NEST: Narrative Event Structures in Time for Long Video Understanding
Pith reviewed 2026-06-26 17:55 UTC · model grok-4.3
The pith
The NEST dataset of 1005 movies shows vision-language models fail at discovering narrative events but handle their relations better once events are supplied.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that the capacity to ingest long token streams does not produce narrative understanding, and they demonstrate this by releasing NEST together with baselines showing that grounded event discovery stays very hard while relation extraction becomes tractable once events are given.
What carries the argument
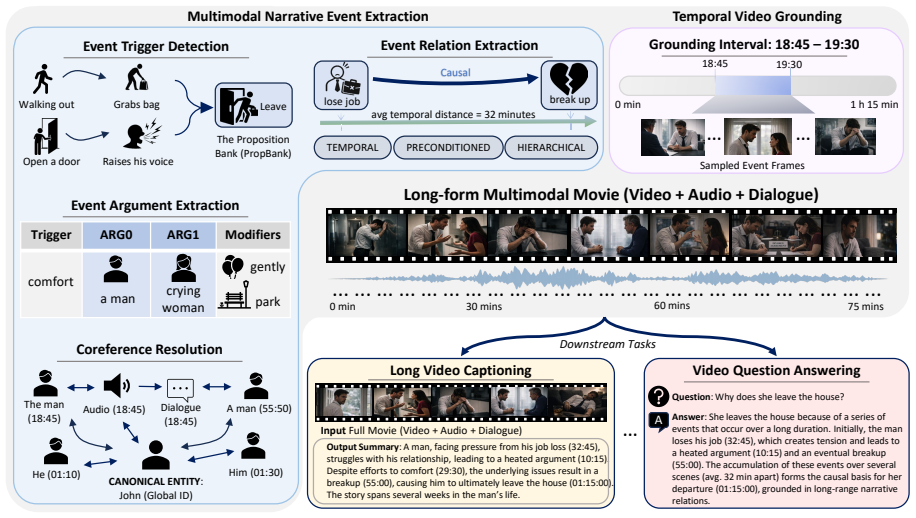
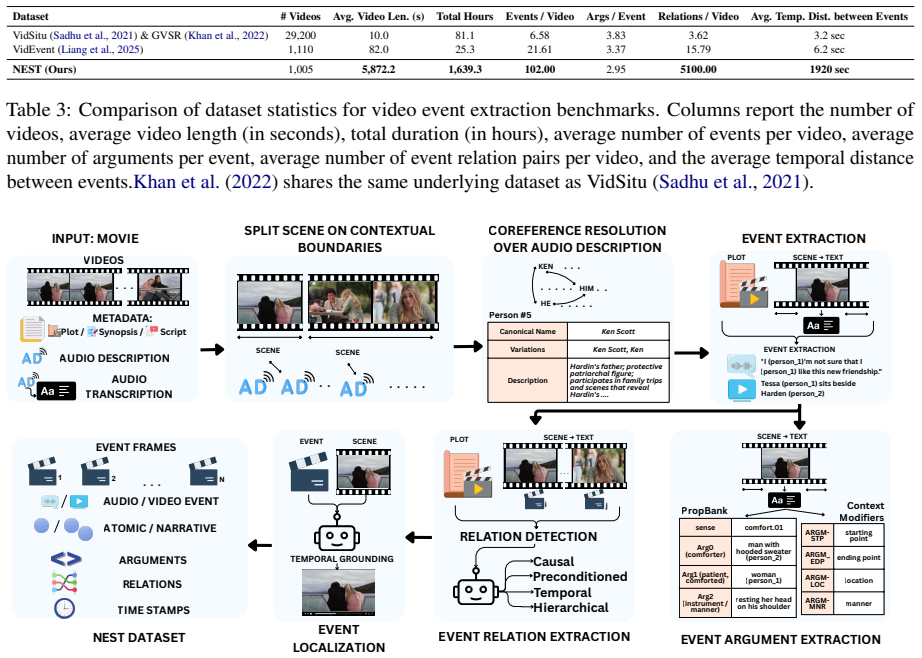
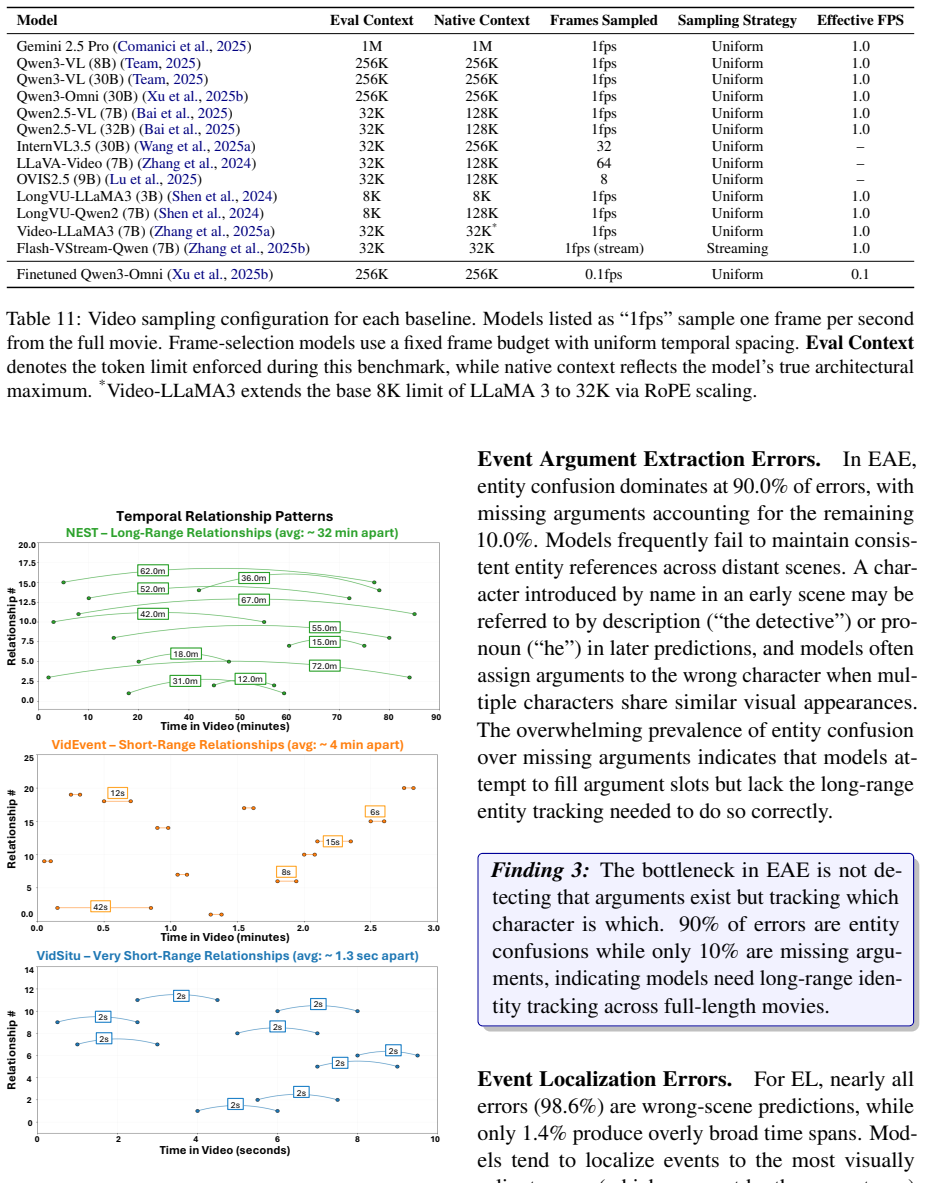
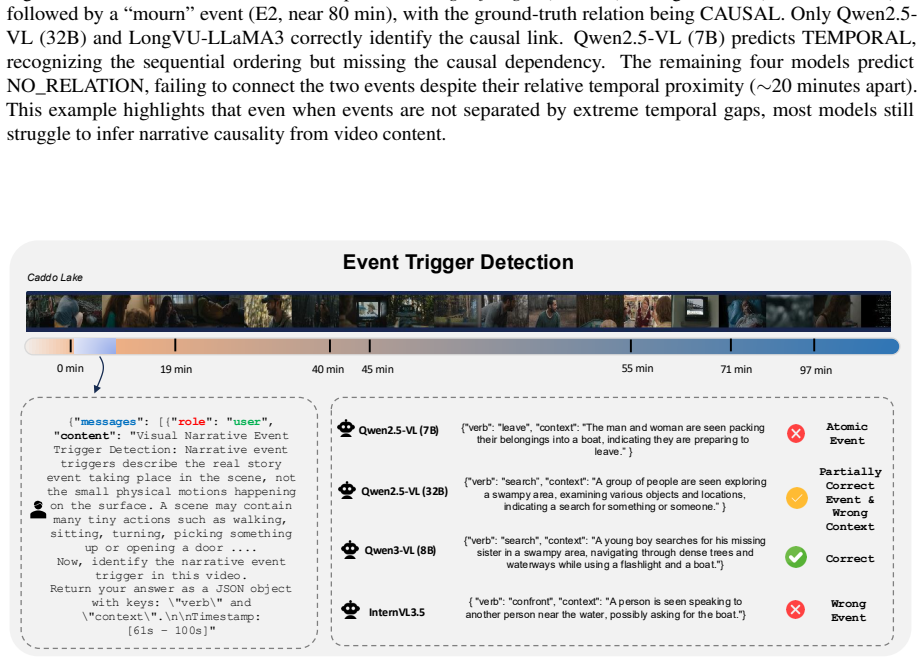
The NEST dataset of 1005 full-length movies each annotated with 102 multimodal narrative events and the relations among them.
If this is right
- Grounded discovery of events from video, dialogue, and audio forms the main remaining obstacle for long-video narrative tasks.
- Relation extraction improves markedly once events are supplied, reaching 44 percent F1 after fine-tuning.
- Standard long-video benchmarks centered on retrieval miss the harder problem of linking events across time.
- Multimodal grounding is required because many events depend on dialogue or audio cues in addition to visuals.
Where Pith is reading between the lines
- Architectures may need explicit mechanisms for chaining events over hour-long spans rather than relying on uniform attention over tokens.
- The same annotation style could be applied to long documents or podcasts to test whether narrative deficits appear across modalities.
- Pre-training losses that reward event boundary prediction might close part of the performance gap observed here.
- Flashback and reframing scenes in the data offer a natural test for whether models can revise earlier event interpretations.
Load-bearing premise
The human annotations of the 102 events per movie and their narrative relations are accurate, consistent, and sufficient to measure genuine narrative understanding.
What would settle it
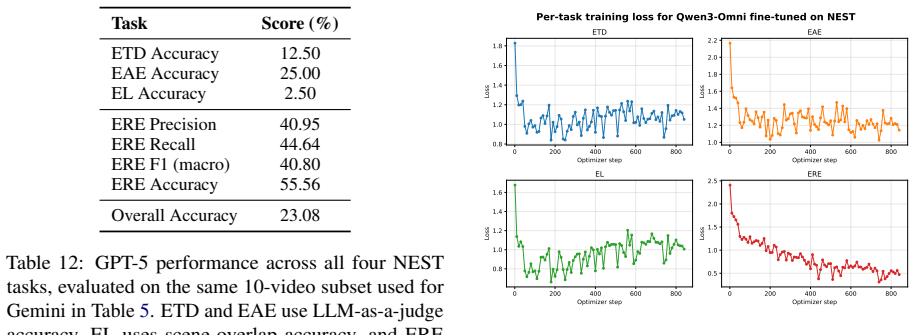
A model that reaches above 30 percent on event localization or argument extraction on the NEST test set would show that the discovery tasks are more solvable by current methods than the reported baselines indicate.
Figures




read the original abstract
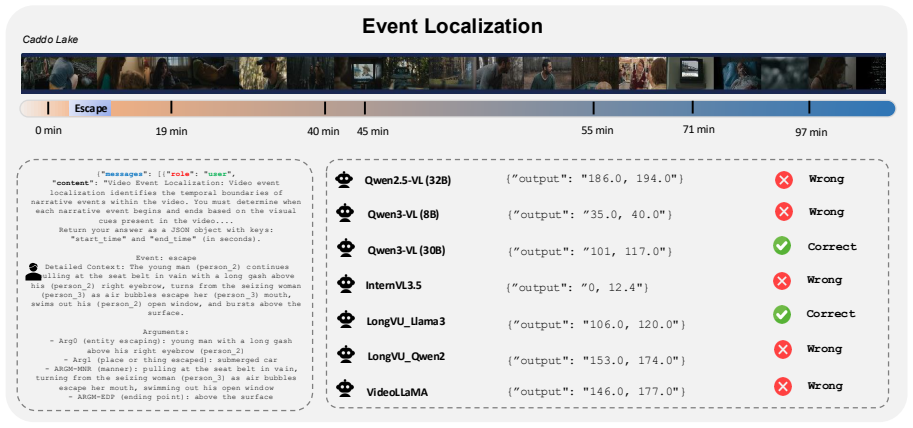
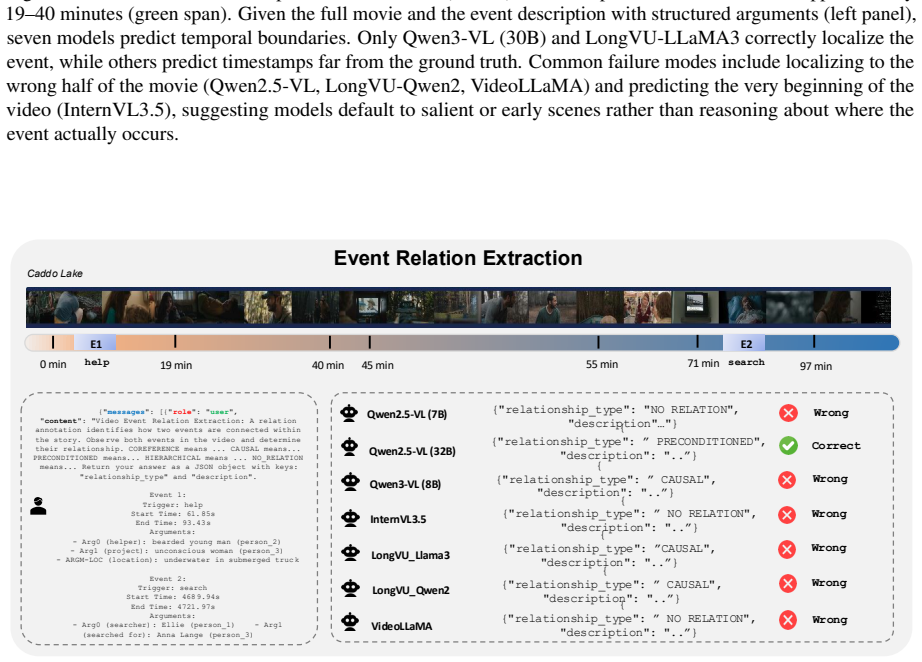
Recent progress in vision-language models has enabled the processing of increasingly long video sequences, but the ability to handle extended token streams does not translate to understanding of narrative structure in long videos. Existing long video benchmarks focus on needle-in-a-haystack retrieval rather than evaluating how low-level actions form events, how events interact across time, and how narratives progress, for example, whether a model can connect an early setback, such as a job loss to a later relationship breakup, despite long gaps, intervening scenes, or flashbacks that reframe what occurred. We introduce NEST (Narrative Event Structures in Time for Long Video Understanding), a dataset of 1005 full-length movies (avg. 98 minutes), each annotated with 102 multimodal narrative events grounded in visual content, dialogue, and audio. NEST captures multimodal narrative events with structured annotations grounded in visual content, dialogue, and audio, and links them through relations that reflect narrative structure, including temporal ordering, hierarchical composition, and long-range dependencies. We introduce baselines for event trigger detection (ETD), event localization (EL), event argument extraction (EAE), and event relation extraction (ERE). The benchmark is highly challenging for grounded event discovery, with ETD below 8%, EL under 6%, and EAE below 11%. In contrast, ERE is more tractable once events are given, reaching 35.45% F1 zero-shot and 44.42% F1 after fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the NEST dataset of 1005 full-length movies (avg. 98 min) each annotated with 102 multimodal narrative events grounded in visual content, dialogue, and audio, linked by temporal, hierarchical, and long-range relations. It defines four tasks (event trigger detection ETD, event localization EL, event argument extraction EAE, event relation extraction ERE) and reports baseline results claiming the first three tasks are highly challenging (ETD <8%, EL <6%, EAE <11%) while ERE reaches 35.45% F1 zero-shot and 44.42% F1 after fine-tuning, arguing that current vision-language models fail to capture narrative structure beyond retrieval.
Significance. If the annotations are shown to be reliable and the baselines are reproducible, the work could be significant by shifting long-video evaluation from needle-in-haystack retrieval to structured narrative understanding, supplying a large-scale resource with explicit multimodal grounding and relational annotations that current benchmarks lack.
major comments (2)
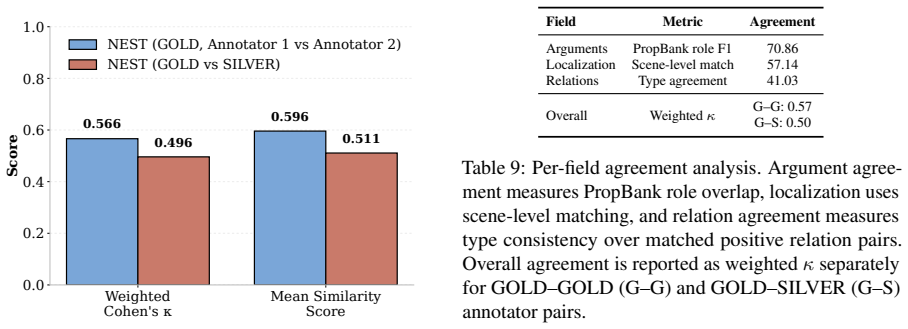
- [Abstract] Abstract: the central claim that 'the benchmark is highly challenging for grounded event discovery' with ETD below 8%, EL under 6%, and EAE below 11% rests on the 102 events per movie and their narrative relations constituting accurate, consistent ground truth. The abstract supplies no information on annotation protocol, number of annotators, inter-annotator agreement, adjudication, or external validation, so low baseline scores cannot be unambiguously attributed to model shortcomings rather than label noise.
- [Abstract] Abstract: baseline performance figures are stated without any description of model implementations, data splits, training details, or statistical measures (error bars, significance tests). This prevents assessment of whether the reported numbers support the difficulty claim.
minor comments (1)
- [Abstract] The abstract repeats the phrase 'structured annotations grounded in visual content, dialogue, and audio' without clarifying how multimodal grounding is operationalized or verified during annotation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that it should more explicitly support the claims regarding annotation quality and baseline reproducibility. We will revise the abstract to address both points by incorporating concise references to the relevant sections of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the benchmark is highly challenging for grounded event discovery' with ETD below 8%, EL under 6%, and EAE below 11% rests on the 102 events per movie and their narrative relations constituting accurate, consistent ground truth. The abstract supplies no information on annotation protocol, number of annotators, inter-annotator agreement, adjudication, or external validation, so low baseline scores cannot be unambiguously attributed to model shortcomings rather than label noise.
Authors: We agree that the abstract would be strengthened by briefly indicating annotation reliability. The manuscript (Section 3) details the annotation protocol, annotator count, agreement metrics, and adjudication process. We will revise the abstract to include a short summary of these elements so that the ground-truth quality is more clearly established. revision: yes
-
Referee: [Abstract] Abstract: baseline performance figures are stated without any description of model implementations, data splits, training details, or statistical measures (error bars, significance tests). This prevents assessment of whether the reported numbers support the difficulty claim.
Authors: We agree that the abstract should point readers to the supporting experimental details. The manuscript (Section 4) specifies the model implementations, data splits, training procedures, and reports statistical measures including error bars. We will revise the abstract to reference these details or add a brief clause summarizing them. revision: yes
Circularity Check
No circularity: empirical dataset construction with no derivations or self-referential predictions
full rationale
The paper introduces the NEST dataset of 1005 movies with 102 annotated events each and reports baseline performance on four tasks (ETD, EL, EAE, ERE). No equations, parameters, or derivations appear in the provided text. Claims rest on empirical annotation and model evaluation rather than any chain that reduces a result to its own inputs by construction. Self-citations are absent from the abstract and described sections; the work is self-contained as dataset release plus baseline reporting against external models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations of narrative events and relations are reliable and capture the intended narrative phenomena
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
-
[4]
arXiv preprint arXiv:2502.14786 , year=
Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features , author=. arXiv preprint arXiv:2502.14786 , year=
-
[5]
2022 , eprint=
CLAP: Learning Audio Concepts From Natural Language Supervision , author=. 2022 , eprint=
2022
-
[6]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[7]
2024 , eprint=
DINOv2: Learning Robust Visual Features without Supervision , author=. 2024 , eprint=
2024
-
[8]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[9]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[10]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[11]
Dan Gusfield , title =. 1997
1997
-
[12]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[13]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[14]
arXiv preprint arXiv:2503.13377 , year =
Time-R1: Post-Training Large Vision-Language Model for Temporal Video Grounding , author =. arXiv preprint arXiv:2503.13377 , year =
-
[15]
arXiv preprint arXiv:2506.18883 , year =
UniTime: Universal Video Temporal Grounding with Generative Multimodal Large Language Models , author =. arXiv preprint arXiv:2506.18883 , year =
-
[16]
arXiv preprint arXiv:2410.03290 , year =
Grounded-VideoLLM: Fine-Grained Temporal Grounding for Video Large Language Models , author =. arXiv preprint arXiv:2410.03290 , year =
-
[17]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
TimeSuite: Scalable Long-Context Adaptation for Temporal Video Grounding , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[18]
Technical Report, Tsinghua University , year =
Localizing Step-by-Step: Multimodal Long-Video Temporal Grounding with Large Language Models , author =. Technical Report, Tsinghua University , year =
-
[19]
arXiv preprint arXiv:2508.10922 , year =
A Survey on Video Temporal Grounding with Multimodal Large Language Models , author =. arXiv preprint arXiv:2508.10922 , year =
-
[20]
2022 , month = jul, howpublished =
Where the Crawdads Sing , author =. 2022 , month = jul, howpublished =
2022
-
[21]
Proceedings of the 34th International Conference on Neural Information Processing Systems , pages=
Belief propagation neural networks , author=. Proceedings of the 34th International Conference on Neural Information Processing Systems , pages=
-
[22]
International Conference on Artificial Intelligence and Statistics , pages=
Neural enhanced belief propagation on factor graphs , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[23]
Computational linguistics , volume=
The proposition bank: An annotated corpus of semantic roles , author=. Computational linguistics , volume=. 2005 , publisher=
2005
-
[24]
arXiv preprint arXiv:2505.15734 , year=
DEBATE, TRAIN, EVOLVE: Self Evolution of Language Model Reasoning , author=. arXiv preprint arXiv:2505.15734 , year=
-
[25]
Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL'25) , year =
Meng Lu and Yuzhang Xie and Zhenyu Bi and Shuxiang Cao and Xuan Wang , title =. Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL'25) , year =
-
[26]
Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL'25) , year =
Priya Pitre and Naren Ramakrishnan and Xuan Wang , title =. Findings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL'25) , year =
-
[27]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
OntoType: Ontology-Guided and Pre-Trained Language Model Assisted Fine-Grained Entity Typing , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[28]
Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024) , pages=
PromptRE: Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming , author=. Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024) , pages=
2024
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Reaction miner: An integrated system for chemical reaction extraction from textual data , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2023
-
[30]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TTM-RE: Memory-Augmented Document-Level Relation Extraction , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
arXiv preprint arXiv:2502.11569 , year=
Towards reasoning ability of small language models , author=. arXiv preprint arXiv:2502.11569 , year=
-
[32]
bioRxiv , pages=
PathoLM: Identifying pathogenicity from the DNA sequence through the Genome Foundation Model , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[33]
arXiv preprint arXiv:2407.03687 , year=
STOC-TOT: Stochastic Tree-of-Thought with Constrained Decoding for Complex Reasoning in Multi-Hop Question Answering , author=. arXiv preprint arXiv:2407.03687 , year=
-
[34]
2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=
REACTCLASS: cross-modal supervision for subword-guided reactant entity classification , author=. 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=. 2022 , organization=
2022
-
[35]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
New frontiers of scientific text mining: tasks, data, and tools , author=. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[36]
2020 IEEE International Conference on Big Data (Big Data) , pages=
Textual evidence mining via spherical heterogeneous information network embedding , author=. 2020 IEEE International Conference on Big Data (Big Data) , pages=. 2020 , organization=
2020
-
[37]
2020 IEEE International Conference on Big Data (Big Data) , pages=
Pattern-enhanced named entity recognition with distant supervision , author=. 2020 IEEE International Conference on Big Data (Big Data) , pages=. 2020 , organization=
2020
-
[38]
2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021 , pages=
COVID-19 Literature Knowledge Graph Construction and Drug Repurposing Report Generation , author=. 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021 , pages=. 2021 , organization=
2021
-
[39]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations , pages=
Evidenceminer: Textual evidence discovery for life sciences , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations , pages=
-
[40]
Bioinformatics , volume=
Cross-type biomedical named entity recognition with deep multi-task learning , author=. Bioinformatics , volume=. 2018 , publisher=
2018
-
[41]
Journal of visualized experiments: JoVE , number=
Cloud-based phrase mining and analysis of user-defined phrase-category association in biomedical publications , author=. Journal of visualized experiments: JoVE , number=
-
[42]
2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=
Pattern discovery for wide-window open information extraction in biomedical literature , author=. 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=. 2018 , organization=
2018
-
[43]
2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=
PENNER: Pattern-enhanced nested named entity recognition in biomedical literature , author=. 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=. 2018 , organization=
2018
-
[44]
American Journal of Physiology-Heart and Circulatory Physiology , volume=
Phrase mining of textual data to analyze extracellular matrix protein patterns across cardiovascular disease , author=. American Journal of Physiology-Heart and Circulatory Physiology , volume=. 2018 , publisher=
2018
-
[45]
Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics , pages=
Open information extraction with meta-pattern discovery in biomedical literature , author=. Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics , pages=
2018
-
[46]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Maximal Matching Matters: Preventing Representation Collapse for Robust Cross-Modal Retrieval , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[47]
Advances in neural information processing systems , volume=
Predicting the politics of an image using webly supervised data , author=. Advances in neural information processing systems , volume=
-
[48]
Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XVIII 16 , pages=
Preserving semantic neighborhoods for robust cross-modal retrieval , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XVIII 16 , pages=. 2020 , organization=
2020
-
[49]
International Journal of Computer Vision , volume=
Predicting visual political bias using webly supervised data and an auxiliary task , author=. International Journal of Computer Vision , volume=. 2021 , publisher=
2021
-
[50]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Emphasizing complementary samples for non-literal cross-modal retrieval , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
Journeybench: A challenging one-stop vision-language understanding benchmark of generated images , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Automatic understanding of image and video advertisements , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[53]
European Conference on Computer Vision , pages=
Fine-grained visual entailment , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[54]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
MetaSumPerceiver: Multimodal Multi-Document Evidence Summarization for Fact-Checking , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
I nfo S urgeon: Cross-Media Fine-grained Information Consistency Checking for Fake News Detection
Fung, Yi and Thomas, Christopher and Gangi Reddy, Revanth and Polisetty, Sandeep and Ji, Heng and Chang, Shih-Fu and McKeown, Kathleen and Bansal, Mohit and Sil, Avi. I nfo S urgeon: Cross-Media Fine-grained Information Consistency Checking for Fake News Detection. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and...
-
[56]
and Mehrab, Kazi Sajeed and Ishmam, Alvi Md and Thomas, Chris
Tang, Chia-Wei and Chen, Ting-Chih and Nguyen, Kiet A. and Mehrab, Kazi Sajeed and Ishmam, Alvi Md and Thomas, Chris. M 3 D : M ulti M odal M ulti D ocument Fine-Grained Inconsistency Detection. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1243
-
[57]
2023 , eprint=
YaRN: Efficient Context Window Extension of Large Language Models , author=. 2023 , eprint=
2023
-
[58]
2024 , eprint=
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens , author=. 2024 , eprint=
2024
-
[59]
arXiv preprint arXiv:2309.10400 , year=
Pose: Efficient context window extension of llms via positional skip-wise training , author=. arXiv preprint arXiv:2309.10400 , year=
-
[60]
2023 , eprint=
Effective Long-Context Scaling of Foundation Models , author=. 2023 , eprint=
2023
-
[61]
2023 , eprint=
LongNet: Scaling Transformers to 1,000,000,000 Tokens , author=. 2023 , eprint=
2023
-
[62]
2024 , eprint=
LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning , author=. 2024 , eprint=
2024
-
[63]
2024 , eprint=
Training-Free Long-Context Scaling of Large Language Models , author=. 2024 , eprint=
2024
-
[64]
2022 , eprint=
Memorizing Transformers , author=. 2022 , eprint=
2022
-
[65]
2023 , eprint=
Unlimiformer: Long-Range Transformers with Unlimited Length Input , author=. 2023 , eprint=
2023
-
[66]
2023 , eprint=
Augmenting Language Models with Long-Term Memory , author=. 2023 , eprint=
2023
-
[67]
Long-Context Language Modeling with Parallel Context Encoding
Yen, Howard and Gao, Tianyu and Chen, Danqi. Long-Context Language Modeling with Parallel Context Encoding. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.142
-
[68]
2024 , eprint=
Jamba: A Hybrid Transformer-Mamba Language Model , author=. 2024 , eprint=
2024
-
[69]
2024 , eprint=
Differential Transformer , author=. 2024 , eprint=
2024
-
[70]
2024 , eprint=
You Only Cache Once: Decoder-Decoder Architectures for Language Models , author=. 2024 , eprint=
2024
-
[71]
2024 , eprint=
Data Engineering for Scaling Language Models to 128K Context , author=. 2024 , eprint=
2024
-
[72]
2024 , eprint=
How to Train Long-Context Language Models (Effectively) , author=. 2024 , eprint=
2024
-
[73]
2024 , eprint=
Make Your LLM Fully Utilize the Context , author=. 2024 , eprint=
2024
-
[74]
L ong A lign: A Recipe for Long Context Alignment of Large Language Models
Bai, Yushi and Lv, Xin and Zhang, Jiajie and He, Yuze and Qi, Ji and Hou, Lei and Tang, Jie and Dong, Yuxiao and Li, Juanzi. L ong A lign: A Recipe for Long Context Alignment of Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.74
-
[75]
arXiv preprint arXiv:2410.21252 , year=
LongReward: Improving Long-context Large Language Models with AI Feedback , author=. arXiv preprint arXiv:2410.21252 , year=
-
[76]
Advances in Neural Information Processing Systems , volume=
Multimodal few-shot learning with frozen language models , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
arXiv preprint arXiv:2209.06794 , year=
Pali: A jointly-scaled multilingual language-image model , author=. arXiv preprint arXiv:2209.06794 , year=
-
[78]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[79]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[80]
arXiv preprint arXiv:2308.01390 , year=
Openflamingo: An open-source framework for training large autoregressive vision-language models , author=. arXiv preprint arXiv:2308.01390 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.