A Systematic Evaluation of Black-Box Uncertainty Estimation Methods for Large Language Models
Pith reviewed 2026-06-26 17:43 UTC · model grok-4.3
The pith
No single black-box uncertainty method for LLMs consistently outperforms the rest, though hybrid and answer-comparison approaches succeed across most tested conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
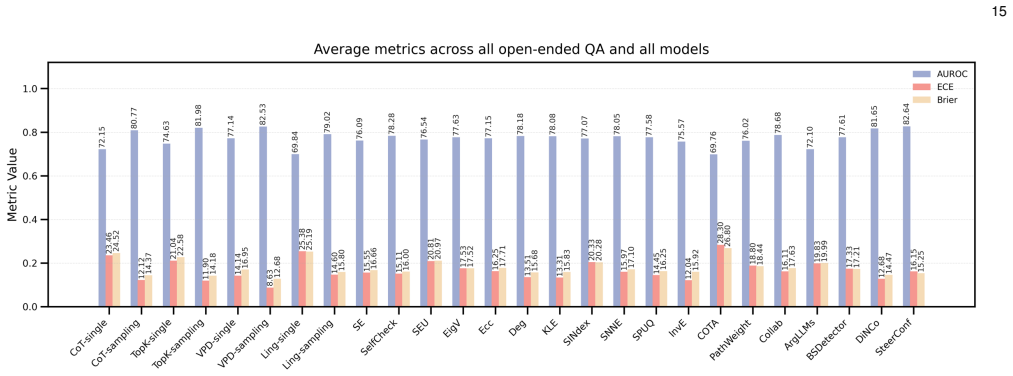
Through systematic benchmarking the authors show that methods reasoning over and comparing candidates in the answer space are generally effective, and hybrid methods that combine multiple uncertainty signals perform well under most conditions, with no single method dominating across all settings.
What carries the argument
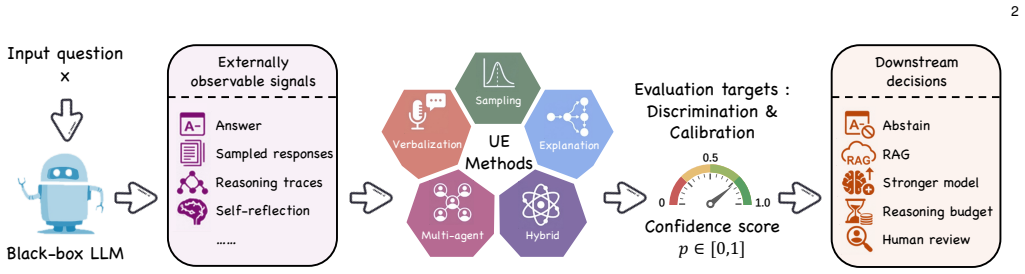
The five-category taxonomy (verbalization-based, sampling-based, explanation-based, multi-agent, hybrid) together with the unified evaluation framework that runs the 24 methods on four models and four datasets.
If this is right
- Hybrid methods that combine multiple signals can be expected to work reliably in most black-box LLM settings.
- Methods that compare candidates in the answer space provide stronger uncertainty signals than single-pass verbalization alone.
- The released benchmark data and framework allow future methods to be tested under identical conditions.
- Practical development of black-box UE methods should prioritize answer-space reasoning and signal combination over isolated approaches.
Where Pith is reading between the lines
- The observed advantage of hybrid methods may extend to uncertainty estimation in other generative models that also expose only black-box outputs.
- Thresholds derived from the better-performing categories could be integrated into production pipelines to decide when to reject or verify an LLM response.
- Running the same benchmark on newer model families would test whether the category-level patterns persist as base capabilities improve.
Load-bearing premise
The 24 chosen methods, four models, and four dataset settings represent the main approaches and typical use cases in black-box uncertainty estimation for LLMs.
What would settle it
A new black-box method that ranks first on every one of the four models and every one of the four datasets would contradict the claim that no single method dominates.
Figures
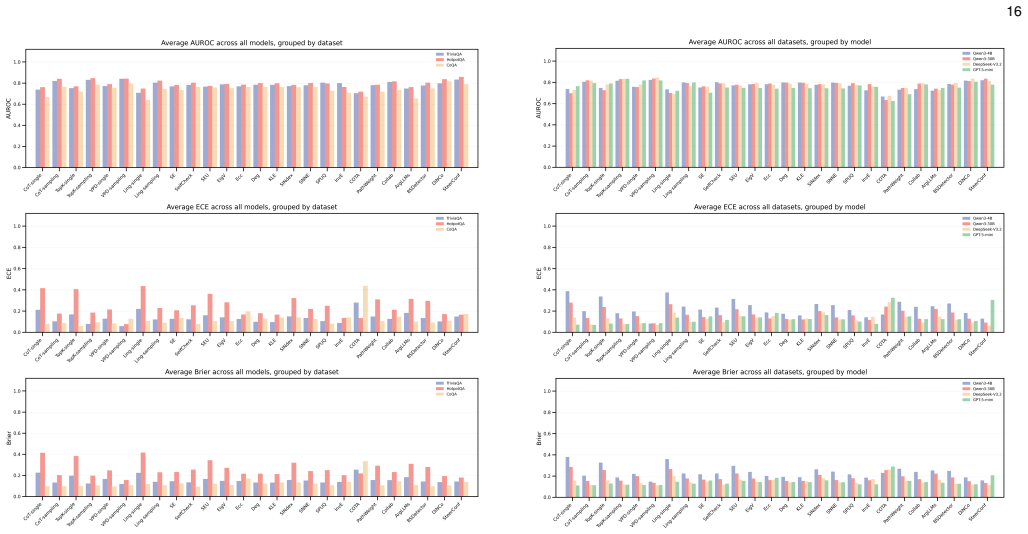
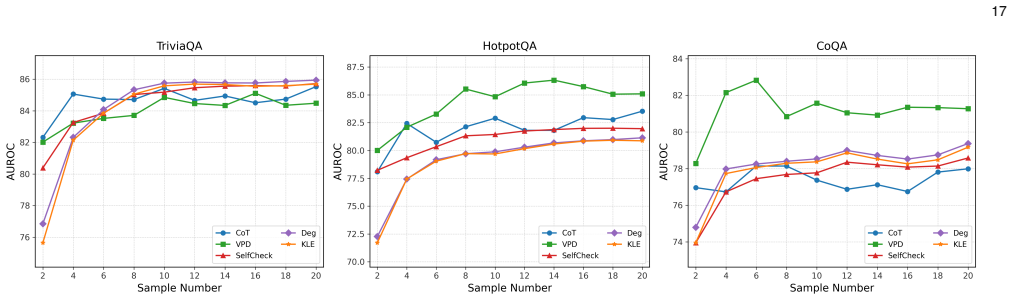
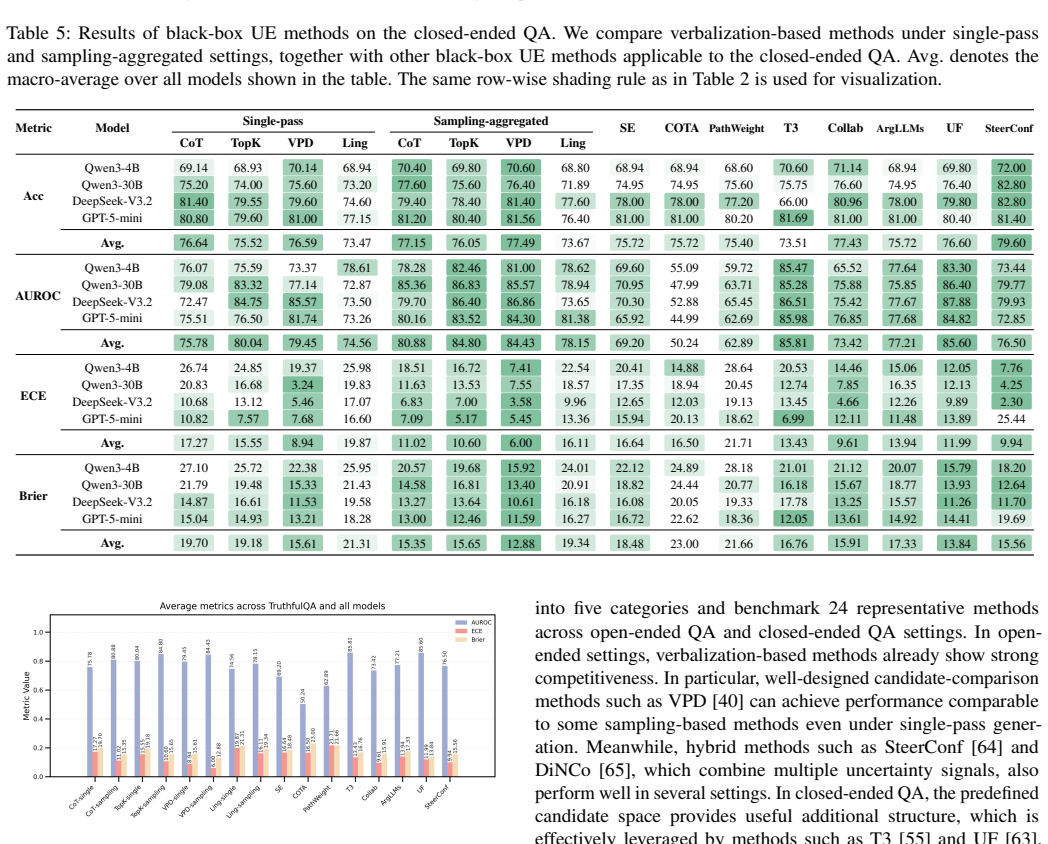
read the original abstract
Although large language models (LLMs) have shown strong capabilities across a wide range of tasks, their outputs often remain unreliable and may contain hallucinations, making uncertainty estimation (UE) essential for building trustworthy LLMs. In practice, many mainstream LLMs are only accessible through restricted APIs, where internal signals such as logits and hidden states are unavailable, making black-box UE especially important. However, existing work on black-box UE for LLMs remains fragmented in methodology and lacks a unified empirical comparison. To address this gap, we present a systematic review of black-box UE methods and organize them into five categories: verbalization-based, sampling-based, explanation-based, multi-agent, and hybrid methods. We further build a unified evaluation framework and benchmark 24 representative methods across 4 models and 4 dataset settings. Our results show that no single method consistently dominates across all settings. Nevertheless, methods that reason over and compare candidates in the answer space are generally effective, and hybrid methods that combine multiple uncertainty signals perform well under most conditions. By releasing the benchmark data and a unified evaluation framework, we aim to facilitate reproducible comparisons and support future research, while our empirical findings provide practical guidance for developing future black-box UE methods for LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic review and empirical benchmark of black-box uncertainty estimation methods for large language models. It organizes 24 methods into five categories (verbalization-based, sampling-based, explanation-based, multi-agent, and hybrid), evaluates them on 4 models and 4 datasets using a unified framework, and finds that no single method dominates but reasoning-over-candidates and hybrid methods are generally effective. The authors release the benchmark data and framework to support future research.
Significance. This work addresses fragmentation in black-box UE research for LLMs by providing a unified benchmark and practical guidance on method categories. The release of benchmark data and a reproducible evaluation framework is a clear strength that supports future comparisons. If the empirical patterns prove robust beyond the tested slice, the findings could offer actionable advice for practitioners building reliable LLM systems.
major comments (2)
- [Experimental Setup] The central generalization that 'methods that reason over and compare candidates in the answer space are generally effective' and that 'hybrid methods perform well under most conditions' is load-bearing on the representativeness of the 4 models and 4 dataset settings. The manuscript provides no explicit justification, diversity analysis, or sensitivity checks for these choices (e.g., variation in model scale, training data overlap, or task distribution), so the observed patterns could be artifacts of the narrow selection rather than stable category-level properties.
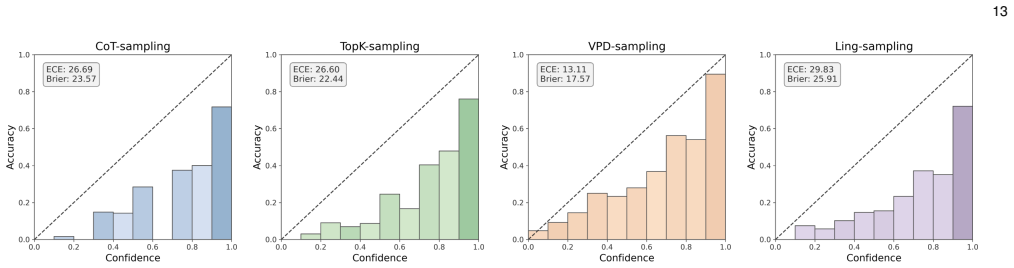
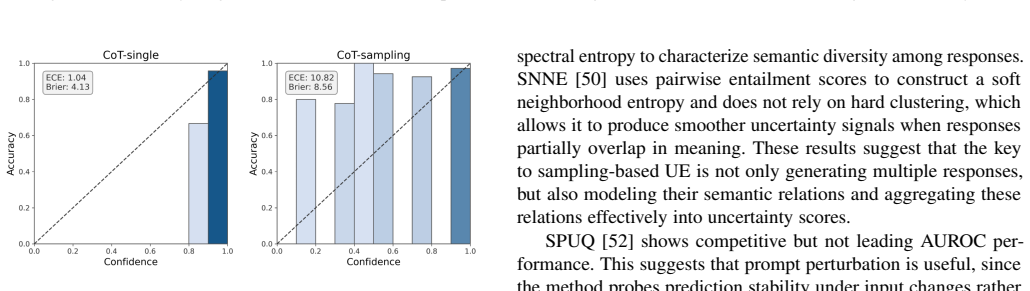
- [Evaluation Framework] The description of the 'unified evaluation framework' does not specify the concrete performance metrics (e.g., AUROC, ECE, or Brier score), number of runs, or statistical tests used to support the claim that 'no single method consistently dominates across all settings.' Without these details or controls for method-selection bias, the comparative results cannot be rigorously assessed.
minor comments (1)
- [Abstract] The abstract would benefit from briefly naming the primary metrics and the exact number of models/datasets to give readers an immediate sense of evaluation scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Experimental Setup] The central generalization that 'methods that reason over and compare candidates in the answer space are generally effective' and that 'hybrid methods perform well under most conditions' is load-bearing on the representativeness of the 4 models and 4 dataset settings. The manuscript provides no explicit justification, diversity analysis, or sensitivity checks for these choices (e.g., variation in model scale, training data overlap, or task distribution), so the observed patterns could be artifacts of the narrow selection rather than stable category-level properties.
Authors: We acknowledge the concern regarding generalizability. The four models were selected to span different scales (7B to 70B) and families (Llama, Mistral, GPT), and the datasets cover question answering, reasoning, and classification tasks with varying difficulty. In the revision we will add an explicit subsection justifying these choices with reference to prior benchmarks and include a short diversity analysis (e.g., token overlap statistics and task taxonomy). We will also add a limitations paragraph noting that broader sensitivity checks across additional models or domains remain future work, as expanding the experimental matrix would require prohibitive additional compute. The observed category-level trends are consistent within the tested slice, but we will tone down absolute claims accordingly. revision: partial
-
Referee: [Evaluation Framework] The description of the 'unified evaluation framework' does not specify the concrete performance metrics (e.g., AUROC, ECE, or Brier score), number of runs, or statistical tests used to support the claim that 'no single method consistently dominates across all settings.' Without these details or controls for method-selection bias, the comparative results cannot be rigorously assessed.
Authors: We agree that the framework description in the main text is insufficiently detailed. The concrete metrics (AUROC as primary ranking metric, ECE and Brier score for calibration), the use of five independent runs per method, and the statistical tests (paired t-tests with Bonferroni correction) are reported in Section 4.3 and Appendix B, but they are not consolidated in the framework overview. In the revision we will move these specifications into the unified evaluation framework section, explicitly state the protocol used to avoid method-selection bias (identical prompting, decoding, and evaluation pipeline for all 24 methods), and add a short paragraph on how ties and variance are handled. This will make the comparative claims fully reproducible from the main text. revision: yes
Circularity Check
Empirical benchmark paper with no derivations or self-referential reductions
full rationale
The paper conducts a literature review, organizes 24 methods into five categories, and reports direct empirical results from benchmarking them on 4 models and 4 datasets. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the derivation chain. The headline findings (no single method dominates; reasoning-over-candidates and hybrid methods perform well) are observational summaries of the experimental outcomes rather than reductions to prior assumptions or self-citations. The representativeness of the chosen models/datasets is an external validity concern, not a circularity issue per the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[4]
Chawla, Olaf Wiest, and Xiangliang Zhang
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V . Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, pages 8048–8057, 2024
2024
-
[5]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[6]
Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[7]
Large language models hallu- cination: A comprehensive survey.arXiv preprint arXiv:2510.06265, 2025
Aisha Alansari and Hamzah Luqman. Large language models hallu- cination: A comprehensive survey.arXiv preprint arXiv:2510.06265, 2025
-
[8]
Large language model influence on diagnostic reasoning: a randomized clinical trial.JAMA network open, 7(10):e2440969, 2024
Ethan Goh, Robert Gallo, Jason Hom, Eric Strong, Yingjie Weng, Hannah Kerman, Joséphine A Cool, Zahir Kanjee, Andrew S Parsons, Neera Ahuja, et al. Large language model influence on diagnostic reasoning: a randomized clinical trial.JAMA network open, 7(10):e2440969, 2024
2024
-
[9]
Large legal fictions: Profiling legal hallucinations in large language models
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E Ho. Large legal fictions: Profiling legal hallucinations in large language models. Journal of Legal Analysis, 16(1):64–93, 2024
2024
-
[10]
Satyadhar Joshi. Comprehensive review of ai hallucinations: Impacts and mitigation strategies for financial and business applications.International Journal of Computer Applications Technology and Research (IJCATR), 2025
2025
-
[11]
The Scales of Justitia: A Comprehensive Survey on Safety Evaluation of LLMs
Songyang Liu, Chaozhuo Li, Jiameng Qiu, Xi Zhang, Feiran Huang, Litian Zhang, Yiming Hei, and Philip S Yu. The scales of justitia: A comprehensive survey on safety evaluation of llms.arXiv preprint arXiv:2506.11094, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Xiaoye Wang, Nicole Xi Zhang, Hongyu He, Trang Nguyen, Kun-Hsing Yu, Hao Deng, Cynthia Brandt, Danielle S Bitterman, Ling Pan, Ching-Yu Cheng, et al. Safety challenges of ai in medicine in the era of large language models.arXiv preprint arXiv:2409.18968, 2024
-
[13]
Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
2025
-
[14]
Confrag: Confidence-guided retrieval-augmenting generation.arXiv preprint arXiv:2506.07309, 2025
Yin Huang, Yifan Ethan Xu, Kai Sun, Vera Yan, Alicia Sun, Haidar Khan, Jimmy Nguyen, Jingxiang Chen, Mohammad Kachuee, Zhaojiang Lin, et al. Confrag: Confidence-guided retrieval-augmenting generation.arXiv preprint arXiv:2506.07309, 2025
-
[15]
Leveraging uncertainty estimation for efficient LLM routing
Tuo Zhang, Asal Mehradfar, Dimitrios Dimitriadis, and Salman Aves- timehr. Leveraging uncertainty estimation for efficient LLM routing. In ICML 2025 Workshop on Collaborative and Federated Agentic Workflows, 2025
2025
-
[16]
Deep think with confidence
Yichao Fu, Xuewei Wang, Hao Zhang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[17]
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity
Xiaochen Zhu, Caiqi Zhang, Yizhou Chi, Tom Stafford, Nigel Collier, and Andreas Vlachos. Demystifying multi-agent debate: The role of confidence and diversity.arXiv preprint arXiv:2601.19921, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5050–5063, 2024
2024
-
[19]
Contextualized sequence likelihood: Enhanced confidence scores for natural language generation
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Contextualized sequence likelihood: Enhanced confidence scores for natural language generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10351–10368, 2024
2024
-
[20]
Xin Qiu and Risto Miikkulainen. Semantic density: Uncertainty quan- tification for large language models through confidence measurement in semantic space.Advances in neural information processing systems, 37:134507–134533, 2024
2024
-
[21]
Genuine: Graph enhanced multi-level uncertainty estimation for large language models
Tuo Wang, Adithya Kulkarni, Tyler Cody, Peter A Beling, Yujun Yan, and Dawei Zhou. Genuine: Graph enhanced multi-level uncertainty estimation for large language models. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 20522–20541, 2025
2025
-
[22]
INSIDE: LLMs’ internal states retain the power of hallucination detection
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. INSIDE: LLMs’ internal states retain the power of hallucination detection. InThe Twelfth International Conference on Learning Representations, 2024. 19
2024
-
[23]
Icr probe: Tracking hidden state dynamics for reliable hallucination detection in llms
Zhenliang Zhang, Xinyu Hu, Huixuan Zhang, Junzhe Zhang, and Xiaojun Wan. Icr probe: Tracking hidden state dynamics for reliable hallucination detection in llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 17986–18002, 2025
2025
-
[24]
De- tecting hallucinations in large language models using semantic entropy
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. De- tecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625–630, 2024
2024
-
[25]
Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37:8901–8929, 2024
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities.Advances in Neural Information Processing Systems, 37:8901–8929, 2024
2024
-
[26]
Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[27]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
2023
-
[28]
A survey of calibration process for black-box llms.arXiv preprint arXiv:2412.12767, 2024
Liangru Xie, Hui Liu, Jingying Zeng, Xianfeng Tang, Yan Han, Chen Luo, Jing Huang, Zhen Li, Suhang Wang, and Qi He. A survey of calibration process for black-box llms.arXiv preprint arXiv:2412.12767, 2024
-
[29]
A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.ACM Computing Surveys, 58(3):1–38, 2025
Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z Ren, and Anirudha Majumdar. A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.ACM Computing Surveys, 58(3):1–38, 2025
2025
-
[30]
Benchmarking uncertainty quantification methods for large language models with lm- polygraph.Transactions of the Association for Computational Linguistics, 13:220–248, 2025
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Daniil Vasilev, Akim Tsvigun, Sergey Petrakov, Rui Xing, Abdelrahman Sadallah, Kirill Grishchenkov, et al. Benchmarking uncertainty quantification methods for large language models with lm- polygraph.Transactions of the Association for Computational Linguistics, 13:220–248, 2025
2025
-
[31]
Uncertainty quantification and confidence calibration in large language models: A survey
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 6107– 6117, 2025
2025
-
[32]
Reconsidering llm uncertainty estimation methods in the wild
Yavuz Faruk Bakman, Duygu Nur Yaldiz, Sungmin Kang, Tuo Zhang, Baturalp Buyukates, Salman Avestimehr, and Sai Praneeth Karimireddy. Reconsidering llm uncertainty estimation methods in the wild. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29531–29556, 2025
2025
-
[33]
Uncertainty quantification for language models: A suite of black-box, white-box, LLM judge, and ensemble scorers.Transactions on Machine Learning Research, 2025
Dylan Bouchard and Mohit Singh Chauhan. Uncertainty quantification for language models: A suite of black-box, white-box, LLM judge, and ensemble scorers.Transactions on Machine Learning Research, 2025
2025
-
[34]
A survey of uncertainty estimation methods on large language models
Zhiqiu Xia, Jinxuan Xu, Yuqian Zhang, and Hang Liu. A survey of uncertainty estimation methods on large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 21381– 21396, 2025
2025
-
[35]
Ruiyang Zhang, Hu Zhang, Hao Fei, and Zhedong Zheng. Uncertainty- o: One model-agnostic framework for unveiling uncertainty in large multimodal models.arXiv preprint arXiv:2506.07575, 2025
-
[36]
Gregory Kang Ruey Lau, Hieu Dao, Nicole Kan Hui Lin, and Bryan Kian Hsiang Low. Uncertainty quantification for multimodal large language models with incoherence-adjusted semantic volume.arXiv preprint arXiv:2602.24195, 2026
-
[37]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucina- tion in large vision-language models.arXiv preprint arXiv:2402.00253, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
A survey on learning to reject.Proceedings of the IEEE, 111(2):185–215, 2023
Xu-Yao Zhang, Guo-Sen Xie, Xiuli Li, Tao Mei, and Cheng-Lin Liu. A survey on learning to reject.Proceedings of the IEEE, 111(2):185–215, 2023
2023
-
[40]
Ante Wang, Weizhi Ma, and Yang Liu. Don’t miss the forest for the trees: In-depth confidence estimation for llms via reasoning over the answer space.arXiv preprint arXiv:2511.14275, 2025
-
[41]
Jiayu Liu, Qing Zong, Weiqi Wang, and Yangqiu Song. Revisiting epistemic markers in confidence estimation: Can markers accurately reflect large language models’ uncertainty? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 206–221, 2025
2025
-
[42]
Selfcheckgpt: Zero- resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero- resource black-box hallucination detection for generative large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, 2023
2023
-
[43]
Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research, 2024
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research, 2024
2024
-
[44]
Luq: Long-text uncertainty quantification for llms
Caiqi Zhang, Fangyu Liu, Marco Basaldella, and Nigel Collier. Luq: Long-text uncertainty quantification for llms. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5244–5262, 2024
2024
-
[45]
Graph-based uncertainty metrics for long-form language model generations.Advances in Neural Information Processing Systems, 37:32980–33006, 2024
Mingjian Jiang, Yangjun Ruan, Prasanna Sattigeri, Salim Roukos, and Tatsunori Hashimoto. Graph-based uncertainty metrics for long-form language model generations.Advances in Neural Information Processing Systems, 37:32980–33006, 2024
2024
-
[46]
Improving uncer- tainty quantification in large language models via semantic embeddings
Yashvir S Grewal, Edwin V Bonilla, and Thang D Bui. Improving uncer- tainty quantification in large language models via semantic embeddings. arXiv preprint arXiv:2410.22685, 2024
-
[47]
Tiejin Chen, Xiaoou Liu, Longchao Da, Jia Chen, Vagelis Papalexakis, and Hua Wei. Uncertainty quantification of large language models through multi-dimensional responses.arXiv preprint arXiv:2502.16820, 2025
-
[48]
Uncertainty quantification in large language models through convex hull analysis.Discover Artificial Intelligence, 4(1):90, 2024
Ferhat Ozgur Catak and Murat Kuzlu. Uncertainty quantification in large language models through convex hull analysis.Discover Artificial Intelligence, 4(1):90, 2024
2024
-
[49]
Samir Abdaljalil, Hasan Kurban, Parichit Sharma, Erchin Serpedin, and Rachad Atat. Sindex: Semantic inconsistency index for hallucination detection in llms.arXiv preprint arXiv:2503.05980, 2025
-
[50]
Beyond semantic entropy: Boosting llm uncertainty quantification with pairwise semantic similarity
Dang Nguyen, Ali Payani, and Baharan Mirzasoleiman. Beyond semantic entropy: Boosting llm uncertainty quantification with pairwise semantic similarity. InFindings of the Association for Computational Linguistics: ACL 2025, pages 4530–4540, 2025
2025
-
[51]
Xingtao Zhao, Hao Peng, Dingli Su, Xianghua Zeng, Chunyang Liu, Jinzhi Liao, and Philip S. Yu. Sese: A structural information-guided uncertainty quantification framework for hallucination detection in llms. arXiv preprint arXiv:2511.16275, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Spuq: Perturbation-based uncertainty quantification for large language models
Xiang Gao, Jiaxin Zhang, Lalla Mouatadid, and Kamalika Das. Spuq: Perturbation-based uncertainty quantification for large language models. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2336–2346, 2024
2024
-
[53]
Inv- entropy: A fully probabilistic framework for uncertainty quantification in language models
Haoyi Song, Ruihan Ji, Naichen Shi, Fan Lai, and Raed Al Kontar. Inv- entropy: A fully probabilistic framework for uncertainty quantification in language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[54]
Quantifying uncertainty in natural language explanations of large language models
Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. Quantifying uncertainty in natural language explanations of large language models. InInternational Conference on Artificial Intelligence and Statistics, pages 1072–1080. PMLR, 2024
2024
-
[55]
Think twice before trusting: Self-detection for large language models through comprehensive answer reflection
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, and Tat-Seng Chua. Think twice before trusting: Self-detection for large language models through comprehensive answer reflection. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 11858–11875, 2024
2024
-
[56]
Understanding the uncertainty of LLM explanations: A perspective based on reasoning topology
Longchao Da, Xiaoou Liu, Jiaxin Dai, Lu Cheng, Yaqing Wang, and Hua Wei. Understanding the uncertainty of LLM explanations: A perspective based on reasoning topology. InSecond Conference on Language Modeling, 2025
2025
-
[57]
Reasoning about uncertainty: Do reasoning models know when they don’t know? InFindings of the Association for Computational Linguistics: EACL 2026, pages 3408–3458, 2026
Zhiting Mei, Christina Zhang, Tenny Yin, Justin Lidard, Ola Sho, and Anirudha Majumdar. Reasoning about uncertainty: Do reasoning models know when they don’t know? InFindings of the Association for Computational Linguistics: EACL 2026, pages 3408–3458, 2026
2026
-
[58]
All roads lead to rome: Graph-based confidence estimation for large language model reasoning
Caiqi Zhang, Chang Shu, Ehsan Shareghi, and Nigel Collier. All roads lead to rome: Graph-based confidence estimation for large language model reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31802–31812, 2025
2025
-
[59]
Confidence calibration and rationalization for LLMs via multi-agent deliberation
Ruixin Yang, Dheeraj Rajagopal, Shirley Anugrah Hayati, Bin Hu, and Dongyeop Kang. Confidence calibration and rationalization for LLMs via multi-agent deliberation. InICLR 2024 Workshop on Reliable and Responsible Foundation Models, 2024
2024
-
[60]
Argumentative large language models for explainable and contestable claim verification
Gabriel Freedman, Adam Dejl, Deniz Gorur, Xiang Yin, Antonio Rago, and Francesca Toni. Argumentative large language models for explainable and contestable claim verification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14930–14939, 2025
2025
-
[61]
Rethinking LLM uncertainty: A multi-agent approach to estimating black- 20 box model uncertainty
Yu Feng, Phu Mon Htut, Zheng Qi, Wei Xiao, Manuel Mager, Nikolaos Pappas, Kishaloy Halder, Yang Li, Yassine Benajiba, and Dan Roth. Rethinking LLM uncertainty: A multi-agent approach to estimating black- 20 box model uncertainty. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 12349–12375, 2025
2025
-
[62]
Quantifying uncertainty in answers from any language model and enhancing their trustworthiness
Jiuhai Chen and Jonas Mueller. Quantifying uncertainty in answers from any language model and enhancing their trustworthiness. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5186–5200, 2024
2024
-
[63]
Calibrating the confidence of large language models by eliciting fidelity
Mozhi Zhang, Mianqiu Huang, Rundong Shi, Linsen Guo, Chong Peng, Peng Yan, Yaqian Zhou, and Xipeng Qiu. Calibrating the confidence of large language models by eliciting fidelity. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2959–2979, 2024
2024
-
[64]
Steerconf: Steering llms for confidence elicitation.arXiv preprint arXiv:2503.02863, 2025
Ziang Zhou, Tianyuan Jin, Jieming Shi, and Qing Li. Steerconf: Steering llms for confidence elicitation.arXiv preprint arXiv:2503.02863, 2025
-
[65]
Calibrating verbalized confidence with self-generated distractors
Victor Wang and Elias Stengel-Eskin. Calibrating verbalized confidence with self-generated distractors. InThe Fourteenth International Confer- ence on Learning Representations, 2026
2026
-
[66]
Gal Yona, Roee Aharoni, and Mor Geva. Can large language models faithfully express their intrinsic uncertainty in words? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7752–7764, 2024
2024
-
[67]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining, page 226–231, 1996
1996
-
[68]
Calibrating large language models using their generations only
Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Oh. Calibrating large language models using their generations only. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15440–15459, 2024
2024
-
[69]
Graph-based confidence calibration for large language models.Transactions on Machine Learning Research, 2025
Yukun Li, Sijia Wang, Lifu Huang, and Liping Liu. Graph-based confidence calibration for large language models.Transactions on Machine Learning Research, 2025
2025
-
[70]
Simple yet effective: An information- theoretic approach to multi-llm uncertainty quantification
Maya Kruse, Majid Afshar, Saksham Khatwani, Anoop Mayampurath, Guanhua Chen, and Yanjun Gao. Simple yet effective: An information- theoretic approach to multi-llm uncertainty quantification. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30481–30492, 2025
2025
-
[71]
Verify when Uncertain: Beyond Self-Consistency in Black Box Hallucination Detection
Yihao Xue, Kristjan Greenewald, Youssef Mroueh, and Baharan Mirza- soleiman. Verify when uncertain: Beyond self-consistency in black box hallucination detection.arXiv preprint arXiv:2502.15845, 2025
work page internal anchor Pith review arXiv 2025
-
[72]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
2017
-
[73]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018
2018
-
[74]
Coqa: A conversa- tional question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversa- tional question answering challenge.Transactions of the Association for Computational Linguistics, 7:249–266, 2019
2019
-
[75]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, 2022
2022
-
[76]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[77]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai GPT-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
The use of the area under the roc curve in the evaluation of machine learning algorithms.Pattern recognition, 30(7):1145–1159, 1997
Andrew P Bradley. The use of the area under the roc curve in the evaluation of machine learning algorithms.Pattern recognition, 30(7):1145–1159, 1997
1997
-
[80]
Obtain- ing well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtain- ing well calibrated probabilities using bayesian binning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 29, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.