Repeated Shared Access Enables Grokking, but Edit Propagation Depends on an Addressable Memory
Pith reviewed 2026-06-26 20:41 UTC · model grok-4.3
The pith
Addressable memory enables factual edit propagation while repeated access enables grokking regardless of mechanism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Repeated shared access, achieved either by looped recomputation or by repeated memory rereading, suffices to cross the out-of-distribution grokking barrier, whereas edit propagation after a single localized factual edit requires an addressable memory site that the forward pass can write to and later reread; every memory-bearing model exceeds every memory-free model, and a non-recurrent dense model with memory still propagates edits at high rates.
What carries the argument
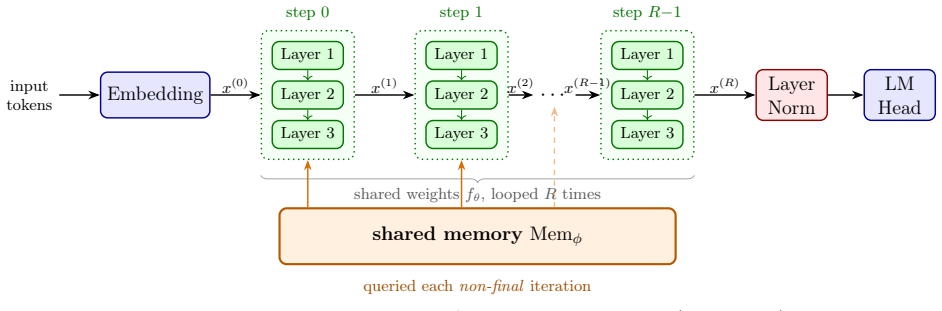
The 2x2 grid of architectures (dense, looped, dense-plus-memory, looped-plus-memory) that isolates repeated shared access from the presence of an explicit addressable memory store.
Load-bearing premise
The synthetic knowledge-graph QA task and the 2x2 controls isolate memory access from recurrence without confounding effects from scale or task structure.
What would settle it
Finding strong edit propagation after a single factual edit in a memory-free looped model on the same task or a closely matched one would falsify the necessity of addressable memory.
Figures
read the original abstract
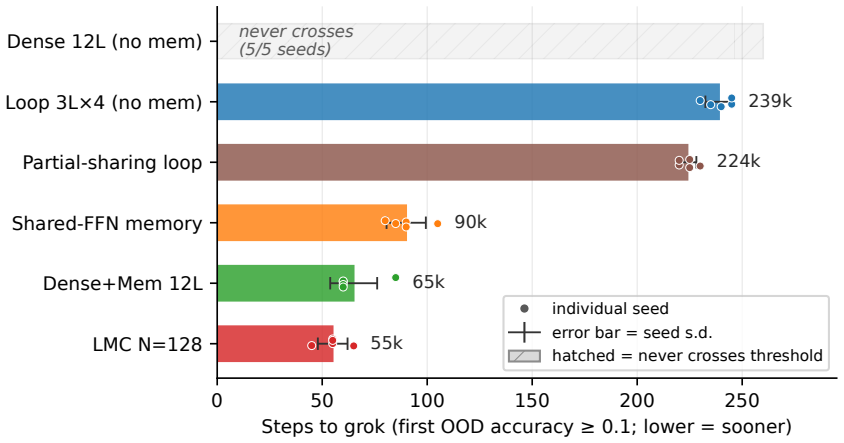
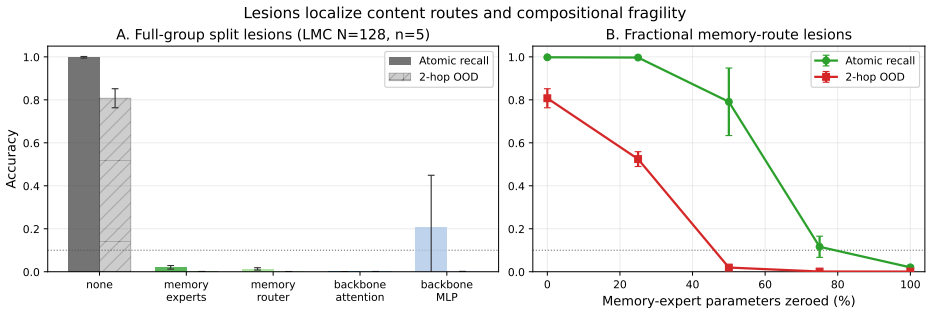
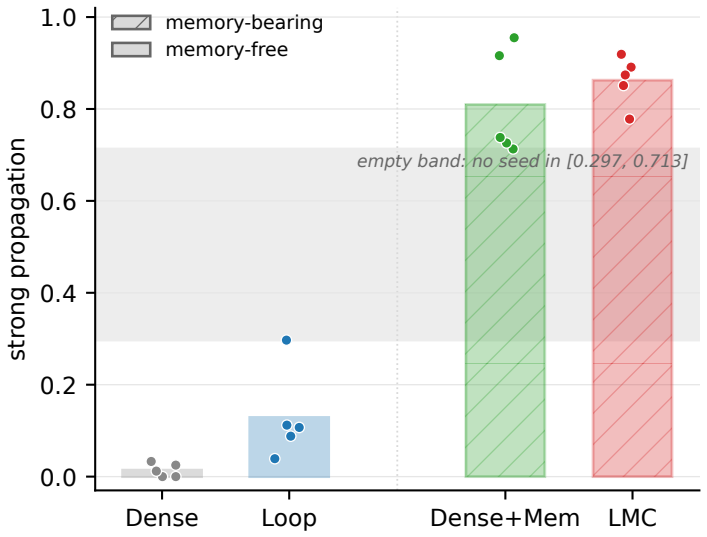
We study factual edit propagation in a controlled synthetic knowledge-graph QA setting using a 2x2 grid that crosses loop recurrence with shared-memory access: a dense transformer (Dense), a looped transformer (Loop), a dense backbone with shared memory (Dense+Mem), and a looped backbone with shared memory (loop-memory coupling, LMC). The two factors dissociate. For learning, both routes to repeated shared access -- looped recomputation and repeated memory rereading -- cross the out-of-distribution (OOD) grokking barrier that Dense fails, so repeated shared access is the behavioral regularity, not a specific architecture. For editing, the substrates split along a different axis: applying a single localized factual edit (conditioned on direct success) and measuring 2-hop propagation on a shared pre-edit-correct set, the edit propagates strongly in both memory-bearing cells (LMC 0.78-0.92, Dense+Mem 0.71-0.96) and only weakly in the memory-free ones (Loop 0.04-0.30, Dense 0.00-0.03). The split is along the memory axis, not the loop axis: every memory-bearing seed exceeds every memory-free seed, with no detectable difference between the two memory cells. Crucially Dense+Mem has no recurrence, so the propagating ingredient is an addressable site that an edit can write to and later computation rereads, not loop recomputation; Loop is at best a partial intermediate. The affordance survives coarsening the store (N=128 to N=13): propagation attenuates but the memory/no-memory split persists, so fine granularity buys precision rather than the affordance itself. These results dissociate learning competence from editing affordance -- repeated shared access suffices to grok, but edit propagation depends on whether the substrate exposes an addressable memory that the forward computation can write to and later reread, an affordance that loop recurrence provides only partially.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that repeated shared access enables grokking on a synthetic knowledge-graph QA task regardless of whether it arises from loop recurrence or memory rereading, but factual edit propagation requires an addressable memory site that edits can write to and later computation can reread. This is shown via a 2x2 grid (Dense, Loop, Dense+Mem, LMC) where grokking occurs in both repeated-access routes while edit propagation splits cleanly along the memory axis (memory cells 0.71-0.96 vs memory-free 0.00-0.30), with every memory-bearing seed exceeding every memory-free seed and the split persisting after coarsening the memory store from N=128 to N=13.
Significance. If the experimental controls isolate the factors as described, the dissociation between grokking competence and edit-propagation affordance is a useful empirical result for understanding transformer editing. The design credits the clean separation, the observation that Dense+Mem succeeds without recurrence, and the persistence of the memory/no-memory split under coarsening; these elements make the central claim falsifiable and directly testable.
minor comments (3)
- [Abstract] Abstract and results: propagation rates are reported as ranges without accompanying error bars, seed counts, or statistical tests; adding these would allow readers to assess the reliability of the claim that every memory-bearing seed exceeds every memory-free seed.
- The description of the synthetic KG-QA task and the precise definition of 2-hop propagation (including how the shared pre-edit-correct set is constructed) should be expanded in the methods to support replication and to confirm absence of confounds from task structure.
- Figure or table presenting the 2x2 grid outcomes would benefit from explicit labeling of the four cells and the coarsening control to make the memory-axis split visually immediate.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, accurate summary of the 2x2 ablation results, and recommendation for minor revision. The design's ability to dissociate repeated shared access (for grokking) from addressable memory (for edit propagation) was correctly identified as the central contribution.
Circularity Check
No significant circularity
full rationale
The paper is strictly empirical, reporting measured performance differences across a 2x2 experimental grid (Dense, Loop, Dense+Mem, LMC) on a synthetic KG-QA task. No equations, derivations, fitted parameters, or self-citations appear in the provided text; claims rest on direct comparisons (e.g., memory-bearing cells 0.71-0.96 vs memory-free 0.00-0.30 for propagation) without any reduction of outputs to inputs by construction. The design isolates factors via controlled variants, making the central dissociation self-contained against external benchmarks rather than internally referential.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization.Advances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2405.15071
arXiv 2024
-
[2]
Harsh Kohli, Srinivasan Parthasarathy, Huan Sun, and Yuekun Yao. Loop, think, & generalize: Implicit reasoning in recurrent-depth transformers.arXiv preprint arXiv:2604.07822, 2026. The Ohio State University; concurrent work, same KG-reasoning task as Wang 2024
Pith/arXiv arXiv 2026
-
[3]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. arXiv:2202.05262 (ROME)
Pith/arXiv arXiv 2022
-
[4]
Sim-cot: Supervised implicit chain-of-thought.arXiv preprint arXiv:2509.20317, 2025
Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Jiaqi Wang, Xipeng Qiu, and Dahua Lin. Sim-cot: Supervised implicit chain-of-thought.arXiv preprint arXiv:2509.20317, 2025
arXiv 2025
-
[5]
Uni- versal transformers
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[6]
Bar- toldson, BhavyaKailkhura, AbhinavBhatele, andTomGoldstein
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bar- toldson, BhavyaKailkhura, AbhinavBhatele, andTomGoldstein. Scalinguptest-timecompute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171, 2025. Huginn-3.5B
Pith/arXiv arXiv 2025
-
[7]
Scaling latent reasoning via looped language models.arXiv preprint arXiv:2510.25741, 2025
Rui-Jie Zhu, Zixuan Wang, Kai Hua, Tianyu Zhang, Ziniu Li, Haoran Que, Boyi Wei, Zixin Wen, Fan Yin, He Xing, Lu Li, Jiajun Shi, Kaijing Ma, Shanda Li, Taylor Kergan, Andrew Smith, Xingwei Qu, Mude Hui, Bohong Wu, Qiyang Min, Hongzhi Huang, Xun Zhou, Wei Ye, Jiaheng Liu, Jian Yang, Yunfeng Shi, Chenghua Lin, Enduo Zhao, Tianle Cai, Ge Zhang, Wenhao Huang,...
Pith/arXiv arXiv 2025
-
[8]
Looped transformers for length generalization
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2409.15647
arXiv 2025
-
[9]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reason- ing with latent thoughts: On the power of looped transformers. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2502.17416
arXiv 2025
-
[10]
ALBERT: A lite BERT for self-supervised learning of language representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations. In International Conference on Learning Representations (ICLR), 2020. arXiv:1909.11942 (cross- layer parameter sharing)
Pith/arXiv arXiv 2020
-
[11]
Lessons on parameter sharing across layers in transformers
Sho Takase and Shun Kiyono. Lessons on parameter sharing across layers in transformers. arXiv preprint arXiv:2104.06022, 2021
arXiv 2021
-
[12]
MoEUT: Mixture-of-experts universal transformers
RóbertCsordás, KazukiIrie, JürgenSchmidhuber, ChristopherPotts, andChristopherD.Man- ning. MoEUT: Mixture-of-experts universal transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2405.16039. 33
arXiv 2024
-
[13]
Amirkeivan Mohtashami, Matteo Pagliardini, and Martin Jaggi. CoTFormer: A chain-of- thought driven architecture with budget-adaptive computation cost at inference. InInterna- tional Conference on Learning Representations (ICLR), 2025. arXiv:2310.10845
arXiv 2025
-
[14]
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177, 2022
Pith/arXiv arXiv 2022
-
[15]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[16]
Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390, 2023
Vikrant Varma, Rohin Shah, Zachary Kenton, János Kramár, and Ramana Kumar. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390, 2023
arXiv 2023
-
[17]
Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
Pith/arXiv arXiv 2014
-
[18]
Hybrid computing using a neural network with dynamic external memory.Nature, 538(7626): 471–476, 2016
Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska- Barwińska, Sergio Gomez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, Adria Puigdomenech Badia, Karl Moritz Hermann, Yori Zwols, Georg Ostrovski, Adam Cain, Helen King, Christopher Summerfield, Phil Blunsom, Koray Kavukcuoglu, and Demis Hassabis. Hybr...
2016
-
[19]
Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. InInternational Con- ference on Learning Representations (ICLR), 2015. arXiv:1410.3916
Pith/arXiv arXiv 2015
-
[20]
End-to-end memory networks
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[21]
Aydar Bulatov, Yuri Kuratov, and Mikhail S. Burtsev. Recurrent memory transformer. In Advances in Neural Information Processing Systems (NeurIPS), 2022. arXiv:2207.06881
arXiv 2022
-
[22]
Rabe, DeLesley Hutchins, and Christian Szegedy
Yuhuai Wu, Markus N. Rabe, DeLesley Hutchins, and Christian Szegedy. Memoriz- ing transformers. InInternational Conference on Learning Representations (ICLR), 2022. arXiv:2203.08913
arXiv 2022
-
[23]
Memory layers at scale.arXiv preprint arXiv:2412.09764, 2024
Vincent-Pierre Berges, Barlas Oğuz, Daniel Haziza, Wen-tau Yih, Luke Zettlemoyer, and Gargi Ghosh. Memory layers at scale.arXiv preprint arXiv:2412.09764, 2024
arXiv 2024
-
[24]
Rubin Wei, Jiaqi Cao, Jiarui Wang, Jushi Kai, Qipeng Guo, Bowen Zhou, and Zhouhan Lin. MLP memory: A retriever-pretrained memory for large language models.arXiv preprint arXiv:2508.01832, 2025
arXiv 2025
-
[25]
Titans: Learning to memorize at test time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2025
Pith/arXiv arXiv 2025
-
[26]
Chan, Fraser Greenlee, George Thomas, Marvin Purtorab, and Andy Toulis
Jikun Kang, Wenqi Wu, Filippos Christianos, Alex J. Chan, Fraser Greenlee, George Thomas, Marvin Purtorab, and Andy Toulis. LM2: Large memory models.arXiv preprint arXiv:2502.06049, 2025. 34
arXiv 2025
-
[27]
Shangyi Geng, Wenting Zhao, and Alexander M. Rush. Great memory, shallow reasoning: Limits of kNN-LMs. InProceedings of NAACL (Short Papers), 2025. arXiv:2408.11815; first posted 2024
arXiv 2025
-
[28]
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D. Manning. Fast model editing at scale. InInternational Conference on Learning Representations (ICLR), 2022. arXiv:2110.11309 (MEND)
arXiv 2022
-
[29]
Mass- editing memory in a transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. InInternational Conference on Learning Representations (ICLR), 2023. arXiv:2210.07229 (MEMIT)
Pith/arXiv arXiv 2023
-
[30]
Manning, Christopher Potts, and Danqi Chen
Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, and Danqi Chen. MQuAKE: Assessing knowledge editing in language models via multi-hop questions.arXiv preprint arXiv:2305.14795, 2023
arXiv 2023
-
[31]
Markus Frey, Behzad Shomali, Ali Hamza Bashir, David Berghaus, Joachim Koehler, and Mehdi Ali. Adaptive loops and memory in transformers: Think harder or know more?arXiv preprint arXiv:2603.08391, 2026. Latent & Implicit Thinking Workshop @ ICLR 2026
arXiv 2026
-
[32]
Grigory Sapunov. Universal transformers need memory: Depth-state trade-offs in adaptive recursive reasoning.arXiv preprint arXiv:2604.21999, 2026. 35
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.