Beyond Uniform Forgetting: A Study of Sequential Direct Preference Optimization Across Preference Settings
Pith reviewed 2026-06-26 18:00 UTC · model grok-4.3
The pith
Sequential DPO produces varied preference changes rather than uniform forgetting, depending on objective relationships and training order.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
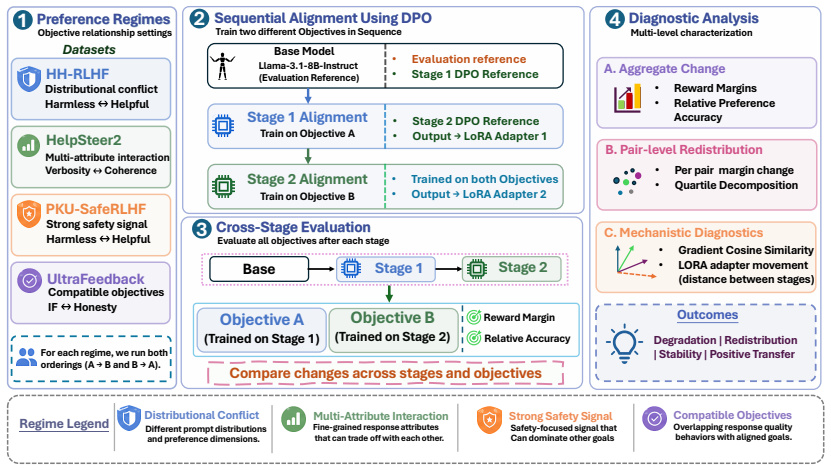
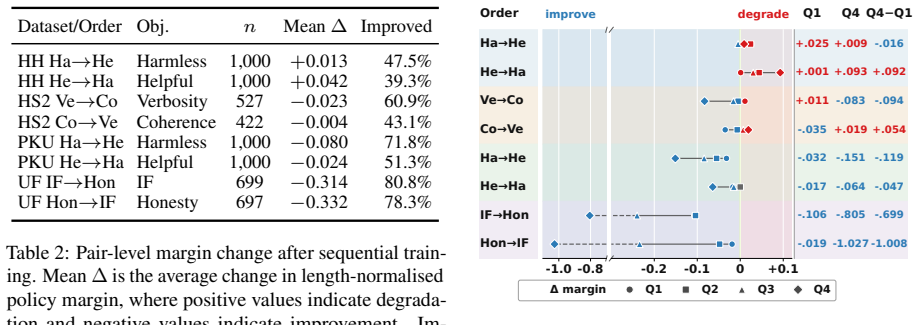
Sequential DPO does not produce a single forgetting pattern; preference change ranges from partial degradation to stability, pair-level redistribution, or positive transfer depending on objective relationship, signal strength, and training order. Pair-level analysis using length-normalised policy margins shows that aggregate metrics can mask heterogeneous changes across preference pairs, whereas quartile decomposition reveals that high-confidence pairs can either degrade or improve depending on the setting. Mechanistic diagnostics show that Stage 2 gradients and adapter updates are near-orthogonal to the previous objective across all settings, providing little evidence that direct gradient o
What carries the argument
Sequential DPO across four preference settings with fixed base-model reference evaluation after each stage and length-normalised policy margin analysis.
If this is right
- Later training stages do not uniformly degrade preferences acquired earlier.
- Objective compatibility and signal strength determine whether earlier preferences degrade, stay stable, redistribute, or improve.
- Training order influences the direction and size of preference shifts.
- Aggregate performance scores can conceal pair-level redistributions that quartile analysis uncovers.
- Near-orthogonal gradients between stages suggest mechanisms other than direct opposition drive the observed changes.
Where Pith is reading between the lines
- Alignment pipelines could improve by selecting objective sequences according to measured compatibility instead of applying them in arbitrary order.
- The same non-uniform patterns may appear when using other preference optimization techniques beyond DPO.
- Monitoring individual high-confidence preference pairs rather than averages could give earlier warning of unintended shifts.
- Extending the fixed-reference protocol to larger models or full fine-tuning would test whether the orthogonality result generalizes.
Load-bearing premise
The four chosen preference settings represent real-world objective relationships and the fixed base-model reference isolates sequential effects without confounding factors from data construction or model updates.
What would settle it
Observing uniform degradation across all four settings or finding that gradient opposition between stages correlates directly with measured preference loss.
Figures
read the original abstract
Aligning language models with human preferences often requires optimising multiple behavioural objectives. A practical approach is to apply these objectives sequentially using preference optimisation methods such as Direct Preference Optimisation (DPO), but it remains unclear whether later training uniformly degrades preferences learned earlier or whether the effect depends on the relationship between objectives. We study sequential DPO across four preference settings covering distributional conflict, multi-attribute interaction, strong safety signal, and compatible response-quality objectives. Using Llama-3.1-8B-Instruct with LoRA adapters, we evaluate all objectives after every stage with a fixed base-model reference. We find that sequential DPO does not produce a single forgetting pattern; preference change ranges from partial degradation to stability, pair-level redistribution, or positive transfer depending on objective relationship, signal strength, and training order. Pair-level analysis using length-normalised policy margins shows that aggregate metrics can mask heterogeneous changes across preference pairs, whereas quartile decomposition reveals that high-confidence pairs can either degrade or improve depending on the setting. Mechanistic diagnostics show that Stage~2 gradients and adapter updates are near-orthogonal to the previous objective across all settings, providing little evidence that direct gradient opposition is the primary driver. These findings suggest that future sequential alignment pipelines should account for objective compatibility and signal strength, rather than assuming that later objectives affect earlier preferences uniformly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sequential DPO across multiple preference objectives does not produce uniform forgetting of earlier preferences. Instead, effects range from partial degradation to stability, pair-level redistribution, or positive transfer, depending on objective relationship, signal strength, and training order. Experiments use Llama-3.1-8B-Instruct with LoRA adapters on four settings (distributional conflict, multi-attribute interaction, strong safety signal, compatible response-quality), evaluating all objectives after each stage against a fixed base-model reference. Additional analyses include length-normalised policy margins for pair-level changes, quartile decomposition, and mechanistic checks showing near-orthogonal Stage-2 gradients and adapter updates to prior objectives.
Significance. If the empirical patterns hold, the work is significant for alignment research because it provides concrete evidence against the default assumption of uniform degradation in sequential preference optimisation. The use of a fixed base reference, pair-level margin analysis, quartile breakdowns, and gradient orthogonality diagnostics are strengths that allow finer-grained claims than aggregate metrics alone. These findings could directly inform the design of multi-objective alignment pipelines by highlighting the roles of compatibility and signal strength.
major comments (2)
- [experimental settings] Description of the four preference settings: no taxonomy, sampling argument, or justification is given for why these four (distributional conflict, multi-attribute interaction, strong safety signal, compatible response-quality) adequately cover or sample the space of objective relationships; without this, the claim that patterns 'depend on objective relationship' rests on an uncharacterised selection whose commonalities in pair construction could explain the observed heterogeneity.
- [evaluation methodology] Evaluation protocol using fixed base-model reference after each stage: the manuscript does not report controls or ablations for whether LoRA adapter stacking, data-construction artifacts, or non-merged model updates introduce confounds that would differ under full-parameter sequential training; this weakens the isolation of purely sequential DPO effects.
minor comments (1)
- [abstract] The abstract states high-level findings without referencing any quantitative results, error bars, or statistical tests; moving a brief summary of key metrics (e.g., margin changes or orthogonality values) into the abstract would improve immediate verifiability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and limitations of our study on sequential DPO. We provide point-by-point responses to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [experimental settings] Description of the four preference settings: no taxonomy, sampling argument, or justification is given for why these four (distributional conflict, multi-attribute interaction, strong safety signal, compatible response-quality) adequately cover or sample the space of objective relationships; without this, the claim that patterns 'depend on objective relationship' rests on an uncharacterised selection whose commonalities in pair construction could explain the observed heterogeneity.
Authors: The four settings were deliberately selected to probe different categories of objective relationships based on prior literature in multi-objective alignment: distributional conflict (opposing data distributions), multi-attribute interaction (trade-offs across attributes like helpfulness and harmlessness), strong safety signal (high-priority overriding objective), and compatible response-quality (aligned objectives that can reinforce each other). While we do not claim exhaustive coverage, these represent a range along the dimensions of compatibility and signal strength. To address potential commonalities in pair construction, each setting employs distinct data sources and pair generation methods specific to the objective (e.g., using safety-specific preference pairs for the safety setting versus quality-focused pairs). We will revise the manuscript to include an explicit taxonomy of objective relationships and a sampling argument in a new subsection, along with more details on pair construction to demonstrate differentiation. revision: yes
-
Referee: [evaluation methodology] Evaluation protocol using fixed base-model reference after each stage: the manuscript does not report controls or ablations for whether LoRA adapter stacking, data-construction artifacts, or non-merged model updates introduce confounds that would differ under full-parameter sequential training; this weakens the isolation of purely sequential DPO effects.
Authors: We recognize this as a valid concern regarding the generalizability of our findings. The choice of LoRA with a fixed base reference was made to enable efficient sequential training and to measure changes relative to the initial model without the confounding effects of model merging. However, we did not conduct ablations with full-parameter updates or merged adapters. In the revised manuscript, we will expand the discussion and limitations sections to explicitly address potential confounds from adapter stacking and data artifacts, and clarify that our results are specific to the LoRA-based sequential setup. The near-orthogonal gradient findings provide supporting evidence that is less dependent on the parameter update method. revision: partial
Circularity Check
No significant circularity: empirical measurements only
full rationale
The paper is a purely empirical study reporting experimental results from sequential DPO training on four preference settings. It contains no mathematical derivation chain, no equations that define quantities in terms of themselves, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. All reported patterns (degradation, stability, redistribution, transfer) and diagnostics (gradient orthogonality) are direct outputs of the described experiments and evaluations against a fixed base-model reference. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
PKU- SafeRLHF: Towards multi-level safety alignment for LLMs with human preference
Ji, Jiaming and Hong, Donghai and Zhang, Borong and Chen, Boyuan and Dai, Josef and Zheng, Boren and Qiu, Tianyi Alex and Zhou, Jiayi and Wang, Kaile and Li, Boxun and Han, Sirui and Guo, Yike and Yang, Yaodong. PKU - S afe RLHF : Towards Multi-Level Safety Alignment for LLM s with Human Preference. Proceedings of the 63rd Annual Meeting of the Associatio...
-
[2]
arXiv preprint arXiv:2308.05374 , year=
Trustworthy llms: a survey and guideline for evaluating large language models' alignment , author=. arXiv preprint arXiv:2308.05374 , year=
-
[3]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[5]
arXiv preprint arXiv:2310.01377 , year=
Ultrafeedback: Boosting language models with scaled ai feedback , author=. arXiv preprint arXiv:2310.01377 , year=
-
[6]
and Sreedhar, Makesh Narsimhan and Kuchaiev, Oleksii , booktitle =
Wang, Zhilin and Dong, Yi and Delalleau, Olivier and Zeng, Jiaqi and Shen, Gerald and Egert, Daniel and Zhang, Jimmy J. and Sreedhar, Makesh Narsimhan and Kuchaiev, Oleksii , booktitle =. HelpSteer 2: Open-source dataset for training top-performing reward models , url =. doi:10.52202/079017-0047 , editor =
-
[7]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
-
[8]
International Conference on Artificial Intelligence and Statistics , pages=
A general theoretical paradigm to understand learning from human preferences , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[9]
SimPO: Simple Preference Optimization with a Reference-Free Reward , url =
Meng, Yu and Xia, Mengzhou and Chen, Danqi , booktitle =. SimPO: Simple Preference Optimization with a Reference-Free Reward , url =. doi:10.52202/079017-3946 , editor =
-
[10]
Advances in Neural Information Processing Systems , volume=
Panacea: Pareto alignment via preference adaptation for llms , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
2025 , eprint=
Mapping Post-Training Forgetting in Language Models at Scale , author=. 2025 , eprint=
2025
-
[12]
Lou, Xingzhou and Zhang, Junge and Xie, Jian and Liu, Lifeng and Yan, Dong and Huang, Kaiqi , title =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2025 ...
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Lifealign: Lifelong alignment for large language models with memory-augmented focalized preference optimization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
Fu, Yahui and Pang, Zi Haur and Kawahara, Tatsuya. Minority-Aware Satisfaction Estimation in Dialogue Systems via Preference-Adaptive Reinforcement Learning. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 2025. doi:10...
-
[15]
arXiv preprint arXiv:2503.06072 , year=
A survey on post-training of large language models , author=. arXiv preprint arXiv:2503.06072 , year=
-
[16]
International Conference on Learning Representations , volume=
Safe rlhf: Safe reinforcement learning from human feedback , author=. International Conference on Learning Representations , volume=
-
[17]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[18]
Aligning Large Language Models via Fine-grained Supervision
Xu, Dehong and Qiu, Liang and Kim, Minseok and Ladhak, Faisal and Do, Jaeyoung. Aligning Large Language Models via Fine-grained Supervision. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.acl-short.62
-
[19]
2022 , eprint=
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink , author=. 2022 , eprint=
2022
-
[20]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.