Co-policy: Responsive Human-Robot Co-Creation for Musical Performances
Pith reviewed 2026-06-26 17:06 UTC · model grok-4.3
The pith
Co-policy separates semantic planning via F-Qwen from visuomotor execution via GMP to let robots generate complementary musical responses under constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
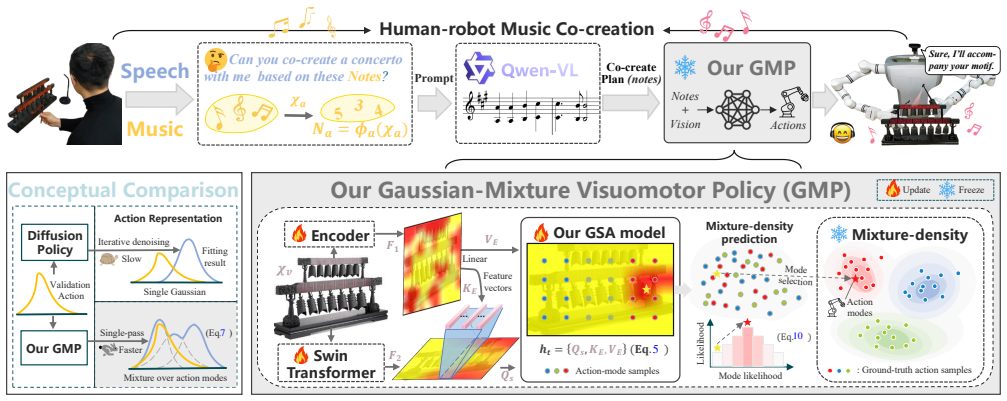
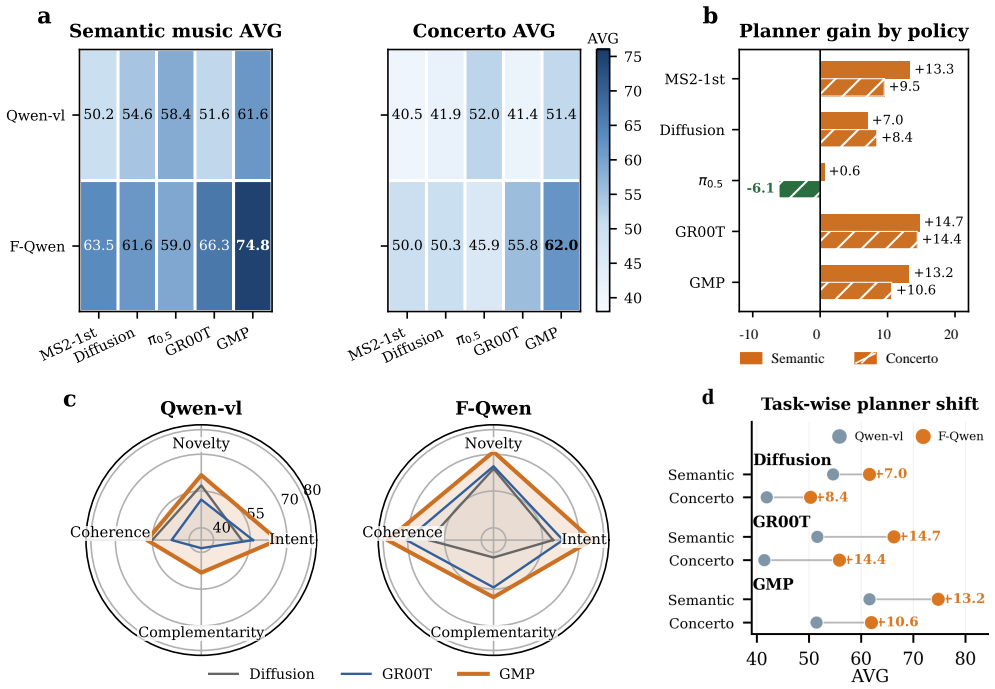
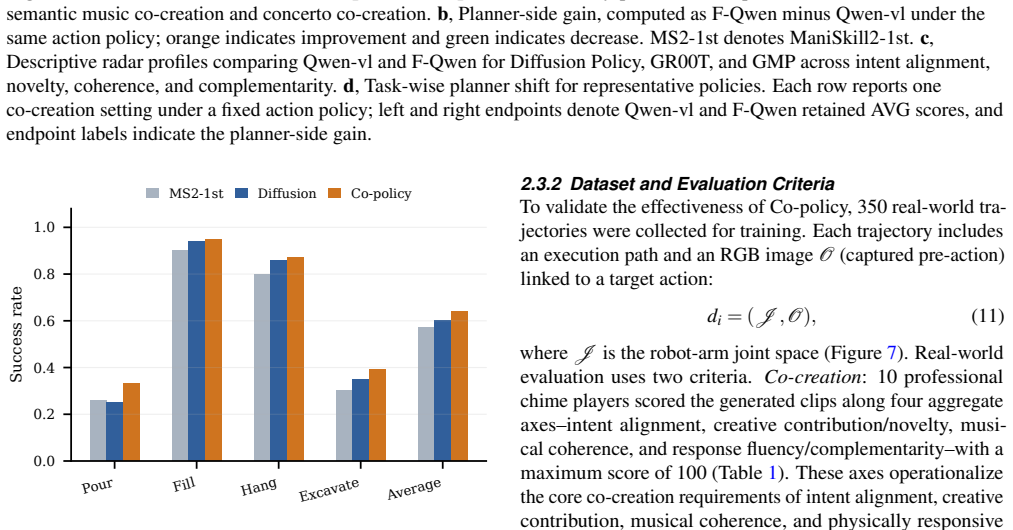
Co-policy uses pre-inference semantic anchors and a fine-tuned Qwen-vl planner (F-Qwen) to convert speech, musical seeds, and visual observations into structured co-creation plans, then employs a Gaussian-Mixture Visuomotor Policy (GMP) that maps target notes and visual context to multimodal robot actions in one forward pass, generating complementary responses under musical and physical constraints, as demonstrated by higher intent alignment, execution accuracy, and response frequency in real-robot chime experiments compared with diffusion-policy baselines.
What carries the argument
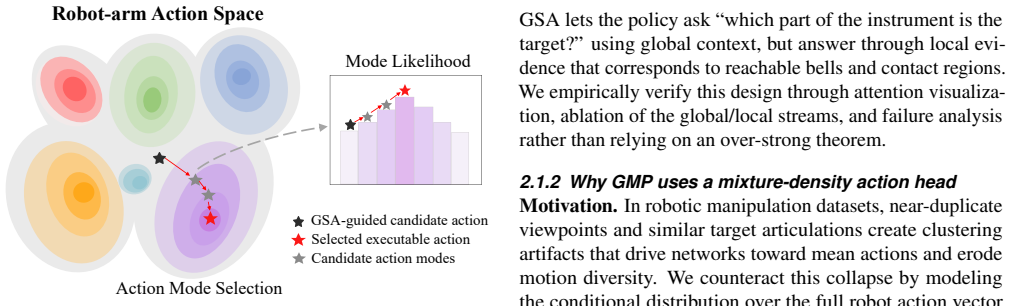
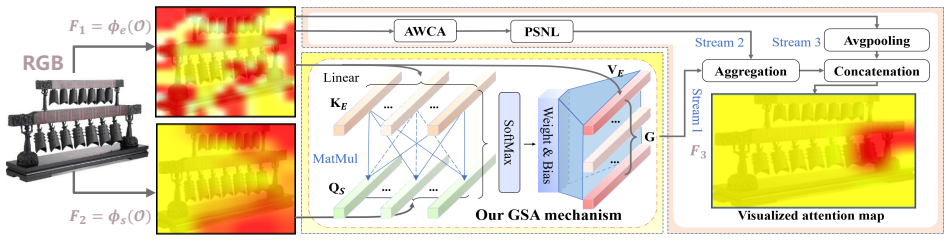
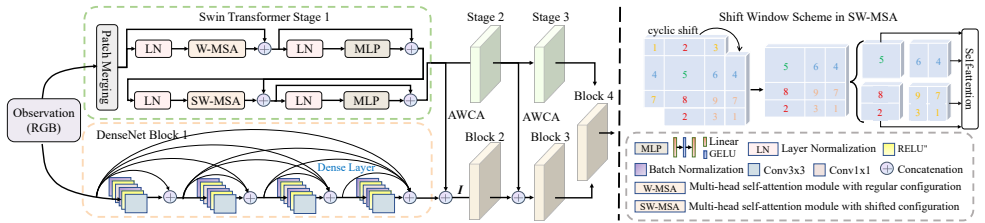
Gaussian-Mixture Visuomotor Policy (GMP), a conditional mixture-density policy that produces multimodal robot actions from planned notes and visual context in a single forward pass.
If this is right
- Robots can produce responses that align with human musical intent while remaining physically executable.
- Single-forward-pass GMP execution yields higher response frequency and accuracy than diffusion-policy alternatives.
- Structured plans derived from multimodal inputs enforce both musical and physical constraints simultaneously.
- Ablation results indicate that removing either the semantic anchors or the mixture model degrades performance.
Where Pith is reading between the lines
- The planning-execution split may extend to other real-time embodied creative tasks such as dance or drawing co-creation.
- Testing the framework on longer multi-turn performances could reveal whether coherence holds across extended sessions.
- Adding further sensor streams would likely preserve low latency given the single-pass design of GMP.
Load-bearing premise
Pre-inference semantic anchors together with the fine-tuned F-Qwen planner can reliably turn speech, live musical seeds, and visual observations into structured plans that the GMP executes at low latency while keeping musical coherence and physical feasibility.
What would settle it
A set of real-robot trials in which the generated actions frequently mismatch planned notes, exceed physical joint limits, or receive low expert ratings on musical intent alignment would falsify the claim that the two-stage system reliably produces complementary responses.
Figures





read the original abstract
Art has long stood as a pivotal expression of human creativity. Embodied artificial intelligence offers a route for generative models to participate in that creativity through physical action rather than disembodied digital content. In robotic music co-creation, it is challenging to connect semantic musical understanding with real-time and physically executable performance. We present Co-policy, a framework for human-robot musical co-creation that separates semantic intent grounding, constrained musical variation, and visuomotor execution. To ground musical semantics, Co-policy uses pre-inference semantic anchors and a fine-tuned Qwen-vl planner (F-Qwen) to transform speech, live musical seeds, and visual observations into structured co-creation plans. To support low-latency execution, Co-policy introduces a Gaussian-Mixture Visuomotor Policy (GMP), implemented as a conditional mixture-density policy that maps target notes and visual context to multimodal robot actions in a single forward pass. Unlike robotic playback systems that merely reproduce user-specified notes, Co-policy generates complementary musical responses under both musical and physical constraints. Real-robot chime experiments, ablations, and expert evaluation show improved intent alignment, execution accuracy, and response frequency over diffusion-policy and ablated baselines, supporting physically grounded action generation as a key requirement for embodied human-AI co-creation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Co-policy, a framework for human-robot musical co-creation that separates semantic intent grounding (via pre-inference semantic anchors and a fine-tuned Qwen-vl planner called F-Qwen) from constrained musical variation and visuomotor execution (via a Gaussian-Mixture Visuomotor Policy or GMP). The GMP is implemented as a conditional mixture-density policy mapping target notes and visual context to multimodal robot actions in one forward pass. Unlike playback systems, it generates complementary responses under musical and physical constraints. Real-robot chime experiments, ablations, and expert evaluation are claimed to show gains in intent alignment, execution accuracy, and response frequency versus diffusion-policy and ablated baselines.
Significance. If the empirical results hold with proper quantification, the work would contribute to embodied AI and human-robot interaction by demonstrating a practical modular architecture for real-time semantic-to-physical mapping in creative performance. The separation of high-level planning from low-latency visuomotor control, the use of mixture-density networks for multimodal actions, and the focus on real-robot validation (rather than simulation) are positive elements. The emphasis on physical feasibility alongside musical coherence addresses a key requirement for embodied co-creation systems.
major comments (2)
- [Abstract] Abstract: The central empirical claim rests on 'real-robot chime experiments, ablations, and expert evaluation' showing 'improved intent alignment, execution accuracy, and response frequency,' yet the text supplies no quantitative metrics, tables of results, statistical tests, dataset sizes, or error analysis. This absence is load-bearing for assessing whether the data support the stated improvements over diffusion-policy baselines.
- [Methods] Methods/Implementation: The description of how pre-inference semantic anchors are constructed and how the fine-tuned F-Qwen planner converts speech, live musical seeds, and visual observations into structured plans lacks detail on training data, fine-tuning procedure, or latency measurements; without these, it is difficult to verify the claim that the planner reliably produces plans executable at low latency by the GMP while preserving coherence.
minor comments (2)
- [Abstract] Abstract: 'F-Qwen' is introduced as 'fine-tuned Qwen-vl planner (F-Qwen)' but the expansion should appear at first use for readability.
- [Abstract] Abstract: The full expansion 'Gaussian-Mixture Visuomotor Policy (GMP)' is given, but the acronym could be introduced in the sentence describing the policy for consistency with standard notation practice.
Simulated Author's Rebuttal
Thank you for the constructive review. We agree that the current manuscript lacks sufficient quantitative metrics and methodological details to support the claims. We will make major revisions to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim rests on 'real-robot chime experiments, ablations, and expert evaluation' showing 'improved intent alignment, execution accuracy, and response frequency,' yet the text supplies no quantitative metrics, tables of results, statistical tests, dataset sizes, or error analysis. This absence is load-bearing for assessing whether the data support the stated improvements over diffusion-policy baselines.
Authors: We agree that the manuscript does not currently provide the quantitative metrics, tables, statistical tests, dataset sizes, or error analysis needed to substantiate the claims. We will add a results section with these elements, including specific numbers for intent alignment, execution accuracy, and response frequency versus the diffusion-policy baseline and ablations. revision: yes
-
Referee: [Methods] Methods/Implementation: The description of how pre-inference semantic anchors are constructed and how the fine-tuned F-Qwen planner converts speech, live musical seeds, and visual observations into structured plans lacks detail on training data, fine-tuning procedure, or latency measurements; without these, it is difficult to verify the claim that the planner reliably produces plans executable at low latency by the GMP while preserving coherence.
Authors: We acknowledge the insufficient detail. In the revision we will expand the Methods section with explicit information on semantic anchor construction, the training data and fine-tuning procedure for F-Qwen, and latency measurements for the planner and GMP. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a modular framework (semantic anchors + F-Qwen planner feeding GMP) whose central claims rest on empirical results from real-robot chime experiments, ablations, and expert evaluation rather than any derivation chain. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the architecture is presented as an engineering separation whose performance is externally validated.
Axiom & Free-Parameter Ledger
invented entities (2)
-
F-Qwen
no independent evidence
-
GMP
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InAI Music Creativity(2024)
Sturm, B.et al.Ai music studies: Preparing for the coming flood. InAI Music Creativity(2024)
2024
-
[2]
arXiv preprint arXiv:2402.17177(2024)
Liu, Y .et al.Sora: A review on background, technol- ogy, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177(2024)
Pith/arXiv arXiv 2024
-
[3]
Wang, T.et al.Weaver: Foundation models for creative writing.arXiv preprint arXiv:2401.17268(2024)
arXiv 2024
-
[4]
InRobotics: Science and Systems (RSS)(2023)
Chi, C.et al.Diffusion policy: Visuomotor policy learn- ing via action diffusion. InRobotics: Science and Systems (RSS)(2023)
2023
-
[5]
Dong, Z.et al.Diffuserlite: Towards real-time diffusion planning.arXiv preprint arXiv:2401.15443(2024)
arXiv 2024
- [6]
-
[7]
Yang, A.et al.Qwen2 technical report.arXiv preprint arXiv:2407.10671(2024)
Pith/arXiv arXiv 2024
-
[8]
Socially intelligent robots: dimensions of human–robot interaction.Philos
Dautenhahn, K. Socially intelligent robots: dimensions of human–robot interaction.Philos. Transactions Royal Soc. B: Biol. Sci.360, 679–704 (2005)
2005
-
[9]
F., Queiroz, M
Wamba, S. F., Queiroz, M. M. & Hamzi, L. A biblio- metric and multi-disciplinary quasi-systematic analysis of social robots: Past, future, and insights of human-robot interaction.Technol. Forecast. Soc. Chang.197, 122912 (2023)
2023
-
[10]
Hashmi, B. Q. Artificial intelligence and its role in in- formation and communication technologies (ict): Appli- cation areas of artificial intelligence. InAI and its con- vergence with communication technologies, 1–18 (IGI Global, 2023)
2023
-
[11]
Karimi, P., Rezwana, J., Siddiqui, S., Maher, M. L. & Dehbozorgi, N. Creative sketching partner: an analysis of human-ai co-creativity. InProceedings of the 25th international conference on intelligent user interfaces, 221–230 (2020)
2020
-
[12]
& Dogan, T
Hsieh, P., Benros, D. & Dogan, T. Conversational co-creativity with deep reinforcement learning agent in kitchen layout. InDesign computing and cognition’20, 399–409 (Springer, 2022). 12/13
2022
-
[13]
& De Wit, J
De Rooij, A., Van Den Broek, S., Bouw, M. & De Wit, J. Co-designing with a social robot facilitator: Effects of robot mood expression on human group dynamics. InProceedings of the 11th International Conference on Human-Agent Interaction, 22–29 (2023)
2023
-
[14]
de Rooij, A., Broek, S. v. d., Bouw, M. & de Wit, J. Co- creating with a robot facilitator: Robot expressions cause mood contagion enhancing collaboration, satisfaction, and performance.Int. J. Soc. Robotics1–20 (2024)
2024
-
[15]
Dai, W.et al.Instructblip: Towards general-purpose vision-language models with instruction tuning (2023). 2305.06500
Pith/arXiv arXiv 2023
-
[16]
& Lee, Y
Liu, H., Li, C., Wu, Q. & Lee, Y . J. Visual instruction tuning.Adv. neural information processing systems36 (2024)
2024
-
[17]
Liu, H., Li, C., Li, Y . & Lee, Y . J. Improved base- lines with visual instruction tuning.arXiv preprint arXiv:2310.03744(2023)
Pith/arXiv arXiv 2023
-
[18]
& Fox, D
Shridhar, M., Manuelli, L. & Fox, D. Perceiver-actor: A multi-task transformer for robotic manipulation. In Conference on Robot Learning, 785–799 (PMLR, 2023)
2023
-
[19]
M.et al.Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213(2024)
Team, O. M.et al.Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213(2024)
Pith/arXiv arXiv 2024
-
[20]
Khandate, G.et al.Sampling-based Exploration for Re- inforcement Learning of Dexterous Manipulation. In Proceedings of Robotics: Science and Systems, DOI: 10.15607/RSS.2023.XIX.020 (Daegu, Republic of Ko- rea, 2023)
-
[21]
InProceedings of Robotics: Science and Systems, DOI: 10.15607/RSS
Li, Z.et al.Robust and Versatile Bipedal Jumping Con- trol through Reinforcement Learning. InProceedings of Robotics: Science and Systems, DOI: 10.15607/RSS. 2023.XIX.052 (Daegu, Republic of Korea, 2023)
-
[22]
& Kim, B
Kim, M., Han, J., Kim, J. & Kim, B. Pre-and post-contact policy decomposition for non-prehensile manipulation with zero-shot sim-to-real transfer. In2023 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), 10644–10651 (IEEE, 2023)
2023
-
[23]
Xu, K., Yu, H., Lai, Q., Wang, Y . & Xiong, R. Efficient learning of goal-oriented push-grasping synergy in clutter. IEEE Robotics Autom. Lett.6, 6337–6344 (2021). 24.Haldar, S., Pari, J., Rai, A. & Pinto, L. Teach a Robot to FISH: Versatile Imitation from One Minute of Demonstra- tions. InProceedings of Robotics: Science and Systems, DOI: 10.15607/RSS.20...
-
[24]
neural information processing systems34, 15084–15097 (2021)
Chen, L.et al.Decision transformer: Reinforcement learning via sequence modeling.Adv. neural information processing systems34, 15084–15097 (2021)
2021
-
[25]
M., Cui, Z., Altanzaya, A
Shafiullah, N. M., Cui, Z., Altanzaya, A. A. & Pinto, L. Behavior transformers: Cloning k modes with one stone.Adv. neural information processing systems35, 22955–22968 (2022)
2022
-
[26]
InConference on Computer Vision and Pattern Recognition (CVPR)(2023)
Huang, S.et al.Diffusion-based generation, optimization, and planning in 3d scenes. InConference on Computer Vision and Pattern Recognition (CVPR)(2023)
2023
-
[27]
Li, R., Li, R., Guo, S. & Zhang, L. Source prompt disen- tangled inversion for boosting image editability with dif- fusion models.arXiv preprint arXiv:2403.11105(2024)
arXiv 2024
-
[28]
& Gkanatsios, N
Xian, Z. & Gkanatsios, N. Chaineddiffuser: Uni- fying trajectory diffusion and keypose prediction for robotic manipulation. InConference on Robot Learn- ing/Proceedings of Machine Learning Research(Proceed- ings of Machine Learning Research, 2023)
2023
-
[29]
Evans, Z., Carr, C., Taylor, J., Hawley, S. H. & Pons, J. Fast timing-conditioned latent audio diffusion. In Forty-first International Conference on Machine Learning (2024)
2024
-
[30]
Bai, J.et al.Qwen-vl: A frontier large vision- language model with versatile abilities.arXiv preprint arXiv:2308.12966(2023)
Pith/arXiv arXiv 2023
-
[31]
neural information processing systems30(2017)
Vaswani, A.et al.Attention is all you need.Adv. neural information processing systems30(2017)
2017
-
[32]
InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 12009– 12019 (2022)
Liu, Z.et al.Swin transformer v2: Scaling up capacity and resolution. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 12009– 12019 (2022)
2022
-
[33]
InProceedings of the IEEE/CVF international conference on computer vision, 10012–10022 (2021)
Liu, Z.et al.Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, 10012–10022 (2021)
2021
-
[34]
& Liu, F
Li, J., Wu, C., Song, R., Li, Y . & Liu, F. Adaptive weighted attention network with camera spectral sensi- tivity prior for spectral reconstruction from rgb images. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops, 462– 463 (2020)
2020
-
[35]
Gu, J.et al.Maniskill2: A unified benchmark for generalizable manipulation skills.arXiv preprint arXiv:2302.04659(2023)
arXiv 2023
-
[36]
Gao, F., Li, X., Yu, J. & Shaung, F. A two-stage fine- tuning strategy for generalizable manipulation skill of embodied ai.arXiv preprint arXiv:2307.11343(2023)
arXiv 2023
-
[37]
Fang, H.-S.et al.Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot.arXiv preprint arXiv:2307.00595(2023)
arXiv 2023
-
[38]
Khazatsky, A.et al.Droid: A large-scale in- the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945(2024). 13/13
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.