DataMagic: Transforming Tabular Data into Data Insight Video
Pith reviewed 2026-06-26 15:43 UTC · model grok-4.3
The pith
DataMagic turns raw tabular data and natural language queries into narrative data-insight videos that keep exact data values intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
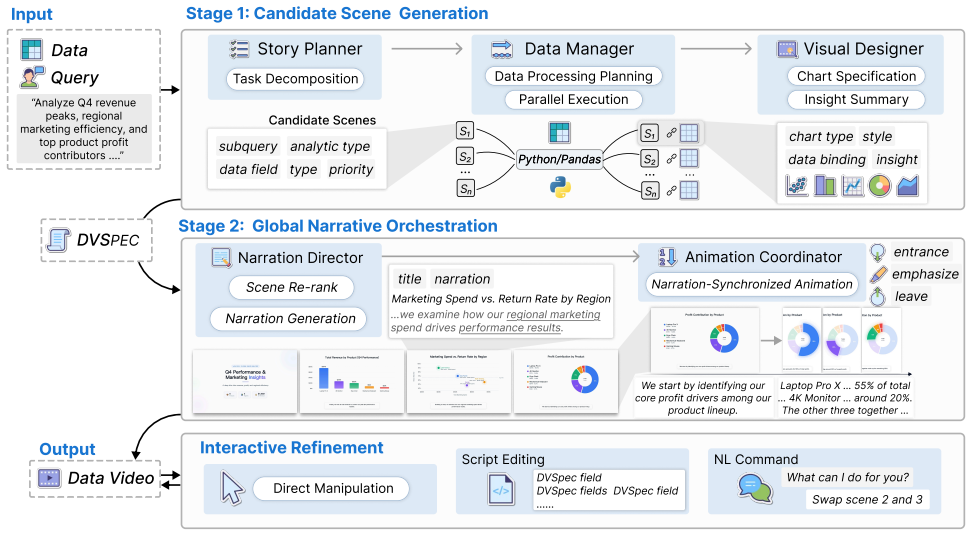
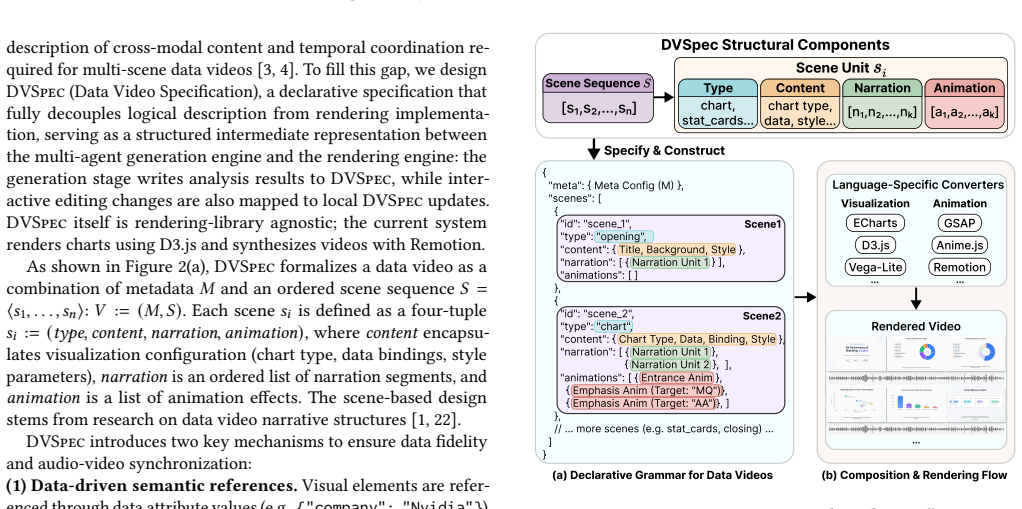
Raw tabular data together with natural language queries can be automatically turned into narrative videos by first declaring visual and animation elements through data-driven semantic references in DVSpec, then using parallel generation of candidate scenes followed by global orchestration to enforce narrative coherence, with the resulting videos supporting provenance-based queries.
What carries the argument
DVSpec, a declarative specification that binds visual and animation elements to underlying data fields through data-driven semantic references, paired with the Generate-then-Orchestrate multi-agent architecture that produces candidate scenes in parallel and then optimizes global narrative coherence.
If this is right
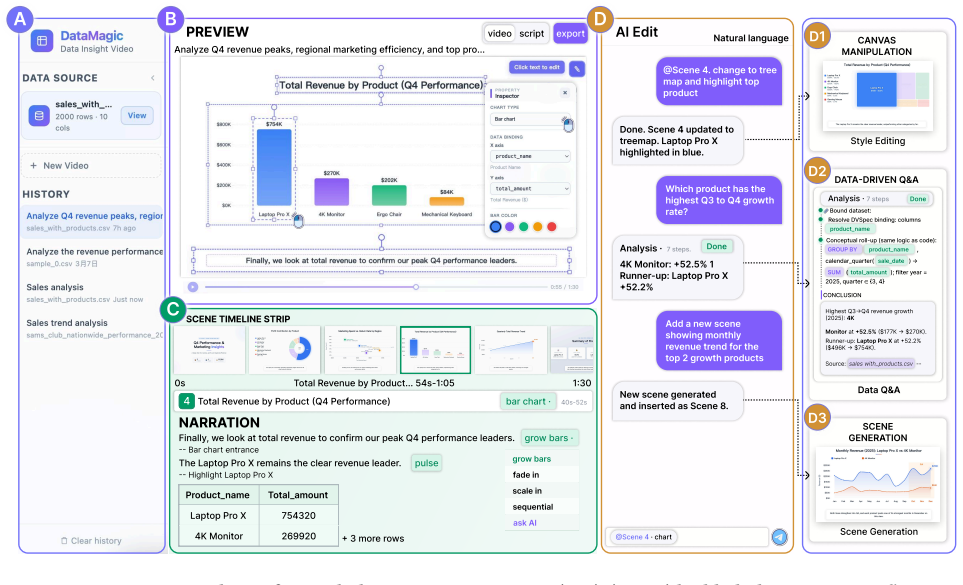
- One-way videos become two-way interfaces that accept structured questions about the underlying data.
- Decoupling of specification from rendering enables three distinct interaction modes on the same output.
- Data fidelity is preserved end-to-end because every visual element remains explicitly linked to its source field.
Where Pith is reading between the lines
- The approach could shorten the time between raw data analysis and shareable communication in typical data workflows.
- If orchestration scales, similar pipelines might be applied to other temporal media such as interactive reports or dashboards.
- Provenance tracking in the videos opens the possibility of audit trails for data claims made in presentations.
Load-bearing premise
The combination of parallel scene generation and a later global orchestration step will produce videos that stay both narratively coherent and numerically faithful without any post-generation manual fixes.
What would settle it
Apply the system to a fresh collection of tabular datasets and complex queries outside the original 109 samples, then measure whether every numeric value shown in the video matches the source table and whether the story flows without breaks or contradictions.
Figures
read the original abstract
Data videos integrate dynamic charts, voice narration, and synchronized animations to communicate data insights as temporal narratives, making them an effective medium for improving data consumption efficiency in the data management lifecycle. However, producing high-quality data videos requires expertise spanning data analysis, narrative design, and video production. Existing approaches fall short: static visualization tools (e.g., BI dashboards) lack narrative logic and animation; authoring tools require users to pre-prepare visualizations rather than working from raw data; pixel-level video generation models cannot guarantee data fidelity or provenance. We demonstrate DataMagic, an end-to-end interactive system that transforms raw tabular data and natural language queries into narrative data-insight videos. To ensure data fidelity, DataMagic introduces the declarative specification DVSpec, which binds visual and animation elements to underlying data fields through data-driven semantic references. To address the combinatorial explosion of the design space, DataMagic adopts a Generate-then-Orchestrate multi-agent architecture that generates candidate scenes in parallel and then optimizes narrative coherence through global orchestration. Leveraging DVSpec's decoupling of logic and rendering, the system further supports three interaction modes and structured provenance-based data Q&A, transforming one-way videos into explorable interactive data interfaces. Evaluation on 109 real-world samples validates the effectiveness of the DataMagic. Homepage: https://datamagic-home.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DataMagic, an end-to-end interactive system that transforms raw tabular data and natural language queries into narrative data-insight videos. It introduces the declarative DVSpec to bind visual/animation elements to data fields for fidelity, adopts a Generate-then-Orchestrate multi-agent architecture to manage combinatorial design space, supports three interaction modes plus provenance-based Q&A, and claims validation via evaluation on 109 real-world samples.
Significance. If the central claims hold, the work offers a practical engineering contribution to automated data storytelling by decoupling logic from rendering and addressing narrative coherence in video generation from raw data. Strengths include the interactive modes and provenance features that extend one-way videos into explorable interfaces; however, the absence of any reported metrics, baselines, or fidelity measures in the evaluation substantially weakens the assessed significance.
major comments (2)
- [Evaluation] Evaluation section (referenced in abstract): the claim that 'evaluation on 109 real-world samples validates the effectiveness' supplies no metrics, baselines, error analysis, or description of how data fidelity or narrative coherence was measured, rendering the central effectiveness claim impossible to assess.
- [System Architecture] Generate-then-Orchestrate architecture (abstract and system description): the multi-agent orchestration step that resolves the combinatorial design space is presented only at high level with no algorithm, conflict-resolution rules, or failure-mode analysis, which is load-bearing for the claim that the architecture reliably produces coherent, faithful videos without post-hoc fixes.
minor comments (2)
- [Abstract] The abstract mentions 'three interaction modes' but provides no concrete examples or details on how DVSpec enables them.
- [Abstract] Homepage link is given but no mention of whether code, DVSpec examples, or evaluation data are released for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each major comment below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (referenced in abstract): the claim that 'evaluation on 109 real-world samples validates the effectiveness' supplies no metrics, baselines, error analysis, or description of how data fidelity or narrative coherence was measured, rendering the central effectiveness claim impossible to assess.
Authors: We agree that the evaluation section lacks sufficient quantitative details to fully support the effectiveness claim. The 109 samples were used to demonstrate the system's applicability across real-world scenarios, but we did not report specific metrics such as fidelity scores or coherence ratings. In the revised version, we will add a detailed evaluation subsection including metrics for data fidelity (e.g., accuracy of data bindings), narrative coherence (e.g., user study scores), baselines if applicable, and error analysis. revision: yes
-
Referee: [System Architecture] Generate-then-Orchestrate architecture (abstract and system description): the multi-agent orchestration step that resolves the combinatorial design space is presented only at high level with no algorithm, conflict-resolution rules, or failure-mode analysis, which is load-bearing for the claim that the architecture reliably produces coherent, faithful videos without post-hoc fixes.
Authors: The manuscript presents the architecture at a conceptual level to emphasize the Generate-then-Orchestrate paradigm. However, we recognize the need for more implementation details. We will revise the system description to include the specific orchestration algorithm, rules for resolving conflicts between agents (such as priority-based merging of scene elements), and analysis of potential failure modes with mitigation strategies. revision: yes
Circularity Check
No circularity: engineering system description with no derivation chain or fitted quantities
full rationale
The paper describes an interactive system (DataMagic) that uses DVSpec for data binding and a Generate-then-Orchestrate multi-agent architecture to produce videos from tabular data and NL queries. No equations, parameters, predictions, or self-citations appear in the abstract or provided text that reduce any central claim to its own inputs by construction. The 109-sample evaluation is presented only as validation of effectiveness, with no indication of fitted inputs renamed as predictions or load-bearing self-citations. The work is self-contained as an artifact description rather than a mathematical derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DVSpec
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fereshteh Amini et al. 2015. Understanding Data Videos: Looking at Narrative Visualization through the Cinematography Lens. InCHI. ACM, 1459–1468
2015
-
[2]
Anthropic. 2025. Claude Sonnet 4. https://www.anthropic.com/news/claude- sonnet-4
2025
-
[3]
Yiru Chen et al. 2025. Physical Visualization Design: Decoupling Interface and System Design.Proc. ACM Manag. Data3, 3 (2025), 197:1–197:27
2025
-
[4]
Yiru Chen, Jeffrey Tao, and Eugene Wu. 2023. DIG: The Data Interface Grammar. InHILDA@SIGMOD. ACM, 7:1–7:7
2023
-
[5]
Yiyu Chen, Yifan Wu, Shuyu Shen, Yupeng Xie, Leixian Shen, Hui Xiong, and Yuyu Luo. 2025. ChartMark: A Structured Grammar for Chart Annotation. In 2025 IEEE Visualization and Visual Analytics (VIS). IEEE, 311–315
2025
-
[6]
DeepSeek-AI. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL]
Pith/arXiv arXiv 2025
-
[7]
Tong Ge, Weiwei Cui, Bongshin Lee, Huamin Qu, and Dongmei Zhang. 2020. Canis: A High-level Language for Cohort-based Chart Animations. InProceedings of the ACM Conference on Human Factors in Computing Systems
2020
-
[8]
Google DeepMind. 2025. Gemini 2.5: Our Most Intelligent Model Yet. https://blog.google/technology/google-deepmind/gemini-model-thinking- updates-march-2025/
2025
-
[9]
Fangyu Lei, Jinxiang Meng, Yiming Huang, Junjie Zhao, Yitong Zhang, Jianwen Luo, Xin Zou, Ruiyi Yang, Wenbo Shi, Yan Gao, Shizhu He, Zuo Wang, Qian Liu, Yang Wang, Ke Wang, Jun Zhao, and Kang Liu. 2025. DAComp: Benchmarking Data Agents across the Full Data Intelligence Lifecycle.CoRRabs/2512.04324 (2025). https://doi.org/10.48550/ARXIV.2512.04324 arXiv:2512.04324
-
[10]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The dawn of natural language to sql: Are we fully ready?arXiv preprint arXiv:2406.01265(2024)
arXiv 2024
-
[11]
Boyan Li, Yiran Peng, Yupeng Xie, Sirong Lu, Yizhang Zhu, Xing Mu, Xinyu Liu, and Yuyu Luo. 2026. Deepeye: A steerable self-driving data agent system. In Companion of the International Conference on Management of Data. 74–77
2026
-
[12]
Tianyi Lin et al. 2025. LEAD: Iterative Data Selection for Efficient LLM Instruction Tuning.arXiv preprint(2025)
2025
-
[13]
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, et al . 2024. Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177(2024)
Pith/arXiv arXiv 2024
-
[14]
Tianqi Luo, Chuhan Huang, Leixian Shen, Boyan Li, Shuyu Shen, Wei Zeng, Nan Tang, and Yuyu Luo. 2026. nvbench 2.0: Resolving ambiguity in text- to-visualization through stepwise reasoning.Advances in Neural Information Processing Systems38 (2026)
2026
-
[15]
Yuyu Luo, Xuedi Qin, Nan Tang, and Guoliang Li. 2018. Deepeye: Towards automatic data visualization. In2018 IEEE 34th international conference on data engineering (ICDE). IEEE, 101–112
2018
-
[16]
Yuyu Luo, Nan Tang, Guoliang Li, Chengliang Chai, Wenbo Li, and Xuedi Qin
-
[17]
InProceedings of the 2021 International Conference on Management of Data
Synthesizing natural language to visualization (NL2VIS) benchmarks from NL2SQL benchmarks. InProceedings of the 2021 International Conference on Management of Data. 1235–1247
2021
-
[18]
Yuyu Luo, Nan Tang, Guoliang Li, Jiawei Tang, Chengliang Chai, and Xuedi Qin
-
[19]
Natural language to visualization by neural machine translation.IEEE Transactions on Visualization and Computer Graphics28, 1 (2021), 217–226
2021
-
[20]
OpenAI. 2025. GPT-5 System Card. https://openai.com/index/gpt-5-system- card/
2025
-
[21]
Fotis Psallidas and Eugene Wu. 2018. Provenance for interactive visualizations. InProceedings of the Workshop on Human-In-the-Loop Data Analytics. 1–8
2018
-
[22]
Yanlin Qi, Xinhang Chen, Huiqiang Jiang, Qitong Wang, Botao Peng, and Themis Palpanas. 2026. ParisKV: Fast and Drift-Robust KV-Cache Retrieval for Long- Context LLMs.arXiv preprint arXiv:2602.07721(2026)
Pith/arXiv arXiv 2026
-
[23]
Arvind Satyanarayan, Dominik Moritz, Kanit Wongsuphasawat, and Jeffrey Heer. 2017. Vega-Lite: A Grammar of Interactive Graphics.IEEE Transactions on Visualization and Computer Graphics23, 1 (2017), 341–350
2017
-
[24]
Leixian Shen et al. 2024. Data Player: Automatic Generation of Data Videos with Narration-Animation Interplay.IEEE Trans. Vis. Comput. Graph.30, 1 (2024), 109–119
2024
-
[25]
Leixian Shen et al. 2025. Data Playwright: Authoring Data Videos With Anno- tated Narration.IEEE Trans. Vis. Comput. Graph.31, 9 (2025), 5884–5897
2025
-
[26]
Leixian Shen, Haotian Li, Yun Wang, and Huamin Qu. 2025. Reflecting on Design Paradigms of Animated Data Video Tools. InCHI. ACM, 190:1–190:21
2025
-
[27]
Leixian Shen, Enya Shen, Yuyu Luo, Xiaocong Yang, Xuming Hu, Xiongshuai Zhang, Zhiwei Tai, and Jianmin Wang. 2022. Towards natural language interfaces for data visualization: A survey.IEEE transactions on visualization and computer graphics29, 6 (2022), 3121–3144
2022
-
[28]
Shuyu Shen, Sirong Lu, Leixian Shen, and Yuyu Luo. 2026. Debugging Defective Visualizations: Empirical Insights Informing a Human-AI Co-Debugging System. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–24
2026
-
[29]
Tarique Siddiqui et al. 2016. Effortless Data Exploration with zenvisage: An Expressive and Interactive Visual Analytics System.Proc. VLDB Endow.10, 4 (2016), 457–468
2016
-
[30]
Xiaoyan Su, Peijie Dong, Zhenheng Tang, Song Tang, Yuyao Zhai, Kaitao Lin, Liang Chen, Gai Yuhang, Yuyu Luo, Qiang Wang, et al . 2026. VCG-Bench: Towards A Unified Visual-Centric Benchmark for Structured Generation and Editing.arXiv preprint arXiv:2605.15677(2026)
Pith/arXiv arXiv 2026
-
[31]
Yinghao Tang, Xueding Liu, Boyuan Zhang, Tingfeng Lan, Yupeng Xie, Jiale Lao, Yiyao Wang, Haoxuan Li, Tingting Gao, Bo Pan, et al . 2026. IGenBench: Benchmarking the Reliability of Text-to-Infographic Generation.arXiv preprint arXiv:2601.04498(2026)
Pith/arXiv arXiv 2026
-
[32]
Yinghao Tang, Yupeng Xie, Yingchaojie Feng, Tingfeng Lan, and Wei Chen. 2026. sketch-plot: Progressive Editing for Text-to-Image Academic Figures.arXiv preprint arXiv:2606.09171(2026)
Pith/arXiv arXiv 2026
-
[33]
Yinghao Tang, Yupeng Xie, Yingchaojie Feng, Tingfeng Lan, Jiale Lao, Yue Cheng, and Wei Chen. 2026. ViviDoc: Generating Interactive Documents through Human-Agent Collaboration.arXiv preprint arXiv:2603.27991(2026)
arXiv 2026
-
[34]
Yinghao Tang, Yupeng Xie, Yingchaojie Feng, Jiale Lao, Tingfeng Lan, and Wei Chen. 2026. Demonstrating chart-plot: Closing the Last Mile of Academic Chart Generation.arXiv preprint arXiv:2606.09174(2026)
Pith/arXiv arXiv 2026
-
[35]
Manasi Vartak et al . 2015. SEEDB: Efficient Data-Driven Visualization Rec- ommendations to Support Visual Analytics.Proc. VLDB Endow.8, 13 (2015), 2182–2193
2015
-
[36]
Liangwei Wang, Zhengxuan Zhang, Yi-Fan Cao, Fugee Tsung, and Yuyu Luo
-
[37]
InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems
TableTale: Reviving the Narrative Interplay Between Data Tables and Text in Scientific Papers. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–17
2026
-
[38]
Yifan Wu, Lutao Yan, Leixian Shen, Yunhai Wang, Nan Tang, and Yuyu Luo. 2024. Chartinsights: Evaluating multimodal large language models for low-level chart question answering. InFindings of the Association for Computational Linguistics: EMNLP 2024. 12174–12200
2024
-
[39]
Yupeng Xie, Yuyu Luo, Guoliang Li, and Nan Tang. 2024. HAIChart: Human and AI Paired Visualization System.Proc. VLDB Endow.17, 11 (2024), 3178–3191
2024
-
[40]
Yupeng Xie, Zhiyang Zhang, Yifan Wu, Sirong Lu, Jiayi Zhang, Zhaoyang Yu, Jinlin Wang, Sirui Hong, Bang Liu, Chenglin Wu, and Yuyu Luo
-
[41]
VisJudge-Bench: Aesthetics and Quality Assessment of Visualizations. arXiv:2510.22373 [cs.CL]
-
[42]
Jie Zhang, Changzai Pan, Kaiwen Wei, et al . 2025. T2R-bench: A Bench- mark for Generating Article-Level Reports from Real World Industrial Ta- bles.CoRRabs/2508.19813 (2025). https://doi.org/10.48550/ARXIV.2508.19813 arXiv:2508.19813
-
[43]
Yizhang Zhu, Liangwei Wang, Chenyu Yang, Xiaotian Lin, Boyan Li, Wei Zhou, Xinyu Liu, Zhangyang Peng, Tianqi Luo, Yu Li, et al . 2025. A Survey of Data Agents: Emerging Paradigm or Overstated Hype?arXiv preprint arXiv:2510.23587 (2025). 5
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.