NAMESAKES: Probing Identity Memorization in Text-to-Image Models
Pith reviewed 2026-06-26 18:12 UTC · model grok-4.3
The pith
A black-box probe using only generated images can detect which names trigger memorized identities in text-to-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a fully black-box behavioral probe that distinguishes between memorized and fabricated identity regimes in text-to-image models while requiring no reference photos or prior knowledge of training data. To benchmark the task we present the NAMESAKES dataset of over one thousand names and faces of public figures spanning a wide range of fame levels, along with perturbed, less famous names. Experiments on state-of-the-art T2I models show that our probe substantially predicts identity memorization and separates memorized from unrecognized names, with further insights into differences across model families.
What carries the argument
A behavioral probe that compares generation patterns from a given name against patterns from its perturbed variants to infer memorization status.
If this is right
- Memorization status for any name can be estimated from outputs alone, enabling audits without external data.
- The probe distinguishes memorized names from unrecognized ones at scale across current models.
- Different model families display distinct patterns of identity memorization.
- The NAMESAKES dataset provides a reusable benchmark for testing future detection methods.
Where Pith is reading between the lines
- Similar behavioral probes could be developed for other generative domains such as text or audio to detect memorized content.
- Model developers could run the probe routinely to identify and mitigate privacy risks before release.
- The separation of memorized versus fabricated outputs suggests training pipelines need explicit safeguards against retaining identifiable faces.
- The approach opens the possibility of automated monitoring for compliance with data-protection rules on deployed image generators.
Load-bearing premise
Patterns visible in generated images alone are enough to tell whether the model has previously seen the identity or is creating a new face.
What would settle it
Apply the probe to a model whose training data is fully known, then check whether names scored as memorized actually appear in that training set; systematic mismatch would falsify the probe.
Figures


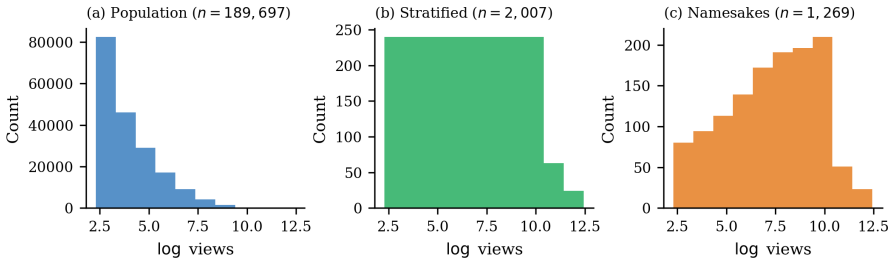
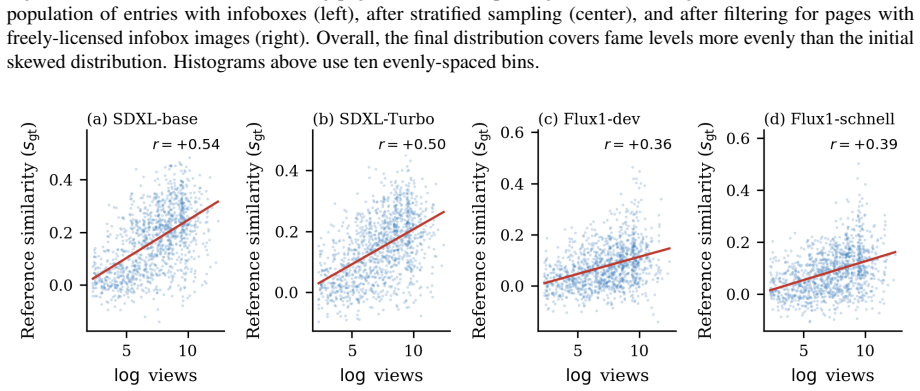
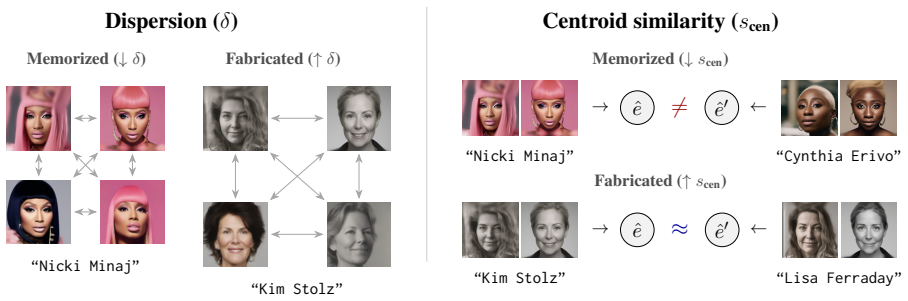






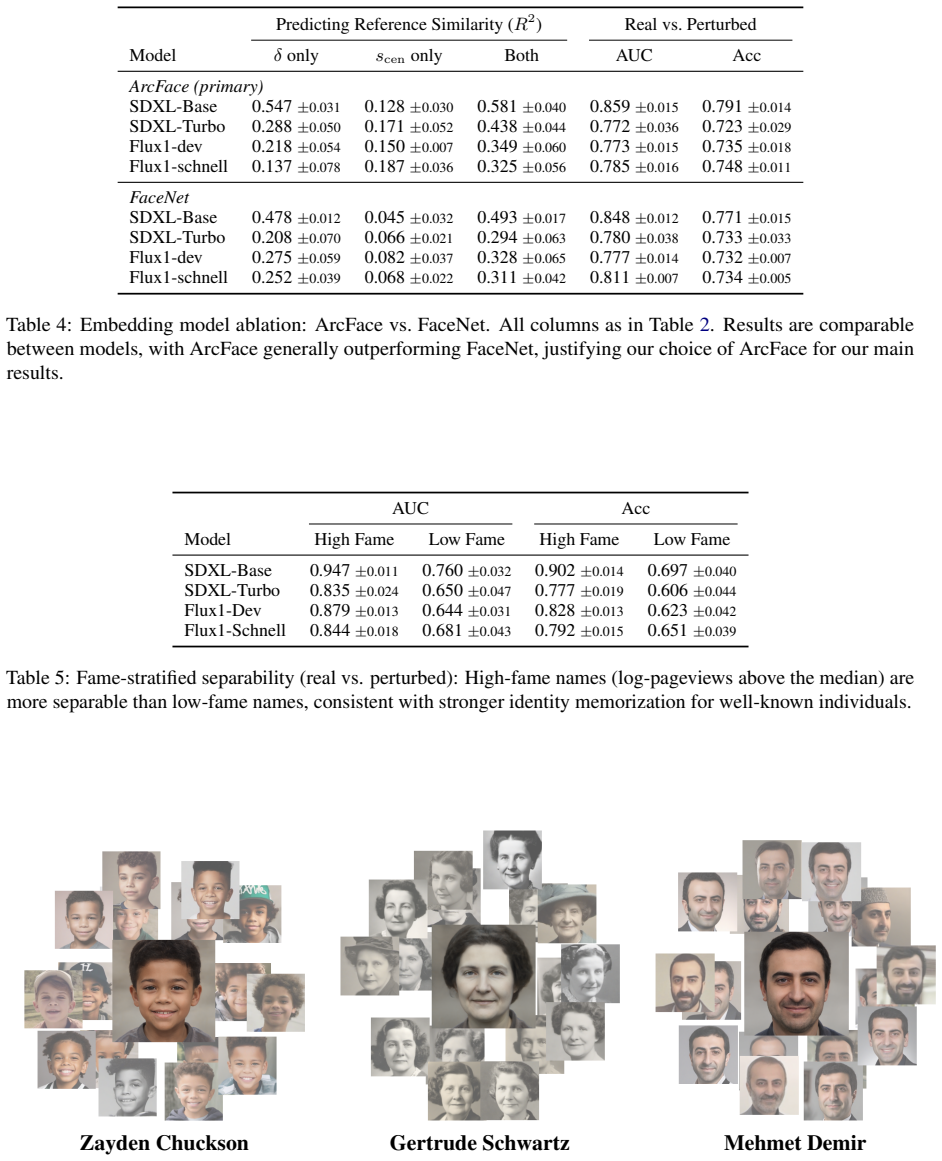
read the original abstract
Text-to-image (T2I) models generate realistic likenesses of some individuals when prompted with their names, raising privacy concerns. However, distinguishing whether a generated face is memorized or fabricated currently requires ground-truth photos, access to training data, or white-box access to model internals, limiting applicability. We introduce a fully black-box behavioral probe that distinguishes between these regimes while requiring no reference photos or prior knowledge of training data. To benchmark this task, we present the NAMESAKES dataset of over one thousand names and faces of public figures spanning a wide range of fame levels, along with perturbed, less famous names. Experiments on state-of-the-art T2I models show that our probe substantially predicts identity memorization and separates memorized from unrecognized names, with further insights into differences across model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the NAMESAKES dataset (>1000 public-figure names/faces spanning fame levels plus perturbed-name controls) and a fully black-box behavioral probe that uses generated-image patterns to distinguish memorized identities from fabricated ones in T2I models, without reference photos or training-data access. Experiments on state-of-the-art models are claimed to show that the probe substantially predicts identity memorization, separates memorized from unrecognized names, and reveals model-family differences.
Significance. A validated black-box probe for identity memorization would be a useful auditing tool for privacy risks in deployed T2I systems. The dataset construction and cross-family comparisons could also supply a reusable benchmark if the fame-level proxy is shown to track actual training exposure.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that the probe 'substantially predicts identity memorization' is evaluated against fame-level proxy labels for 'memorized' vs. 'unrecognized' names. No direct validation (e.g., correlation with known training-set membership, ablation on non-famous names that nevertheless appear in training, or comparison against models trained with/without the identities) is supplied, so the reported separation may reflect broad statistical regularities rather than instance-level memorization.
- [Dataset] Dataset construction (implied in Abstract): the positive/negative split relies on public-figure fame as a monotonic proxy for training exposure. This proxy can fail for low-fame names that still appear in training data or for high-fame names whose faces are generated via generic pre-training statistics rather than memorization; the manuscript does not quantify or bound this mismatch.
minor comments (1)
- [Abstract] The abstract states the probe is 'fully black-box' and requires 'no reference photos,' yet does not specify the exact behavioral features or generation protocol used by the probe; a methods subsection should enumerate them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that the probe 'substantially predicts identity memorization' is evaluated against fame-level proxy labels for 'memorized' vs. 'unrecognized' names. No direct validation (e.g., correlation with known training-set membership, ablation on non-famous names that nevertheless appear in training, or comparison against models trained with/without the identities) is supplied, so the reported separation may reflect broad statistical regularities rather than instance-level memorization.
Authors: We agree that direct validation against training-set membership would be stronger evidence. Such validation is not feasible in a black-box setting without training-data access, which is the regime our probe targets. The perturbed-name controls are designed to isolate instance-level effects from generic statistical patterns. We will add an explicit limitations discussion on the proxy and potential statistical regularities. revision: partial
-
Referee: [Dataset] Dataset construction (implied in Abstract): the positive/negative split relies on public-figure fame as a monotonic proxy for training exposure. This proxy can fail for low-fame names that still appear in training data or for high-fame names whose faces are generated via generic pre-training statistics rather than memorization; the manuscript does not quantify or bound this mismatch.
Authors: We acknowledge that the fame proxy is imperfect and the manuscript provides no quantitative bounds on mismatch. Bounding the mismatch exactly requires training-data access that is unavailable. We will revise to add a qualitative analysis of failure modes and how the fame spectrum plus perturbed controls address them. revision: partial
- Direct quantification or validation of the fame proxy against actual training-set membership is not possible without access to the models' proprietary training data.
Circularity Check
No significant circularity; evaluation uses independent proxy labels
full rationale
The paper defines a black-box behavioral probe and evaluates its ability to separate names using the NAMESAKES dataset, where labels derive from public-figure fame levels and perturbed-name controls. No equations or steps reduce the probe's reported predictive power to a fit or self-definition by construction. The distinction between memorized and unrecognized regimes is benchmarked against the constructed proxy rather than being tautological with it. No self-citation load-bearing, ansatz smuggling, or renaming of known results appears in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Krzysztof Adamkiewicz, Brian Moser, Stanislav Frolov, Tobias Christian Nauen, Federico Raue, and Andreas Dengel. 2026. When pretty isn't useful: Investigating why modern text-to-image models fail as reliable training data generators. arXiv preprint arXiv:2602.19946
Pith/arXiv arXiv 2026
-
[2]
Morris Alper and Hadar Averbuch-Elor. 2023. Kiki or bouba? sound symbolism in vision-and-language models. Advances in Neural Information Processing Systems, 36:78347--78359
2023
-
[3]
Morris Alper and Hadar Averbuch-Elor. 2024. Emergent visual-semantic hierarchies in image-text representations. In European Conference on Computer Vision, pages 220--238. Springer
2024
-
[4]
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. 2023. Easily accessible text-to-image generation amplifies demographic stereotypes at large scale. In Proceedings of the 2023 ACM conference on fairness, accountability, and transparency, pages 1493--1504
2023
-
[5]
Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, pages 77--91. PMLR
2018
-
[6]
Qiong Cao, Li Shen, Weidi Xie, Omkar M Parkhi, and Andrew Zisserman. 2018. Vggface2: A dataset for recognising faces across pose and age. In 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018), pages 67--74. IEEE
2018
-
[7]
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023. Extracting training data from diffusion models. In 32nd USENIX security symposium (USENIX Security 23), pages 5253--5270
2023
-
[8]
Jacob Cohen. 2013. Statistical power analysis for the behavioral sciences. routledge
2013
-
[9]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690--4699
2019
-
[10]
Jinhao Duan, Fei Kong, Shiqi Wang, Xiaoshuang Shi, and Kaidi Xu. 2023. Are diffusion models vulnerable to membership inference attacks? In International Conference on Machine Learning, pages 8717--8730. PMLR
2023
-
[11]
Jan Dubi \'n ski, Antoni Kowalczuk, Stanis aw Pawlak, Przemyslaw Rokita, Tomasz Trzci \'n ski, and Pawe Morawiecki. 2024. Towards more realistic membership inference attacks on large diffusion models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4860--4869
2024
-
[12]
Rohit Gandikota and David Bau. 2026. Distilling diversity and control in diffusion models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1304--1313
2026
-
[13]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daum \'e Iii, and Kate Crawford. 2021. Datasheets for datasets. Communications of the ACM, 64(12):86--92
2021
-
[14]
GitHub. 2024. Flux doesn't understand specifics! https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1494
2024
-
[15]
Google . 2026. https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ Gemini 3.1 Pro: A smarter model for your most complex tasks
2026
-
[16]
Xiangming Gu, Chao Du, Tianyu Pang, Chongxuan Li, Min Lin, and Ye Wang. 2023. On memorization in diffusion models. arXiv preprint arXiv:2310.02664
arXiv 2023
-
[17]
Dominik Hintersdorf, Lukas Struppek, Manuel Brack, Felix Friedrich, Patrick Schramowski, and Kristian Kersting. 2024 a . Does clip know my face? Journal of Artificial Intelligence Research, 80:1033--1062
2024
-
[18]
Dominik Hintersdorf, Lukas Struppek, Kristian Kersting, Adam Dziedzic, and Franziska Boenisch. 2024 b . Finding nemo: Localizing neurons responsible for memorization in diffusion models. Advances in Neural Information Processing Systems, 37:88236--88278
2024
-
[19]
Hailong Hu and Jun Pang. 2023. Membership inference of diffusion models. arXiv preprint arXiv:2301.09956
arXiv 2023
-
[20]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401--4410
2019
-
[21]
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of StyleGAN . In Proc. CVPR
2020
-
[22]
Black Forest Labs. 2024. Flux.1 [dev]. https://github.com/black-forest-labs/flux
2024
-
[23]
Songze Li, Ruoxi Cheng, and Xiaojun Jia. 2025. Tuni: A textual unimodal detector for identity inference in clip models. In Proceedings of the Sixth Workshop on Privacy in Natural Language Processing, pages 1--13
2025
-
[24]
Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. 2023. https://openreview.net/forum?id=qVXYU3F017 Stable bias: Evaluating societal representations in diffusion models . In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2023
-
[25]
Zhe Ma, Qingming Li, Xuhong Zhang, Tianyu Du, Ruixiao Lin, Zonghui Wang, Shouling Ji, and Wenzhi Chen. 2025. An inversion-based measure of memorization for diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16959--16969
2025
-
[26]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M \"u ller, Joe Penna, and Robin Rombach. 2024. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In The Twelfth International Conference on Learning Representations
2024
-
[27]
Reddit. 2024. What happened here, and why? (flux-dev). https://www.reddit.com/r/StableDiffusion/comments/1ejuuzm/what_happened_here_and_why_fluxdev/
2024
-
[28]
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. 2024. Adversarial diffusion distillation. In European Conference on Computer Vision, pages 87--103. Springer
2024
-
[29]
Morgan Klaus Scheuerman, Alex Hanna, and Remi Denton. 2021. Do datasets have politics? disciplinary values in computer vision dataset development. Proceedings of the ACM on human-computer interaction, 5(CSCW2):1--37
2021
-
[30]
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 815--823
2015
-
[31]
Hannu Simonen, Atte Kiviniemi, Hannah Johnston, Helena Barranha, and Jonas Oppenlaender. 2026. https://doi.org/10.1145/3772318.3790681 An exploration of default images in text-to-image generation . In ACM CHI Conference on Human Factors in Computing Systems, New York, NY, USA. ACM
-
[32]
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2023 a . Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6048--6058
2023
-
[33]
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2023 b . Understanding and mitigating copying in diffusion models. Advances in Neural Information Processing Systems, 36:47783--47803
2023
-
[34]
Nikki Stevens and Os Keyes. 2021. Seeing infrastructure: Race, facial recognition and the politics of data. Cultural Studies, 35(4-5):833--853
2021
-
[35]
Lukas Struppek, Dominik Hintersdorf, Felix Friedrich, Manuel Brack, Patrick Schramowski, and Kristian Kersting. 2024. Exploiting cultural biases via homoglyphs intext-to-image synthesis (abstract reprint). In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 8486--8486
2024
-
[36]
Omer Tov, Yuval Alaluf, Yotam Nitzan, Or Patashnik, and Daniel Cohen-Or. 2021. Designing an encoder for stylegan image manipulation. ACM Transactions on Graphics (TOG), 40(4):1--14
2021
-
[37]
Jayneel Vora, Nader Bouacida, Aditya Krishnan, Prabhu Shankar, and Prasant Mohapatra. 2025. Identity-focused inference and extraction attacks on diffusion models. In Proceedings of the 40th ACM/SIGAPP Symposium on Applied Computing, pages 1522--1530
2025
-
[38]
Ryan Webster, Julien Rabin, Loic Simon, and Frederic Jurie. 2021. This person (probably) exists. identity membership attacks against gan generated faces. arXiv preprint arXiv:2107.06018
arXiv 2021
-
[39]
Yuxin Wen, Yuchen Liu, Chen Chen, and Lingjuan Lyu. 2024. Detecting, explaining, and mitigating memorization in diffusion models. In The Twelfth International Conference on Learning Representations
2024
-
[40]
Ge Yuan, Xiaodong Cun, Yong Zhang, Maomao Li, Chenyang Qi, Xintao Wang, Ying Shan, and Huicheng Zheng. 2023. Inserting anybody in diffusion models via celeb basis. Advances in Neural Information Processing Systems, 36:72958--72982
2023
-
[41]
Seyma Yucer, Furkan Tektas, Noura Al Moubayed, and Toby Breckon. 2024. Racial bias within face recognition: A survey. ACM Computing Surveys, 57(4):1--39
2024
-
[42]
Zheng Zhu, Guan Huang, Jiankang Deng, Yun Ye, Junjie Huang, Xinze Chen, Jiagang Zhu, Tian Yang, Jiwen Lu, Dalong Du, and 1 others. 2021. Webface260m: A benchmark unveiling the power of million-scale deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10492--10502
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.