MindAlign: Decoding Inner Speech from fMRI Signals via Multimodal Embedding Alignment under Limited Data
Pith reviewed 2026-06-27 04:08 UTC · model grok-4.3
The pith
A two-stage alignment maps fMRI signals to semantic space so a frozen multimodal language model can generate text from inner speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
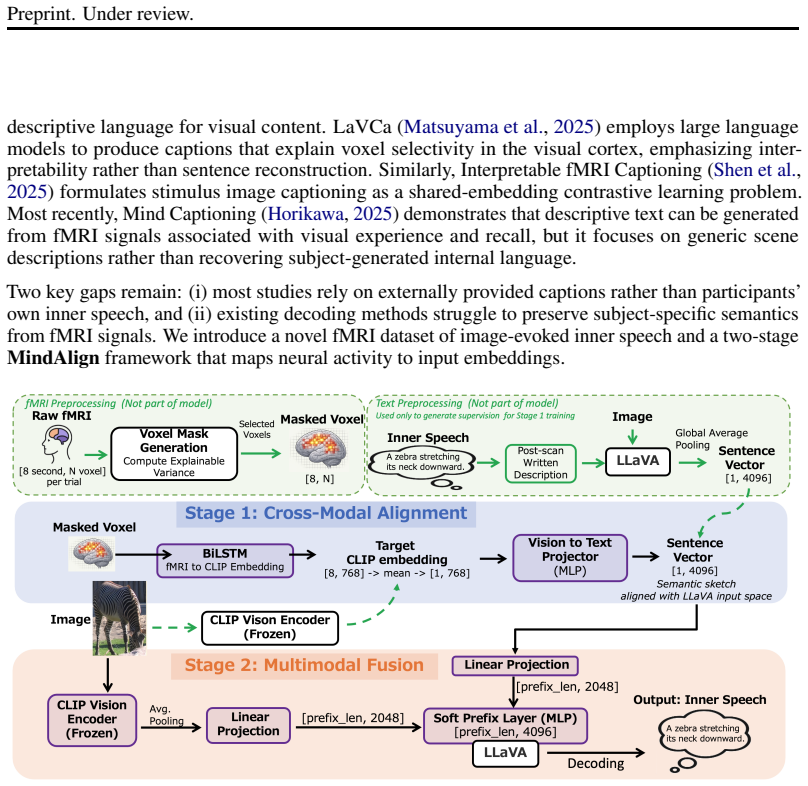
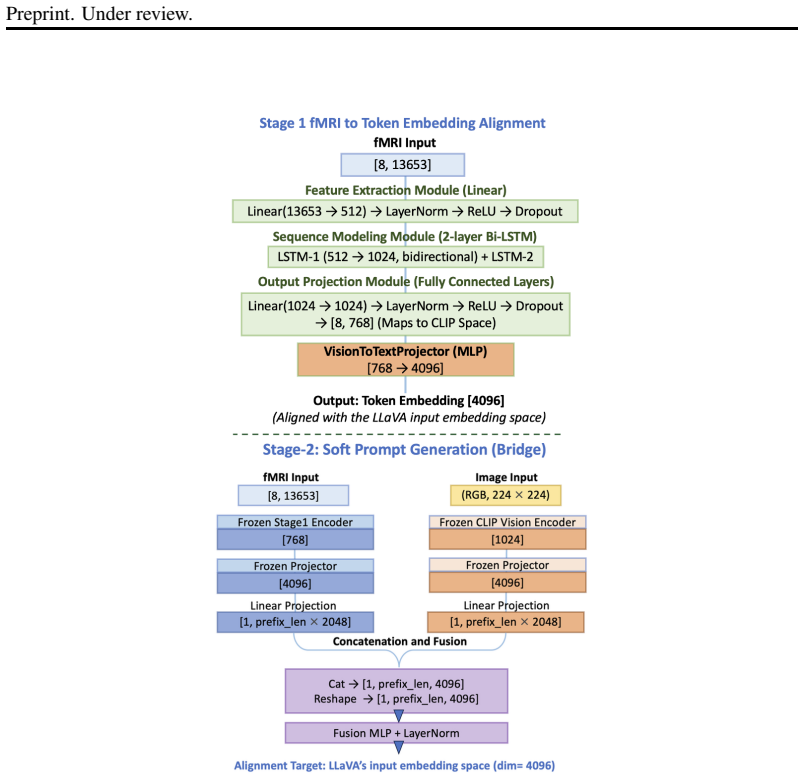
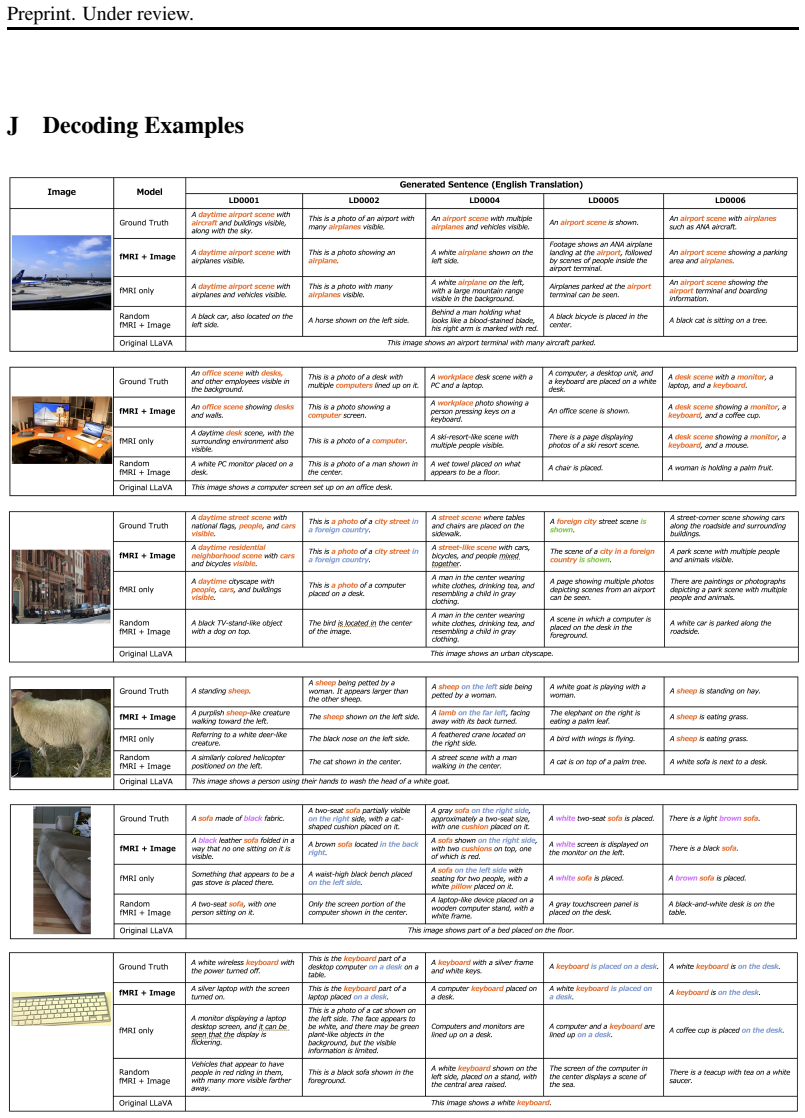
MindAlign learns a subject-specific neural-semantic alignment that maps fMRI activity into a shared multimodal semantic space, extracting a latent semantic sketch of the internally generated sentence. This sketch is integrated with visual context to prompt a frozen multimodal language model for free-form generation. The approach outperforms fMRI-only and random baselines on silent image description data and shows that the learned semantic-to-language projection generalizes across subjects when paired with subject-specific neural alignment, indicating that neural signals modulate semantic content beyond image-driven priors.
What carries the argument
A decoupled two-stage brain-to-language framework that first performs subject-specific neural-semantic alignment to produce a latent semantic sketch and then integrates it with a frozen multimodal language model.
If this is right
- The method outperforms fMRI-only and random baselines on fMRI data from silent image description tasks.
- The learned semantic-to-language projection generalizes across subjects when used with subject-specific neural alignment.
- Neural signals modulate semantic content beyond what image-driven priors alone would supply.
- The framework supports open-ended text generation without task-specific fine-tuning of the underlying language model.
Where Pith is reading between the lines
- The separation of neural alignment from language generation could let the same alignment step pair with different language models as they improve.
- Cross-subject transfer of the projection step suggests semantic representations extracted from brain signals may have a common structure across individuals.
- The design may extend to inner speech tasks without visual stimuli if the semantic sketch proves sufficiently independent of image context.
Load-bearing premise
The first-stage alignment extracts a latent semantic sketch from fMRI that is sufficiently independent of image-driven priors for the second stage to generate accurate free-form text from inner speech alone.
What would settle it
An experiment in which text generation accuracy on fMRI from inner speech drops to random baseline levels when visual context is withheld or when the alignment is tested on held-out subjects without retraining.
Figures


read the original abstract
Decoding inner speech from non-invasive brain signals remains a fundamental challenge due to the absence of overt linguistic output, limited training data, and large inter-subject variability. Existing brain-to-text approaches often rely on task-specific decoder fine-tuning, which restricts scalability and complicates adaptation to new participants. We propose MindAlign, a decoupled two-stage brain-to-language framework that enables open-ended text generation from fMRI signals without modifying the underlying language model. The first stage learns a subject-specific neural-semantic alignment that maps fMRI activity into a shared multimodal semantic space, extracting a latent semantic sketch of the internally generated sentence. The second stage integrates this sketch with visual context to prompt a frozen multimodal language model for free-form generation. Experiments on fMRI data collected during silent image description demonstrate that the proposed approach consistently outperforms fMRI-only and random baselines. We further show that the learned semantic-to-language projection can generalize across subjects, enabling effective decoding when paired with subject-specific neural alignment. These results indicate that neural signals modulate semantic content beyond image-driven priors, supporting a scalable and modular direction for brain-to-text decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MindAlign, a decoupled two-stage brain-to-text framework for decoding inner speech from fMRI. Stage 1 learns a subject-specific neural-semantic alignment mapping fMRI activity into a shared multimodal embedding space to produce a latent semantic sketch. Stage 2 combines this sketch with visual context to prompt a frozen multimodal language model for free-form text generation. Experiments on silent image-description fMRI data claim consistent outperformance over fMRI-only and random baselines plus cross-subject generalization of the semantic-to-language projection, supporting that neural signals add semantic content beyond image-driven priors.
Significance. If the central empirical claims hold after appropriate controls, the modular design (no LM fine-tuning, subject-specific alignment only) would address key scalability barriers in brain-to-text decoding under limited data and high inter-subject variability, offering a practical path toward open-ended inner-speech decoding.
major comments (2)
- [Experiments] Experiments section: no ablation is reported in which the first-stage mapper is trained solely on image embeddings (or image-driven priors) and then compared against the fMRI-derived sketch when both are fed to the frozen MLLM. Without this control, outperformance over the stated baselines and the Abstract claim that “neural signals modulate semantic content beyond image-driven priors” remain indistinguishable from residual image correlation in the fMRI voxels.
- [Abstract] Abstract and Experiments: the central claims of “consistent outperformance” and “cross-subject generalization” are stated without any quantitative metrics, dataset sizes, error bars, or baseline-construction details, leaving the load-bearing empirical support unverifiable from the provided text.
minor comments (2)
- [Abstract] Abstract does not specify the multimodal embedding space, the exact loss used for alignment, or how visual context is supplied to the MLLM.
- [Introduction] Notation for the “latent semantic sketch” and the “semantic-to-language projection” is introduced without an accompanying equation or diagram in the early sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the manuscript to incorporate the suggested controls and clarifications.
read point-by-point responses
-
Referee: [Experiments] Experiments section: no ablation is reported in which the first-stage mapper is trained solely on image embeddings (or image-driven priors) and then compared against the fMRI-derived sketch when both are fed to the frozen MLLM. Without this control, outperformance over the stated baselines and the Abstract claim that “neural signals modulate semantic content beyond image-driven priors” remain indistinguishable from residual image correlation in the fMRI voxels.
Authors: We agree that this ablation is required to rigorously support the claim that neural signals contribute semantic content beyond image-driven priors. In the revised manuscript we will add the requested control: the first-stage mapper will be trained on image embeddings alone (derived from the same visual stimuli used in the fMRI sessions) and the resulting sketches will be compared directly against fMRI-derived sketches when both are used to prompt the frozen MLLM. This will quantify any additional benefit provided by the neural data. revision: yes
-
Referee: [Abstract] Abstract and Experiments: the central claims of “consistent outperformance” and “cross-subject generalization” are stated without any quantitative metrics, dataset sizes, error bars, or baseline-construction details, leaving the load-bearing empirical support unverifiable from the provided text.
Authors: The Experiments section of the full manuscript already reports dataset sizes (number of subjects and trials), quantitative metrics with error bars obtained via cross-validation, and explicit baseline-construction procedures. To improve verifiability from the abstract itself, we will revise the abstract to include the key numerical results (e.g., relative improvements over baselines and cross-subject generalization performance). revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract and available description present a two-stage empirical framework (neural-semantic alignment followed by prompting a frozen MLLM) whose performance claims rest on outperforming fMRI-only and random baselines in silent image-description fMRI data. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems are referenced that would reduce any claimed prediction or result to an input quantity by construction. The central claim that neural signals modulate semantic content beyond image priors is presented as an empirical observation rather than a definitional or fitted tautology, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A shared multimodal semantic space exists that can align fMRI activity, language, and visual context.
Reference graph
Works this paper leans on
-
[1]
Reconstructing the Mind's Eye: f
Paul Steven Scotti and Atmadeep Banerjee and Jimmie Goode and Stepan Shabalin and Alex Nguyen and Cohen Ethan and Aidan James Dempster and Nathalie Verlinde and Elad Yundler and David Weisberg and Kenneth Norman and Tanishq Mathew Abraham , booktitle=. Reconstructing the Mind's Eye: f. 2023 , url=
2023
-
[2]
Norman and Tanishq Mathew Abraham , booktitle=
Paul Steven Scotti and Mihir Tripathy and Cesar Torrico and Reese Kneeland and Tong Chen and Ashutosh Narang and Charan Santhirasegaran and Jonathan Xu and Thomas Naselaris and Kenneth A. Norman and Tanishq Mathew Abraham , booktitle=. MindEye2: Shared-Subject Models Enable f. 2024 , url=
2024
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mindbridge: A cross-subject brain decoding framework , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Weikang Qiu and Zheng Huang and Haoyu Hu and Aosong Feng and Yujun Yan and Rex Ying , booktitle=. Mind. 2025 , url=
2025
-
[5]
Nature communications , volume=
Toward a universal decoder of linguistic meaning from brain activation , author=. Nature communications , volume=. 2018 , publisher=
2018
-
[6]
arXiv preprint arXiv:2405.07840 , year=
Open-vocabulary Auditory Neural Decoding Using fMRI-prompted LLM , author=. arXiv preprint arXiv:2405.07840 , year=
-
[7]
Nature neuroscience , volume=
A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence , author=. Nature neuroscience , volume=. 2022 , publisher=
2022
-
[8]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages =
Mishra, Abhijit and Shukla, Shreya and Torres, Jose and Gwizdka, Jacek and Roychowdhury, Shounak , title =. Findings of the Association for Computational Linguistics: NAACL 2025 , pages =. 2025 , url =
2025
-
[9]
Communications Biology , volume=
Generative language reconstruction from brain recordings , author=. Communications Biology , volume=. 2025 , publisher=
2025
-
[10]
Visual Decoding and Reconstruction via
Dongyang Li and Chen Wei and Shiying Li and Jiachen Zou and Quanying Liu , booktitle=. Visual Decoding and Reconstruction via. 2024 , url=
2024
-
[11]
IEEE Transactions on Medical Imaging , year =
Ma, Yongqiang and Liu, Yulong and Chen, Liangjun and Zhu, Guibo and Chen, Badong and Zheng, Nanning , title =. IEEE Transactions on Medical Imaging , year =
-
[12]
EMNLP , year=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. EMNLP , year=
-
[13]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[14]
Information processing & management , volume=
Term-weighting approaches in automatic text retrieval , author=. Information processing & management , volume=. 1988 , publisher=
1988
-
[15]
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
Reimers, Nils and Gurevych, Iryna. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.365
-
[16]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[17]
, author=
String comparator metrics and enhanced decision rules in the fellegi-sunter model of record linkage. , author=. 1990 , publisher=
1990
-
[18]
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[19]
ICML , year=
Learning transferable visual models from natural language supervision , author=. ICML , year=
-
[20]
Nature Neuroscience , volume=
Semantic reconstruction of continuous language from non-invasive brain recordings , author=. Nature Neuroscience , volume=. 2023 , doi=
2023
-
[21]
arXiv preprint arXiv:2406.07584 , year=
BrainChat: Decoding Semantic Information from fMRI using Vision-language Pretrained Models , author=. arXiv preprint arXiv:2406.07584 , year=
-
[22]
arXiv preprint arXiv:2405.17720 , year=
MindFormer: Semantic Alignment of Multi-Subject fMRI for Brain Decoding , author=. arXiv preprint arXiv:2405.17720 , year=
-
[23]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
UniCoRN: Unified Cognitive Signal ReconstructioN bridging cognitive signals and human language , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2023
-
[24]
arXiv preprint arXiv:2409.19710 , year=
A multimodal LLM for the non-invasive decoding of spoken text from brain recordings , author=. arXiv preprint arXiv:2409.19710 , year=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
Cross-Modal Cloze Task: A New Task to Brain-to-Word Decoding , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=. 2022 , organization=
2022
-
[27]
A Call for Clarity in Reporting BLEU Scores
Post, Matt. A Call for Clarity in Reporting BLEU Scores. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018
2018
-
[28]
Soviet physics doklady , volume=
Binary codes capable of correcting deletions, insertions, and reversals , author=. Soviet physics doklady , volume=. 1966 , organization=
1966
-
[29]
Frontiers in Human Neuroscience , volume=
Brain Decoding-Classification of Hand Written Digits from fMRI Data Employing Bayesian Networks , author=. Frontiers in Human Neuroscience , volume=. 2016 , publisher=
2016
-
[30]
Proceedings of the Cognitive Computational Neuroscience Conference (CCN) , year=
Visual Feature-Based Brain Decoding Yields Weight Maps Better Aligned with Scene Understanding than Classification , author=. Proceedings of the Cognitive Computational Neuroscience Conference (CCN) , year=
-
[31]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[32]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[33]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[34]
chr F : character n-gram F -score for automatic MT evaluation
Popovi \'c , Maja. chr F : character n-gram F -score for automatic MT evaluation. Proceedings of the Tenth Workshop on Statistical Machine Translation. 2015. doi:10.18653/v1/W15-3049
-
[35]
Bleu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[36]
The Thirteenth International Conference on Learning Representations , year=
Toward Generalizing Visual Brain Decoding to Unseen Subjects , author=. The Thirteenth International Conference on Learning Representations , year=
-
[37]
2014 , eprint=
Microsoft COCO: Common Objects in Context , author=. 2014 , eprint=
2014
-
[38]
arXiv preprint arXiv:2501.02570 , year=
Decoding fMRI Data into Captions using Prefix Language Modeling , author=. arXiv preprint arXiv:2501.02570 , year=
-
[39]
arXiv preprint arXiv:2101.00190 , year=
Prefix-tuning: Optimizing continuous prompts for generation , author=. arXiv preprint arXiv:2101.00190 , year=
-
[40]
Communications biology , volume=
Small sample sizes reduce the replicability of task-based fMRI studies , author=. Communications biology , volume=. 2018 , publisher=
2018
-
[41]
2016 , publisher=
Deep Learning , author=. 2016 , publisher=
2016
-
[42]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , year=
Sentence-BERT: Sentence embeddings using Siamese BERT-networks , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , year=
2019
-
[43]
Neural computation , volume=
Long short-term memory , author=. Neural computation , volume=. 1997 , publisher=
1997
-
[44]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[45]
Publications Manual , year = "1983", publisher =
1983
-
[46]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[47]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[48]
Dan Gusfield , title =. 1997
1997
-
[49]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[50]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[51]
2025 , note =
Florian Reichel , title =. 2025 , note =
2025
-
[52]
Frontiers in Computational Neuroscience , volume=
Measuring the performance of neural models , author=. Frontiers in Computational Neuroscience , volume=
-
[53]
Advances in Neural Information Processing Systems , volume=
How linear are auditory cortical responses? , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Network: Computation in Neural Systems , volume=
Quantifying variability in neural responses and its application for the validation of model predictions , author=. Network: Computation in Neural Systems , volume=
-
[55]
Huth and Gallant Lab , title =
Alexander G. Huth and Gallant Lab , title =
-
[56]
Journal of big data , volume=
A survey on image data augmentation for deep learning , author=. Journal of big data , volume=. 2019 , publisher=
2019
-
[57]
NeuroImage: Clinical , volume=
Data augmentation with Mixup: Enhancing performance of a functional neuroimaging-based prognostic deep learning classifier in recent onset psychosis , author=. NeuroImage: Clinical , volume=. 2022 , publisher=
2022
-
[58]
arXiv preprint arXiv:1710.09412 , year=
mixup: Beyond empirical risk minimization , author=. arXiv preprint arXiv:1710.09412 , year=
-
[59]
arXiv preprint arXiv:2502.13606 , year=
LaVCa: LLM-assisted Visual Cortex Captioning , author=. arXiv preprint arXiv:2502.13606 , year=
-
[60]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Interpretable fMRI Captioning via Contrastive Learning , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
2025
-
[61]
arXiv preprint arXiv:2505.01670 , year=
Efficient Multi Subject Visual Reconstruction from fMRI Using Aligned Representations , author=. arXiv preprint arXiv:2505.01670 , year=
-
[62]
Science Advances , volume=
Mind captioning: Evolving descriptive text of mental content from human brain activity , author=. Science Advances , volume=. 2025 , publisher=
2025
-
[63]
arXiv preprint arXiv:1508.01991 , year=
Bidirectional LSTM-CRF models for sequence tagging , author=. arXiv preprint arXiv:1508.01991 , year=
-
[64]
Rethinking Cross-Subject Data Splitting for Brain-to-Text Decoding
Yin, Congchi and Yu, Qian and Fang, Zhiwei and Peng, Changping and Li, Piji. Rethinking Cross-Subject Data Splitting for Brain-to-Text Decoding. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.289
-
[65]
Advances in Neural Information Processing Systems , year =
Brain-Inspired fMRI-to-Text Decoding via Incremental and Wrap-Up Language Modeling , author =. Advances in Neural Information Processing Systems , year =
-
[66]
arXiv preprint arXiv:2502.17480 , year =
Brain-to-Text Decoding: A Non-invasive Approach via Typing , author =. arXiv preprint arXiv:2502.17480 , year =. 2502.17480 , archivePrefix =
-
[67]
arXiv preprint arXiv:2511.21740 , year =
A Cross-Species Neural Foundation Model for End-to-End Speech Decoding , author =. arXiv preprint arXiv:2511.21740 , year =. 2511.21740 , archivePrefix =
-
[68]
Journal of Urban Management , volume =
Hmamouche, Youssef and Chihab, Ismail and Kdouri, Lahoucine and. Journal of Urban Management , volume =. 2026 , publisher =. doi:10.1016/j.jum.2025.09.002 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.