Empowering Polymeric Materials Discovery by Artificial Intelligence
Pith reviewed 2026-06-26 15:39 UTC · model grok-4.3
The pith
Polymer science is shifting from manual experiments to autonomous discovery ecosystems where AI, data and automation form self-improving loops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Polymer research is entering an era of autonomous discovery in which data, simulation, reasoning and experimentation operate within self-improving feedback loops that continuously generate hypotheses, design materials, execute experiments and refine predictive models. By unifying molecular design, process optimization, experimental validation and industrial translation, such autonomous ecosystems establish a more predictive, reproducible and scalable paradigm for polymer innovation.
What carries the argument
Autonomous discovery ecosystems formed by interconnected feedback loops that link polymer databases, predictive AI models, and automated laboratories.
If this is right
- The focus of polymer research shifts from improving single predictive models to enabling seamless integration across computation, experimentation, and reasoning.
- Molecular design, process optimization, and industrial translation become unified within the same adaptive loops.
- Discovery cycles accelerate by replacing labor-intensive manual iteration with continuous hypothesis generation and model refinement.
- Reproducibility and scalability improve because each loop iteration incorporates new experimental outcomes directly into the shared models.
Where Pith is reading between the lines
- Similar loop-based ecosystems could be tested in adjacent fields such as small-molecule pharmaceuticals where multi-scale interactions also dominate.
- The approach implies that future polymer databases must be designed from the start for machine-readable feedback rather than human browsing.
- Industrial translation speed may increase if the same ecosystem that discovers a material can also optimize its manufacturing parameters without separate campaigns.
Load-bearing premise
Advances in data infrastructure, machine learning, AI models, and laboratory automation will converge into reliable, interconnected ecosystems that support decision-making across computation and experiment.
What would settle it
Sustained absence of any closed-loop AI-automated system that designs, synthesizes, tests, and iteratively improves a polymer with targeted performance gains beyond those achieved by conventional separate workflows.
Figures



read the original abstract
Polymeric materials underpin modern technologies spanning energy storage, microelectronics, healthcare and sustainable manufacturing. Yet their rational design remains exceptionally challenging because material performance emerges from complex interactions among molecular composition, chain architecture, processing history and hierarchical structural evolution across multiple length and time scales. Consequently, polymer research has long relied on labor-intensive experimentation and fragmented modeling approaches, limiting both mechanistic understanding and innovation efficiency. Recent advances in data infrastructure, machine learning, large artificial intelligence (AI) models and laboratory automation are beginning to reshape this landscape. Rather than functioning as isolated tools, polymer databases, predictive models, AI agents and automated laboratories are increasingly converging into interconnected discovery ecosystems. As a result, the central challenge is shifting from improving predictive accuracy alone to enabling reliable decision-making, adaptive learning and seamless integration across computation, experimentation and scientific reasoning. We argue that polymer science is entering an era of autonomous discovery, in which data, simulation, reasoning and experimentation operate within self-improving feedback loops that continuously generate hypotheses, design materials, execute experiments and refine predictive models. By unifying molecular design, process optimization, experimental validation and industrial translation, such autonomous ecosystems establish a more predictive, reproducible and scalable paradigm for polymer innovation, fundamentally transforming how polymer research is conducted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a perspective article arguing that polymer science is entering an era of autonomous discovery. It claims that advances in data infrastructure, machine learning, large AI models, and laboratory automation are converging from isolated tools into interconnected ecosystems. These ecosystems will enable self-improving feedback loops integrating data, simulation, reasoning, and experimentation to generate hypotheses, design materials, execute experiments, and refine models, thereby shifting the central challenge to reliable decision-making and adaptive learning across computation, experimentation, and reasoning, ultimately establishing a more predictive, reproducible, and scalable paradigm for polymer innovation.
Significance. If the described convergence of data, AI, and automation materializes into functional autonomous ecosystems, the work would be significant for highlighting a potential paradigm shift in polymer research. It synthesizes observed trends to argue for faster innovation in applications such as energy storage, microelectronics, healthcare, and sustainable manufacturing, moving beyond fragmented modeling and labor-intensive experimentation. As a forward-looking perspective, it offers value in framing research directions, though its impact depends on the accuracy of the trend synthesis rather than new empirical or theoretical results.
minor comments (1)
- The abstract and introduction could benefit from one or two concrete, recent examples of partial convergence (e.g., a specific polymer database linked to an automated workflow) to ground the forward-looking claims without altering the perspective genre.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our perspective article and for recommending acceptance. The referee's summary correctly captures our central argument that polymer science is transitioning toward autonomous discovery ecosystems through the integration of data infrastructure, AI models, and laboratory automation.
Circularity Check
No significant circularity
full rationale
The manuscript is a perspective article presenting a forward-looking synthesis of trends in polymer science, data infrastructure, ML/AI, and lab automation. It contains no equations, no parameter fitting, no quantitative predictions, and no derivation chain. The central argument—that polymer research is shifting toward autonomous discovery ecosystems—is framed as an observed convergence of external advances rather than a result derived from internal definitions or self-citations. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Material performance emerges from complex interactions among molecular composition, chain architecture, processing history and hierarchical structural evolution across multiple length and time scales.
- domain assumption Recent advances in data infrastructure, machine learning, large artificial intelligence (AI) models and laboratory automation are beginning to reshape this landscape.
Reference graph
Works this paper leans on
-
[1]
Introduction Polymeric materials, macromolecules assembled from repeated monomer units, are indispensable to industrial manufacturing and high-tech applications such as automotive1, electronics2 and healthcare3. Representing the mainstream of polymeric materials, global plastic production totals approximately 431 million metric tons in 2025, and is expect...
2025
-
[2]
Polymeric Materials Databases Reliable and standardized data underpin all AI-powered polymer research. Polymers are governed by complex multiscale interactions among chemical composition, chain architecture, molecular-weight distributions, processing conditions, and hierarchical morphology, making the construction of dedicated data infrastructures substan...
-
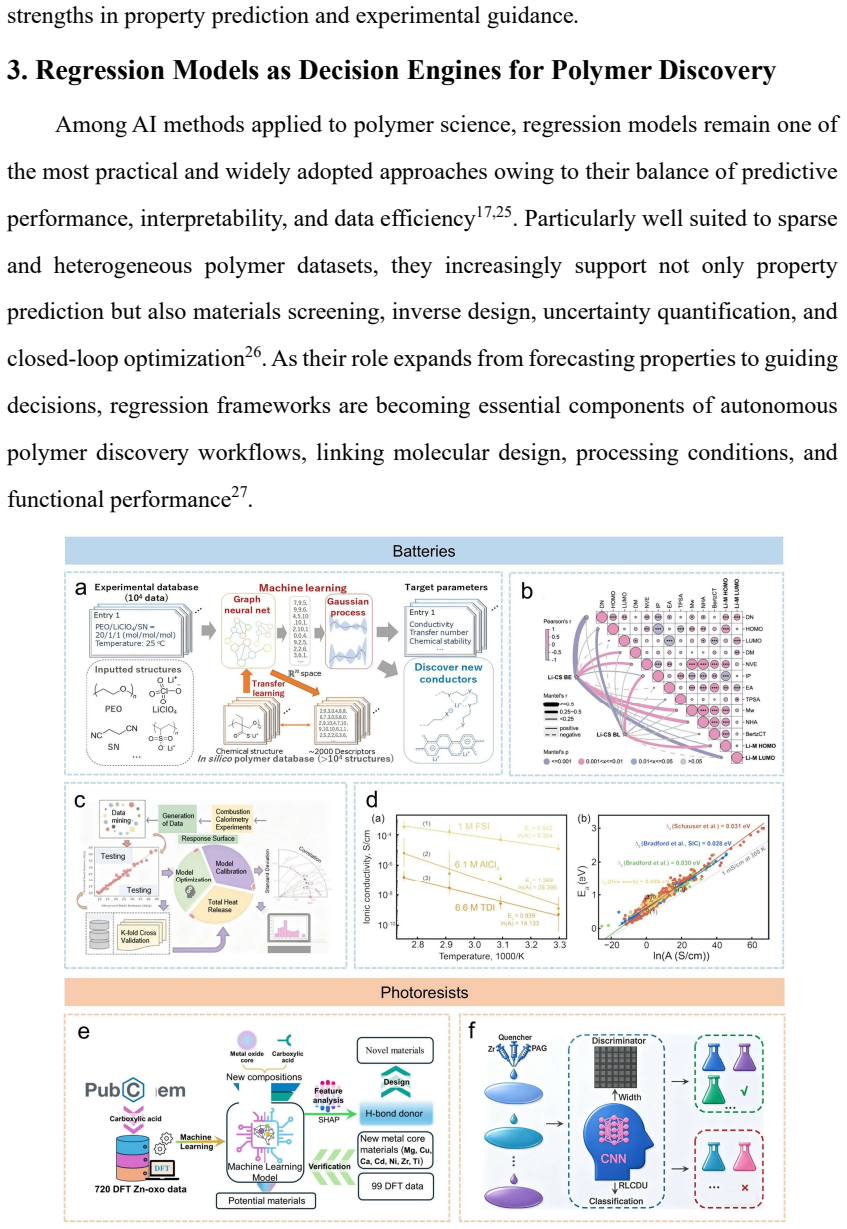
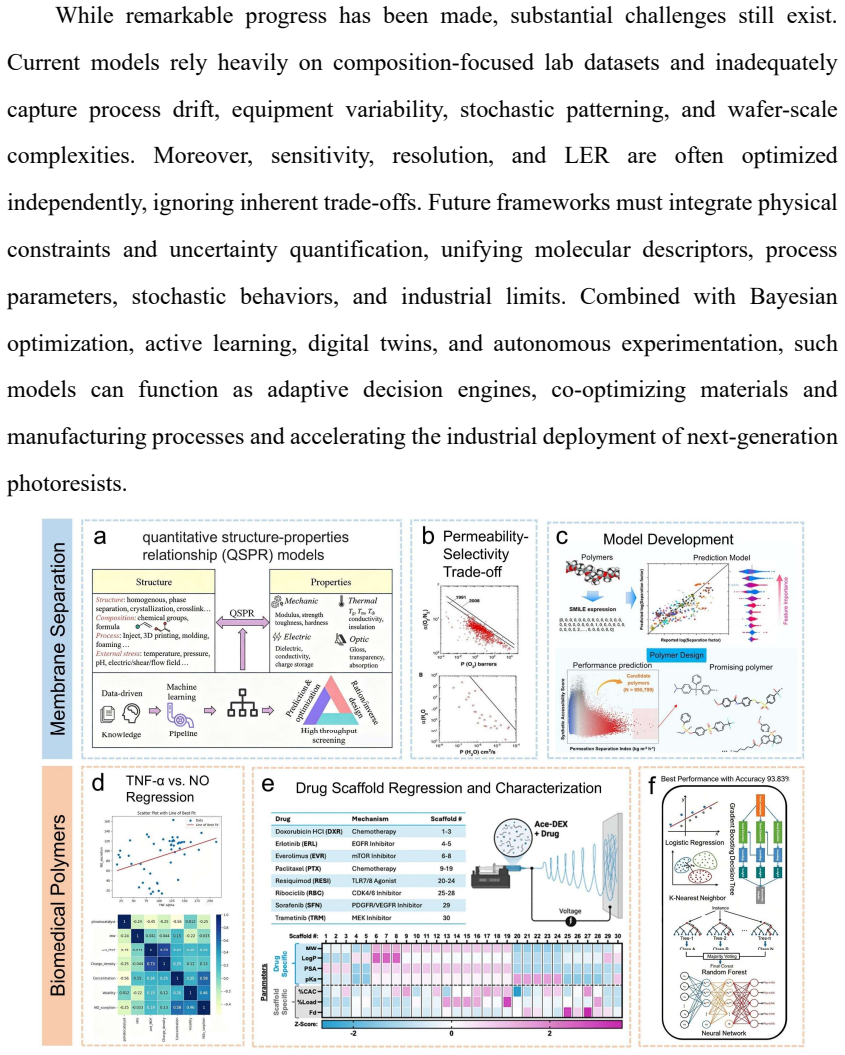
[3]
Regression Models as Decision Engines for Polymer Discovery Among AI methods applied to polymer science, regression models remain one of the most practical and widely adopted approaches owing to their balance of predictive performance, interpretability, and data efficiency17,25. Particularly well suited to sparse and heterogeneous polymer datasets, they i...
2020
-
[4]
Classical force fields can handle large amorphous systems and long trajectories but often fail to capture chemical transferability, polarization, or bond-breaking
MLIPs as the Physical Foundation of Polymer Discovery MLIPs are emerging as a key technology for bridging a persistent challenge in polymer science: connecting quantum-level chemistry with the length and time scales needed to predict realistic material behavior54 (Figure 5a-b). Classical force fields can handle large amorphous systems and long trajectorie...
2019
-
[5]
LLMs and AI Agents for Polymer Discovery The inherent multiscale hierarchical structures and pronounced processing- dependent properties of polymers pose fundamental challenges to conventional ML methods. Unlike small molecules and inorganic materials, polymers lack a universal molecular representation system, and traditional molecular descriptors fail to...
-
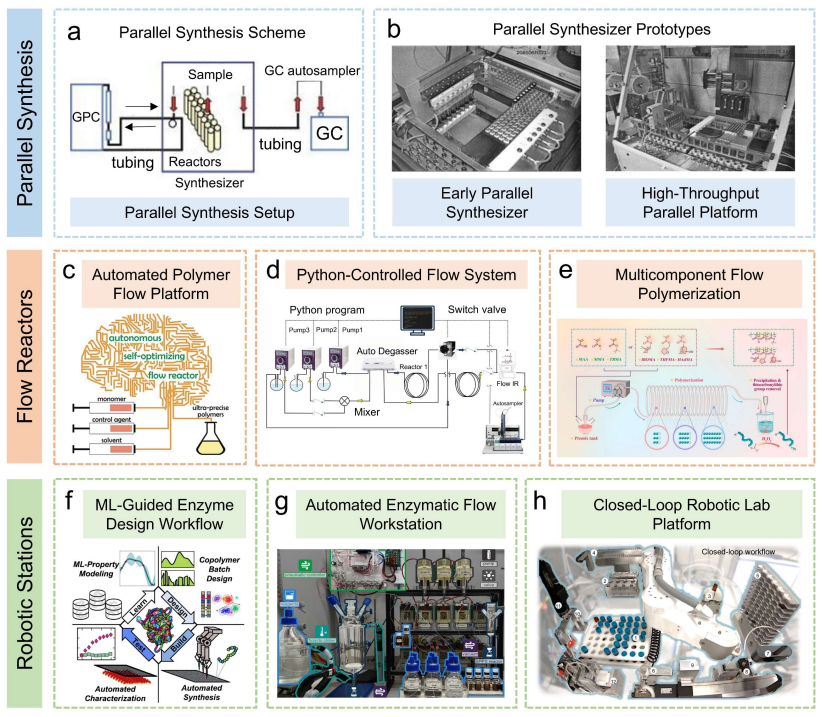
[6]
AI-Driven Polymeric Automated Synthesis Predictive models alone cannot achieve fully autonomous polymer discovery. Progress is hindered by the difficulty of generating high-quality, reproducible experimental data to validate models, explore untapped polymer design spaces, and optimize performance. Laboratory automation provides the essential experimental ...
2019
-
[7]
Standardized multiscale polymer databases provide fundamental structural, processing and performance data
AI-Enabled Polymeric Closed-Loop Autonomous polymer discovery is underpinned by a hierarchically integrated closed-loop ecosystem coupling computational modules and automated experiments14. Standardized multiscale polymer databases provide fundamental structural, processing and performance data. Regression models enable rapid structure–property prediction...
-
[8]
Summary and Outlook Modern polymer research is evolving rapidly from empirical trial-and-error toward a digital, intelligent, and autonomous innovation paradigm. Driven by multiscale material data accumulation, machine learning algorithms, and LLM-based intelligent agents, polymer R&D is shifting from passive verification of known rules to active explorat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.