SciLens: Multi-modal Scientific Claim Verification with Agentic Entailment and Grounding
Pith reviewed 2026-06-26 17:16 UTC · model grok-4.3
The pith
SciLens supports a scientific claim only when every central empirical atom is entailed by the multimodal evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
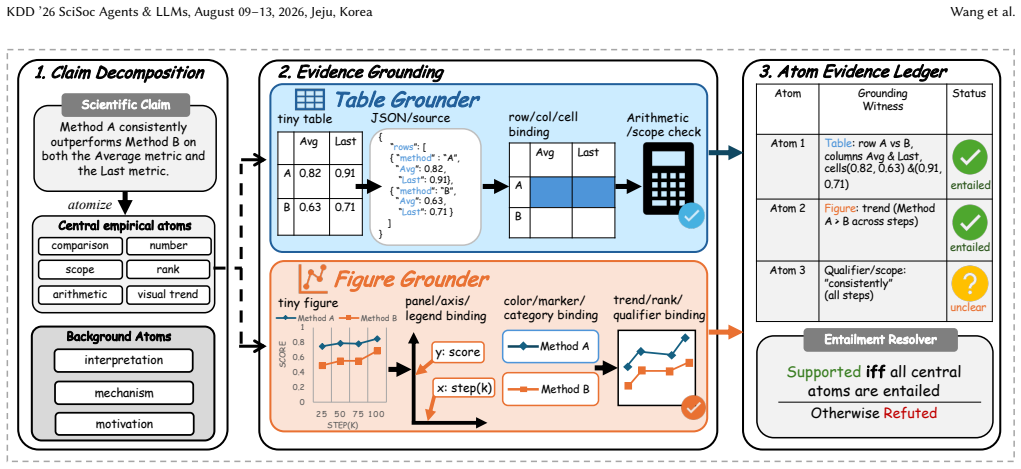
SciLens decomposes each claim into central empirical atoms and background atoms, grounds the central atoms to modality-specific evidence witnesses, and predicts the final label with an atom-level entailment rule. For tables, atoms are grounded to rows, columns, cells, arithmetic relations, and table scope; for figures, they are grounded through panels, axes, legends, visual encodings, categories, trends, ranks, and qualifier checks. This yields a unified validation procedure in which a claim is supported only if every central empirical atom is entailed by the current evidence.
What carries the argument
The atom-level entailment rule that requires every central empirical atom to be entailed after grounding to modality-specific evidence witnesses.
If this is right
- Claims that combine numerical results, comparisons, scope qualifiers, and explanatory context receive more precise validation than direct model judgments.
- Evidence sensitivity rises because each central atom must be tied to concrete witnesses such as table cells or figure trends.
- Interpretability increases as the validation procedure identifies which atoms support or refute the claim.
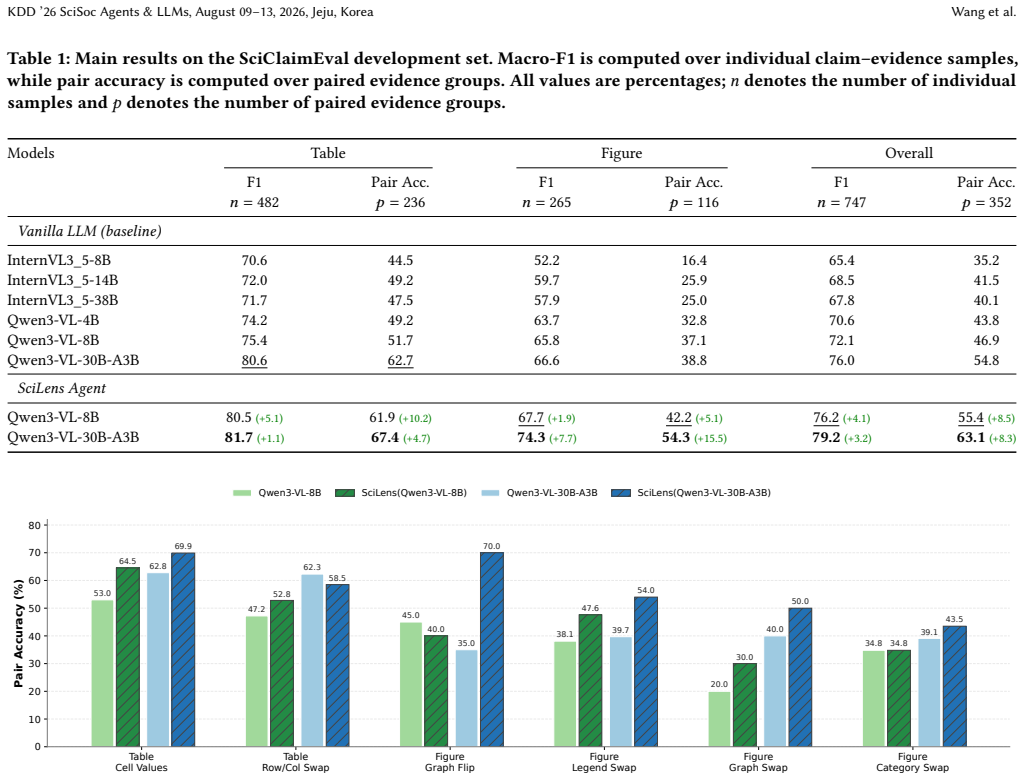
- Performance reaches 79.2 percent macro-F1 and 63.1 percent pair accuracy on the SciClaimEval development set.
Where Pith is reading between the lines
- The same grounding and entailment structure could be extended to additional modalities such as equations or diagrams if new witness types are defined.
- Systems built on explicit atom decomposition may show better robustness when claims are revised or when evidence sources change.
- The separation of central and background atoms invites tests on whether background atoms ever need to constrain the entailment check itself.
Load-bearing premise
Scientific claims can be decomposed into central empirical atoms and background atoms without loss of meaning, and these atoms can be reliably grounded to specific evidence witnesses in tables and figures.
What would settle it
A collection of claims on a new test set in which all central atoms are individually entailed yet the overall claim is false because an interaction between a central atom and a background qualifier was missed by the decomposition.
Figures
read the original abstract
Scientific discovery increasingly relies on automated systems that generate hypotheses, inspect multimodal evidence, and validate claims at scale. Yet scientific claim verification is not well served by asking a vision-language model for a direct binary judgment: claims often combine numerical results, comparisons, scope qualifiers, and explanatory context, while evidence is encoded in tables and figures with distinct grounding structures. We present SciLens, an evidence-conditioned atomic entailment framework for multimodal scientific claim verification. SciLens decomposes each claim into central empirical atoms and background atoms, grounds the central atoms to modality-specific evidence witnesses, and predicts the final label with an atom-level entailment rule. For tables, atoms are grounded to rows, columns, cells, arithmetic relations, and table scope; for figures, they are grounded through panels, axes, legends, visual encodings, categories, trends, ranks, and qualifier checks. This yields a unified validation procedure in which a claim is supported only if every central empirical atom is entailed by the current evidence. On the SciClaimEval development set, SciLens achieves 79.2% macro-F1 and 63.1% pair accuracy, showing that structured agentic validation improves both evidence sensitivity and interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. SciLens is an evidence-conditioned atomic entailment framework for multimodal scientific claim verification. It decomposes each claim into central empirical atoms and background atoms, grounds the central atoms to modality-specific evidence witnesses (e.g., rows/columns/cells for tables; panels/axes/legends for figures), and applies an atom-level entailment rule requiring every central empirical atom to be supported by the evidence. The paper reports 79.2% macro-F1 and 63.1% pair accuracy on the SciClaimEval development set, claiming improved sensitivity and interpretability over direct VLM binary judgments.
Significance. If the empirical results and decomposition procedure hold under scrutiny, the work offers a structured alternative to opaque VLM judgments for scientific claims involving numerical results, comparisons, and multimodal evidence. The explicit grounding to table/figure elements and the conjunction-style entailment rule could improve both auditability and error localization in automated verification pipelines.
major comments (2)
- [Abstract, §3] Abstract and §3 (decomposition procedure): the central claim that 'a claim is supported only if every central empirical atom is entailed' rests on the premise that decomposition into central empirical atoms plus background atoms preserves meaning without loss. No examples are provided of decomposition on claims containing conditional scopes, comparative qualifiers, or joint constraints across multiple results, nor is there a check that recombining entailed atoms recovers the source claim. This directly affects whether the atom-level rule can be guaranteed to match human verdicts on complex claims.
- [Evaluation] Evaluation section (dataset construction and protocol): the reported 79.2% macro-F1 and 63.1% pair accuracy are presented without details on how SciClaimEval was constructed, what baselines were used, error analysis by claim type (e.g., simple vs. conditional), or the exact evaluation protocol. These omissions make it impossible to assess whether the numbers support the claim of improved evidence sensitivity.
minor comments (2)
- [Abstract] Notation for 'central empirical atoms' vs. 'background atoms' is introduced in the abstract but would benefit from an explicit formal definition or example table/figure early in the paper.
- [Abstract] The abstract mentions 'agentic entailment' but does not clarify the precise role of any agent loop versus a single-pass grounding procedure.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (decomposition procedure): the central claim that 'a claim is supported only if every central empirical atom is entailed' rests on the premise that decomposition into central empirical atoms plus background atoms preserves meaning without loss. No examples are provided of decomposition on claims containing conditional scopes, comparative qualifiers, or joint constraints across multiple results, nor is there a check that recombining entailed atoms recovers the source claim. This directly affects whether the atom-level rule can be guaranteed to match human verdicts on complex claims.
Authors: We agree that the current version of §3 would be strengthened by explicit examples of decomposition for claims involving conditional scopes, comparative qualifiers, and joint constraints. In the revised manuscript we will add a new subsection with several such examples, including a verification step showing that recombining the entailed atoms recovers the original claim. These additions will provide direct evidence that the atom-level entailment rule aligns with human interpretation on complex cases. revision: yes
-
Referee: [Evaluation] Evaluation section (dataset construction and protocol): the reported 79.2% macro-F1 and 63.1% pair accuracy are presented without details on how SciClaimEval was constructed, what baselines were used, error analysis by claim type (e.g., simple vs. conditional), or the exact evaluation protocol. These omissions make it impossible to assess whether the numbers support the claim of improved evidence sensitivity.
Authors: We acknowledge that the evaluation section currently lacks sufficient detail on dataset construction, baselines, error analysis stratified by claim type, and the precise protocol. In the revision we will expand the Evaluation section with these elements, including a breakdown of performance on simple versus conditional claims and a clear description of the evaluation protocol. This will enable readers to better evaluate the reported metrics. revision: yes
Circularity Check
No significant circularity; empirical performance report with no derivations or self-referential fits
full rationale
The paper describes an agentic framework for multimodal claim verification that decomposes claims into atoms and applies entailment rules, then reports empirical metrics (79.2% macro-F1, 63.1% pair accuracy) on SciClaimEval. No equations, parameter fits, uniqueness theorems, or derivations appear in the abstract or described content. The central claim is a performance result on held-out data rather than a quantity obtained by construction from the method's own inputs. Self-citations, if present, are not load-bearing for any mathematical result because none exists. The decomposition premise is an engineering assumption whose validity is tested empirically rather than defined into the output. This matches the default case of a self-contained empirical system with no circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[2]
Zheye Deng, Chunkit Chan, Weiqi Wang, Yuxi Sun, Wei Fan, Tianshi Zheng, Yauwai Yim, and Yangqiu Song. 2024. Text-Tuple-Table: Towards Infor- mation Integration in Text-to-Table Generation via Global Tuple Extraction. arXiv:2404.14215 [cs.CL] https://arxiv.org/abs/2404.14215
arXiv 2024
-
[3]
Tianqing Fang, Zhisong Zhang, Xiaoyang Wang, Rui Wang, Can Qin, Yuxuan Wan, Jun-Yu Ma, Ce Zhang, Jiaqi Chen, Xiyun Li, Yonglin Wang, Jingchen Ni, Tianshi Zheng, Chun Chen, Wenhao Yu, Zhenwen Liang, Hongming Zhang, Haitao Mi, and Dong Yu. 2026. Cognitive Kernel-Pro: A Framework for Deep Re- search Agents and Agent Foundation Models Training. arXiv:2508.004...
Pith/arXiv arXiv 2026
-
[4]
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alex Wardle- Solano, Hannah Szabo, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander R. Fabbri, Wojciech Kry...
arXiv 2024
-
[5]
Xanh Ho, Yun-Ang Wu, Sunisth Kumar, Tian Cheng Xia, Florian Boudin, Andre Greiner-Petter, and Akiko Aizawa. 2026. SciClaimEval: Cross-modal Claim Verification in Scientific Papers. arXiv:2602.07621 [cs.CL] https://arxiv.org/abs/ 2602.07621
arXiv 2026
-
[6]
Fangzhou Liang, Tianshi Zheng, Chunkit Chan, Yauwai Yim, and Yangqiu Song. 2025. LLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory- of-Mind and Rationale Inference in Imperfect Information Collaboration Game. arXiv:2510.04980 [cs.AI] https://arxiv.org/abs/2510.04980
arXiv 2025
-
[7]
Ziming Luo, Zonglin Yang, Zexin Xu, Wei Yang, and Xinya Du. 2025. LLM4SR: A Survey on Large Language Models for Scientific Research. arXiv:2501.04306 [cs.CL] https://arxiv.org/abs/2501.04306
arXiv 2025
-
[8]
Yunxiang Mo, Tianshi Zheng, Qing Zong, Jiayu Liu, Baixuan Xu, Yauwai Yim, Chunkit Chan, Jiaxin Bai, and Yangqiu Song. 2025. DixitWorld: Evaluating Multimodal Abductive Reasoning in Vision-Language Models with Multi-Agent Dixit Gameplay. arXiv:2510.10117 [cs.AI] https://arxiv.org/abs/2510.10117
arXiv 2025
-
[9]
Xiyu Ren, Zhaowei Wang, Yiming Du, Zhongwei Xie, Chi Liu, Xinlin Yang, Haoyue Feng, Wenjun Pan, Tianshi Zheng, Baixuan Xu, Zhengnan Li, Yangqiu Song, Ginny Wong, and Simon See. 2026. MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models. arXiv:2605.14906 [cs.CV] https://arxiv.org/abs/2605.14906
Pith/arXiv arXiv 2026
-
[10]
Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K Reddy. 2025. LLM-SR: Scientific Equation Discovery via Programming with Large Language Models. arXiv:2404.18400 [cs.LG] https://arxiv.org/abs/ 2404.18400
arXiv 2025
-
[11]
Qiushi Sun, Zhoumianze Liu, Chang Ma, Zichen Ding, Fangzhi Xu, Zhangyue Yin, Haiteng Zhao, Zhenyu Wu, Kanzhi Cheng, Zhaoyang Liu, Jianing Wang, Qintong Li, Xiangru Tang, Tianbao Xie, Xiachong Feng, Xiang Li, Ben Kao, Wenhai Wang, Biqing Qi, Lingpeng Kong, and Zhiyong Wu. 2026. ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific W...
Pith/arXiv arXiv 2026
-
[12]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mit- tal. 2018. FEVER: a large-scale dataset for Fact Extraction and VERification. arXiv:1803.05355 [cs.CL] https://arxiv.org/abs/1803.05355
Pith/arXiv arXiv 2018
-
[13]
David Wadden, Kyle Lo, Bailey Kuehl, Arman Cohan, Iz Beltagy, Lucy Lu Wang, and Hannaneh Hajishirzi. 2022. SciFact-Open: Towards open-domain scientific claim verification. arXiv:2210.13777 [cs.CL] https://arxiv.org/abs/2210.13777
arXiv 2022
-
[14]
Zhaowei Wang, Wenhao Yu, Xiyu Ren, Jipeng Zhang, Yu Zhao, Rohit Saxena, Liang Cheng, Ginny Wong, Simon See, Pasquale Minervini, Yangqiu Song, and Mark Steedman. 2025. MMLongBench: Benchmarking Long-Context Vision- Language Models Effectively and Thoroughly. arXiv:2505.10610 [cs.CV] https: //arxiv.org/abs/2505.10610
arXiv 2025
-
[15]
Wanghan Xu, Yuhao Zhou, Yifan Zhou, Qinglong Cao, Shuo Li, Jia Bu, Bo Liu, Yixin Chen, Xuming He, Xiangyu Zhao, Xiang Zhuang, Fengxiang Wang, Zhi- wang Zhou, Qiantai Feng, Wenxuan Huang, Jiaqi Wei, Hao Wu, Yuejin Yang, Guangshuai Wang, Sheng Xu, Ziyan Huang, Xinyao Liu, Jiyao Liu, Cheng Tang, Wei Li, Ying Chen, Junzhi Ning, Pengfei Jiang, Chenglong Ma, Ye...
arXiv 2025
-
[16]
Tianshi Zheng, Yixiang Chen, Chengxi Li, Chunyang Li, Qing Zong, Haochen Shi, Baixuan Xu, Yangqiu Song, Ginny Y. Wong, and Simon See. 2025. The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning. arXiv:2504.05081 [cs.CL] https://arxiv.org/abs/2504.05081
arXiv 2025
-
[17]
Tianshi Zheng, Jiayang Cheng, Chunyang Li, Haochen Shi, Zihao Wang, Jiaxin Bai, Yangqiu Song, Ginny Y. Wong, and Simon See. 2025. LogiDynamics: Unrav- eling the Dynamics of Inductive, Abductive and Deductive Logical Inferences in LLM Reasoning. arXiv:2502.11176 [cs.CL] https://arxiv.org/abs/2502.11176
arXiv 2025
-
[18]
Tianshi Zheng, Zheye Deng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Zihao Wang, and Yangqiu Song. 2025. From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery. arXiv:2505.13259 [cs.CL] https://arxiv.org/abs/2505.13259
arXiv 2025
-
[19]
Tianshi Zheng, Kelvin Kiu-Wai Tam, Newt Hue-Nam K. Nguyen, Baixuan Xu, Zhaowei Wang, Jiayang Cheng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Tianqing Fang, Yangqiu Song, Ginny Y. Wong, and Simon See. 2026. New- tonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents. arXiv:2510.07172 [cs.AI] https://arxiv.org/abs/2510.07172
arXiv 2026
-
[20]
Tianshi Zheng, Jiazheng Wang, Zihao Wang, Jiaxin Bai, Hang Yin, Zheye Deng, Yangqiu Song, and Jianxin Li. 2025. Enhancing Transformers for Generalizable First-Order Logical Entailment. arXiv:2501.00759 [cs.CL] https://arxiv.org/abs/ 2501.00759
arXiv 2025
-
[21]
Tianshi Zheng, Rui Wang, Xiyun Li, Yangqiu Song, and Tianqing Fang. 2026. SciResearcher: Scaling Deep Research Agents for Frontier Scientific Reasoning. arXiv:2605.01489 [cs.AI] https://arxiv.org/abs/2605.01489 KDD ’26 SciSoc Agents & LLMs, August 09–13, 2026, Jeju, Korea Wang et al. A Prompt Details The full prompts used by SciLens are longer and include...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.