SciResearcher: Scaling Deep Research Agents for Frontier Scientific Reasoning
Pith reviewed 2026-07-01 00:15 UTC · model grok-4.3
The pith
An automated framework synthesizes academic-grounded tasks to train an 8B agent that sets new benchmarks on frontier biology and chemistry reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
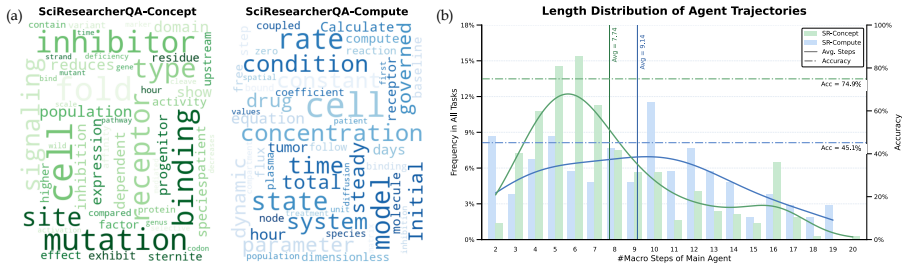
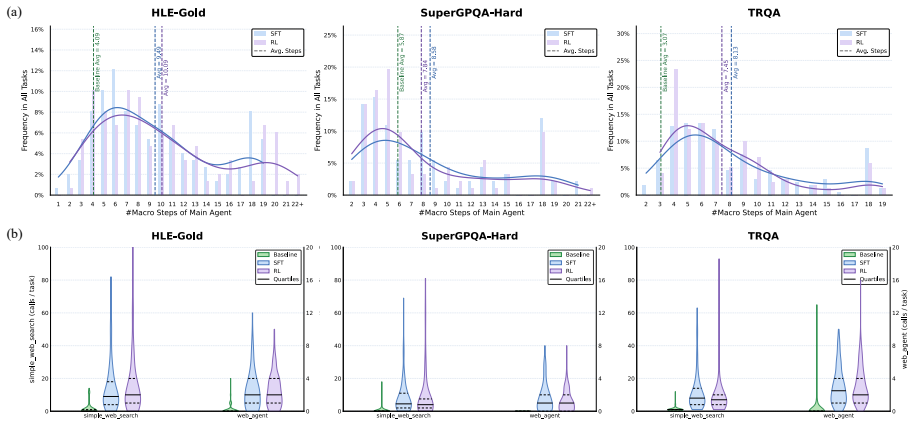
We introduce SciResearcher, a fully automated agentic framework for frontier-science data construction. SciResearcher synthesizes diverse conceptual and computational tasks grounded in academic evidence, while eliciting information acquisition, tool-integrated reasoning, and long-horizon capabilities. Leveraging the curated data for supervised fine-tuning and agentic reinforcement learning, we develop SciResearcher-8B, an agent foundation model that achieves 19.46% on the HLE-Bio/Chem-Gold benchmark, establishing a new state of the art at its parameter scale and surpassing several larger proprietary agents. It further achieves 13-15% absolute gains on SuperGPQA-Hard-Biology and TRQA-Literatu
What carries the argument
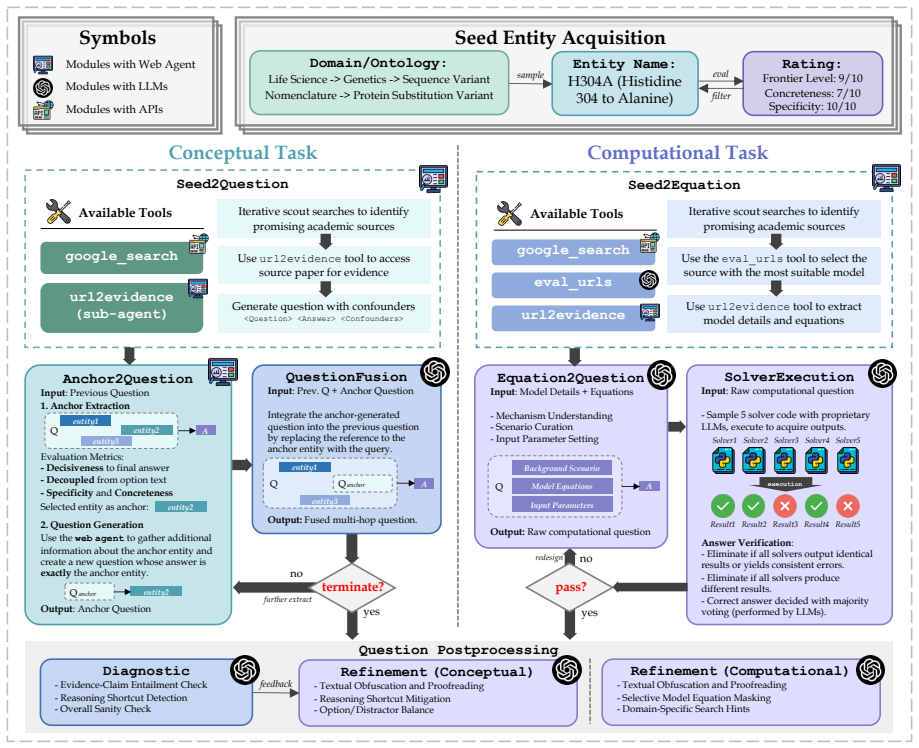
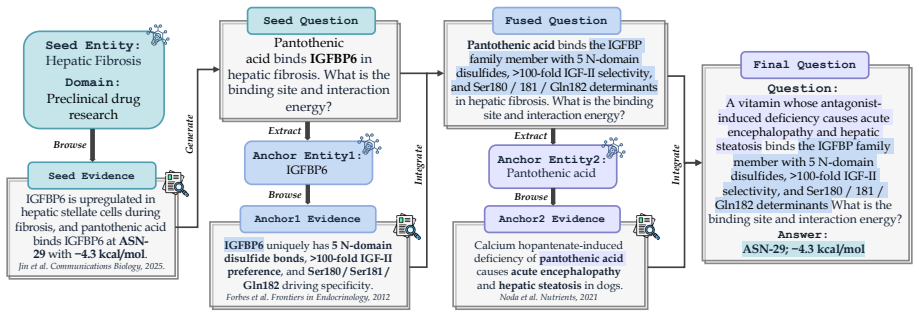
SciResearcher, an automated agentic framework that synthesizes conceptual and computational tasks from academic sources to produce training data for information-seeking and long-horizon reasoning.
If this is right
- Supervised fine-tuning plus agentic reinforcement learning on the synthesized tasks produces measurable gains on hard biology and literature benchmarks.
- An 8B-scale model can exceed the performance of several larger proprietary agents on the reported science evaluations.
- The framework provides a scalable alternative to knowledge-graph or web-browsing data pipelines for frontier scientific domains.
- The same data-construction loop can be repeated to generate additional training examples without manual curation.
Where Pith is reading between the lines
- The same synthesis loop could be applied to physics or mathematics papers to test whether similar gains appear on those benchmarks.
- Open models trained this way may narrow the gap with closed systems that rely on proprietary web-scale data.
- If the tasks successfully train long-horizon tool use, the method could extend to multi-step experimental design agents.
Load-bearing premise
Tasks created by synthesizing academic evidence will produce capabilities that transfer to the held-out science benchmarks.
What would settle it
Retraining the 8B model on the same base data but without the synthesized academic tasks and observing no improvement or a drop below 19.46% on HLE-Bio/Chem-Gold would falsify the central claim.
Figures






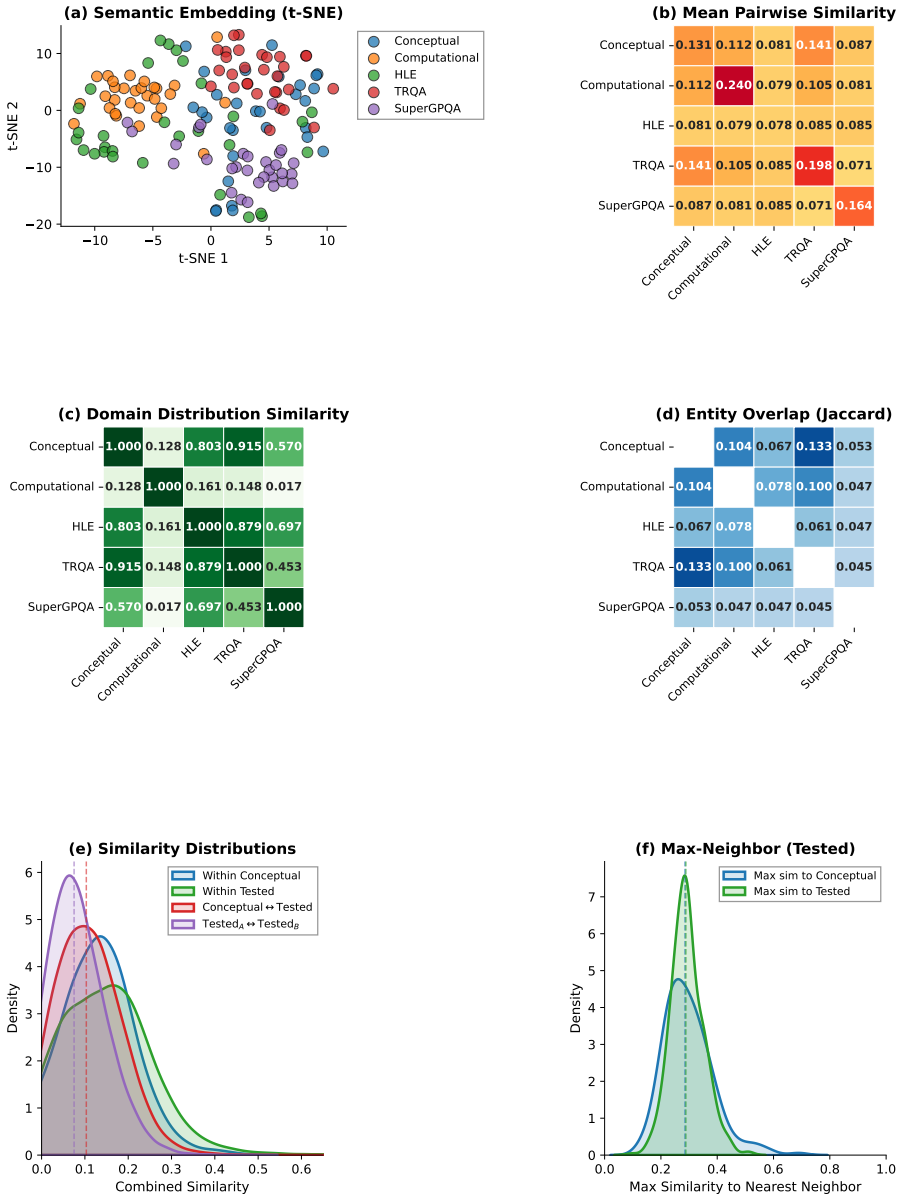
read the original abstract
Frontier scientific reasoning is rapidly emerging as a key foundation for advancing AI agents in automated scientific discovery. Deep research agents offer a promising approach to this challenge. These models develop robust problem-solving capabilities through post-training on information-seeking tasks, which are typically curated via knowledge graph construction or iterative web browsing. However, these strategies face inherent limitations in frontier science, where domain-specific knowledge is scattered across sparse and heterogeneous academic sources, and problem solving requires sophisticated computation and reasoning far beyond factual recall. To bridge this gap, we introduce SciResearcher, a fully automated agentic framework for frontier-science data construction. SciResearcher synthesizes diverse conceptual and computational tasks grounded in academic evidence, while eliciting information acquisition, tool-integrated reasoning, and long-horizon capabilities. Leveraging the curated data for supervised fine-tuning and agentic reinforcement learning, we develop SciResearcher-8B, an agent foundation model that achieves 19.46% on the HLE-Bio/Chem-Gold benchmark, establishing a new state of the art at its parameter scale and surpassing several larger proprietary agents. It further achieves 13-15% absolute gains on SuperGPQA-Hard-Biology and TRQA-Literature benchmarks. Overall, SciResearcher introduces a new paradigm for automated data construction for frontier scientific reasoning and offers a scalable path toward future scientific agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciResearcher, a fully automated agentic framework that synthesizes diverse conceptual and computational tasks grounded in academic evidence to train deep research agents. These tasks are designed to elicit information acquisition, tool-integrated reasoning, and long-horizon capabilities. The resulting SciResearcher-8B model, trained via supervised fine-tuning and agentic reinforcement learning on the curated data, achieves 19.46% on the HLE-Bio/Chem-Gold benchmark (new SOTA at its scale, surpassing some larger proprietary agents) and 13-15% absolute gains on SuperGPQA-Hard-Biology and TRQA-Literature.
Significance. If the performance improvements are shown to stem specifically from the automated synthesis of grounded tasks rather than generic post-training, the work could offer a scalable paradigm for constructing training data in sparse, heterogeneous scientific domains where traditional knowledge-graph or web-browsing approaches fall short. This would strengthen the case for agent foundation models in automated scientific discovery.
major comments (2)
- [Abstract and §4 (Results)] Abstract and §4 (Results): The central performance claims (19.46% on HLE-Bio/Chem-Gold and 13-15% gains on the other two benchmarks) are presented as resulting from the SciResearcher synthesis method, yet no ablation studies isolate the contribution of the synthesized conceptual/computational tasks, no validation of task grounding accuracy is reported, and no comparison to generic fine-tuning baselines is provided. This leaves the transfer from synthesized tasks to benchmark gains unsupported.
- [§3 (Method)] §3 (Method): The description of the automated framework for task synthesis lacks any quantitative analysis or error analysis showing that the generated tasks correctly elicit information acquisition, tool use, and long-horizon reasoning without introducing factual or computational errors from the academic sources.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional empirical support would strengthen our claims regarding the SciResearcher framework. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] Abstract and §4 (Results): The central performance claims (19.46% on HLE-Bio/Chem-Gold and 13-15% gains on the other two benchmarks) are presented as resulting from the SciResearcher synthesis method, yet no ablation studies isolate the contribution of the synthesized conceptual/computational tasks, no validation of task grounding accuracy is reported, and no comparison to generic fine-tuning baselines is provided. This leaves the transfer from synthesized tasks to benchmark gains unsupported.
Authors: We agree that the current manuscript would benefit from explicit ablations to isolate the contribution of the agentic task synthesis. In the revised version we will add: (i) a generic fine-tuning baseline using standard SFT on raw academic passages without the conceptual/computational task synthesis step; (ii) human validation results on a random sample of 200 synthesized tasks measuring factual and computational grounding accuracy; and (iii) an analysis correlating specific task features (e.g., number of tool calls, horizon length) with downstream benchmark gains. These additions will provide direct evidence for the transfer from synthesized tasks to the reported improvements. revision: yes
-
Referee: [§3 (Method)] §3 (Method): The description of the automated framework for task synthesis lacks any quantitative analysis or error analysis showing that the generated tasks correctly elicit information acquisition, tool use, and long-horizon reasoning without introducing factual or computational errors from the academic sources.
Authors: We acknowledge the absence of quantitative validation in the current §3. The revised manuscript will include: (i) aggregate error statistics from the synthesis pipeline (factual error rate via automated checks plus human review of 300 tasks, computational error rate on code-generation tasks); (ii) distributional statistics on elicited behaviors (e.g., average number of information-acquisition steps, tool invocations, and reasoning horizon length across the dataset); and (iii) a small-scale human study confirming that the generated tasks require the intended capabilities. These metrics will be reported alongside the existing framework description. revision: yes
Circularity Check
No circularity: empirical framework with no self-referential derivations or fitted predictions
full rationale
The paper describes an automated data synthesis framework (SciResearcher) for training an 8B agent model via supervised fine-tuning and agentic RL, then reports benchmark scores. No equations, parameter-fitting procedures, uniqueness theorems, or self-citations appear in the abstract or described content. The performance claims rest on external benchmark evaluations rather than any reduction of outputs to inputs by construction. The derivation chain is therefore self-contained as an empirical pipeline without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SciLens: Multi-modal Scientific Claim Verification with Agentic Entailment and Grounding
SciLens introduces an evidence-conditioned atomic entailment framework that grounds claims to modality-specific witnesses in tables and figures, achieving 79.2% macro-F1 on SciClaimEval.
Reference graph
Works this paper leans on
-
[1]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Scibench: Evaluating college-level scientific problem-solving abilities of large language models. Preprint, arXiv:2307.10635. Jason Wei, Zhiqing Sun, Spencer Papay, Scott McK- inney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. 2025. Browsecomp: A simple yet chal- lenging benchmark for browsing agents.P...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
From automation to autonomy: A survey on large language models in scientific discovery. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17733–17750, Suzhou, China. Association for Com- putational Linguistics. Tianshi Zheng, Kelvin Kiu-Wai Tam, Newt Hue-Nam K. Nguyen, Baixuan Xu, Zhaowei Wang, Jiayang Cheng,...
-
[3]
Include the seed entity or be directly grounded in it
-
[4]
Be concise but scientifically meaningful
-
[5]
Be answerable from a single authoritative academic source at this stage
-
[6]
Prefer multiple-choice format with plausible confounders, while allowing short-answer format when more appropriate
-
[7]
Avoid shortcuts that can be solved by trivia, superficial keyword matching, or generic web search without reading the academic evidence
-
[8]
Plan 3--5 diverse search queries that target academic sources such as peer-reviewed papers, domain databases, preprints, and reputable scientific venues
Be suitable as the semantic backbone for later anchor-based augmentation.> ## Pre-Action Protocol: Plan Before Searching <Metric Definition> <Before browsing, understand the seed entity and its scientific context. Plan 3--5 diverse search queries that target academic sources such as peer-reviewed papers, domain databases, preprints, and reputable scientif...
-
[9]
Meticulousness and persistence in finding high-quality academic evidence
-
[10]
Task decomposition: search -> evidence extraction -> question generation -> verification
-
[11]
Adaptive error handling and reuse of progress state when searches fail or evidence is insufficient
-
[12]
Multi-query scout search and URL selection based on relevance, venue quality, source diversity, and scientific specificity
-
[13]
Use of the url2evidence sub-agent to access selected academic sources, extract key supporting evidence, and distinguish stand-alone scientific facts from study-specific artifacts
-
[14]
Evidence quality checks, including source authority, evidence-answer entailment, and avoidance of unsupported assumptions
-
[15]
Question formulation with plausible, unbiased, and challenging confounders for MCQs; clear expected answer for short-answer questions; and final quality checks
-
[16]
question
Multi-tool coordination following the typical workflow: scout search -> source selection -> url2evidence -> question generation -> verification. ## Output Format The final output MUST be a JSON object with the following structure: '''json { "question": "The question text containing or directly grounded in the seed entity", "answer": "The correct answer co...
-
[17]
**Domain-specific**: It is a concrete scientific entity, such as a gene, protein, pathway, compound, species, technique, disease, mutation, phenotype, material, model, or other scientific concept
-
[18]
**Question-body only**: It appears in the question stem but does NOT appear in the correct answer or any confounder
-
[19]
**Decisive**: The question becomes substantially harder or unanswerable if this entity is masked or removed
-
[20]
## Your Task Given the question, correct answer(s), and confounders below, you must:
**Specific and concrete**: It is sufficiently specific to support further evidence-grounded browsing and question generation. ## Your Task Given the question, correct answer(s), and confounders below, you must:
-
[21]
Identify candidate anchor entities in the question body
-
[22]
Verify that each candidate does NOT appear in the correct answer or any confounder
-
[23]
Evaluate whether each candidate is decisive for deriving the final answer
-
[24]
Select the most decisive, specific, and concrete entity
-
[25]
## Selection Criteria (in priority order)
If no valid anchor exists, return an empty string. ## Selection Criteria (in priority order)
-
[26]
AXL" over
Prefer the MOST SPECIFIC entity, e.g., "AXL" over "receptor tyrosine kinase"
-
[27]
Prefer entities that constrain the answer, such that removing them makes multiple answers plausible
-
[28]
Prefer named entities, such as gene, protein, compound, disease, pathway, or model names, over generic scientific terms
-
[29]
Prefer entities that are decoupled from the surface form of the answer options
-
[30]
candidates
If multiple candidates exist, choose the one most central to the scientific claim. ## Output Format Return ONLY valid JSON: { "candidates": [ { "entity": "...", "in_question": true, "in_options": false, "is_decisive": true } ], "anchor_entity": "<the single valid anchor entity string, or empty string if none>", "entity_type": "<type: gene|protein|pathway|...
-
[31]
Search identifiability
-
[32]
Computational complexity
-
[33]
### Level 3: Detailed Model Extraction with url2evidence Use the url2evidence sub-agent to conduct a deep dive into the final selected source or sources
LLM unfamiliarity Also consider URL validity and whether the source clearly contains a usable computational or numerical model. ### Level 3: Detailed Model Extraction with url2evidence Use the url2evidence sub-agent to conduct a deep dive into the final selected source or sources. Extract the complete model specification, including:
-
[34]
Model name and scientific purpose
-
[35]
Variable definitions
-
[36]
Parameter definitions and units
-
[37]
Applicable scenario and constraints
-
[38]
## Model Selection Criteria Select a model that satisfies as many of the following criteria as possible:
Any assumptions required for correct model use. ## Model Selection Criteria Select a model that satisfies as many of the following criteria as possible:
-
[39]
The model supports calculable numerical outputs
-
[40]
The model is described in a real, citable academic source
-
[41]
The equations are nontrivial and not merely standard textbook formulas
-
[42]
The computation requires meaningful model instantiation or numerical solving
-
[43]
The model can support a realistic scenario-based scientific question
-
[44]
The source is relatively recent, niche, or unlikely to be memorized by LLMs
-
[45]
seed_entity
The model is clearly associated with the seed entity or its scientific domain. ## What Counts as a Frontier Numerical Model? <A model with explicit mathematical structure, such as governing equations, ODE/PDE systems, kinetic models, dose-response models, mechanistic simulations, quantitative biological or chemical models, or other computational formulati...
-
[46]
Search for and identify the relevant model
-
[47]
Extract the model equations and constraints from the paper
-
[48]
Instantiate the model in a concrete scientific scenario
-
[49]
is_valid_url
Write and execute a Python solver to compute a numerical answer. First, perform preliminary validity checks. Then evaluate the article according to the four core metrics used for computational task curation. ## Preliminary Check 1: URL Validity <Metric Definition> <Determine whether the URL corresponds to a real and accessible academic source, such as a p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.