FlowEdit: Associative Memory for Lifelong Pronunciation Adaptation in Flow-Matching TTS
Pith reviewed 2026-06-26 17:34 UTC · model grok-4.3
The pith
FlowEdit enables frozen flow-matching TTS to learn new pronunciations lifelong by storing embedding-space corrections in a Hopfield network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
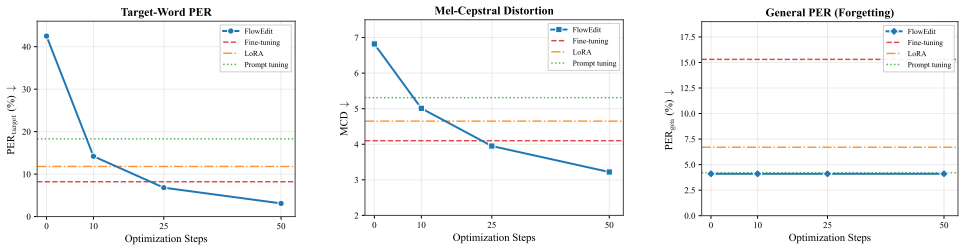
By optimizing a token-level perturbation in the text embedding space for each corrective feedback and storing it in a Modern Hopfield Network, FlowEdit allows the frozen flow-matching TTS model to retrieve and apply pronunciation fixes at inference time through soft attention, achieving a 92.7% relative reduction in phoneme error rate on multilingual proper nouns without changing the model's output distribution for other words.
What carries the argument
Modern Hopfield Network serving as content-addressable episodic memory for text embedding perturbations.
If this is right
- New pronunciation corrections can be added continuously without retraining the base model.
- Retrieval supports fuzzy matching so similar words can trigger the correction.
- General speech quality for non-target words remains identical to the zero-shot model.
- Adaptation is fast enough for practical use, taking about 15 seconds per correction.
Where Pith is reading between the lines
- The same storage and retrieval pattern could be applied to adapt other conditioning inputs in generative audio models.
- Production TTS services could collect and apply user corrections automatically over time.
- Testing whether corrections remain isolated when many are stored would be a useful next experiment.
Load-bearing premise
The assumption that an embedding perturbation optimized for one word will affect only that word's pronunciation and leave all other outputs unchanged.
What would settle it
Measuring whether the phoneme error rate or audio quality for a set of non-target words increases after multiple corrections have been stored and retrieved.
Figures
read the original abstract
Flow-matching text-to-speech systems achieve remarkable zero-shot quality but remain static after deployment: pronunciation errors on out-of-vocabulary proper nouns persist unless the model is retrained. We introduce FlowEdit, a life-long adaptation framework for frozen flow-matching TTS that learns pronunciation corrections as latent conditioning edits rather than weight updates. When corrective feedback is provided, FlowEdit optimizes a token-level perturbation in the text embedding space, then stores the correction in a Modern Hopfield Network serving as content-addressable episodic memory. At inference, corrections are retrieved via soft attention with a similarity gate, enabling fuzzy morphological matching. On our curated benchmark of 312 multilingual proper nouns across 18 language families, FlowEdit reduces target-word Phoneme Error Rate by 92.7% relative to the zero-shot baseline while maintaining identical general-speech quality. Corrections complete in approximately 15 seconds on a single GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowEdit, a lifelong adaptation method for frozen flow-matching TTS models. It optimizes token-level perturbations in text embedding space to correct pronunciations of out-of-vocabulary proper nouns, stores these corrections in a Modern Hopfield Network as content-addressable memory, and retrieves them at inference via soft attention with a similarity gate for fuzzy matching. On a curated benchmark of 312 multilingual proper nouns across 18 language families, it claims a 92.7% relative reduction in target-word Phoneme Error Rate versus the zero-shot baseline while preserving general-speech quality, with corrections completing in ~15 seconds on one GPU.
Significance. If the empirical result holds under rigorous controls, the work would offer a practical mechanism for post-deployment pronunciation adaptation without model retraining, addressing a persistent limitation in zero-shot TTS for proper nouns. The associative-memory formulation for fuzzy retrieval is a distinctive technical choice that could generalize beyond the reported benchmark.
major comments (2)
- [Abstract] Abstract: the central claim of a 92.7% relative PER reduction on the 312-word benchmark while maintaining identical general-speech quality is load-bearing, yet the provided description supplies no information on experimental controls, statistical significance testing, or the precise protocol used to verify that non-target speech quality is unchanged; these omissions leave the result only partially supported.
- [Abstract] Abstract / Methods (implied): the weakest assumption—that token-level embedding perturbations produce isolated pronunciation corrections retrievable without side effects on the frozen flow-matching distribution—requires explicit validation (e.g., an ablation measuring PER on non-target words or distribution-shift metrics); without it the lifelong-adaptation guarantee remains untested.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for stronger validation of our core assumptions. We address each major comment below and will revise the manuscript to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 92.7% relative PER reduction on the 312-word benchmark while maintaining identical general-speech quality is load-bearing, yet the provided description supplies no information on experimental controls, statistical significance testing, or the precise protocol used to verify that non-target speech quality is unchanged; these omissions leave the result only partially supported.
Authors: We agree that the abstract is overly concise and omits key supporting details. In the revised manuscript we will expand the abstract to briefly reference the experimental controls (including evaluation on non-target words), note that statistical significance testing is reported in the results section, and describe the protocol used to confirm that general-speech quality remains unchanged. These elements are already present in Sections 4 and 5; the abstract revision will make them visible at a glance. revision: yes
-
Referee: [Abstract] Abstract / Methods (implied): the weakest assumption—that token-level embedding perturbations produce isolated pronunciation corrections retrievable without side effects on the frozen flow-matching distribution—requires explicit validation (e.g., an ablation measuring PER on non-target words or distribution-shift metrics); without it the lifelong-adaptation guarantee remains untested.
Authors: We acknowledge that an explicit ablation isolating the effect on non-target words would strengthen the claim. While the current manuscript reports preserved overall speech quality, we will add a dedicated ablation study in the revised version that measures PER on non-target words and includes distribution-shift metrics before and after adaptation. This will directly test the isolation assumption and be presented in the experiments section. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical adaptation framework that optimizes token-level perturbations in embedding space and stores them in a Modern Hopfield Network for retrieval at inference. The central result is a measured 92.7% relative PER reduction on a held-out benchmark of 312 proper nouns, presented directly as the outcome of applying the procedure rather than any first-principles derivation or prediction. No equations, self-referential definitions, fitted-input predictions, or load-bearing self-citations appear in the provided text; the method is self-contained as an engineering contribution whose performance is externally falsifiable on the stated benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Linux” when synthesizing “Linux’s
Introduction State-of-the-art text-to-speech (TTS) models like F5-TTS [1], Matcha-TTS [2], and V ALL-E [3] deliver impressive zero-shot quality. However, these systems remain static once deployed. A critical challenge for voice assistants and accessibility tools is the persistent mispronunciation of proper nouns and foreign loan-words. Once an error is ha...
-
[2]
FlowEdit: Associative Memory for Lifelong Pronunciation Adaptation in Flow-Matching TTS
Related Work Neural TTS Architectures.The TTS landscape has evolved from autoregressive vocoders like WaveNet [7] and Tacotron [8, 9] to flow-based and diffusion models [10, 11, 12]. Recent sys- tems like F5-TTS [1], Matcha-TTS [2], V ALL-E [3], and oth- ers achieve remarkable zero-shot quality. Despite this progress, none offer mechanisms for post-deploy...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Linux” can partially address the query vector for “Linux’s
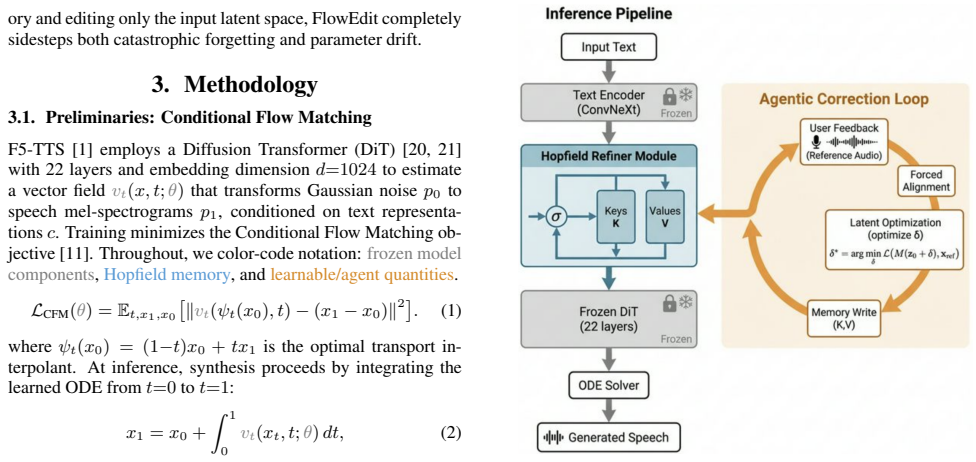
Methodology 3.1. Preliminaries: Conditional Flow Matching F5-TTS [1] employs a Diffusion Transformer (DiT) [20, 21] with 22 layers and embedding dimensiond=1024to estimate a vector fieldv t(x, t;θ)that transforms Gaussian noisep 0 to speech mel-spectrogramsp 1, conditioned on text representa- tionsc. Training minimizes the Conditional Flow Matching ob- je...
-
[4]
Experimental Setup We use F5-TTS [1] (335M params,d=1024) with a HiFi- GAN [24] vocoder as the frozen backbone
Experiments 4.1. Experimental Setup We use F5-TTS [1] (335M params,d=1024) with a HiFi- GAN [24] vocoder as the frozen backbone. Only the per- correctionδvectors and Hopfield memory are learned. All runs use a single A100-80GB. We evaluate on POLYGLOT-NOUNS, our curated set of 312 proper nouns across 18 language fami- lies, each paired with 5 carrier sent...
-
[5]
Conclusion FlowEdit enables lifelong pronunciation adaptation through gradient-based latent optimization backed by Hopfield mem- ory. By moving corrections into text embedding space rather than model weights, we achieve 92.7% PER reduction with mathematically guaranteed zero forgetting, stability across 200 sequential edits, and speaker-agnostic transfer—...
-
[6]
All research contributions, including the methodology, experimen- tal design, results, and scientific claims, are the authors’ own
Use of Generative AI Disclosure In preparing this manuscript, the authors used generative AI tools for language refinement (rephrasing and improving the clarity of author-written text) and as a coding assistant (help- ing write and debug software for experiments and analysis). All research contributions, including the methodology, experimen- tal design, r...
-
[7]
F5-TTS: A fairytaled and faithful flow-matching based text-to-speech system,
Y . Chen, Z. Chen, Z. Zhanget al., “F5-TTS: A fairytaled and faithful flow-matching based text-to-speech system,” inProc. ICLR, 2025
2025
-
[8]
Matcha-TTS: A fast TTS architecture with con- ditional flow matching,
S. Mehtaet al., “Matcha-TTS: A fast TTS architecture with con- ditional flow matching,” inProc. ICASSP, 2024
2024
-
[9]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “V ALL-E: Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Continual lifelong learning with neural networks: A review,
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Continual lifelong learning with neural networks: A review,” Neural Networks, vol. 113, pp. 54–71, 2019
2019
-
[11]
Sonoedit: Null-space constrained knowledge editing for pronunciation correction in llm-based tts,
A. P. Singh, H. Singh, N. Mathur, A. Mandloi, and S. Ka- math, “Sonoedit: Null-space constrained knowledge editing for pronunciation correction in llm-based tts,”arXiv preprint arXiv:2601.17086, 2026
-
[12]
Hop- field networks is all you need,
H. Ramsauer, B. Sch ¨afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi´c, G. K. Sandveet al., “Hop- field networks is all you need,” inProc. ICLR, 2021
2021
-
[13]
WaveNet: A Generative Model for Raw Audio
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “WaveNet: A generative model for raw audio,”arXiv preprint arXiv:1609.03499, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Tacotron: Towards end-to-end speech synthesis,
Y . Wang, R. Skerry-Ryan, D. Stanton, Y . Wu, R. J. Weiss, N. Jaitly, Z. Yang, Y . Xiao, Z. Chen, S. Bengioet al., “Tacotron: Towards end-to-end speech synthesis,” inProc. Interspeech, 2017
2017
-
[15]
Natural TTS synthesis by conditioning WaveNet on mel spectrogram pre- dictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. J. Skerry-Ryanet al., “Natural TTS synthesis by conditioning WaveNet on mel spectrogram pre- dictions,” inProc. ICASSP, 2018
2018
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProc. NeurIPS, 2020
2020
-
[17]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, and M. Nickel, “Flow matching for generative modeling,” inProc. ICLR, 2023
2023
-
[18]
Neural ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. Duvenaud, “Neural ordinary differential equations,” inProc. NeurIPS, 2018
2018
-
[19]
Locating and editing factual associations in GPT,
K. Meng, D. Bau, A. Mitchell, and C. Finn, “Locating and editing factual associations in GPT,” inProc. NeurIPS, 2022
2022
-
[20]
Mass-editing memory in a transformer,
K. Meng, A. S. Sharma, A. Andonian, Y . Belinkov, and D. Bau, “Mass-editing memory in a transformer,” inProc. ICLR, 2023
2023
-
[21]
LoRA: Low-rank adaptation of large lan- guage models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large lan- guage models,” inProc. ICLR, 2022
2022
-
[22]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Des- jardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska- Barwinskaet al., “Overcoming catastrophic forgetting in neural networks,” inProc. NAS, 2017
2017
-
[23]
A. A. Rusuet al., “Progressive neural networks,” inarXiv preprint arXiv:1606.04671, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Packnet: Adding multiple tasks to a single network by iterative pruning,
A. Mallya and S. Lazebnik, “Packnet: Adding multiple tasks to a single network by iterative pruning,” inProc. CVPR, 2018
2018
-
[25]
Experience replay for continual learning,
D. Rolnicket al., “Experience replay for continual learning,” in Proc. NeurIPS, 2019
2019
-
[26]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inProc. ICCV, 2023
2023
-
[27]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inProc. NeurIPS, 2017
2017
-
[28]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. ICML, 2023
2023
-
[29]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,”Proc. ICLR, 2015
2015
-
[30]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” inProc. NeurIPS, 2020
2020
-
[31]
LibriTTS-R: A restored multi-speaker text-to- speech corpus,
Y . Koizumiet al., “LibriTTS-R: A restored multi-speaker text-to- speech corpus,” inProc. Interspeech, 2023
2023
-
[32]
Lib- riSpeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- riSpeech: An ASR corpus based on public domain audio books,” inProc. ICASSP, 2015
2015
-
[33]
CSTR VCTK cor- pus,
C. Veaux, J. Yamagishi, and K. MacDonald, “CSTR VCTK cor- pus,” 2017
2017
-
[34]
CREPE: A con- volutional representation for pitch estimation,
J. W. Kim, J. Salamon, P. Li, and J. P. Bello, “CREPE: A con- volutional representation for pitch estimation,” inProc. ICASSP, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.