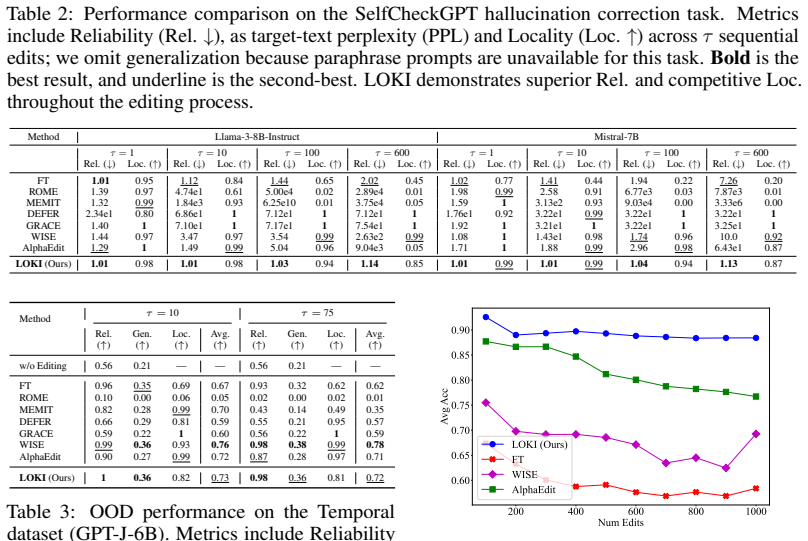
Authors: We agree that the performance claims require supporting statistical details for rigor. In the revised manuscript, we will update the abstract and Section 4 to specify the number of independent runs (e.g., 5), report mean accuracies with standard deviations, note any statistical significance tests performed, and explicitly detail the baselines (such as SERAC, MEND, and others) along with the editing benchmarks (ZsRE, CounterFact, etc.) used in each experiment. The reported 'up to 14%' figure represents the largest observed gain in average accuracy across the evaluated settings and will be contextualized with these controls. revision: yes
-
Referee: [§3.2] §3.2 (Null-space projection): the argument that projection onto the null-space of current weights is sufficient to avoid interference with prior edits, even without any stored statistics, requires an explicit argument or bound showing that the projected update cannot alter the previously edited directions. The current description relies on the geometric intuition alone.
Authors: We acknowledge the need for a more formal justification beyond geometric intuition. In the revision to §3.2, we will include an explicit argument and bound: because prior edits are already embedded in the current weight matrix W, any update ΔW projected onto the null space of W (i.e., satisfying W ΔW = 0) cannot modify the linear mappings established by previous edits. We will provide a short proof sketch showing that the projected update preserves the output behavior on previously edited inputs without requiring stored statistics, along with a bound on residual interference under standard assumptions on the weight matrix rank. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation relies on standard external techniques (HSIC for layer selection and null-space projection of gradients) applied to the editing objective without re-deriving or fitting quantities from the same data in a self-referential loop. No self-citation chains, ansatz smuggling, or fitted-input-as-prediction patterns are present in the abstract or described method. The central claim of memory-free interference prevention is supported by the algorithmic construction rather than reducing to its own inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Correcting diverse factual errors in abstractive summarization via post-editing and language model infilling
Vidhisha Balachandran, Hannaneh Hajishirzi, William Cohen, and Yulia Tsvetkov. Correcting diverse factual errors in abstractive summarization via post-editing and language model infilling. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9818–9830, 2022
2022
-
[2]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
1901
-
[3]
On lazy training in differentiable program- ming.Advances in neural information processing systems, 32, 2019
Lenaic Chizat, Edouard Oyallon, and Francis Bach. On lazy training in differentiable program- ming.Advances in neural information processing systems, 32, 2019
2019
-
[4]
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Shi Jie, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Alphaedit: Null-space constrained knowledge editing for language models. arXiv preprint arXiv:2410.02355, 2024
-
[5]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InInternational Conference on Artificial Intelligence and Statistics, pages 3762–3773. PMLR, 2020
2020
-
[6]
Should chatgpt be biased? challenges and risks of bias in large language models
Emilio Ferrara. Should chatgpt be biased? challenges and risks of bias in large language models. arXiv preprint arXiv:2304.03738, 2023
-
[7]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile: An 800GB dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Measuring statistical dependence with Hilbert-Schmidt norms
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. Measuring statistical dependence with Hilbert-Schmidt norms. InInternational Conference on Algorithmic Learning Theory, pages 63–77. Springer, 2005
2005
-
[10]
Towards lifelong model editing via simulating ideal editor
Yaming Guo, Siyang Guo, Hengshu Zhu, and Ying Sun. Towards lifelong model editing via simulating ideal editor. InForty-second International Conference on Machine Learning, 2025
2025
-
[11]
Aging with grace: Lifelong model editing with discrete key-value adaptors.Advances in Neural Information Processing Systems, 36:47934–47959, 2023
Tom Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, and Marzyeh Ghassemi. Aging with grace: Lifelong model editing with discrete key-value adaptors.Advances in Neural Information Processing Systems, 36:47934–47959, 2023
2023
-
[12]
Model editing with canonical examples.arXiv preprint arXiv:2402.06155, 2024
John Hewitt, Sarah Chen, Lanruo Lora Xie, Edward Adams, Percy Liang, and Christopher D Manning. Model editing with canonical examples.arXiv preprint arXiv:2402.06155, 2024
-
[13]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
2023
-
[14]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. 10
2023
-
[15]
Zero-shot relation extraction via reading comprehension
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. Zero-shot relation extraction via reading comprehension. InProceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 333–342, 2017
2017
-
[16]
Wan-Duo Kurt Ma, J. P. Lewis, and W. Bastiaan Kleijn. The HSIC bottleneck: Deep learning without back-propagation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5085–5092, 2020
2020
-
[17]
SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, 2023
2023
-
[18]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
1989
-
[19]
Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
2022
-
[20]
Mass editing memory in a transformer.The Eleventh International Conference on Learning Represen- tations (ICLR), 2023
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass editing memory in a transformer.The Eleventh International Conference on Learning Represen- tations (ICLR), 2023
2023
-
[21]
Memory-based model editing at scale
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memory-based model editing at scale. InInternational Conference on Machine Learning, pages 15817–15831. PMLR, 2022
2022
-
[22]
Gradient projection memory for continual learning
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning. InInternational Conference on Learning Representations, 2021
2021
-
[23]
Editable neural networks.arXiv preprint arXiv:2004.00345, 2020
Anton Sinitsin, Vsevolod Plokhotnyuk, Dmitriy Pyrkin, Sergei Popov, and Artem Babenko. Editable neural networks.arXiv preprint arXiv:2004.00345, 2020
-
[24]
Deep learning and the information bottleneck principle
Naftali Tishby and Noga Zaslavsky. Deep learning and the information bottleneck principle. In IEEE Information Theory Workshop, pages 1–5. IEEE, 2015
2015
-
[25]
GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model.https://github.com/kingoflolz/mesh-transformer-jax, May 2021
Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model.https://github.com/kingoflolz/mesh-transformer-jax, May 2021
2021
-
[26]
Wise: Rethinking the knowledge memory for lifelong model editing of large language models.Advances in Neural Information Processing Systems, 37:53764– 53797, 2024
Peng Wang, Zexi Li, Ningyu Zhang, Ziwen Xu, Yunzhi Yao, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. Wise: Rethinking the knowledge memory for lifelong model editing of large language models.Advances in Neural Information Processing Systems, 37:53764– 53797, 2024
2024
-
[27]
Peng Wang, Ningyu Zhang, Xin Xie, Yunzhi Yao, Bozhong Tian, Mengru Wang, Zekun Xi, Siyuan Cheng, Kangwei Liu, Guozhou Zheng, et al. Easyedit: An easy-to-use knowledge editing framework for large language models.arXiv preprint arXiv:2308.07269, 2023
-
[28]
Editing large language models: Problems, methods, and opportunities
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. Editing large language models: Problems, methods, and opportunities. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10222–10240, 2023
2023
- [29]
-
[30]
Adaptive budget allocation for parameter-efficient fine-tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Can we edit factual knowledge by in-context learning?arXiv preprint arXiv:2305.12740, 2023
Ce Zheng, Lei Li, Qingxiu Dong, Yuxuan Fan, Zhiyong Wu, Jingjing Xu, and Baobao Chang. Can we edit factual knowledge by in-context learning?arXiv preprint arXiv:2305.12740, 2023. 11
-
[32]
subject is a {insert subject}
Zexuan Zhong, Zhengxuan Wu, Christopher D Manning, Christopher Potts, and Danqi Chen. MQuAKE: Assessing knowledge editing in language models via multi-hop questions. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. 12 A HSIC Definition Let F and G be reproducing kernel Hilbert spaces (RKHSs) on domains X and Y with associat...
2023
-
[33]
What was the date of Air France Flight 447?
prompts generated by the model from scratch, to improve generalization. The resulting inputs are then treated as a batch and used in the loss terms instead of Xt by itself. That is ¯Xt = [[G1, Xt],[G 2, Xt], ...], whereG is are generated by the LLM from scratch. 15 Table 7: LOKI hyperparameters for each benchmark and backbone reported in the main results....
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.