Machine-Coached Policy Revision in Adaptive Agent-Based Regulatory Simulation: A Controller-Level Contestability Layer
Pith reviewed 2026-06-27 02:27 UTC · model grok-4.3
The pith
A machine-coached layer makes policy decisions in agent-based regulatory simulations explainable, revisable, and re-testable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a controller-level contestability layer can be implemented by representing policies as defeasible rules, generating explanations, and translating simulation diagnostics into rule modifications, as shown by adding a relaxation rule to reduce over-conservatism recurrence in held-out runs of an emissions ABM while preserving guardrails.
What carries the argument
The machine-coached policy-revision layer, which represents policy decisions as defeasible rules with explicit conflicts and priorities and translates diagnostic failures into rule changes.
If this is right
- Policy decisions become explainable and challengeable at the controller level.
- Diagnostic failures can be systematically converted into policy revisions.
- Revisions can be tested in held-out simulation runs.
- The approach preserves existing guardrails like violation limits and volatility constraints.
- It extends explainable adaptive ABM frameworks as a complementary method.
Where Pith is reading between the lines
- This could allow iterative policy improvement loops in regulatory modeling without manual intervention after each run.
- Similar layers might apply to other adaptive systems such as traffic control or economic policy simulations.
- Integration with causal or trajectory diagnostics could strengthen the step from failure identification to rule change.
- Testing the layer across multiple distinct failure modes would show how general the translation template is.
Load-bearing premise
Diagnostic failures identified in simulation trajectories can be reliably translated into rule additions, removals, or priority changes that reduce the targeted failure without violating other guardrails.
What would settle it
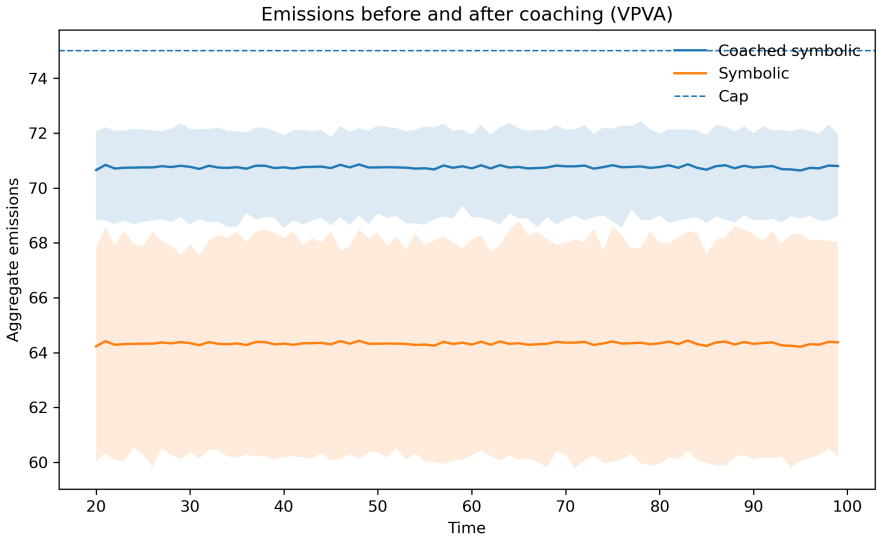
Running the emissions-regulation ABM with the added relaxation rule under new random seeds and observing whether over-conservatism recurrence decreases while violation, overshoot, and volatility metrics stay within limits.
Figures
read the original abstract
Policy-oriented agent-based models are increasingly used to study regulatory interventions in complex adaptive socio-technical systems. Recent adaptive ABM frameworks distinguish between static and adaptive agents, fixed and adaptive policies, and alternative controller designs. However, most diagnostic workflows remain ex post: trajectories are analysed after simulation, but the resulting evidence is not systematically fed back into the policy controller. This paper proposes a lightweight machine-coached policy-revision layer for adaptive agent-based regulation. The layer represents policy decisions as defeasible rules with explicit conflicts and priorities, generates explanations for controller actions, and allows diagnostic failures to be translated into rule additions, removals, or priority changes. The contribution is not a new optimal controller and does not claim formal guarantees for unrestricted machine coaching. Instead, it provides a simulation-compatible operationalization of controller-level contestability: policy decisions can be explained, challenged, revised, and re-evaluated in held-out simulation runs. A stylized emissions-regulation ABM is used as the experimental component. A controlled simulation experiment focuses on an over-conservatism failure in the VPVA regime. The predefined coaching template adds a relaxation rule to the symbolic controller, reducing over-conservatism recurrence under held-out seeds while preserving violation, overshoot, and volatility guardrails. The paper argues that machine coaching is best understood as a controller-level extension of explainable adaptive ABM, complementary to causal, information-theoretic, and trajectory-based diagnostics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight machine-coached policy-revision layer as a controller-level extension for adaptive agent-based regulatory models. Policies are represented as defeasible rules with explicit conflicts and priorities; the layer generates explanations for controller actions and translates diagnostic failures from simulation trajectories into rule additions, removals, or priority changes. The central contribution is framed as a simulation-compatible operationalization of contestability rather than a new optimal controller or formal guarantee. This is illustrated in a stylized emissions-regulation ABM via a controlled experiment on over-conservatism in the VPVA regime, where a predefined coaching template adds a relaxation rule that reduces recurrence under held-out seeds while preserving violation, overshoot, and volatility guardrails.
Significance. If the operationalization proves extensible, the work could meaningfully bridge ex-post diagnostics and in-controller revision in adaptive ABMs for regulation, offering a practical complement to causal, information-theoretic, and trajectory-based methods. The explicit use of defeasible rules and held-out re-evaluation is a concrete strength, though the current demonstration remains limited to a single failure mode and template.
major comments (2)
- [Abstract / Experimental component] Abstract / description of the controlled simulation experiment: the translation from trajectory diagnostics to rule changes is demonstrated only via a single predefined coaching template for one failure mode (over-conservatism in VPVA). This leaves the claim of a general, simulation-compatible operationalization of contestability dependent on an unshown general mechanism for mapping diagnostics to rule additions/removals/priority shifts.
- [Abstract] Abstract: no quantitative results, error bars, or details on validation of the coaching template are reported, so the reduction in recurrence and preservation of guardrails cannot be assessed for robustness or effect size.
minor comments (1)
- [Introduction / Related work] The distinction between the proposed layer and existing explainable ABM diagnostics could be clarified with a short comparison table or explicit positioning paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of the demonstration and the presentation of results in the abstract. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Experimental component] Abstract / description of the controlled simulation experiment: the translation from trajectory diagnostics to rule changes is demonstrated only via a single predefined coaching template for one failure mode (over-conservatism in VPVA). This leaves the claim of a general, simulation-compatible operationalization of contestability dependent on an unshown general mechanism for mapping diagnostics to rule additions/removals/priority shifts.
Authors: The manuscript frames the contribution as a simulation-compatible operationalization via the defeasible rule layer, with the experiment serving as an illustrative case for one failure mode using a predefined coaching template. The general mechanism is the explicit support for rule additions, removals, and priority changes within the defeasible representation; the specific mapping from diagnostics to revisions is implemented through coaching templates that encode domain knowledge. We do not claim or demonstrate a fully automated general mapping beyond this template-based approach. We will revise the abstract and experimental description to clarify the illustrative nature of the demonstration and the role of templates. revision: partial
-
Referee: [Abstract] Abstract: no quantitative results, error bars, or details on validation of the coaching template are reported, so the reduction in recurrence and preservation of guardrails cannot be assessed for robustness or effect size.
Authors: The abstract summarizes the outcome at a high level. The full manuscript reports quantitative results from the held-out evaluation, including recurrence rates under multiple seeds and confirmation that violation, overshoot, and volatility guardrails are preserved. We will revise the abstract to incorporate key quantitative metrics, effect sizes where available, and validation details to allow assessment of robustness. revision: yes
Circularity Check
No circularity: operationalization without derived or self-referential quantities
full rationale
The paper frames its contribution explicitly as a simulation-compatible operationalization of controller-level contestability via a policy-revision layer, rather than any derivation, theorem, or quantitative prediction. No equations, fitted parameters, or first-principles results are presented that could reduce to inputs by construction. The experiment relies on a single predefined coaching template for one failure mode in a stylized ABM, with outcomes evaluated in held-out runs, but this is described as case-specific illustration without general claims or self-referential mappings. No self-citations are invoked as load-bearing for any derivation chain. The work is therefore self-contained as a framework proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diagnostic failures can be translated into rule additions, removals, or priority changes that preserve guardrails
invented entities (1)
-
machine-coached policy-revision layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arthur, W. B. (1994). Inductive reasoning and bounded rationality.American Economic Review, 84(2), 406–411.https://ideas.repec.org/a/aea/aecrev/v84y1994i2p406-11. html
1994
-
[2]
Busoniu, L., Babuska, R., & De Schutter, B. (2008). A comprehensive survey of multiagent reinforcement learning.IEEE Transactions on Systems, Man, and Cybernetics, Part C, 38(2), 156–172.https://doi.org/10.1109/TSMCC.2007.913919
-
[3]
Conte, R., & Paolucci, M. (2014). On agent-based modeling and computational social science.Frontiers in Psychology, 5, 668.https://doi.org/10.3389/fpsyg.2014.00668 24
-
[4]
Crutchfield, J. P. (1994). The calculi of emergence: Computation, dynamics and in- duction.Physica D: Nonlinear Phenomena, 75(1–3), 11–54.https://doi.org/10.1016/ 0167-2789(94)90273-9
1994
-
[5]
Epstein, J. M. (1999). Agent-based computational models and generative social science. Complexity, 4(5), 41–60.https://onlinelibrary.wiley.com/doi/10.1002/%28SICI% 291099-0526%28199905/06%294%3A5%3C41%3A%3AAID-CPLX9%3E3.0.CO%3B2-F
1999
-
[6]
Epstein, J. M. (2012).Generative Social Science: Studies in Agent-Based Computational Modeling. Princeton University Press.https://www.jstor.org/stable/j.ctt7rxj1
2012
-
[7]
Garrone, R. (2025). An adaptive, data-integrated agent-based modeling framework for ex- plainable and contestable policy design.arXiv preprint arXiv:2511.19726.https://arxiv. org/abs/2511.19726
arXiv 2025
-
[8]
Garrone, R. (2026). Structural distinguishability of static and adaptive policy regimes in agent-based regulation. Preprint
2026
-
[9]
(2008).Agent-Based Models
Gilbert, N. (2008).Agent-Based Models. SAGE Publications.https://doi.org/10.4135/ 9781412983259
2008
-
[10]
McCarthy, J. (1959). Programs with common sense. InProceedings of the Tedding- ton Conference on the Mechanization of Thought Processes.http://jmc.stanford.edu/ articles/mcc59/mcc59.pdf
1959
-
[11]
Computational Mechanics: Pattern and Prediction, Structure and Simplicity
Shalizi, C. R., & Crutchfield, J. P. (2001). Computational mechanics: Pattern and pre- diction, structure and simplicity.Journal of Statistical Physics, 104, 817–879.https: //doi.org/10.1023/A:1010388907793
-
[12]
Tesfatsion, L. (2006). Agent-based computational economics: A constructive approach to economic theory. In L. Tesfatsion & K. L. Judd (Eds.),Handbook of Computational Economics, Vol. 2. Elsevier.https://doi.org/10.1016/S1574-0021(05)02016-2
-
[13]
Tesfatsion, L., & Judd, K. L. (Eds.). (2006).Handbook of Computational Economics, Vol- ume 2: Agent-Based Computational Economics. Elsevier.https://shop.elsevier.com/ books/handbook-of-computational-economics/tesfatsion/978-0-444-51253-6
2006
-
[14]
Zhang, K., Yang, Z., & Basar, T. (2021). Multi-agent reinforcement learning: A selective overview of theories and algorithms. InHandbook of Reinforcement Learning and Control. Springer.https://arxiv.org/abs/1911.10635
arXiv 2021
-
[15]
Bradley Knox, and Todd Kulesza
Amershi, S., Cakmak, M., Knox, W. B., & Kulesza, T. (2014). Power to the people: The role of humans in interactive machine learning.AI Magazine, 35(4), 105–120.https: //doi.org/10.1609/aimag.v35i4.2513
-
[16]
Supersymmetric localization of refined chiral multiplets on topologically twisted H2 x S1.Phys
Arrieta, A. B., D´ ıaz-Rodr´ ıguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., Garc´ ıa, S., Gil-L´ opez, S., Molina, D., Benjamins, R., Chatila, R., & Herrera, F. (2020). Ex- plainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI.Information Fusion, 58, 82–115.https://doi.org/10.1016/...
work page doi:10.1016/j 2020
-
[17]
Christiano, P. F., Leike, J., Brown, T. B., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems.https://arxiv.org/abs/1706.03741 25
Pith/arXiv arXiv 2017
-
[18]
Dung, P. M. (1995). On the acceptability of arguments and its fundamental role in non- monotonic reasoning, logic programming and n-person games.Artificial Intelligence, 77(2), 321–357.https://doi.org/10.1016/0004-3702(94)00041-X
-
[19]
Grosan, C., & Abraham, A. (2011). Rule-based expert systems. InIntelligent Sys- tems: A Modern Approach. Springer.https://link.springer.com/book/10.1007/ 978-3-642-21004-4
2011
-
[20]
Karimi, A.-H., Sch¨ olkopf, B., & Valera, I. (2021). Algorithmic recourse: From counter- factual explanations to interventions. InProceedings of the ACM Conference on Fairness, Accountability, and Transparency.https://doi.org/10.1145/3442188.3445899
-
[21]
Nute, D. (1994). Defeasible logic. In D. M. Gabbay, C. J. Hogger, & J. A. Robinson (Eds.),Handbook of Logic in Artificial Intelligence and Logic Programming, Vol. 3. Oxford University Press.https://dl.acm.org/doi/10.5555/186124.186131
-
[22]
Wachter, S., Mittelstadt, B., & Russell, C. (2017). Counterfactual explanations without opening the black box: Automated decisions and the GDPR.Harvard Journal of Law & Technology, 31(2), 841–887.https://arxiv.org/abs/1711.00399
Pith/arXiv arXiv 2017
-
[23]
Michael, L. (2019). Machine Coaching. InProceedings of the IJCAI 2019 Workshop on Ex- plainable Artificial Intelligence (XAI). Macao, China.https://www.researchgate.net/ publication/334989337_Machine_Coaching
arXiv 2019
-
[24]
Markos, V., Thoma, M., & Michael, L. (2022). Machine Coaching with Proxy Coaches. InProceedings of the Workshop on Argumentation and Machine Learning (ArgML@COMMA). CEUR Workshop Proceedings, Vol. 3208.https://ceur-ws.org/ Vol-3208/paper4.pdf 26
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.