AURA: Adaptive Uncertainty-aware Refinement for LLM-as-a-Judge Auditing
Pith reviewed 2026-06-26 15:45 UTC · model grok-4.3
The pith
AURA refines LLM judge trust as a latent quantity by prioritizing uncertain pairwise comparisons for selective human review.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
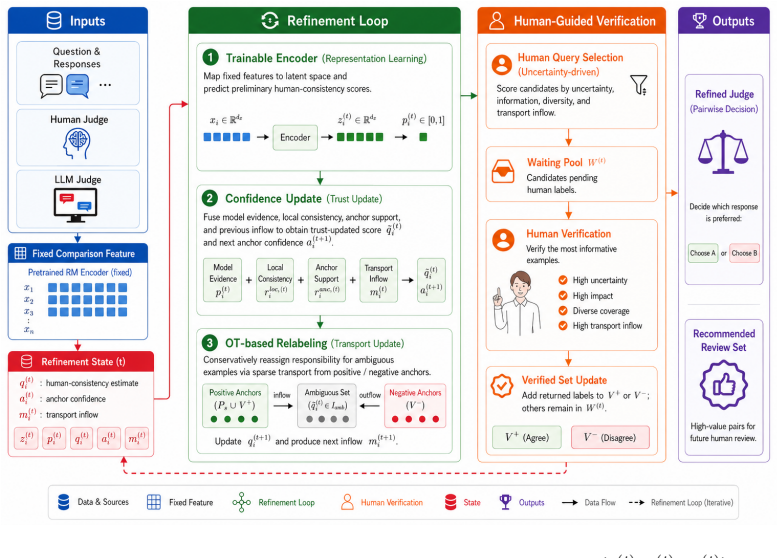
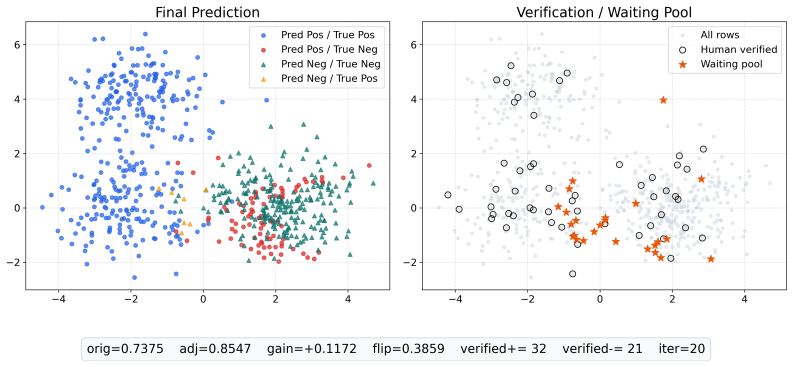
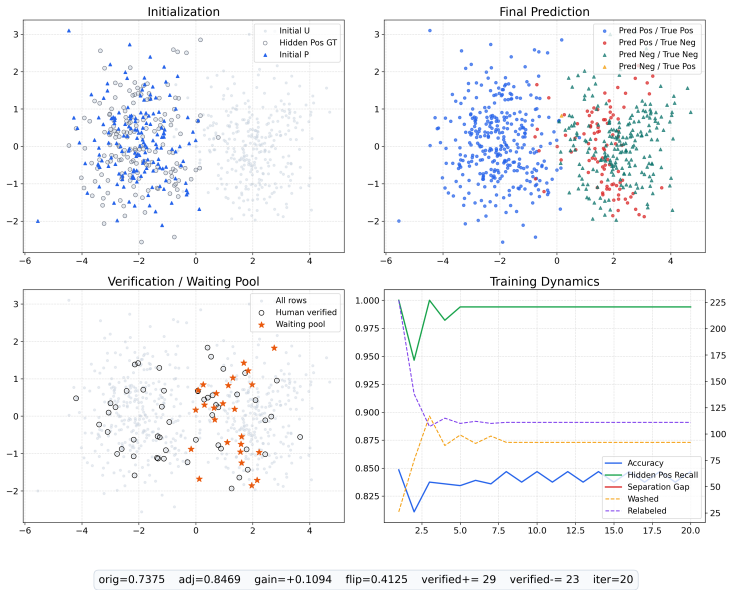
AURA is an adaptive uncertainty-aware refinement framework for auditing pairwise LLM-as-a-judge decisions. It treats trust in the judge as a latent quantity that is progressively refined as evidence accumulates through human verification of prioritized uncertain comparisons. The framework supplies a compact formulation and a stable refinement procedure that operates without presupposing a reliable initial subset of examples, demonstrated on both synthetic and real pairwise LLM-answer data.
What carries the argument
The adaptive uncertainty-aware refinement procedure, which iteratively updates a latent judge-trust signal by selecting uncertain comparisons for human review and propagating reliable evidence.
If this is right
- Auditing pipelines can scale to larger sets of pairwise judgments while using fewer total human labels.
- Consistency signals improve over successive iterations as reliable evidence propagates.
- The method avoids the need to curate or trust any fixed clean subset at the start.
- Evaluation covers both synthetic and real LLM pairwise data, showing the refinement procedure in practice.
Where Pith is reading between the lines
- The same iterative selection of uncertain cases could apply to other forms of LLM preference data beyond pairwise comparisons.
- If the latent-trust model holds, one could run the procedure with multiple different LLM judges and compare the refined signals they produce.
- The framework suggests a possible link to active-learning strategies where uncertainty directly drives the next human query.
- Longer-term runs might reveal whether the refined signals remain stable when new judges or new domains are introduced.
Load-bearing premise
Treating judge trust as a latent quantity that can be progressively refined through selective human verification on uncertain cases will produce stable and unbiased consistency signals without requiring an initial reliable subset of examples.
What would settle it
A controlled test in which AURA is run on data with known initial bias and the resulting consistency signals are compared against ground-truth human preferences to check whether bias is reduced or amplified.
Figures
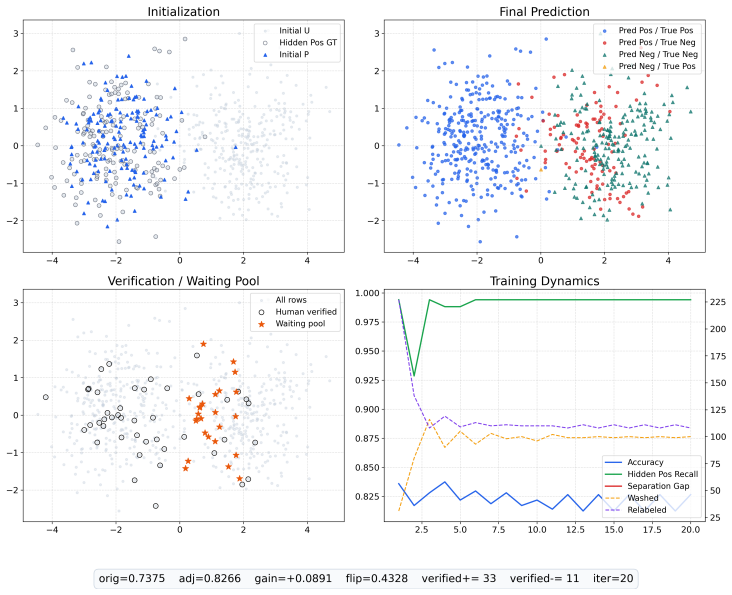
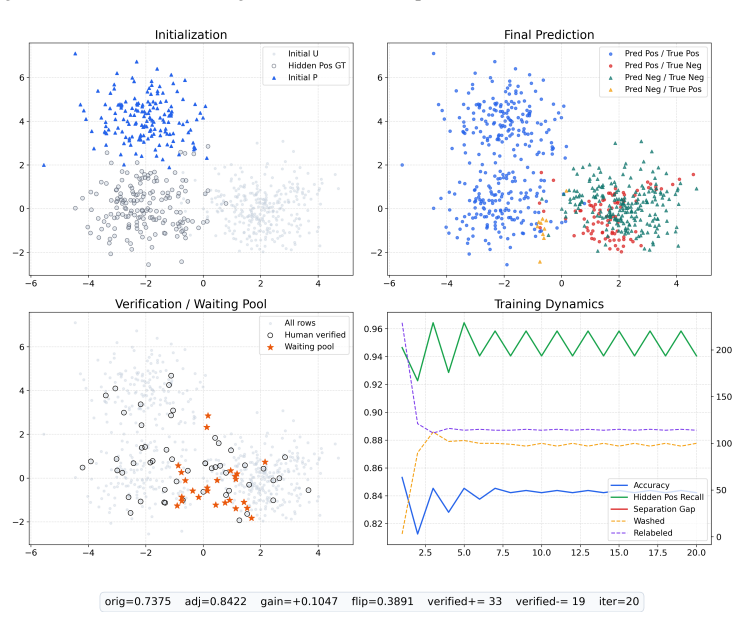
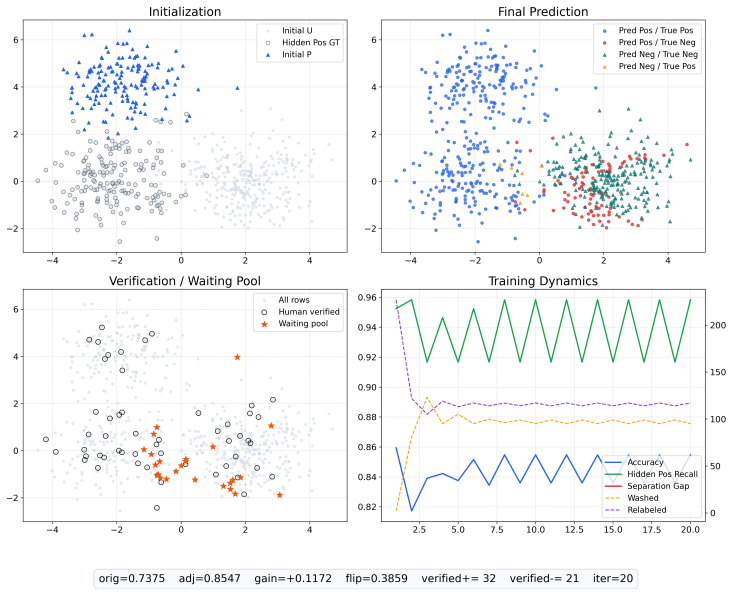
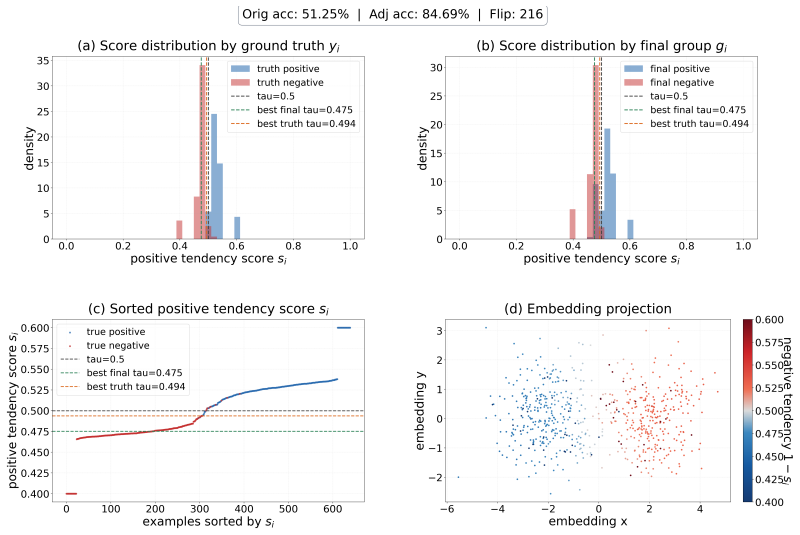
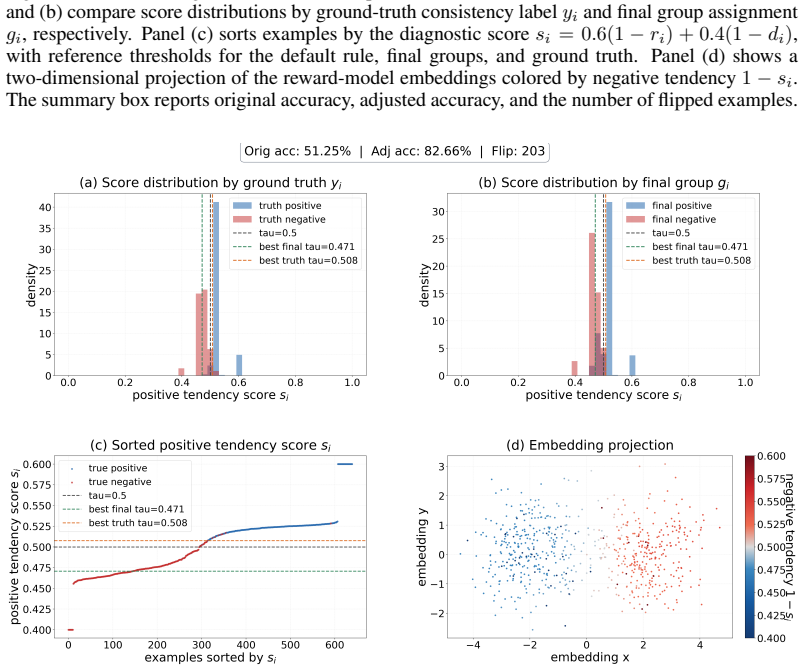
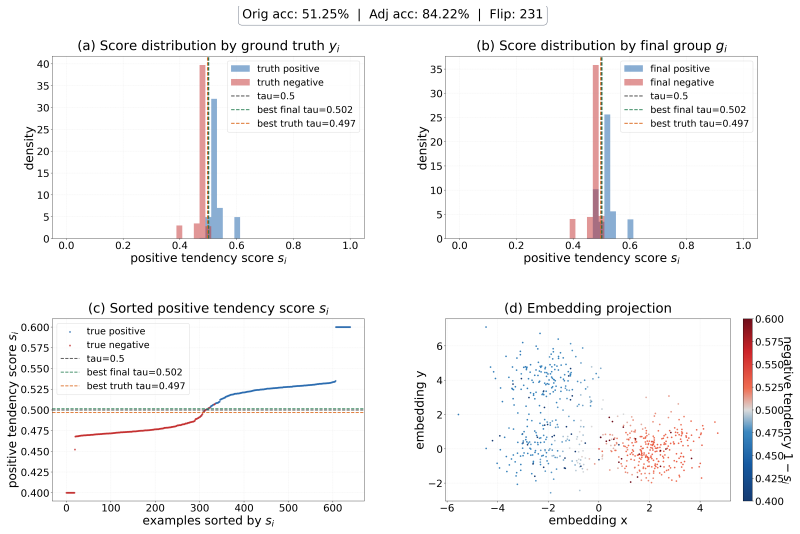
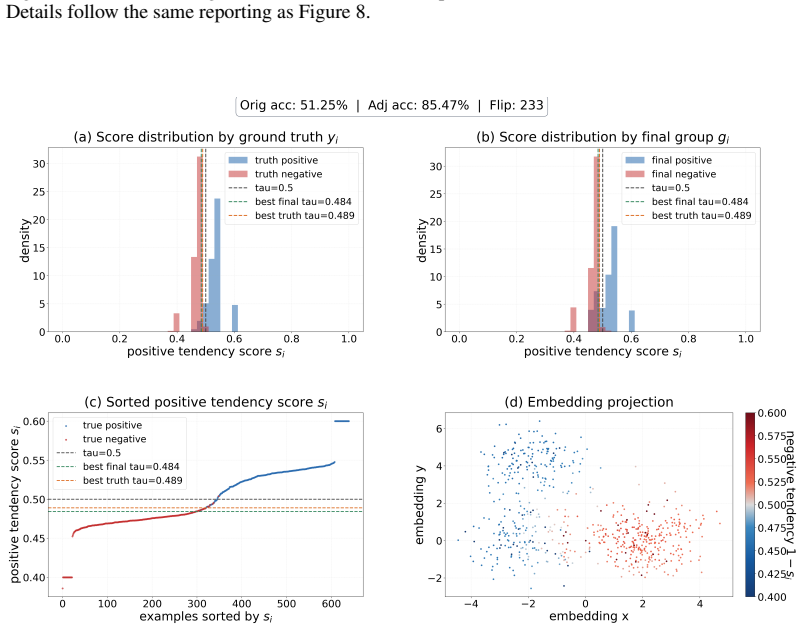
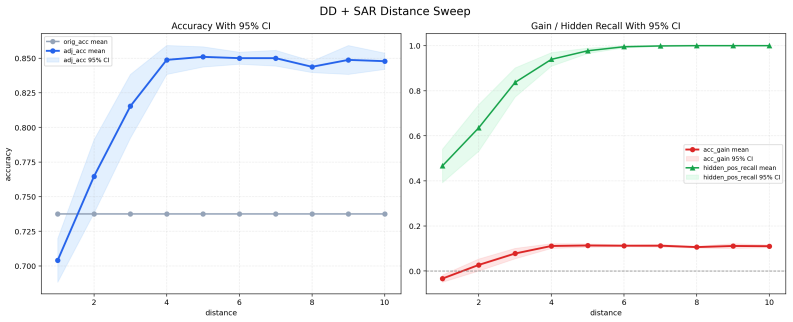
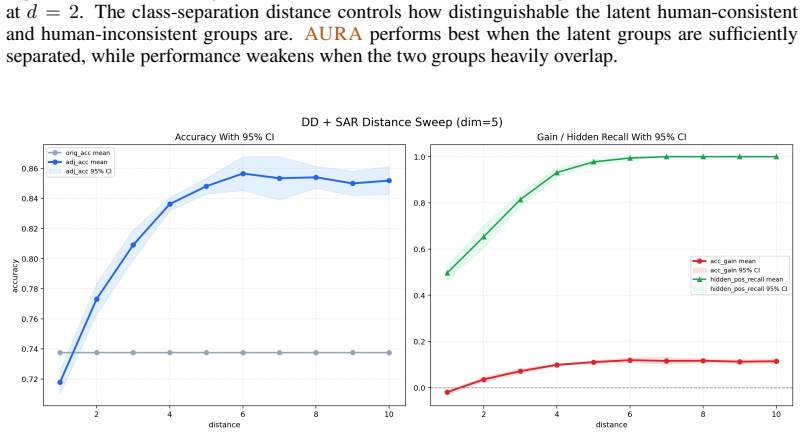
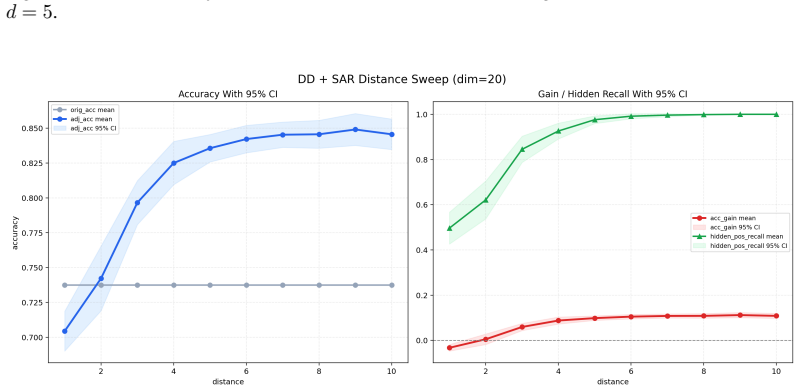
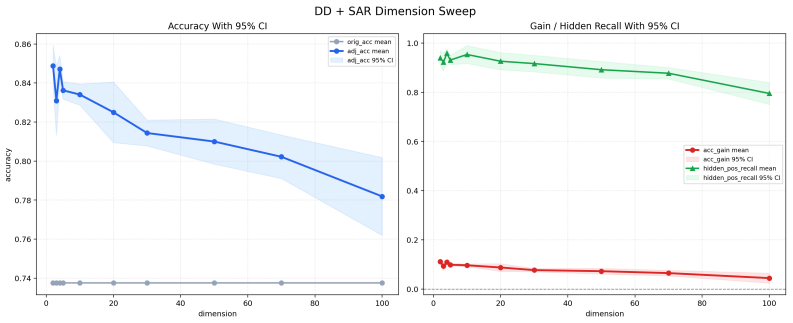
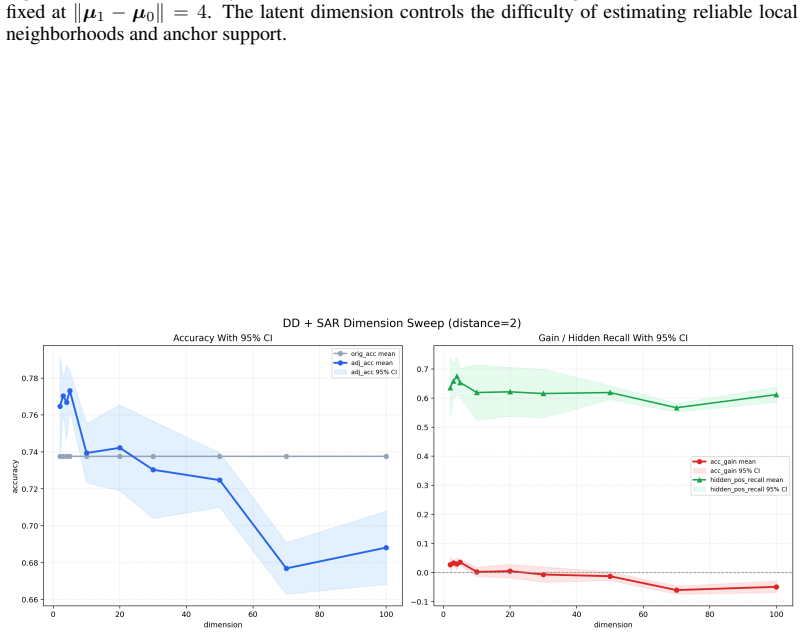
read the original abstract
Large language models (LLMs) are increasingly used as judges for open-ended generation, as large-scale human evaluation is often expensive and difficult to scale, yet their preferences remain imperfect proxies for human judgment. Existing auditing pipelines often assume that a reliable subset of examples or clean supervision signals are available beforehand, for example from human annotation, heuristic filtering, or the outputs of strong judges. In LLM evaluation, this assumption is fragile: the initial split may inherit judge bias, while human verification is typically too scarce to define stable groups at scale. We propose AURA, an adaptive uncertainty--aware refinement framework for auditing pairwise LLM--as--a--judge decisions under selected human verification. AURA iteratively learns a human-consistency signal, propagates reliable evidence, and prioritizes uncertain comparisons for human review. The key idea is to treat trust in a judge as a latent quantity that is progressively refined as evidence accumulates. We provide a compact formulation, a stable refinement procedure, and a comprehensive evaluation on both synthetic and real pairwise LLM-answer data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AURA, an adaptive uncertainty-aware refinement framework for auditing pairwise LLM-as-a-judge decisions under selective human verification. It iteratively learns a human-consistency signal, propagates reliable evidence, and prioritizes uncertain comparisons for human review by modeling judge trust as a latent quantity that is progressively refined without requiring an initial reliable subset of examples. The paper claims to supply a compact formulation, a stable refinement procedure, and comprehensive evaluation on synthetic and real pairwise LLM-answer data.
Significance. If the refinement procedure is stable and recovers unbiased human-consistency signals from uncertain starting comparisons, the work would address a practical bottleneck in scalable LLM evaluation by reducing dependence on large initial clean supervision sets. This could improve auditing pipelines for open-ended generation tasks where human verification is scarce.
major comments (2)
- [Abstract] Abstract: the central claim that iteration alone produces a stable and unbiased consistency signal without an initial reliable subset is unsupported; no fixed-point analysis, update equations, or bias bound is supplied to show that evidence propagation from uncertain pairs avoids inheriting or amplifying judge bias.
- [Abstract] The weakest assumption (no initial anchor needed) is load-bearing for the contribution over existing pipelines, yet the manuscript provides neither convergence guarantees nor an empirical demonstration that the procedure remains stable when the initial evidence is drawn exclusively from uncertain comparisons.
minor comments (1)
- The abstract contains a typesetting artifact ('uncertainty--aware' with double dash) that should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the stability and unbiasedness of the AURA refinement procedure. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that iteration alone produces a stable and unbiased consistency signal without an initial reliable subset is unsupported; no fixed-point analysis, update equations, or bias bound is supplied to show that evidence propagation from uncertain pairs avoids inheriting or amplifying judge bias.
Authors: Section 3 presents a compact formulation together with explicit update equations for the latent trust quantities that are refined iteratively from accumulated human-verified evidence. While the current manuscript does not contain a formal fixed-point analysis or bias bounds, the procedure is constructed to propagate only verified signals and the empirical results in Section 5 demonstrate stability on synthetic data initialized from uncertain comparisons. We will add a convergence analysis and bias discussion in the revised version. revision: yes
-
Referee: [Abstract] The weakest assumption (no initial anchor needed) is load-bearing for the contribution over existing pipelines, yet the manuscript provides neither convergence guarantees nor an empirical demonstration that the procedure remains stable when the initial evidence is drawn exclusively from uncertain comparisons.
Authors: The experiments in Section 5 already include synthetic regimes in which all initial comparisons are uncertain, showing that the iterative refinement recovers consistent signals. We nevertheless agree that an explicit ablation isolating the no-initial-anchor case and a statement of convergence properties would strengthen the contribution. Both will be added to the revised manuscript. revision: yes
Circularity Check
No circularity: framework description contains no equations or self-referential reductions
full rationale
The provided abstract and context describe an iterative refinement procedure for judge trust as a latent variable but supply no equations, fitted parameters, or derivations. No self-citations, ansatzes, or uniqueness theorems are quoted that would reduce the output to the input by construction. The central claim of a stable refinement procedure is asserted without mathematical detail in the visible text, so no load-bearing circular step can be exhibited. This is the default honest finding when no reduction is demonstrable from the paper's own statements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[2]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =
-
[3]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Large Language Models are not Fair Evaluators , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , publisher =
2024
-
[4]
Optimizing Methods in Statistics , pages=
A convergence theorem for non negative almost supermartingales and some applications , author=. Optimizing Methods in Statistics , pages=
-
[5]
IEEE transactions on pattern analysis and machine intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2013 , publisher=
2013
-
[6]
Dubois, Yann and Galambosi, Bal. Length-Controlled. arXiv preprint arXiv:2404.04475 , year =. 2404.04475 , archivePrefix =
-
[7]
Dubois, Yann and Li, Xuechen and Taori, Rohan and Zhang, Tianyi and Gulrajani, Ishaan and Ba, Jimmy and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , booktitle =. 2023 , url =. 2305.14387 , archivePrefix =
arXiv 2023
-
[8]
International Conference on Learning Representations , year =
Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models , author =. International Conference on Learning Representations , year =. 2310.08491 , archivePrefix =
-
[9]
Zhu, Lianghui and Wang, Xinggang and Wang, Xinlong , booktitle =. 2025 , url =. 2310.17631 , archivePrefix =
arXiv 2025
-
[10]
Wang, Yidong and Yu, Zhuohao and Yao, Wenjin and Zeng, Zhengran and Yang, Linyi and Wang, Cunxiang and Chen, Hao and Jiang, Chaoya and Xie, Rui and Wang, Jindong and Xie, Xing and Ye, Wei and Zhang, Shikun and Zhang, Yue , booktitle =. 2024 , url =. 2306.05087 , archivePrefix =
arXiv 2024
-
[11]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[12]
Advances in Neural Information Processing Systems , volume =
Learning to Summarize with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[13]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =. 2305.18290 , archivePrefix =
Pith/arXiv arXiv 2023
-
[14]
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, LJ and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh , booktitle =. 2025 , publisher =. doi:10.18653/v1/2025.findings-naacl.96 , url =. 2403.13787 , archivePrefix =
-
[15]
Learning Classifiers from Only Positive and Unlabeled Data , author =. Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2008 , publisher =. doi:10.1145/1401890.1401920 , url =
-
[16]
Advances in Neural Information Processing Systems , volume =
Analysis of Learning from Positive and Unlabeled Data , author =. Advances in Neural Information Processing Systems , volume =. 2014 , url =
2014
-
[17]
Proceedings of the 32nd International Conference on Machine Learning , series =
Convex Formulation for Learning from Positive and Unlabeled Data , author =. Proceedings of the 32nd International Conference on Machine Learning , series =. 2015 , publisher =
2015
-
[18]
Advances in Neural Information Processing Systems , volume =
Positive-Unlabeled Learning with Non-Negative Risk Estimator , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[19]
Machine Learning , volume =
Learning from Positive and Unlabeled Data: A Survey , author =. Machine Learning , volume =. 2020 , doi =
2020
-
[20]
Proceedings of the 36th International Conference on Machine Learning , series =
Classification from Positive, Unlabeled and Biased Negative Data , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =. 1810.00846 , archivePrefix =
Pith/arXiv arXiv 2019
-
[21]
Advances in Neural Information Processing Systems , volume =
Data Programming: Creating Large Training Sets, Quickly , author =. Advances in Neural Information Processing Systems , volume =. 2016 , url =
2016
-
[22]
Proceedings of the VLDB Endowment , volume =
Snorkel: Rapid Training Data Creation with Weak Supervision , author =. Proceedings of the VLDB Endowment , volume =. 2017 , doi =
2017
-
[23]
Journal of Artificial Intelligence Research , volume =
Confident Learning: Estimating Uncertainty in Dataset Labels , author =. Journal of Artificial Intelligence Research , volume =. 2021 , doi =
2021
-
[24]
Advances in Neural Information Processing Systems , volume =
Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels , author =. Advances in Neural Information Processing Systems , volume =. 2018 , url =. 1804.06872 , archivePrefix =
Pith/arXiv arXiv 2018
-
[25]
and Cubuk, Ekin Dogus and Kurakin, Alexey and Li, Chun-Liang , booktitle =
Sohn, Kihyuk and Berthelot, David and Carlini, Nicholas and Zhang, Zizhao and Zhang, Han and Raffel, Colin A. and Cubuk, Ekin Dogus and Kurakin, Alexey and Li, Chun-Liang , booktitle =. 2020 , url =
2020
-
[26]
2009 , url =
Active Learning Literature Survey , author =. 2009 , url =
2009
-
[27]
ACM Computing Surveys , volume =
A Survey of Deep Active Learning , author =. ACM Computing Surveys , volume =. 2021 , doi =
2021
-
[28]
Advances in Neural Information Processing Systems , volume =
Sinkhorn Distances: Lightspeed Computation of Optimal Transport , author =. Advances in Neural Information Processing Systems , volume =. 2013 , url =. 1306.0895 , archivePrefix =
Pith/arXiv arXiv 2013
-
[29]
Foundations and Trends in Machine Learning , volume =
Computational Optimal Transport , author =. Foundations and Trends in Machine Learning , volume =. 2019 , doi =. 1803.00567 , archivePrefix =
arXiv 2019
-
[30]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Optimal Transport for Domain Adaptation , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2017 , doi =
2017
-
[31]
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Chatbot Arena: An Open Platform for Evaluating. 2024 , publisher =. 2403.04132 , archivePrefix =
Pith/arXiv arXiv 2024
-
[32]
International Conference on Learning Representations , year =
Evaluating Large Language Models at Evaluating Instruction Following , author =. International Conference on Learning Representations , year =. 2310.07641 , archivePrefix =
-
[33]
Tan, Sijun and Zhuang, Siyuan and Montgomery, Kyle and Tang, William Yuan and Cuadron, Alejandro and Wang, Chenguang and Popa, Raluca Ada and Stoica, Ion , booktitle =. 2025 , url =. 2410.12784 , archivePrefix =
Pith/arXiv arXiv 2025
-
[34]
Park, Junsoo and Jwa, Seungyeon and Ren, Meiying and Kim, Daeyoung and Choi, Sanghyuk , booktitle =. 2024 , publisher =. doi:10.18653/v1/2024.findings-emnlp.57 , url =. 2407.06551 , archivePrefix =
-
[35]
Judging the Judges: Evaluating Alignment and Vulnerabilities in
Thakur, Aman Singh and Choudhary, Kartik and Ramayapally, Venkat Srinik and Vaidyanathan, Sankaran and Hupkes, Dieuwke , booktitle =. Judging the Judges: Evaluating Alignment and Vulnerabilities in. 2025 , publisher =. 2406.12624 , archivePrefix =
arXiv 2025
-
[36]
Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , author =. Biometrika , volume =. 1952 , publisher =. doi:10.1093/biomet/39.3-4.324 , url =
-
[37]
Advances in Neural Information Processing Systems , volume =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =
2017
-
[38]
arXiv preprint arXiv:2204.05862 , year =
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. arXiv preprint arXiv:2204.05862 , year =. 2204.05862 , archivePrefix =
-
[39]
Advances in Neural Information Processing Systems , volume =
Estimating the Class Prior and Posterior from Noisy Positives and Unlabeled Data , author =. Advances in Neural Information Processing Systems , volume =. 2016 , url =
2016
-
[40]
Chen, Xuxi and Chen, Wuyang and Chen, Tianlong and Yuan, Ye and Gong, Chen and Chen, Kewei and Wang, Zhangyang , booktitle =. Self-. 2020 , publisher =. 2006.11280 , archivePrefix =
arXiv 2020
-
[41]
2002 , url =
Learning from Labeled and Unlabeled Data with Label Propagation , author =. 2002 , url =
2002
-
[42]
Advances in Neural Information Processing Systems , volume =
Learning with Local and Global Consistency , author =. Advances in Neural Information Processing Systems , volume =. 2003 , url =
2003
-
[43]
Journal of Machine Learning Research , volume =
Manifold Regularization: A Geometric Framework for Learning from Labeled and Unlabeled Examples , author =. Journal of Machine Learning Research , volume =. 2006 , url =
2006
-
[44]
Mathematics of Computation , volume =
Scaling Algorithms for Unbalanced Optimal Transport Problems , author =. Mathematics of Computation , volume =. 2018 , doi =
2018
-
[45]
Advances in Neural Information Processing Systems , volume =
Partial Optimal Transport with Applications on Positive-Unlabeled Learning , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[46]
International Conference on Learning Representations , year =
Active Learning for Convolutional Neural Networks: A Core-Set Approach , author =. International Conference on Learning Representations , year =
-
[47]
Kirsch, Andreas and van Amersfoort, Joost and Gal, Yarin , booktitle =. 2019 , url =. 1906.08158 , archivePrefix =
arXiv 2019
-
[48]
Advances in Neural Information Processing Systems , volume =
Selective Classification for Deep Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2017 , url =. 1705.08500 , archivePrefix =
Pith/arXiv arXiv 2017
-
[49]
Geifman, Yonatan and El-Yaniv, Ran , booktitle =. 2019 , publisher =. 1901.09192 , archivePrefix =
Pith/arXiv arXiv 2019
-
[50]
Proceedings of the 34th International Conference on Machine Learning , series =
On Calibration of Modern Neural Networks , author =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =. 1706.04599 , archivePrefix =
Pith/arXiv arXiv 2017
-
[51]
Predicting good probabilities with supervised learning , isbn =
Predicting Good Probabilities with Supervised Learning , author =. Proceedings of the 22nd International Conference on Machine Learning , pages =. 2005 , publisher =. doi:10.1145/1102351.1102430 , url =
-
[52]
Proceedings of the 38th International Conference on Machine Learning , pages =
Confidence Scores Make Instance-dependent Label-noise Learning Possible , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[53]
Advances in Neural Information Processing Systems , volume =
Part-dependent Label Noise: Towards Instance-dependent Label Noise , author =. Advances in Neural Information Processing Systems , volume =
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Instance-Dependent Label-Noise Learning with Manifold-Regularized Transition Matrix Estimation , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[55]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[56]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[57]
2024 , howpublished=
Gemini 2.5 Flash , author=. 2024 , howpublished=
2024
-
[58]
2024 , howpublished=
Skywork-Reward-Llama-3.1-8B-v0.2 , author =. 2024 , howpublished=
2024
-
[59]
2025 , howpublished=
GPT-5.4 and GPT-5.4-mini , author=. 2025 , howpublished=
2025
-
[60]
Journal of the Royal Statistical Society: Series B , volume=
The Regression Analysis of Binary Sequences , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[61]
Nature , volume=
Learning Representations by Back-propagating Errors , author=. Nature , volume=
-
[62]
Machine Learning , volume=
Random Forests , author=. Machine Learning , volume=
-
[63]
2026 , howpublished =
Introducing GPT-5.4 , author =. 2026 , howpublished =
2026
-
[64]
1999 , publisher=
Nonlinear Programming , author=. 1999 , publisher=
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.