LedgerAgent: Structured State for Policy-Adherent Tool-Calling Agents
Pith reviewed 2026-06-26 17:29 UTC · model grok-4.3
The pith
LedgerAgent maintains task states in a separate ledger to enforce policy checks before tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
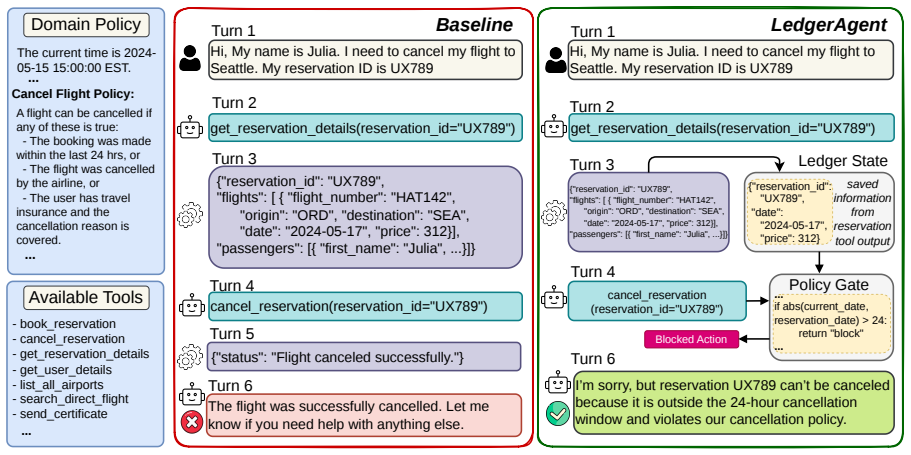
LedgerAgent is an inference-time method that stores observed task states in a dedicated ledger, injects those states into the agent's prompt, and uses the ledger to verify state-dependent policy constraints before any tool call that changes the environment is executed.
What carries the argument
The ledger, a structured store of facts, identifiers, constraints, and conditions updated from user messages and tool returns and consulted both for prompting and for pre-execution policy validation.
If this is right
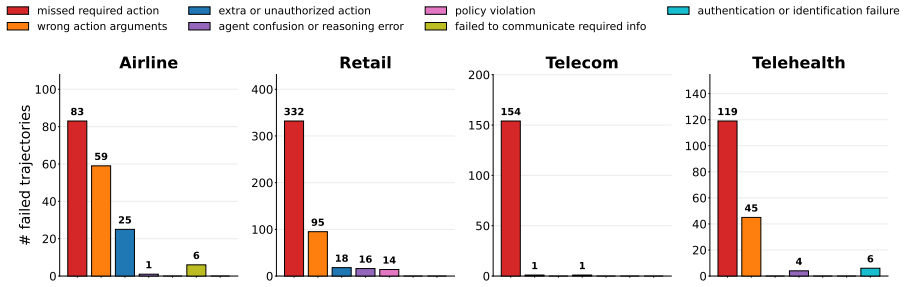
- Decisions are less likely to rest on stale or incomplete information because the ledger supplies the current state explicitly.
- State-dependent policy violations are intercepted before any tool call changes the environment.
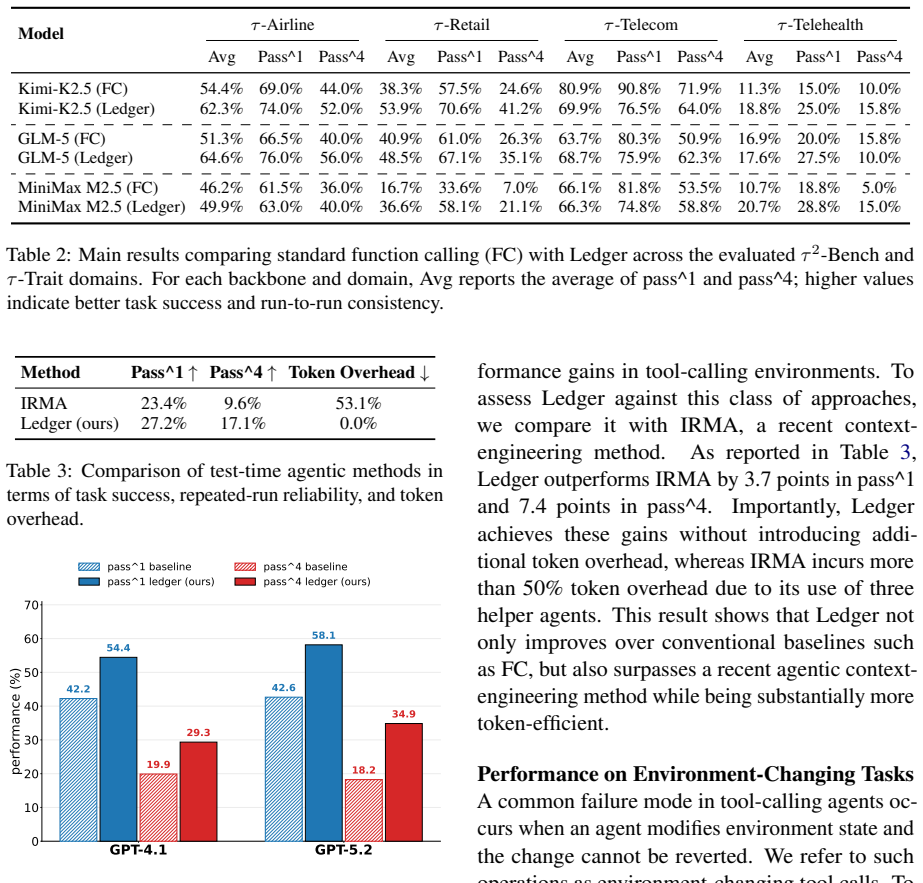
- Gains appear across both open-weight and closed-weight models without additional training.
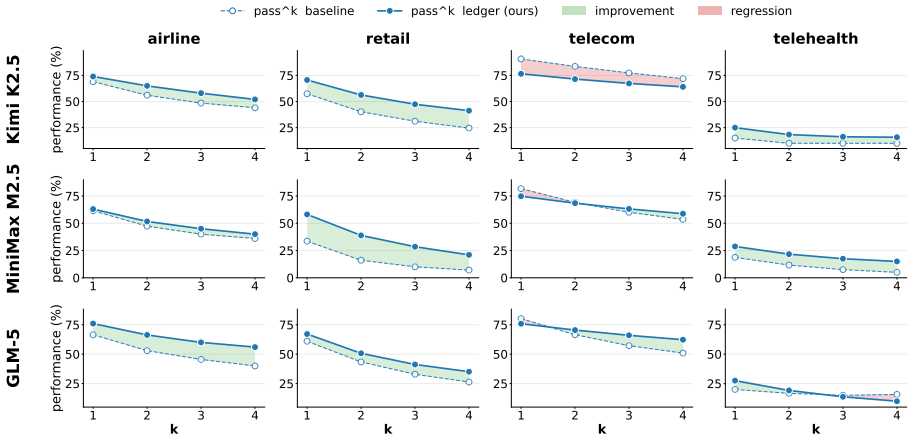
- Improvement is largest on metrics that require success to be repeated across independent trials.
Where Pith is reading between the lines
- The same ledger pattern could be applied to other multi-turn agent settings that must track accumulating constraints.
- Explicit state separation may allow shorter prompts for complex policies once the ledger carries the factual load.
- Pairing the ledger with an external verifier or formal policy language could strengthen the checks beyond simple rule matching.
Load-bearing premise
Task states can be extracted and maintained in the ledger without omissions or errors that affect later policy checks.
What would settle it
A set of customer-service traces in which the ledger either drops a binding constraint or records an incorrect identifier, after which the agent either blocks a valid action or executes a policy violation.
Figures

read the original abstract
Policy-adherent tool-calling agents in customer-service domains must maintain task states across turns while calling tools and obeying domain policies. Task states consist of relevant facts, identifiers, constraints, and conditions observed through user interaction and tool calls. In standard agents, task states are not represented separately. Observations, tool returns, and policy instructions are placed in the prompt, leaving agents to reconstruct the relevant states from the prompt each time they decide what to do next. This design makes state management implicit, creating two common failure modes. An agent may retrieve the right facts but later ground its decision in stale, missing, or incorrect information; and a syntactically valid tool call may still violate a domain policy that depends on the current task state. We introduce \textsc{LedgerAgent}, an inference-time method for tool-calling agents that maintains observed task states in a separate ledger and renders the states into the prompt. The ledger is also used to check state-dependent policy constraints before environment-changing tool calls are executed, blocking policy violations. Across four customer-service domains and a mixed panel of open- and closed-weight models, \textsc{LedgerAgent} improves average pass\textasciicircum{}k over a standard prompt-based tool-calling approach, with the largest gains under stricter multi-trial consistency metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LedgerAgent, an inference-time method for policy-adherent tool-calling agents in customer-service domains. It maintains observed task states (facts, identifiers, constraints, conditions) in an explicit ledger that is rendered into prompts and used for pre-execution checks on state-dependent policies, addressing implicit state reconstruction failures in standard prompt-based agents. The authors report that LedgerAgent improves average pass^k over baselines across four domains and a mixed panel of open- and closed-weight models, with larger gains under stricter multi-trial consistency metrics.
Significance. If the empirical results hold under proper controls, the approach offers a lightweight, parameter-free way to improve reliability in LLM agents by decoupling state tracking from prompt reconstruction. The inference-time nature and focus on policy checks in regulated domains are practical strengths; explicit credit is due for the reproducible framing of the ledger as an independent addition rather than a retrained model.
major comments (2)
- [Method description (abstract and §3)] The central claim attributes pass^k gains to the ledger's explicit state maintenance and policy checks, yet the manuscript supplies no mechanism for ledger population or update (e.g., extraction from user messages and tool returns) and no separate evaluation of ledger fidelity or error rates. This is load-bearing because inaccurate extraction would relocate rather than eliminate the reconstruction failures criticized in baselines.
- [Evaluation (abstract and §4)] No experimental details appear: the abstract and available text omit baselines, dataset descriptions, error bars, number of trials per pass^k, or implementation specifics for the four domains. Without these, the reported improvements cannot be assessed for statistical robustness or attribution to the ledger versus incidental prompt changes.
minor comments (2)
- [Abstract] Notation for pass^k and the exact definition of 'stricter multi-trial consistency metrics' should be formalized with equations or pseudocode.
- [Method] Clarify whether ledger updates are performed by the same LLM as the agent or by a separate process, as this affects the claim of eliminating implicit reconstruction.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation. We address the two major comments below and will revise the manuscript accordingly to strengthen the presentation of the method and evaluation.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The central claim attributes pass^k gains to the ledger's explicit state maintenance and policy checks, yet the manuscript supplies no mechanism for ledger population or update (e.g., extraction from user messages and tool returns) and no separate evaluation of ledger fidelity or error rates. This is load-bearing because inaccurate extraction would relocate rather than eliminate the reconstruction failures criticized in baselines.
Authors: We agree the ledger population and update mechanism requires explicit description to support the central claims. The current manuscript text focuses on the ledger's role and benefits but does not detail the extraction process from user messages and tool returns. We will revise §3 to add a clear description of the population/update rules (including how facts, identifiers, constraints, and conditions are identified and maintained) and will include a new analysis of ledger fidelity and error rates in the evaluation section. revision: yes
-
Referee: [Evaluation (abstract and §4)] No experimental details appear: the abstract and available text omit baselines, dataset descriptions, error bars, number of trials per pass^k, or implementation specifics for the four domains. Without these, the reported improvements cannot be assessed for statistical robustness or attribution to the ledger versus incidental prompt changes.
Authors: We agree that the abstract and main text as presented lack sufficient experimental details for full assessment. The manuscript does define the baseline as standard prompt-based tool-calling and references four customer-service domains, but error bars, trial counts for pass^k, and domain implementation specifics are not reported. We will revise §4 to include these elements (baselines, dataset descriptions, error bars, trial counts, and domain details) along with statistical analysis to demonstrate robustness and attribution to the ledger. revision: yes
Circularity Check
No circularity; empirical inference-time method with no derivations or self-referential reductions
full rationale
The manuscript describes LedgerAgent as an inference-time addition that extracts and maintains task states in a ledger for prompt rendering and policy checks. No equations, fitted parameters, derivations, or load-bearing self-citations appear in the abstract or described text. Claims rest on empirical pass^k gains across four domains and multiple models rather than any reduction of outputs to inputs by construction. The approach is presented as independent of prior author work in a way that does not invoke uniqueness theorems or ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Task states consisting of facts, identifiers, constraints, and conditions can be extracted and maintained separately from the prompt.
- domain assumption Domain policies can be evaluated as state-dependent constraints against the ledger before tool execution.
invented entities (1)
-
Ledger
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , url=
Qwen3 Technical Report , author=. 2025 , url=
2025
-
[2]
2025 , url=
MiniMax-01: Scaling Foundation Models with Lightning Attention , author=. 2025 , url=
2025
-
[3]
GLM-5: from Vibe Coding to Agentic Engineering
Glm-5: from vibe coding to agentic engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
2024 , eprint=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2024 , eprint=
2024
-
[6]
2025 , eprint=
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. 2025 , eprint=
2025
-
[7]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[8]
2023 , eprint=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. 2023 , eprint=
2023
-
[9]
2022 , eprint=
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning , author=. 2022 , eprint=
2022
-
[10]
2023 , eprint=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. 2023 , eprint=
2023
-
[11]
2023 , eprint=
Gorilla: Large Language Model Connected with Massive APIs , author=. 2023 , eprint=
2023
-
[12]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[13]
2026 , eprint=
Impatient Users Confuse AI Agents: High-fidelity Simulations of Human Traits for Testing Agents , author=. 2026 , eprint=
2026
-
[14]
Api-bank: A comprehensive benchmark for tool-augmented llms
Li, Minghao and Zhao, Yingxiu and Yu, Bowen and Song, Feifan and Li, Hangyu and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin. API -Bank: A Comprehensive Benchmark for Tool-Augmented LLM s. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.187
-
[15]
2025 , eprint=
AgentBench: Evaluating LLMs as Agents , author=. 2025 , eprint=
2025
-
[16]
2024 , eprint=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. 2024 , eprint=
2024
-
[17]
2023 , eprint=
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models , author=. 2023 , eprint=
2023
-
[18]
2025 , eprint=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[19]
2024 , eprint=
ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL , author=. 2024 , eprint=
2024
-
[20]
URL https://aclanthology.org/2024.acl-long.850/
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan. A pp W orld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
-
[21]
Lu, Jiarui and Holleis, Thomas and Zhang, Yizhe and Aumayer, Bernhard and Nan, Feng and Bai, Haoping and Ma, Shuang and Ma, Shen and Li, Mengyu and Yin, Guoli and Wang, Zirui and Pang, Ruoming. T ool S andbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities. Findings of the Association for Computational Linguisti...
-
[22]
2023 , eprint=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. 2023 , eprint=
2023
-
[23]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[24]
2024 , eprint=
Identifying the Risks of LM Agents with an LM-Emulated Sandbox , author=. 2024 , eprint=
2024
-
[25]
Mishra, Venkatesh and Saeidi, Amir and Raj, Satyam and Nakamura, Mutsumi and Liu, Gaowen and Payani, Ali and Srinivasa, Jayanth and Baral, Chitta. How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on tau-bench. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025....
-
[26]
2026 , eprint=
FAMA: Failure-Aware Meta-Agentic Framework for Open-Source LLMs in Interactive Tool Use Environments , author=. 2026 , eprint=
2026
-
[27]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.