MotionPyramid: Hierarchical Motion Representation and Residual Interfaces
Pith reviewed 2026-06-27 04:11 UTC · model grok-4.3
The pith
Motion can be organized as a reusable hierarchy of latent decoders that serve as multi-resolution action interfaces for RL policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
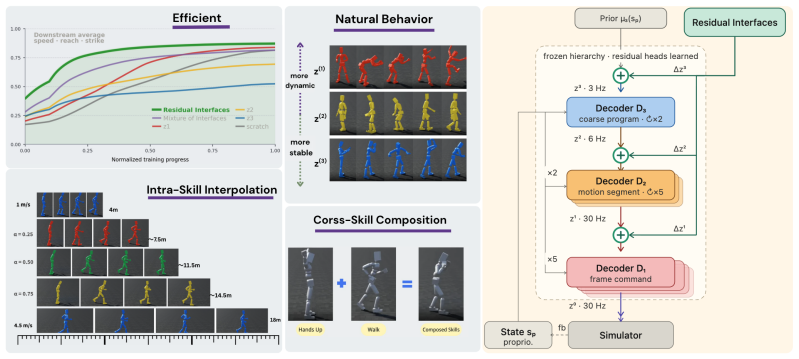
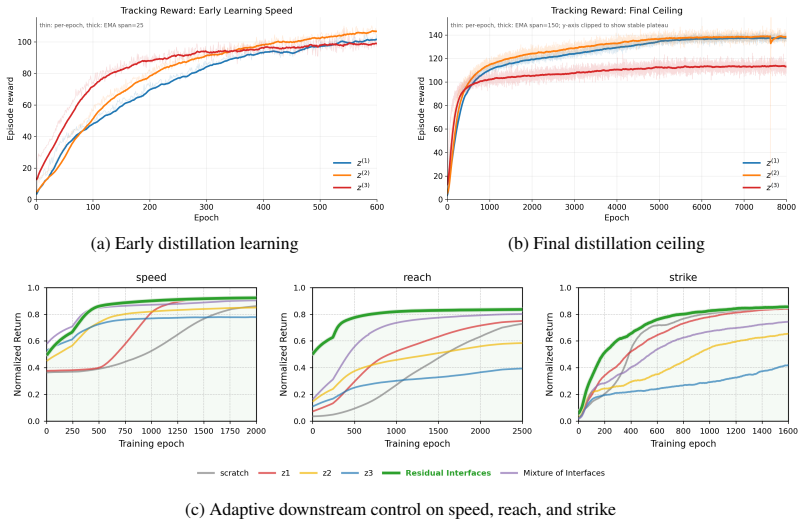
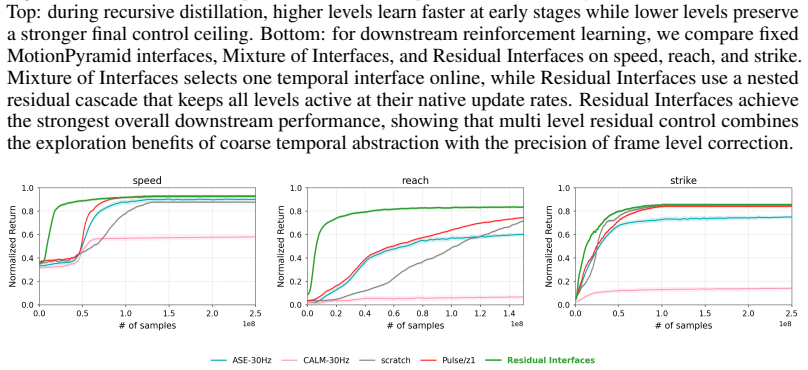
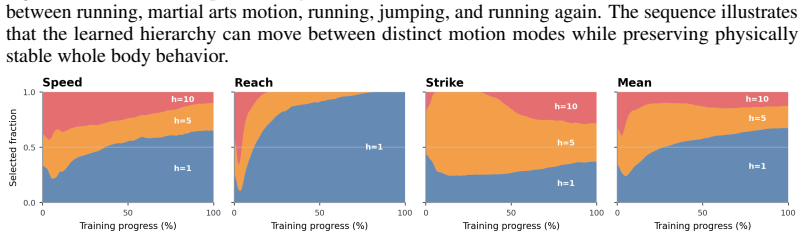
MotionPyramid trains a recursive stack of latent decoders from a motion-tracking teacher. Low-level latents decode directly to full-body motor commands, while each higher level decodes into a sequence of commands at the level below, thereby producing temporally extended motion programs. After pretraining, the entire hierarchy is frozen and exposed to downstream RL policies as a family of action interfaces at different temporal resolutions. Representation probes confirm that the learned levels support traversal, interpolation, transition, and composition. Residual Interfaces further allow a single policy to issue coarse segment-level commands and frame-level corrections simultaneously through
What carries the argument
a recursive stack of latent decoders in which higher-level latents unfold through lower levels into temporally extended motion programs
If this is right
- Coarser interfaces constrain exploration to structured motion segments and thereby improve early learning and motion regularity.
- Finer interfaces preserve closed-loop feedback and final task precision.
- The hierarchy supports explicit traversal, interpolation, and qualitative composition of motions.
- Residual Interfaces let coarse motion programs and fine corrections coexist inside one controller.
Where Pith is reading between the lines
- If the learned levels prove reusable across tasks, the same pretraining procedure could supply motion priors for other sequential control problems.
- The residual-interface pattern could be tested by measuring how much performance drops when the skip connections between levels are removed.
- The same recursive-decoder construction might be applied to other temporally extended signals such as speech or video synthesis.
Load-bearing premise
Training a recursive stack of latent decoders on motion-tracking data will automatically yield levels that remain meaningful and reusable when frozen and inserted as action interfaces into downstream RL policies.
What would settle it
An RL policy using the frozen MotionPyramid levels as action interfaces shows no gain in sample efficiency or final task performance compared with an otherwise identical policy that acts directly on raw motor commands.
Figures


read the original abstract
We ask whether the representational hierarchy seen in perception, from local primitives such as edges to higher level structures such as parts and objects, can be established for motion. In humanoid control, low level actions specify immediate motor commands, while meaningful behavior is organized over longer temporal scales, including contacts, gait fragments, balance recovery, reaching, and whole body skills. We introduce MotionPyramid, a hierarchical action representation that learns such structure from motion data. Starting from a motion tracking teacher, it trains a recursive stack of latent decoders: low level latents decode to immediate full body motor commands, while higher level latents unfold through lower levels into temporally extended motion programs. After pretraining, the hierarchy is frozen and reused by downstream reinforcement learning policies as a family of action interfaces at different control resolutions. Experiments show the learned levels form a motion hierarchy: coarser interfaces improve early learning and motion regularity by constraining exploration to structured segments, while finer interfaces preserve feedback control and final task precision. Representation probes show the hierarchy supports traversal, interpolation, transition, and qualitative composition, exposing editable control handles across temporal scales. Finally, we introduce Residual Interfaces, letting a downstream policy maintain coarse, segment level, and frame level residual commands through the frozen hierarchy. Analogous to residual or skip connections in deep networks, this allows coarse motion programs and fine residual corrections to coexist within one controller. MotionPyramid shows that motion, like perception, can be organized into a reusable multi level representation, providing structured abstraction without sacrificing controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MotionPyramid, a hierarchical motion representation for humanoid control learned from a motion tracking teacher via a recursive stack of latent decoders. Low-level latents decode to immediate motor commands while higher levels unfold into temporally extended programs. After pretraining the hierarchy is frozen and inserted as multi-resolution action interfaces into downstream RL policies. Residual Interfaces allow a policy to issue coarse-to-fine residual commands through the frozen stack. The abstract states that experiments and representation probes confirm that coarser levels constrain exploration and improve regularity while finer levels preserve precision, and that the levels support traversal, interpolation, transition, and composition.
Significance. If the reported experiments hold with appropriate controls and baselines, the work would demonstrate a reusable, multi-scale motion abstraction that improves sample efficiency and controllability in RL without sacrificing final-task performance. The residual-interface mechanism is a concrete engineering contribution that could be adopted in other hierarchical control settings.
major comments (2)
- [Abstract] Abstract: the central claim that 'experiments show the learned levels form a motion hierarchy' and that 'coarser interfaces improve early learning' rests entirely on described results, yet the abstract supplies no quantitative metrics, baselines, task definitions, or statistical controls. Without these the support for the hierarchy-benefit claim cannot be evaluated and the claim is not yet load-bearing.
- [Abstract] Abstract: the description of the recursive latent-decoder stack and the claim that higher-level latents 'unfold through lower levels into temporally extended motion programs' is presented without any equations, loss functions, or training details. This makes it impossible to assess whether the hierarchy is learned or imposed by construction.
Simulated Author's Rebuttal
We thank the referee for the comments. We address each major point below and indicate where revisions to the manuscript are appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'experiments show the learned levels form a motion hierarchy' and that 'coarser interfaces improve early learning' rests entirely on described results, yet the abstract supplies no quantitative metrics, baselines, task definitions, or statistical controls. Without these the support for the hierarchy-benefit claim cannot be evaluated and the claim is not yet load-bearing.
Authors: We agree that the abstract is concise and omits specific numbers. The full manuscript reports quantitative results, including task definitions, baselines, and multi-seed statistics in the Experiments section. To make the abstract's claims more self-contained, we will revise it to include brief quantitative highlights of the reported benefits. revision: yes
-
Referee: [Abstract] Abstract: the description of the recursive latent-decoder stack and the claim that higher-level latents 'unfold through lower levels into temporally extended motion programs' is presented without any equations, loss functions, or training details. This makes it impossible to assess whether the hierarchy is learned or imposed by construction.
Authors: The abstract summarizes at a high level. The manuscript details the recursive training from the motion-tracking teacher, the unfolding mechanism, and the per-level losses in Section 3, confirming the hierarchy is learned. We will revise the abstract to explicitly state that the levels are learned via this procedure. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method for learning hierarchical motion representations via a recursive stack of latent decoders pretrained on motion tracking data and then frozen for use in downstream RL. No mathematical derivations, first-principles predictions, or equations are described that could reduce to fitted inputs by construction. Claims rest on experimental outcomes (hierarchy properties, residual interfaces) rather than any self-definitional or fitted-input structure. No self-citations or uniqueness theorems are invoked in the provided text. The derivation chain is therefore self-contained as a standard training-and-evaluation pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The option critic architecture
Pierre Luc Bacon, Jean Harb, and Doina Precup. The option critic architecture. InProceedings of the AAAI Conference on Artificial Intelligence, 2017
2017
-
[2]
Bernstein.The Coordination and Regulation of Movements
Nikolai A. Bernstein.The Coordination and Regulation of Movements. Pergamon Press, Oxford, 1967
1967
-
[3]
Imitate and repurpose: Learning reusable robot movement skills from human and animal behaviors, 2022
Steven Bohez, Saran Tunyasuvunakool, Philemon Brakel, Fereshteh Sadeghi, Leonard Hasen- clever, Yuval Tassa, Emilio Parisotto, Jan Humplik, Tuomas Haarnoja, Roland Hafner, Markus Wulfmeier, Michael Neunert, Ben Moran, Noah Siegel, Andrea Huber, Francesco Romano, Nathan Batchelor, Federico Casarini, Josh Merel, Raia Hadsell, and Nicolas Heess. Imitate and ...
arXiv 2022
-
[4]
Paiton, and Bruno A
Yubei Chen, Dylan M. Paiton, and Bruno A. Olshausen. The sparse manifold trans- form. InAdvances in Neural Information Processing Systems, volume 31, pages 10534–10545, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/ 8e19a39c36b8e5e3afd2a3b2692aea96-Abstract.html
2018
-
[5]
Dietterich
Thomas G. Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition.Journal of Artificial Intelligence Research, 13:227–303, 2000. doi: 10.1613/ jair.639
2000
-
[6]
Diversity is all you need: Learning skills without a reward function
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=SJx63jRqFm
2019
-
[7]
Latent space policies for hierarchical reinforcement learning.arXiv preprint arXiv:1804.02808, 2018
Tuomas Haarnoja, Kristian Hartikainen, Pieter Abbeel, and Sergey Levine. Latent space policies for hierarchical reinforcement learning.arXiv preprint arXiv:1804.02808, 2018
Pith/arXiv arXiv 2018
-
[8]
Neural motion simulator: Pushing the limit of world models in reinforcement learning
Chenjie Hao, Weyl Lu, Yifan Xu, and Yubei Chen. Neural motion simulator: Pushing the limit of world models in reinforcement learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27608–27617, 2025. URL https://openaccess.thecvf.com/content/CVPR2025/html/Hao_Neural_Motion_ Simulator_Pushing_the_Limit_of_World_M...
2025
-
[9]
CoMic: Complementary task learning and mimicry for reusable skills
Leonard Hasenclever, Fabio Pardo, Raia Hadsell, Nicolas Heess, and Josh Merel. CoMic: Complementary task learning and mimicry for reusable skills. InProceedings of the 37th Inter- national Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4105–4115. PMLR, 2020. URL https://proceedings.mlr.press/v119/ hasenclever20a.html
2020
-
[10]
Learning an embedding space for transferable robot skills
Karol Hausman, Jost Tobias Springenberg, Ziyu Wang, Nicolas Heess, and Martin Riedmiller. Learning an embedding space for transferable robot skills. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=rk07ZXZRb
2018
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 11
2016
-
[12]
Hong-Ye Hu, Dian Wu, Yi-Zhuang You, Bruno Olshausen, and Yubei Chen. RG-flow: A hierar- chical and explainable flow model based on renormalization group and sparse prior.Machine Learning: Science and Technology, 3(3):035009, August 2022. doi: 10.1088/2632-2153/ac8393. URLhttps://doi.org/10.1088/2632-2153/ac8393
-
[13]
Simple emergent action representations from multi- task policy training
Pu Hua, Yubei Chen, and Huazhe Xu. Simple emergent action representations from multi- task policy training. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=NUl0ylt7SM
2023
-
[14]
Auke Jan Ijspeert, Jun Nakanishi, Heiko Hoffmann, Peter Pastor, and Stefan Schaal. Dynamical movement primitives: Learning attractor models for motor behaviors.Neural Computation, 25 (2):328–373, 2013. doi: 10.1162/NECO_a_00393
-
[15]
Learning multi-level hierar- chies with hindsight
Andrew Levy, George Konidaris, Robert Platt, and Kate Saenko. Learning multi-level hierar- chies with hindsight. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=ryzECoAcY7
2019
-
[16]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
2017
-
[17]
Character controllers using motion vaes.ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH), 39(4), 2020
Hung Yu Ling, Fabio Zinno, George Cheng, and Michiel van de Panne. Character controllers using motion vaes.ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH), 39(4), 2020
2020
-
[18]
Perpetual humanoid control for real time simulated avatars.arXiv preprint arXiv:2305.06456, 2023
Zhengyi Luo, Jinkun Cao, Alexander Winkler, Kris Kitani, and Weipeng Xu. Perpetual humanoid control for real time simulated avatars.arXiv preprint arXiv:2305.06456, 2023
arXiv 2023
-
[19]
Kitani, and Weipeng Xu
Zhengyi Luo, Jinkun Cao, Josh Merel, Alexander Winkler, Jing Huang, Kris M. Kitani, and Weipeng Xu. Universal humanoid motion representations for physics-based control. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=OrOd8PxOO2
2024
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5442–5451, 2019. doi: 10.1109/ICCV . 2019.00554
-
[21]
Neural probabilistic motor primitives for humanoid control
Josh Merel, Leonard Hasenclever, Alexandre Galashov, Arun Ahuja, Vu Pham, Greg Wayne, Yee Whye Teh, and Nicolas Heess. Neural probabilistic motor primitives for humanoid control. arXiv preprint arXiv:1811.11711, 2018
Pith/arXiv arXiv 2018
-
[22]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. InAdvances in Neural Information Processing Systems, volume 31, pages 3307–3317, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/ e6384711491713d29bc63fc5eeb5ba4f-Abstract.html
2018
-
[23]
Near-optimal representation learning for hierarchical reinforcement learning
Ofir Nachum, Shixiang Gu, Honglak Lee, and Sergey Levine. Near-optimal representation learning for hierarchical reinforcement learning. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=H1emus0qF7
2019
-
[24]
Peters, and Gerhard Neumann
Alexandros Paraschos, Christian Daniel, Jan R. Peters, and Gerhard Neumann. Probabilistic movement primitives. InAdvances in Neural Information Processing Systems, volume 26, pages 2616–2624, 2013
2013
-
[25]
Ronald Parr and Stuart J. Russell. Reinforcement learning with hierarchies of machines. InAdvances in Neural Information Processing Systems, vol- ume 10, 1997. URL https://proceedings.neurips.cc/paper/1997/hash/ 5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html
1997
-
[26]
Deepmimic: Example guided deep reinforcement learning of physics based character skills.ACM Transactions on Graphics, 37(4), 2018
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. Deepmimic: Example guided deep reinforcement learning of physics based character skills.ACM Transactions on Graphics, 37(4), 2018. 12
2018
-
[27]
Mcp: Learning composable hierarchical control with multiplicative compositional policies.Advances in neural information processing systems, 32, 2019
Xue Bin Peng, Michael Chang, Grace Zhang, Pieter Abbeel, and Sergey Levine. Mcp: Learning composable hierarchical control with multiplicative compositional policies.Advances in neural information processing systems, 32, 2019
2019
-
[28]
Amp: Adversarial motion priors for stylized physics based character control.ACM Transactions on Graphics, 40 (4), 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics based character control.ACM Transactions on Graphics, 40 (4), 2021
2021
-
[29]
Ase: Large scale reusable adversarial skill embeddings for physically simulated characters
Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, and Sanja Fidler. Ase: Large scale reusable adversarial skill embeddings for physically simulated characters. InACM SIGGRAPH Conference Proceedings, 2022
2022
-
[30]
Karl Pertsch, Youngwoon Lee, and Joseph J. Lim. Accelerating reinforcement learning with learned skill priors. InProceedings of the 2020 Conference on Robot Learning, volume 155 ofProceedings of Machine Learning Research, pages 188–204. PMLR, 2021. URL https://proceedings.mlr.press/v155/pertsch21a.html
2020
-
[31]
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas J. Guibas. HuMoR: 3d human motion model for robust pose estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11468–11479, 2021. doi: 10.1109/ICCV48922.2021.01129
-
[32]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[33]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 627–635. PMLR, 2011
2011
-
[34]
Andrei A. Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, V olodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation.arXiv preprint arXiv:1511.06295, 2015
Pith/arXiv arXiv 2015
-
[35]
Richard A. Schmidt. A schema theory of discrete motor skill learning.Psychological Review, 82(4):225–260, 1975
1975
-
[36]
Hudson, Augustin Zidek, Simon Osindero, Carl Doersch, Woj- ciech M
Simon Schmitt, Jonathan J. Hudson, Augustin Zidek, Simon Osindero, Carl Doersch, Woj- ciech M. Czarnecki, Joel Z. Leibo, Heinrich Kuttler, Andrew Zisserman, Karen Simonyan, and S. M. Ali Eslami. Kickstarting deep reinforcement learning.arXiv preprint arXiv:1803.03835, 2018
Pith/arXiv arXiv 2018
-
[37]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1–2): 181–211, 1999. doi: 10.1016/S0004-3702(99)00052-1
-
[38]
Calm: Conditional adversarial latent models for directable virtual characters
Chen Tessler, Yoni Kasten, Yunrong Guo, Shie Mannor, Gal Chechik, and Xue Bin Peng. Calm: Conditional adversarial latent models for directable virtual characters. InACM SIGGRAPH Conference Proceedings, 2023
2023
-
[39]
Chen Tessler, Yunrong Guo, Ofir Nabati, Gal Chechik, and Xue Bin Peng. Maskedmimic: Unified physics-based character control through masked motion inpainting.ACM Transactions on Graphics, 43(6), 2024. doi: 10.1145/3687951
-
[40]
Andrea Tirinzoni, Ahmed Touati, Jesse Farebrother, Mateusz Guzek, Anssi Kanervisto, Yingchen Xu, Alessandro Lazaric, and Matteo Pirotta. Zero shot whole body humanoid control via behavioral foundation models.arXiv preprint arXiv:2504.11054, 2025
arXiv 2025
-
[41]
Emanuel Todorov and Michael I. Jordan. Optimal feedback control as a theory of motor coordination.Nature Neuroscience, 5(11):1226–1235, 2002. 13
2002
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[43]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. InProceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3540–3549. PMLR, 2017. URL https: //proceedi...
2017
-
[44]
Greg Wayne and L. F. Abbott. Hierarchical control using networks trained with higher-level forward models.Neural Computation, 26(10):2163–2193, 2014. doi: 10.1162/NECO_a_00639
-
[45]
Physics based character controllers using conditional vaes.ACM Transactions on Graphics, 41(4), 2022
Jungdam Won, Deepak Gopinath, and Jessica Hodgins. Physics based character controllers using conditional vaes.ACM Transactions on Graphics, 41(4), 2022
2022
-
[46]
Heyuan Yao, Zhenhua Song, Baoquan Chen, and Libin Liu. Controlvae: Model based learning of generative controllers for physics based characters.arXiv preprint arXiv:2210.06063, 2022
arXiv 2022
-
[47]
Understanding neural networks through deep visualization.arXiv preprint arXiv:1506.06579, 2015
Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Understanding neural networks through deep visualization.arXiv preprint arXiv:1506.06579, 2015
Pith/arXiv arXiv 2015
-
[48]
Olshausen and Yann LeCun , title =
Zeyu Yun, Yubei Chen, Bruno Olshausen, and Yann LeCun. Transformer visualization via dictionary learning: Contextualized embedding as a linear superposition of transformer factors. InProceedings of Deep Learning Inside Out: The 2nd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, pages 1–10, Online, June 2021. Association ...
-
[49]
Visualizing and understanding convolutional networks
Matthew D. Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In Computer Vision – ECCV 2014, volume 8689 ofLecture Notes in Computer Science, pages 818–833. Springer, 2014. doi: 10.1007/978-3-319-10590-1_53. URL https://doi.org/10. 1007/978-3-319-10590-1_53
-
[50]
Qingxu Zhu, He Zhang, Mengting Lan, and Lei Han. Neural categorical priors for physics-based character control.ACM Transactions on Graphics, 42(6), 2023. doi: 10.1145/3618397. 14 A Method Details This appendix provides additional details for the construction of the recursive action interfaces and for downstream reinforcement learning with temporally exten...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.