Global Convergence of Gradient Descent for Score Matching in Gaussian Mixtures via Reverse Fisher Divergence
Pith reviewed 2026-06-26 17:57 UTC · model grok-4.3
The pith
Gradient descent on the reverse Fisher divergence converges globally for score matching when fitting Gaussian mixtures to a single Gaussian target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the teacher distribution is a single Gaussian and the student is a Gaussian mixture model with fixed weights and identity covariances, gradient descent on the reverse Fisher divergence converges globally from arbitrary initializations. When the teacher is also a Gaussian mixture model, the same objective yields global convergence guarantees under a global random initialization scheme and a separation assumption on the target means; with high probability each student component converges near its closest teacher component, and conditions are given under which the student distribution converges in total variation distance. The proofs rely on a Lyapunov-based analysis of the gradient descen
What carries the argument
The reverse Fisher divergence, the expectation with respect to the student distribution of the squared difference between the score functions of the student and teacher.
If this is right
- Gradient descent reaches the global minimum of the reverse Fisher divergence from any initialization in the single-Gaussian-teacher case.
- Under the separation assumption each student component converges to a neighborhood of its nearest teacher component.
- The student and teacher distributions converge in total variation distance once the component-wise convergence and separation conditions hold.
- The reverse objective produces a landscape free of the initialization-dependent spurious stationary points that appear under the forward objective.
Where Pith is reading between the lines
- The same Lyapunov argument might be adaptable to score matching for other location-scale families beyond Gaussians.
- Practical training of diffusion models could benefit from replacing the usual forward objective with its reverse counterpart to reduce sensitivity to random seeds.
- The separation assumption suggests that the method is most reliable when the target mixture components are well-separated, which could be tested by varying the mean spacing in synthetic experiments.
Load-bearing premise
The student must use fixed mixture weights and identity covariance matrices when the teacher is a single Gaussian.
What would settle it
A numerical run in which gradient descent on the reverse Fisher divergence fails to reach the target mixture from some arbitrary initialization, with the teacher a single Gaussian and the student using fixed weights and identity covariances, would falsify the global-convergence claim.
Figures
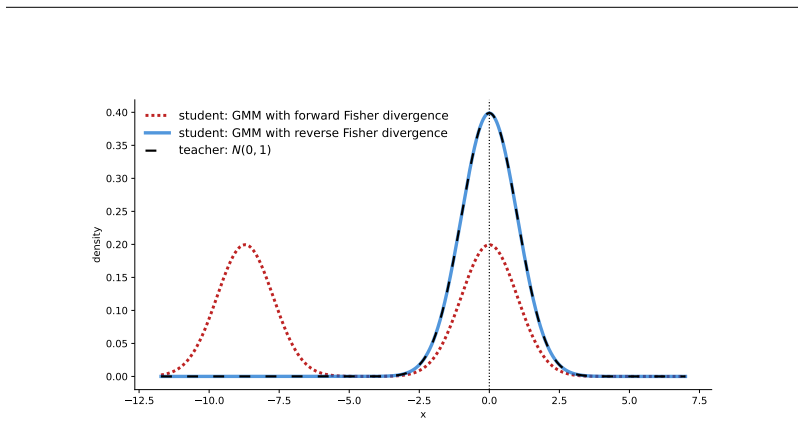
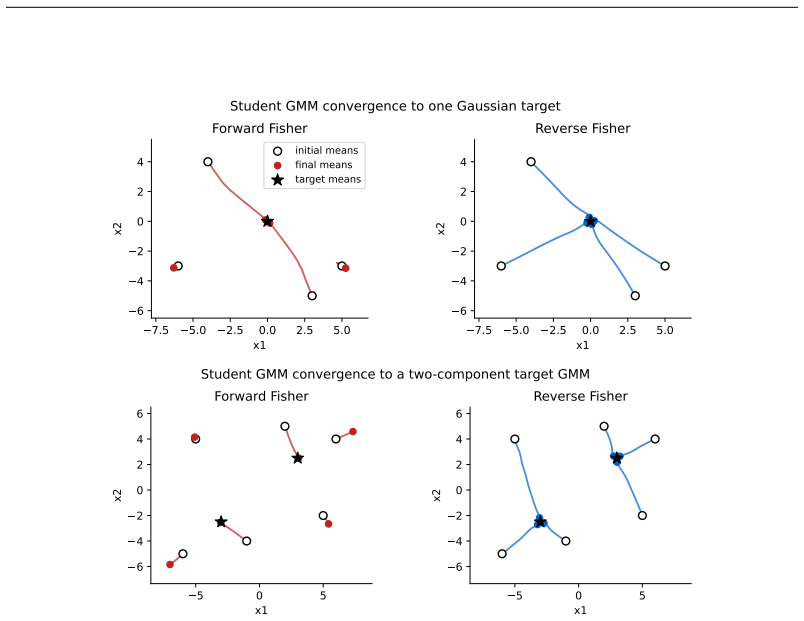
read the original abstract
The score matching problem is a central training objective in modern generative modeling, diffusion models, fitting unnormalized statistical models, and inverse problems. A standard approach is to minimize the forward Fisher divergence, where the expectation is taken with respect to the teacher distribution. However, recent results show that even in simple Gaussian mixture model settings, this objective can lead to undesirable and initialization-dependent convergence behavior. In this paper, we study an alternative objective: the reverse Fisher divergence, where the expectation is taken with respect to the student distribution. We analyze gradient descent (GD) for fitting Gaussian mixture models and show that this change in the objective leads to significantly better optimization properties. First, when the teacher distribution is a single Gaussian and the student is a Gaussian mixture model with fixed weights and identity covariances, we prove the global convergence of GD from arbitrary initializations. Second, we extend the analysis to the case where the teacher is also a Gaussian mixture model and prove global convergence guarantees under a global random initialization scheme and a $\widetilde{\Omega}(1)$-separation assumption on the target means. In particular, with high probability, each student component converges near its closest teacher component, and we provide conditions under which the student distribution converges in total variation distance. Our proofs rely on a new Lyapunov-based analysis of the gradient descent dynamics, showing that the reverse Fisher divergence has a much more favorable optimization landscape than the forward Fisher divergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that replacing the forward Fisher divergence with the reverse Fisher divergence as the score-matching objective yields significantly better optimization properties for gradient descent on Gaussian mixture models. When the teacher is a single Gaussian and the student is a GMM with fixed weights and identity covariances, global convergence holds from arbitrary initializations. When the teacher is also a GMM, global convergence is proved under a global random initialization scheme and a Ω̃(1)-separation assumption on the target means; with high probability each student component converges near its closest teacher component, and conditions are given under which the student converges to the teacher in total variation. All claims rest on a new Lyapunov analysis of the gradient-flow dynamics.
Significance. If the stated results hold, the work supplies the first global-convergence guarantees for score matching on GMMs under the reverse objective and directly addresses known initialization-dependent failures of the forward objective. The explicit conditioning on fixed student weights/identity covariances (single-Gaussian case) and on separation plus random initialization (GMM case) keeps the claims proportionate. The Lyapunov technique itself is a methodological contribution that may extend to other unnormalized models.
minor comments (2)
- [Abstract] Abstract, line on Ω̃(1)-separation: the precise meaning of the tilde and the dependence on dimension or number of components should be stated explicitly in the main text (e.g., §2 or §3) so that the assumption can be checked against standard GMM separation results.
- The manuscript repeatedly refers to 'global random initialization scheme' without giving the precise distribution or variance scaling in the main body; a short paragraph or remark after the statement of Theorem X would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity; proofs are self-contained mathematical analysis
full rationale
The paper's central claims consist of explicit mathematical proofs of global convergence for gradient descent on the reverse Fisher divergence objective, conditioned on stated assumptions (fixed student weights/identity covariances for the single-Gaussian case; separation and random initialization for the GMM case). These are derived via a new Lyapunov-based analysis of the dynamics, without any reduction of the target results to fitted parameters from the same data, self-definitional loops, or load-bearing self-citations. The derivation chain is independent of the evaluation quantities and does not rename or smuggle in prior results by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ω̃(1)-separation of target means together with global random initialization
- domain assumption Student model uses fixed mixture weights and identity covariances
Reference graph
Works this paper leans on
-
[1]
Nearlyd-linear con- vergence bounds for diffusion models via stochastic localization
Joe Benton, Valentin De Bortoli, Arnaud Doucet, and George Deligiannidis. Nearlyd-linear con- vergence bounds for diffusion models via stochastic localization. InInternational Conference on Learning Representations, volume 2024, pp. 36916–36936,
2024
-
[2]
Diana Cai, Chirag Modi, Charles C Margossian, Robert M Gower, David M Blei, and Lawrence K Saul. Eigenvi: score-based variational inference with orthogonal function expansions.Advances in Neural Information Processing Systems, 37:132691–132721, 2024a. Diana Cai, Chirag Modi, Loucas Pillaud-Vivien, Charles Margossian, Robert M Gower, David Blei, and Lawren...
-
[3]
Learning general gaussian mixtures with efficient score matching.arXiv preprint arXiv:2404.18893,
Sitan Chen, Vasilis Kontonis, and Kulin Shah. Learning general gaussian mixtures with efficient score matching.arXiv preprint arXiv:2404.18893,
-
[4]
Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687,
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687,
-
[5]
Luc Devroye, Abbas Mehrabian, and Tommy Reddad. The total variation distance between high- dimensional gaussians with the same mean.arXiv preprint arXiv:1810.08693,
-
[6]
Learning mixtures of gaussians using diffu- sion models.arXiv preprint arXiv:2404.18869,
Khashayar Gatmiry, Jonathan Kelner, and Holden Lee. Learning mixtures of gaussians using diffu- sion models.arXiv preprint arXiv:2404.18869,
-
[7]
Faster diffusion sampling with randomized midpoints: Sequential and parallel
10 Shivam Gupta, Linda Cai, and Sitan Chen. Faster diffusion sampling with randomized midpoints: Sequential and parallel. InInternational Conference on Learning Representations, volume 2025, pp. 97663–97698,
2025
-
[8]
Neural network-based score estimation in diffusion models: Optimization and generalization
Yinbin Han, Meisam Razaviyayn, and Renyuan Xu. Neural network-based score estimation in diffusion models: Optimization and generalization. InInternational Conference on Learning Representations, volume 2024, pp. 42520–42558,
2024
-
[9]
Adam: A Method for Stochastic Optimization
doi: 10.1137/S0040585X97981846. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1137/s0040585x97981846
-
[10]
Frederic Koehler, Alexander Heckett, and Andrej Risteski. Statistical efficiency of score matching: The view from isoperimetry.arXiv preprint arXiv:2210.00726,
-
[11]
Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761,
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761,
Pith/arXiv arXiv 2009
-
[12]
A unified view of score-based and drifting models.arXiv preprint arXiv:2603.07514,
Chieh-Hsin Lai, Bac Nguyen, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yuki Mitsufuji, Stefano Ermon, and Molei Tao. A unified view of score-based and drifting models.arXiv preprint arXiv:2603.07514,
-
[13]
On the generalization properties of diffusion models.Advances in Neural Information Processing Systems, 36:2097–2127,
Puheng Li, Zhong Li, Huishuai Zhang, and Jiang Bian. On the generalization properties of diffusion models.Advances in Neural Information Processing Systems, 36:2097–2127,
2097
-
[14]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
-
[15]
Variational approximations using fisher divergence
Yue Yang, Ryan Martin, and Howard Bondell. Variational approximations using fisher divergence. arXiv preprint arXiv:1905.05284,
Pith/arXiv arXiv 1905
-
[16]
Mo Zhou, Weihang Xu, Maryam Fazel, and Simon S Du. Global convergence of gradient em for over-parameterized gaussian mixtures.arXiv preprint arXiv:2506.06584,
-
[17]
2 1.2 Motivation and contributions
12 CONTENTS 1 Introduction 1 1.1 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.2 Motivation and contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.3 Preliminaries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2 Learning Single Gaussian Component 4 2.1 Discu...
2007
-
[18]
Otherwise, consider the case b−¯µa∗ j ≥ δmin 4 .LetA={x∈R d :x= ¯µ a∗ j +α(µ 0 i −¯µa∗ j ) + β(¯µa∗ i −¯µa∗ j ), α, β∈R}be the affine space. Notice that if b−¯µa∗ j ≥ δmin 4 andb∈[µ 0 j ,¯µa∗ j ], then b= ¯µa∗ j +t(µ 0 j −¯µa∗ j ) for somet≥ δmin 4 µ0 j −¯µa∗ j ≥ δmin 8R0 .We get P2 ≤P ∪t∈[δmin/8R0,1]dist(A,¯µa∗ j +t(µ 0 j −¯µa∗ j ))<∆ 3 =P ∪t∈[δmin/8R0,1...
2006
-
[19]
18 Lemma B.5.Letρ∈(0,1]andµ 0 ℓ =R 0ηℓ/∥η ℓ∥, whereR 0 >0andη ℓ ∼ N(0,I d)for allℓ∈[n], independently
Hence, P(Ω 3)≥1−ρ. 18 Lemma B.5.Letρ∈(0,1]andµ 0 ℓ =R 0ηℓ/∥η ℓ∥, whereR 0 >0andη ℓ ∼ N(0,I d)for allℓ∈[n], independently. Let Ωfull 4 := µ0 1 ⊤ ... µ0 n ⊤ op ≤∆ 4 . Then choosing ∆4 =R 0 vuut n d + max ( 4 3 log 2d ρ , s 4n d log 2d ρ ) guarantees that P Ωfull 4 ≥1−ρ. Proof.Without loss of generality, we assume thatR 0 = 1....
2019
-
[20]
X i∈Ia rk,a i (x) µk i −¯µa 2 # −E x∼pk,a µ h mk a(x)−¯µa 2i!2 49 =n aEx∼pk,a µ h mk a(x)−¯µa 2i +κ a 1 na Zk a 2 F −E x∼pk,a µ h mk a(x)−¯µa 2i 2 since Ex∼pk,a µ
Using (25), (27), and (37), µ ¯K ℓ −¯µa∗ ℓ ≤ 1− 2γ n ¯K µ0 ℓ −¯µa∗ ℓ + E ¯K−1 ℓ ≤ 8 √ ¯∆ R0 µ0 ℓ −¯µa∗ ℓ +E 1 ≤16 p ¯∆ +E 1 because µ0 ℓ =R 0 and ¯µa∗ ℓ ≤R 0.Due to (33) and (32), µ ¯K ℓ −¯µa∗ ℓ ≤16 p ¯∆ +E 1 ≤17 p ¯∆(38) for allℓ∈[n].LetI a ={i a,1, . . . , ia,na }.The inequality ensures that after ¯Ksteps, each component converges to a small-¯∆neighborh...
1987
-
[21]
For orthogonal equal-norm modes, write¯µa =re a in some orthonormal basis
By Theorem 3.3, this gives TV(pµk ,¯p)≤ √ε. For orthogonal equal-norm modes, write¯µa =re a in some orthonormal basis. Then a∗(η) = arg min a∈[m] R0η−¯µa 2 = arg max a∈[m] ⟨η,¯µa⟩= arg max a∈[m] ηa, whereη∼Unif(S d−1). The coordinatesη 1, . . . , ηm are exchangeable. Thus pa =P(a ∗(η) =a) = 1 m for alla∈[m]. F PROOF OFTHEOREMF.1 Theorem F .1(Lower bound)....
2048
-
[22]
The base case holds due to µ0 1,i =R 0 and (65). Similarly to the proof of Theorem E.1, we get µk+1 1,i = ¯µ1 + 1− 2γ nmin k+1 (µ0 1,i −¯µ1)−E k 1,i,(68) where Ek 1,ℓ := 2γ nmin kX j=0 1− 2γ nmin k−j Ex∼N(µ j 1,ℓ,I) h ¯E j 1,ℓ(x) i , and ¯E k 1,ℓ(x) :=m µk 1 (x)−µ k 1,ℓ +C µk 1 (x) µk 1,ℓ −m µk 1 (x) . 53 Let us definer k 1,i(x) := exp(− 1 2 ∥x−µk 1,i∥2)P...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.