ReLaTS: a Reinforcement Learning-based method for dynamically determining the coupling Time Step in multi-scale simulations of self-gravitating systems
Pith reviewed 2026-06-26 15:15 UTC · model grok-4.3
The pith
Reinforcement learning selects coupling time steps dynamically to keep energy errors below a preset threshold in multi-scale star cluster simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
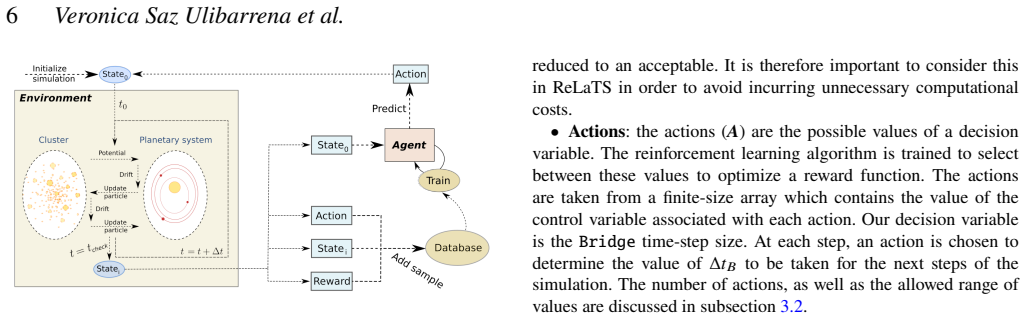
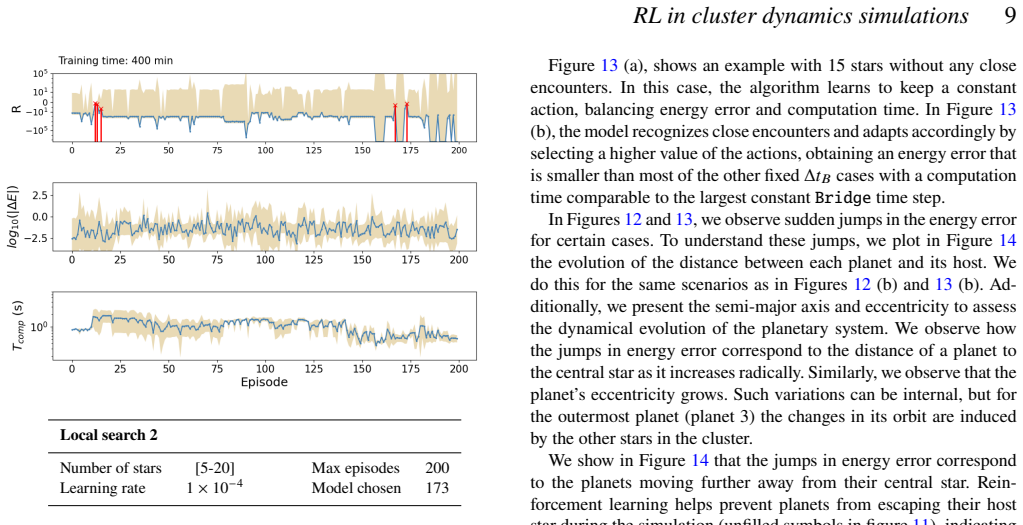
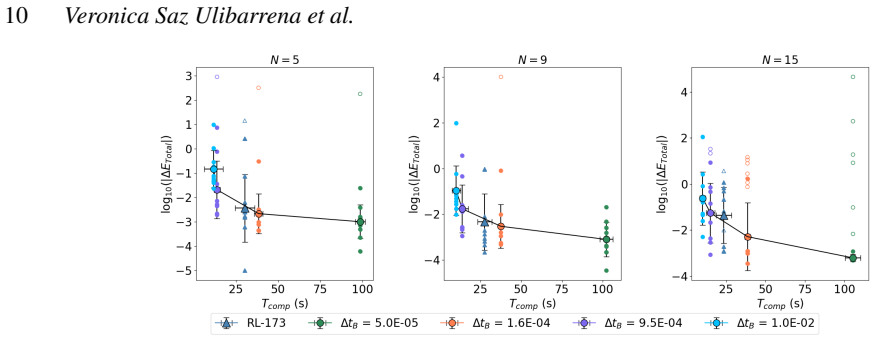
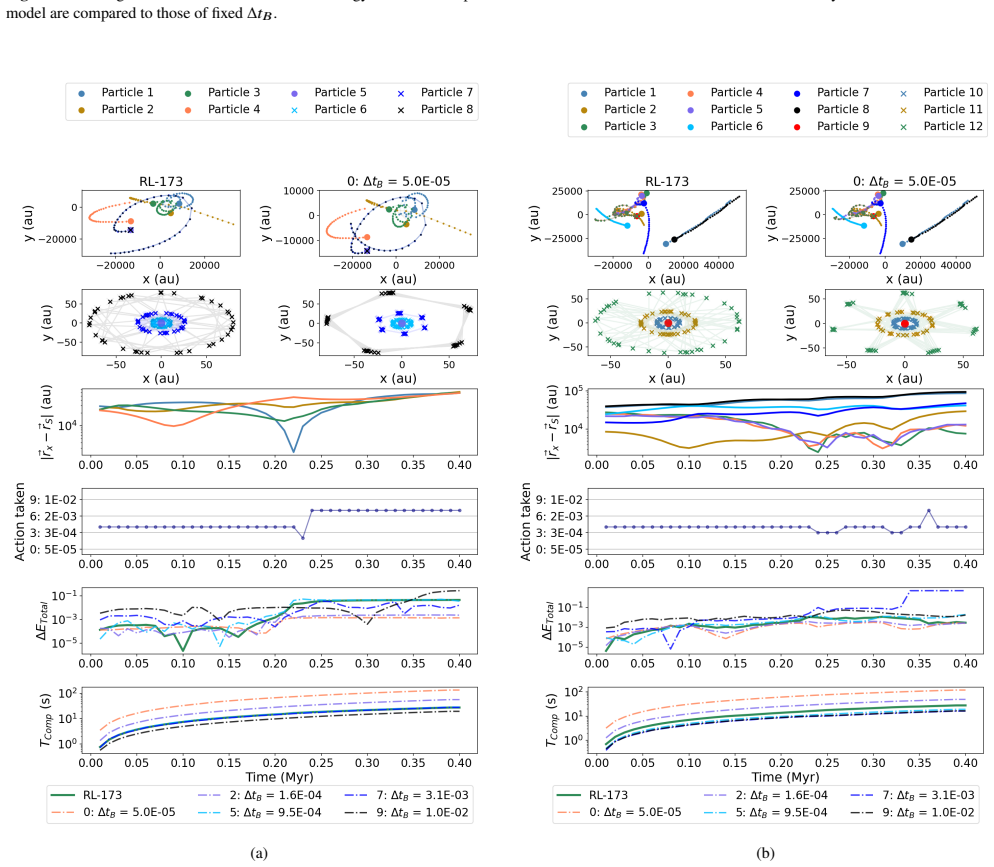
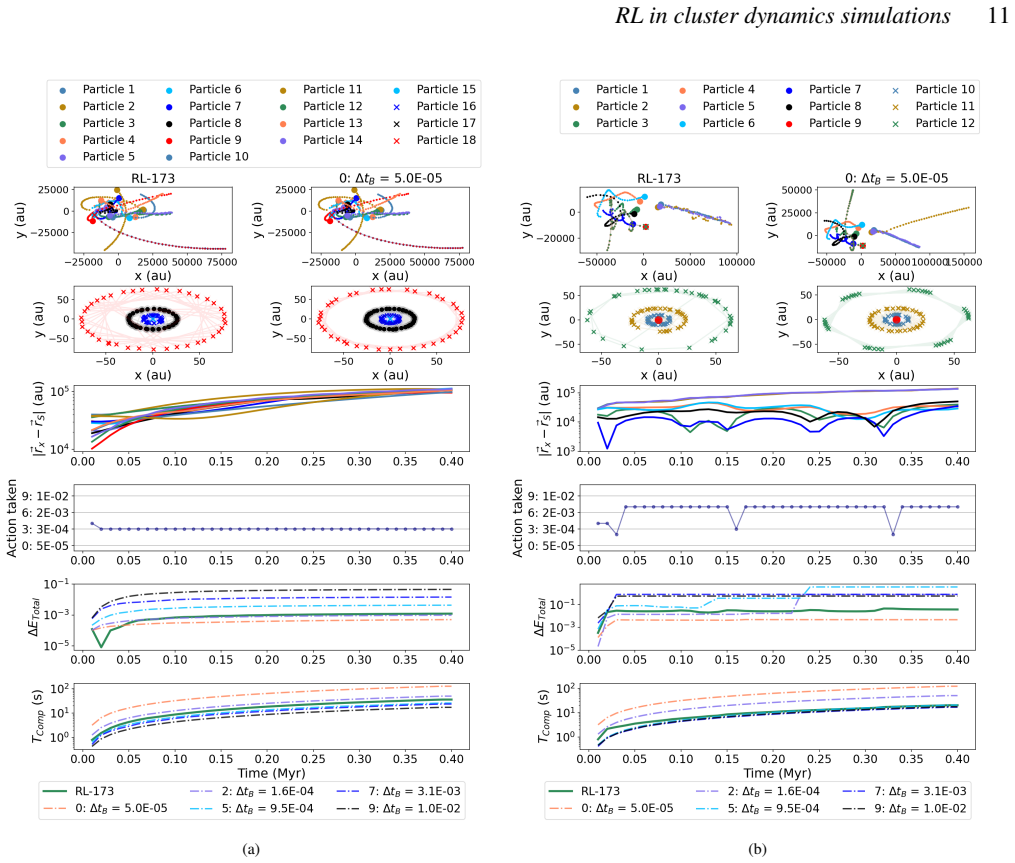
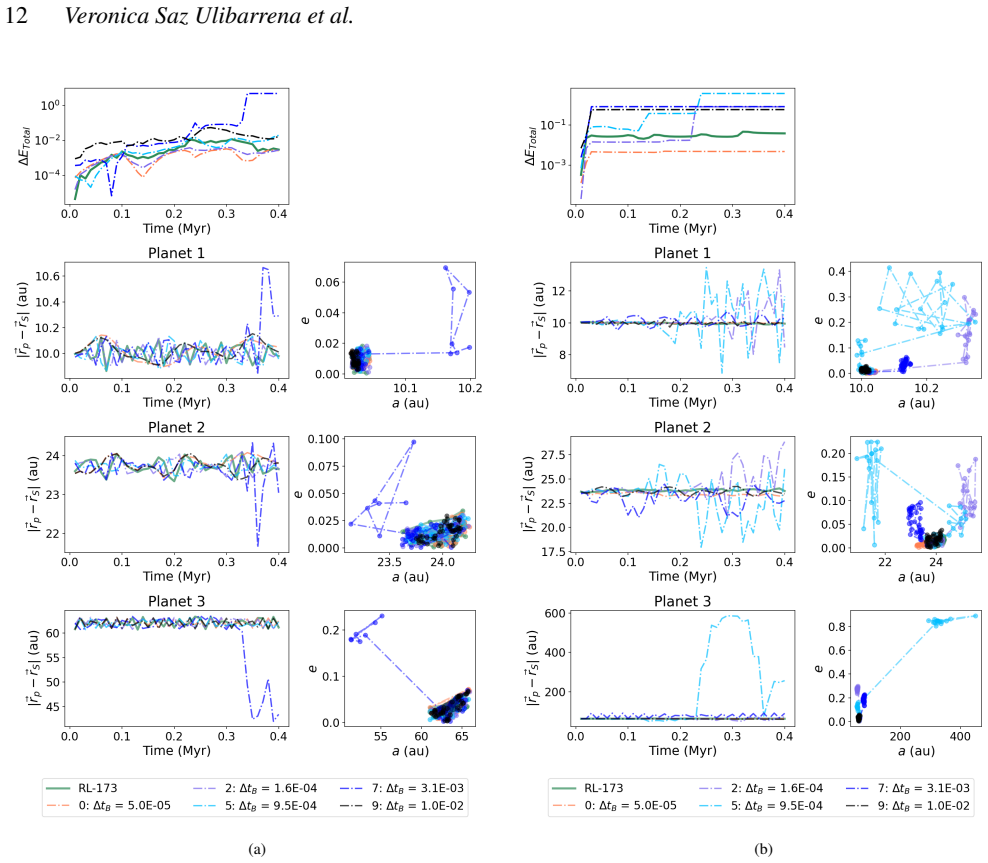
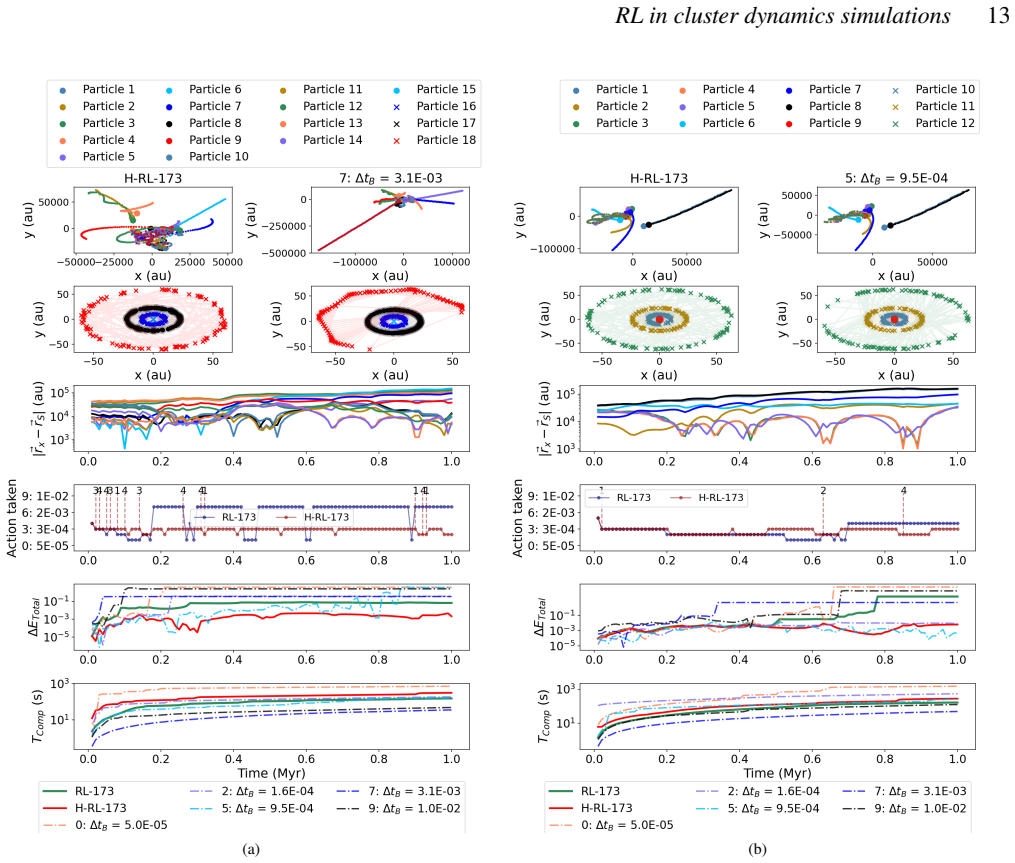
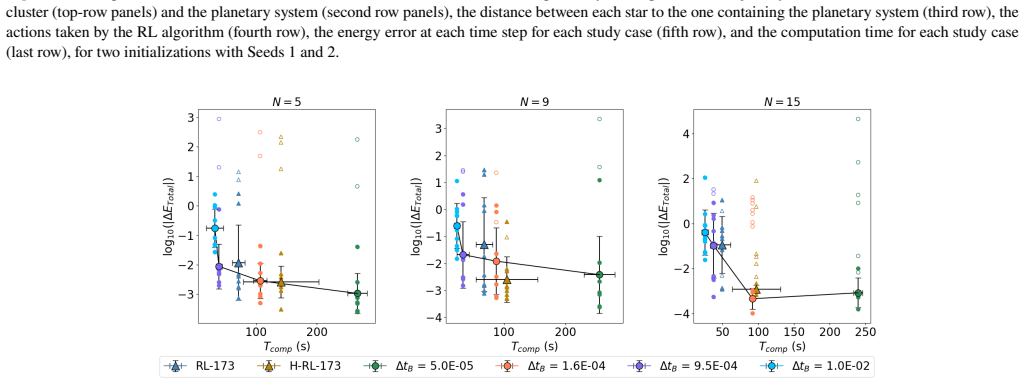
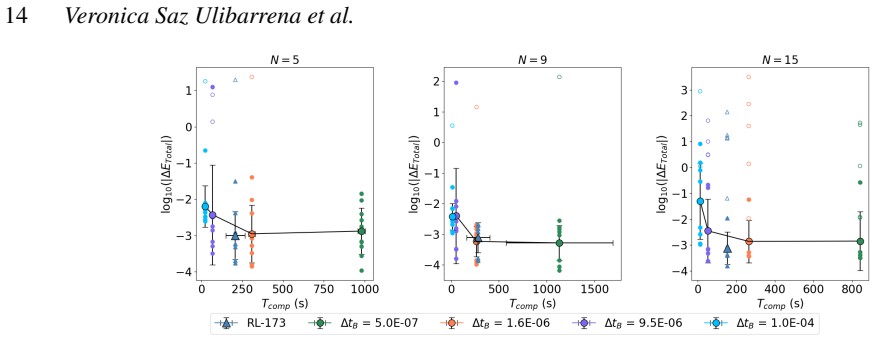
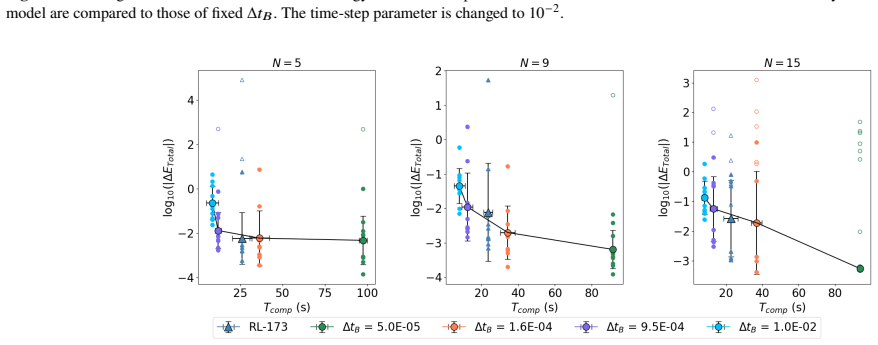
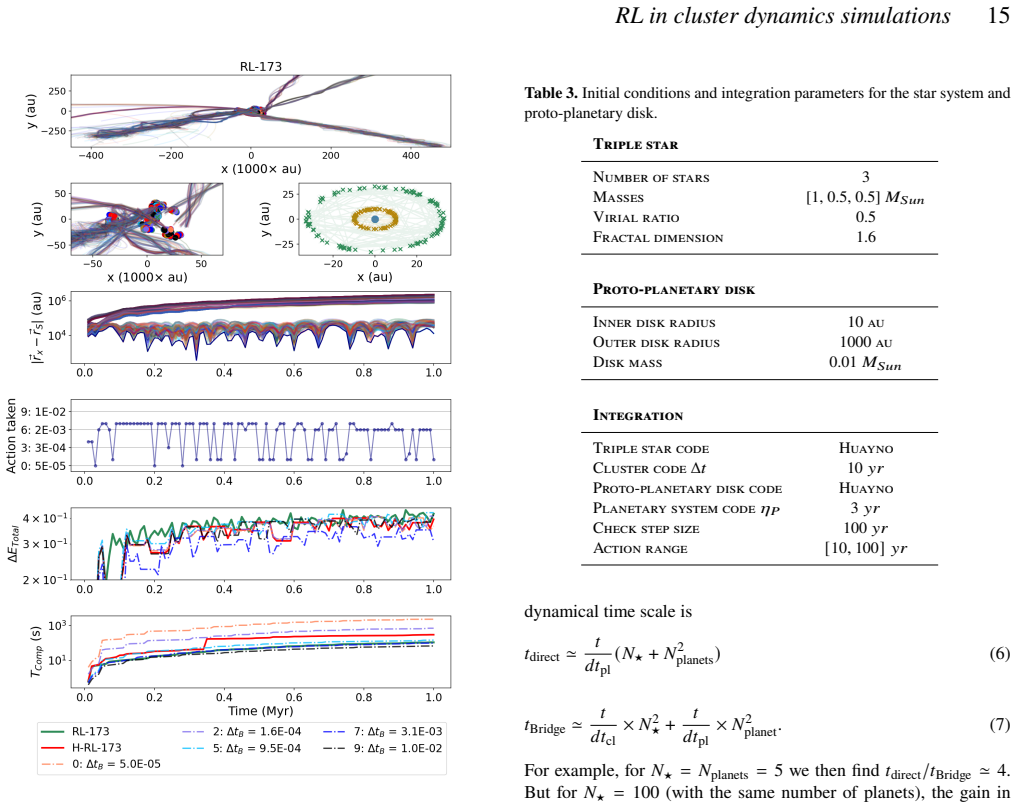
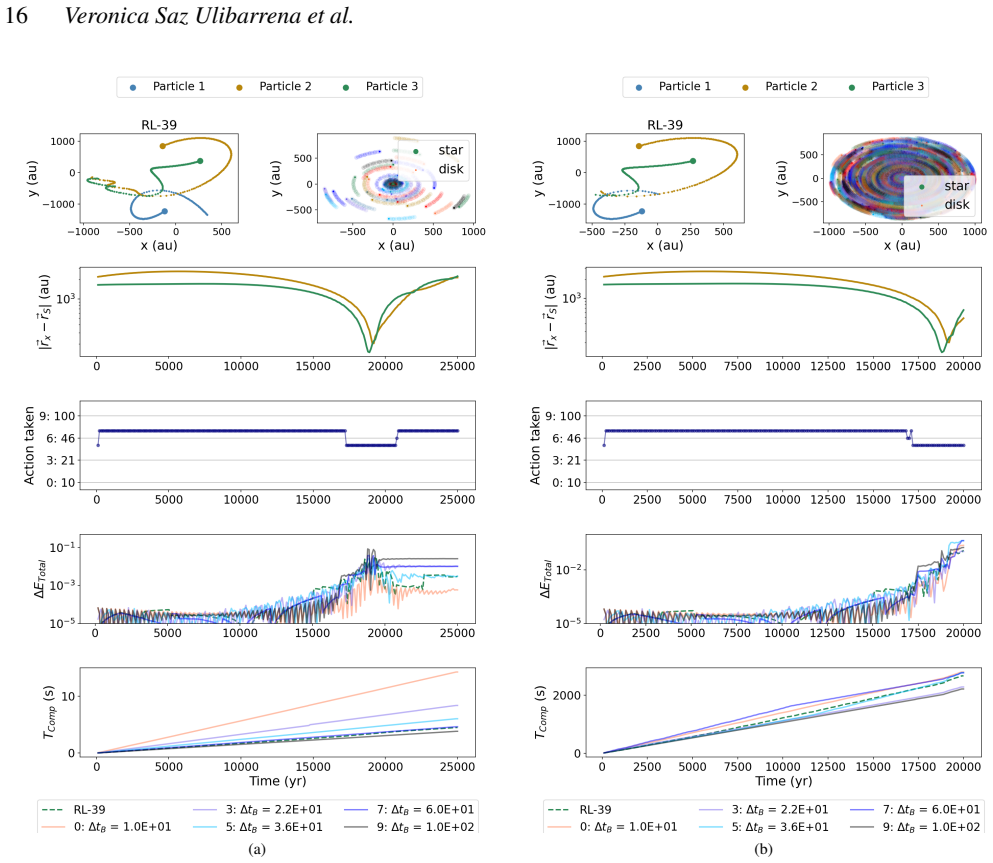
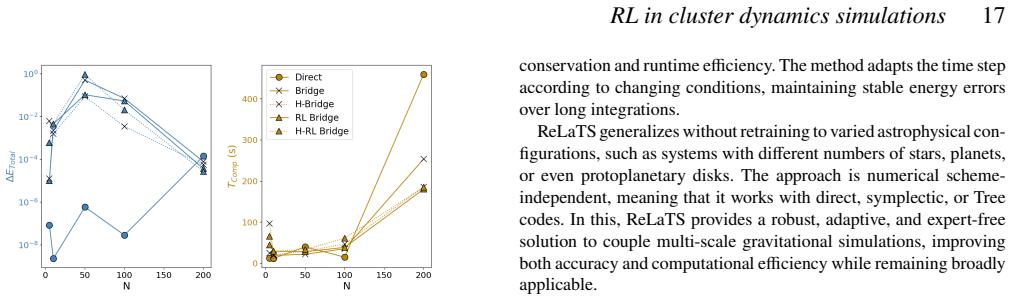
The reinforcement learning algorithm selects the coupling time step dynamically to balance accuracy and cost, keeping the energy error below a preset threshold in simulations of star clusters with planetary systems. This holds across variations in the number of stars and planets, and the network generalizes independently of the specific N-body integrators used.
What carries the argument
The reinforcement learning agent that observes the simulation state and outputs the next coupling time step to optimize the accuracy-cost tradeoff.
If this is right
- Energy errors remain controlled below the threshold even in long-time integrations of large N systems.
- The method requires no expert tuning once the network is trained.
- Performance stays stable when changing the number of stars or planets in the setup.
- Computational overhead stays low while improving accuracy over fixed-time-step methods.
Where Pith is reading between the lines
- Similar RL agents could be trained for other multi-physics simulations where coupling timescales are hard to set manually.
- The approach might allow simulations with larger particle numbers by adapting the coupling without increasing overall cost.
- Extending the state representation to include individual body errors could improve reliability for low-mass objects.
Load-bearing premise
The reinforcement learning agent can recognize and correct for integration errors even when some bodies have masses so small that they contribute negligibly to the total energy.
What would settle it
Running the trained agent on a system containing a planet whose mass is negligible compared with the stars and measuring whether the total energy error still exceeds the preset threshold.
Figures
read the original abstract
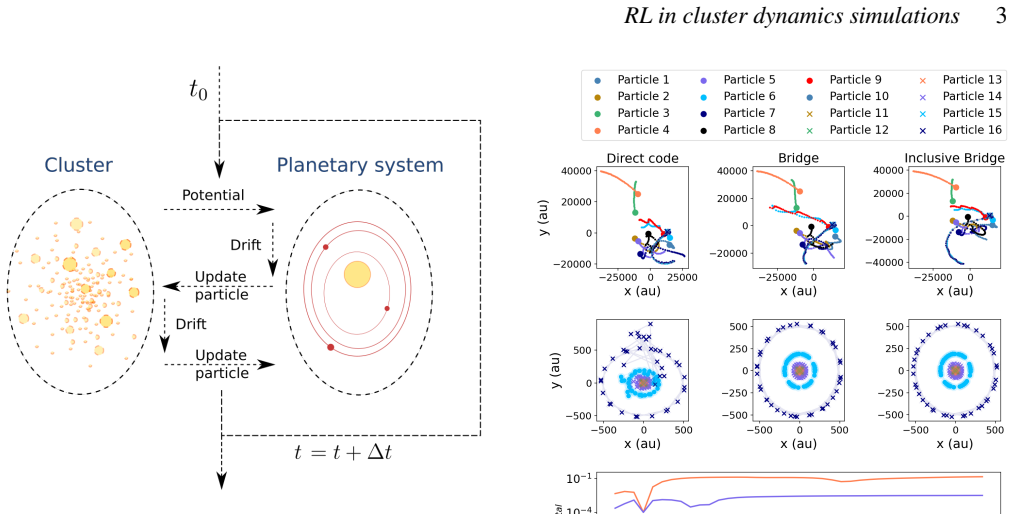
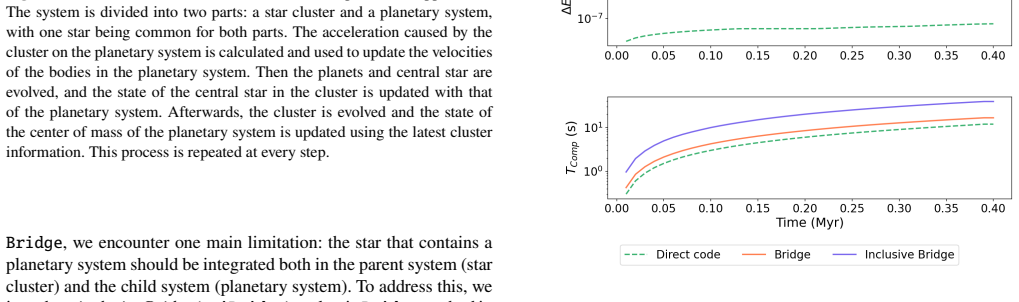
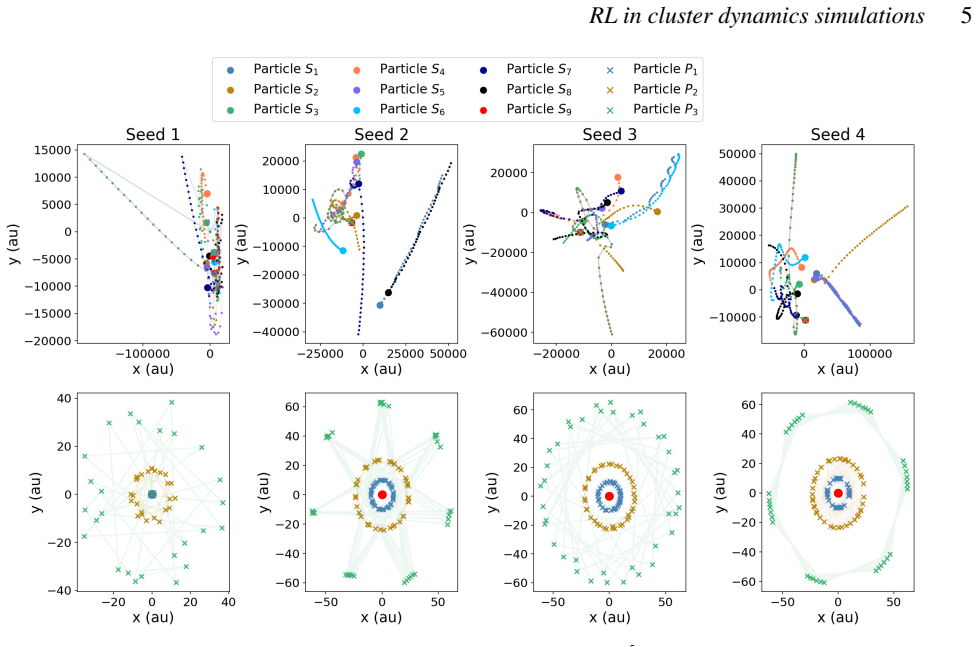
Astrophysical simulations frequently address multi-scale, multi-physics problems through subsystem decomposition, problem-tailored integration schemes, and coupling on fixed manually set timescales. Here we introduce ReLaTS, a reinforcement learning framework that dynamically selects the coupling time step to optimize the trade-off between accuracy and computational cost. We validate ReLaTS on star clusters containing a planetary system, and test the method by varying the number of stars $N_\star$ in the cluster and the number of planets ($N_{\rm planet}$) orbiting one of them. The method finds the optimal coupling time step that balances speed and accuracy without requiring expert knowledge. In addition, the trained network operates independently of the coupled \textit{N}-body algorithms, displaying stable performance across a range of setups. We observe that the method is less reliable for cases with infinitesimal masses, as their contribution to the total energy is negligible compared to that of the massive bodies, and the network is not capable of recognizing potential errors generated while integrating them. For long-time integration of large $N$ systems, the error accumulates. The reinforcement learning algorithm, however, manages to keep the energy error below a pre-set threshold. This approach substantially reduces energy errors relative to fixed-time step baselines without substantial additional computational overhead. Once trained, ReLaTS requires no expert tuning and generalizes across diverse astrophysical domains, enabling adaptive multi-scale simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReLaTS, a reinforcement learning framework for dynamically selecting the coupling time step between subsystems in multi-scale N-body simulations of self-gravitating systems. It validates the approach on star clusters containing a planetary system by varying N_star and N_planet, claiming that the trained network keeps total energy error below a preset threshold, substantially reduces errors relative to fixed-step baselines without major overhead, operates independently of the underlying N-body integrators, and generalizes across setups without expert tuning (with the explicit caveat that performance is less reliable for infinitesimal masses whose energy contribution is negligible).
Significance. If the quantitative validation supports the claims, the method would address a common practical bottleneck in coupled multi-scale astrophysical simulations by removing the need for manual coupling timescale selection. The reported independence from specific N-body algorithms and the use of RL to balance accuracy versus cost are potentially useful strengths for the field.
major comments (2)
- [Abstract] Abstract: The central claim that the RL policy 'manages to keep the energy error below a pre-set threshold' and 'substantially reduces energy errors relative to fixed-time step baselines' across the tested setups is load-bearing, yet the abstract itself notes reduced reliability for infinitesimal masses because 'their contribution to the total energy is negligible' and the network cannot recognize their integration errors. In the star-cluster-plus-planets validation, planets already form a mass hierarchy; if the reward is dominated by the stellar component, there is no demonstrated mechanism ensuring the agent shortens steps when low-mass orbital errors accumulate. This directly weakens both the error-reduction claim and the assertion of 'stable performance across a range of setups.'
- [Abstract] Abstract (validation description): The generalization claim rests on tests that vary N_star and N_planet, but no quantitative metrics, error bars, training details, or separate tracking of low-mass subsystem errors are referenced. Without these, it is impossible to verify whether the energy-error threshold is maintained when the low-mass bodies' contribution is negligible yet their long-term dynamics remain relevant.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our claims. We address each major comment below and will revise the abstract accordingly to improve precision and substantiation of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the RL policy 'manages to keep the energy error below a pre-set threshold' and 'substantially reduces energy errors relative to fixed-time step baselines' across the tested setups is load-bearing, yet the abstract itself notes reduced reliability for infinitesimal masses because 'their contribution to the total energy is negligible' and the network cannot recognize their integration errors. In the star-cluster-plus-planets validation, planets already form a mass hierarchy; if the reward is dominated by the stellar component, there is no demonstrated mechanism ensuring the agent shortens steps when low-mass orbital errors accumulate. This directly weakens both the error-reduction claim and the assertion of 'stable performance across a range of setups.'
Authors: The reward is computed from the total energy error of the full system, providing a mechanism that in principle responds to errors from all components. However, we acknowledge that when low-mass bodies contribute negligibly to total energy, their orbital errors are not effectively detected, as stated in the abstract. This is a genuine limitation of the current reward design rather than a flaw in the reported results for the tested mass hierarchies. We will revise the abstract to explicitly delimit the mass regimes where the error-reduction and stability claims hold, and to note that separate low-mass error tracking is not performed because the method optimizes total energy. revision: yes
-
Referee: [Abstract] Abstract (validation description): The generalization claim rests on tests that vary N_star and N_planet, but no quantitative metrics, error bars, training details, or separate tracking of low-mass subsystem errors are referenced. Without these, it is impossible to verify whether the energy-error threshold is maintained when the low-mass bodies' contribution is negligible yet their long-term dynamics remain relevant.
Authors: The abstract is a concise summary; quantitative metrics, error bars, and training details appear in the main text and figures. We agree that the abstract should better reference these to support the generalization claim. We will revise it to include brief quantitative statements on the tested ranges of N_star and N_planet, the observed energy-error reductions relative to fixed-step baselines, and an explicit note that low-mass subsystem errors are not tracked separately. revision: yes
Circularity Check
No circularity: RL policy trained and validated on independent multi-scale test cases
full rationale
The paper trains an RL agent to select coupling timesteps and validates performance via direct empirical comparison against fixed-timestep baselines on held-out configurations (varying N_star and N_planet). No derivation step reduces to a fitted parameter renamed as prediction, no self-citation supplies a uniqueness theorem, and the energy-error threshold is an external reward target rather than a self-defined output. The method is explicitly noted as less reliable for negligible-mass bodies, but this is an acknowledged limitation rather than a circular reduction. The central claims rest on observable simulation outcomes, not on any input-output equivalence by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Energy error serves as a sufficient and observable reward signal for learning an optimal accuracy-cost trade-off in coupling decisions.
Reference graph
Works this paper leans on
-
[1]
A., 2003
Aarseth , S. A., 2003. Gravitational N-body simulations \/ , Cambdridge University press, 2003
2003
-
[2]
Aarseth , S. J. & Lecar , M., 1975. Computer simulations of stellar systems , Annual Review of Astronomy and Astrophysics\/ , 13 , 1--88
1975
-
[3]
& Hut, P., 1986
Barnes, J. & Hut, P., 1986. A hierarchical o (n log n) force-calculation algorithm, nature\/ , 324 (6096), 446--449
1986
-
[4]
& Portegies Zwart , S., 2015
Boekholt , T. & Portegies Zwart , S., 2015. On the reliability of N-body simulations , Computational Astrophysics and Cosmology\/ , 2 , 2
2015
-
[5]
G., Foley , C
Breen , P. G., Foley , C. N., Boekholt , T., & Portegies Zwart , S., 2020. Newton versus the machine: solving the chaotic three-body problem using deep neural networks , \/ , 494 (2), 2465--2470
2020
-
[6]
E., 2021
Cai, S., Wang, Z., Wang, S., Perdikaris, P., & Karniadakis, G. E., 2021. Physics-informed neural networks for heat transfer problems, Journal of Heat Transfer\/ , 143 (6), 060801
2021
-
[7]
Fujii, M., Iwasawa, M., Funato, Y., & Makino, J., 2007. Bridge: A direct-tree hybrid-body algorithm for fully self-consistent simulations of star clusters and their parent galaxies, Publications of the Astronomical Society of Japan\/ , 59 (6), 1095--1106
2007
-
[8]
Goodwin, S. P. & Whitworth, A. P., 2004. The dynamical evolution of fractal star clusters: The survival of substructure, Astronomy & Astrophysics\/ , 413 (3), 929--937
2004
-
[9]
Hamiltonian neural networks, Advances in neural information processing systems\/ , 32
Greydanus, S., Dzamba, M., & Yosinski, J., 2019. Hamiltonian neural networks, Advances in neural information processing systems\/ , 32
2019
-
[10]
Soft Actor-Critic Algorithms and Applications
Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P., et al., 2018. Soft actor-critic algorithms and applications, arXiv preprint arXiv:1812.05905\/
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
& Hut , P., 2003
Heggie , D. & Hut , P., 2003. The Gravitational Million-Body Problem: A Multidisciplinary Approach to Star Cluster Dynamics \/ , The Gravitational Million-Body Problem: A Multidisciplinary Approach to Star Cluster Dynamics, by Douglas Heggie and Piet Hut. Cambridge University Press, 2003, 372 pp
2003
-
[12]
A connected component-based method for efficiently integrating multi-scale n-body systems, Astronomy & Astrophysics\/ , 570 , A20
J \"a nes, J., Pelupessy, I., & Portegies Zwart, S., 2014. A connected component-based method for efficiently integrating multi-scale n-body systems, Astronomy & Astrophysics\/ , 570 , A20
2014
-
[13]
& Ida, S., 2002
Kokubo, E. & Ida, S., 2002. Formation of protoplanet systems and diversity of planetary systems, The Astrophysical Journal\/ , 581 (1), 666
2002
-
[14]
Playing Atari with Deep Reinforcement Learning
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M., 2013. Playing atari with deep reinforcement learning, arXiv preprint arXiv:1312.5602\/
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
A., Veness, J., Bellemare, M
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al., 2015. Human-level control through deep reinforcement learning, nature\/ , 518 (7540), 529--533
2015
-
[16]
& Towers, M., 2025
Paszke, A. & Towers, M., 2025. Reinforcement learning (dqn) tutorial
2025
-
[17]
I., J \"a nes , J., & Portegies Zwart , S., 2012
Pelupessy , F. I., J \"a nes , J., & Portegies Zwart , S., 2012. N-body integrators with individual time steps from Hierarchical splitting , New Astronomy\/ , 17 , 711--719
2012
-
[18]
& McMillan , S., 2018
Portegies Zwart , S. & McMillan , S., 2018. Astrophysical Recipes; The art of AMUSE \/
2018
-
[19]
Portegies Zwart , S., McMillan , S., Harfst , S., Groen , D., Fujii , M., Nuall \'a in , B. \'O ., Glebbeek , E., Heggie , D., Lombardi , J., Hut , P., Angelou , V., Banerjee , S., Belkus , H., Fragos , T., Fregeau , J., Gaburov , E., Izzard , R., Juri \'c , M., Justham , S., Sottoriva , A., Teuben , P., van Bever , J., Yaron , O., & Zemp , M., 2009. A mu...
2009
-
[20]
Non-intrusive hierarchical coupling strategies for multi-scale simulations in gravitational dynamics, Communications in Nonlinear Science and Numerical Simulation\/ , 85 , 105240
Portegies Zwart, S., Pelupessy, I., Mart \' nez-Barbosa, C., van Elteren, A., & McMillan, S., 2020. Non-intrusive hierarchical coupling strategies for multi-scale simulations in gravitational dynamics, Communications in Nonlinear Science and Numerical Simulation\/ , 85 , 105240
2020
-
[21]
Astrophysical Recipes; The art of AMUSE \/ , 2514-3433, IOP Publishing
Portegies Zwart , S., McMillan , S., & Rieder , S., 2026. Astrophysical Recipes; The art of AMUSE \/ , 2514-3433, IOP Publishing
2026
-
[22]
F., McMillan, S
Portegies Zwart, S. F., McMillan, S. L., van Elteren, A., Pelupessy, F. I., & de Vries, N., 2013. Multi-physics simulations using a hierarchical interchangeable software interface, Computer Physics Communications\/ , 184 (3), 456--468
2013
-
[23]
F., Boekholt , T
Portegies Zwart , S. F., Boekholt , T. C. N., Por , E. H., Hamers , A. S., & McMillan , S. L. W., 2022. Chaos in self-gravitating many-body systems. Lyapunov time dependence of N and the influence of general relativity , \/ , 659 , A86
2022
-
[24]
E., 1955
Salpeter, E. E., 1955. The luminosity function and stellar evolution., Astrophysical Journal, vol. 121, p. 161\/ , 121 , 161
1955
-
[25]
& Portegies Zwart, S., 2025
Saz Ulibarrena, V. & Portegies Zwart, S., 2025. Reinforcement learning for adaptive time-stepping in the chaotic gravitational three-body problem, Communications in Nonlinear Science and Numerical Simulation\/ , 145
2025
-
[26]
X., 2024
Saz Ulibarrena, V., Horn, P., Portegies Zwart, S., Sellentin, E., Koren, B., & Cai, M. X., 2024. A hybrid approach for solving the gravitational n-body problem with artificial neural networks, Journal of Computational Physics\/ , 496 , 112596
2024
-
[27]
Sutton, R. S. & Barto, A. G., 2018. Reinforcement learning: An introduction\/ , MIT press
2018
-
[28]
The statistical mechanics of planet orbits, The Astrophysical Journal\/ , 807 (2), 157
Tremaine, S., 2015. The statistical mechanics of planet orbits, The Astrophysical Journal\/ , 807 (2), 157
2015
-
[29]
A review on deep reinforcement learning for fluid mechanics: An update, Physics of Fluids\/ , 34 (11), 111301
Viquerat, J., Meliga, P., Larcher, A., & Hachem, E., 2022. A review on deep reinforcement learning for fluid mechanics: An update, Physics of Fluids\/ , 34 (11), 111301
2022
-
[30]
Historical best q-networks for deep reinforcement learning, in 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI)\/ , pp
Yu, W., Wang, R., Li, R., Gao, J., & Hu, X., 2018. Historical best q-networks for deep reinforcement learning, in 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI)\/ , pp. 6--11, IEEE
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.