PeerCheck: Enhancing LLM-Generated Academic Reviews Towards Human-Level Quality
Pith reviewed 2026-06-26 17:10 UTC · model grok-4.3
The pith
LLM reviews focus more on theory than methods, and Chain-of-Thought prompting improves their quality toward human standards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that LLMs and humans attend to different aspects of papers, with LLMs prioritizing theory and humans methodology and experiments. Chain-of-Thought prompting significantly improves the quality of LLM-generated reviews, while retrieval-augmented generation shows an unexpected paradox where it helps some models but reduces quality in others.
What carries the argument
The PeerCheck framework, which measures term focus differences between human and LLM reviews and evaluates prompt engineering techniques like CoT and RAG for alignment.
If this is right
- Adopting Chain-of-Thought in review generation systems would produce reviews that better match human emphasis on methods and results.
- The RAG paradox implies that retrieval must be applied selectively rather than as a default enhancement for all models.
- Future review tools could incorporate term-balance checks to ensure coverage of experimental aspects.
- Large-scale use of improved LLM reviews could help scale peer review without sacrificing attention to empirical work.
Where Pith is reading between the lines
- Similar term-focus analysis could be applied to LLM outputs in other expert domains such as legal case summaries or medical reports.
- If the quality gain from CoT holds across different review rubrics, then minimal prompting changes could suffice without full model retraining.
- Extending the framework to measure agreement on specific claims rather than term counts might reveal deeper alignment issues.
Load-bearing premise
That shifts in which terms receive attention, combined with results on undefined quality measures, indicate that LLM reviews are inferior to human ones.
What would settle it
If expert reviewers rate CoT-enhanced LLM reviews as equal or superior to human-written reviews on the same papers using a standardized scoring rubric for thoroughness and fairness, the improvement claim would hold; persistent gaps would falsify it.
Figures

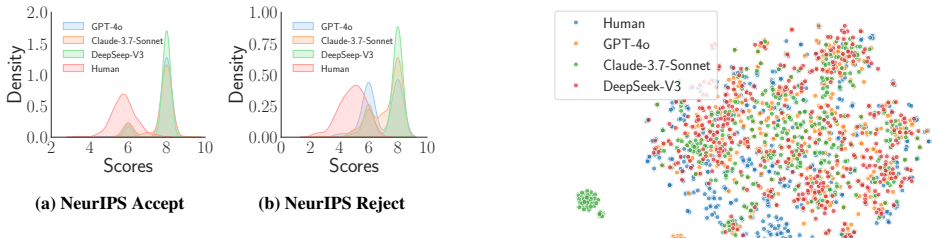

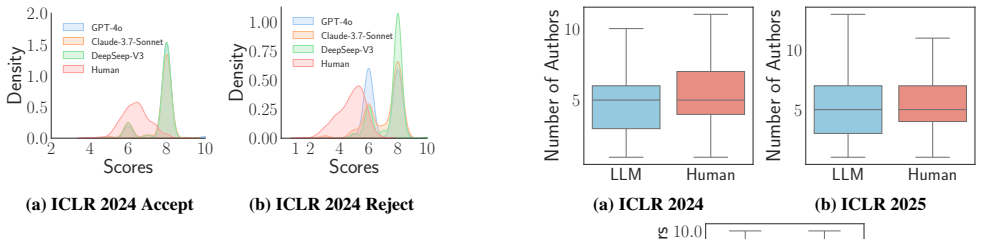




read the original abstract
As academic submissions grow, the traditional peer review process struggles to keep up, raising concerns about quality and fairness. A trend of using large language models (LLMs) for assistance has emerged. In this work, we take a critical step toward improving the quality of LLM-generated reviews. We propose the PeerCheck framework, which investigates LLM-human review differences (RQ1) and explores methods to improve LLM-generated review quality (RQ2). We first analyzed the human-written reviews with reviews generated by various LLMs and found that LLMs and humans focus on different terms, e.g., LLMs prioritize theory while humans emphasize methodology and experiments. We further adopt prompt engineering, such as Chain-of-Thought (CoT), and utilize retrieval-augmented generation (RAG) to enhance the LLM-generated reviews towards human-level quality. We find CoT significantly improves the quality of LLM reviews, while we discover an unexpected "RAG paradox," i.e., experiments with RAG produce different results for various LLMs and, in some cases, even reduce review quality. Our comprehensive analysis of LLM-generated academic reviews illustrates both possibilities and limitations, contributing to a more effective, human-aligned review system. Our dataset is available on https://github.com/TrustAIRLab/PeerCheck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the PeerCheck framework to investigate differences between LLM-generated and human-written academic reviews (RQ1) and to test prompt-engineering methods including Chain-of-Thought (CoT) and Retrieval-Augmented Generation (RAG) for improving LLM review quality toward human-level standards (RQ2). Term-frequency analysis is used to claim that LLMs prioritize theory terms while humans emphasize methodology and experiments; experiments reportedly show CoT yields significant quality gains while RAG produces inconsistent or even negative effects across models. A dataset is released via GitHub.
Significance. If the reported differences and improvement effects are shown to track actual review utility, the work could inform the design of LLM-assisted peer-review tools and the released dataset would constitute a reusable resource for the community. The explicit release of data supports reproducibility and follow-on studies.
major comments (2)
- [RQ1 analysis (term-frequency comparison)] The RQ1 conclusion that LLM reviews are lower quality rests on term-frequency shifts (theory emphasis vs. methodology/experiments emphasis) as a quality proxy, yet no validation is supplied that these frequency differences correlate with expert-rated helpfulness, inter-reviewer agreement, or downstream outcomes such as revision quality. This proxy is load-bearing for both the quality gap claim and the subsequent RQ2 improvement claims.
- [RQ2 experiments and results] The RQ2 claims that CoT 'significantly improves' quality and that RAG exhibits a 'paradox' (sometimes reducing quality) are stated directionally in the abstract and main text without reported evaluation metrics, statistical tests, sample sizes, or controls, making it impossible to assess the magnitude or reliability of the reported effects.
minor comments (2)
- [Abstract and §3] The abstract and method sections would benefit from an explicit description of the internal scoring procedure or rubric used to quantify 'review quality' beyond term frequencies.
- [Experimental setup] Clarify the exact LLMs, prompt templates, and retrieval corpus used in the RAG experiments to enable replication.
Simulated Author's Rebuttal
Thank you for the constructive referee report and the recommendation for major revision. We appreciate the emphasis on validating the term-frequency proxy and improving the reporting of experimental results. We address each major comment below and will revise the manuscript accordingly to strengthen these aspects while preserving the core contributions of the PeerCheck framework and released dataset.
read point-by-point responses
-
Referee: [RQ1 analysis (term-frequency comparison)] The RQ1 conclusion that LLM reviews are lower quality rests on term-frequency shifts (theory emphasis vs. methodology/experiments emphasis) as a quality proxy, yet no validation is supplied that these frequency differences correlate with expert-rated helpfulness, inter-reviewer agreement, or downstream outcomes such as revision quality. This proxy is load-bearing for both the quality gap claim and the subsequent RQ2 improvement claims.
Authors: We agree that the term-frequency analysis functions as an exploratory indicator of differing emphases rather than a fully validated quality measure, and that explicit correlation with human-rated helpfulness would strengthen the RQ1 claims. The released PeerCheck dataset includes human evaluations that enable such analysis. In the revision we will add a section correlating term frequencies with the human-rated review quality scores, including statistical measures such as Spearman rank correlation, to validate the proxy and discuss its implications for the observed quality gap. revision: yes
-
Referee: [RQ2 experiments and results] The RQ2 claims that CoT 'significantly improves' quality and that RAG exhibits a 'paradox' (sometimes reducing quality) are stated directionally in the abstract and main text without reported evaluation metrics, statistical tests, sample sizes, or controls, making it impossible to assess the magnitude or reliability of the reported effects.
Authors: We acknowledge that the current presentation of RQ2 results would benefit from more explicit reporting to allow assessment of effect magnitude and reliability. In the revised manuscript we will expand the experimental section and abstract to include the specific human evaluation metrics (e.g., 5-point scales on helpfulness, depth, and clarity), statistical tests with p-values, exact sample sizes per condition, effect sizes where applicable, and controls for model and prompt variations. The directional claims will be qualified with these quantitative details. revision: yes
Circularity Check
No significant circularity
full rationale
The paper conducts empirical comparisons of LLM vs. human reviews via term-frequency analysis and tests prompt methods (CoT, RAG) against external human-written reviews as the benchmark. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear. Quality claims rest on direct external references rather than internal reductions, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-written reviews represent the desired quality standard that LLM reviews should approach.
invented entities (1)
-
PeerCheck framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ChatGPT.https://chat.openai.com/chat. 1
-
[2]
OpenReview.net.https://openreview.net/. 13
-
[3]
AAAI Launches AI-Powered Peer Review Assessment System
AAAI. AAAI Launches AI-Powered Peer Review Assessment System. https://aaai.org/aaai-launches-ai-powered- peer-review-assessment-system/, 2025. 1
2025
-
[4]
Claude.https://claude.ai/
Anthropic. Claude.https://claude.ai/. 1
-
[5]
Claude 3.7 Sonnet and Claude Code
Anthropic. Claude 3.7 Sonnet and Claude Code. https: //www.anthropic.com/news/claude-3-7-sonnet , 2025. 3
2025
-
[6]
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. InAAAI Conference on Artificial Intelligence (AAAI), pages 17682–17690. AAAI, 2024. 1
2024
-
[7]
Overview of Pan 2023: Authorship Verification, Multi-author Writing Style Analysis, Profiling Cryptocurrency Influencers, and Trigger Detection: Condensed Lab Overview
Janek Bevendorff, Ian Borrego-Obrador, Mara Chinea-Ríos, Marc Franco-Salvador, Maik Fröbe, Annina Heini, Krzysztof Kredens, Maximilian Mayerl, Piotr P˛ ezik, Martin Potthast, Francisco Rangel, Paolo Rosso, Efstathios Stamatatos, Benno Stein, Matti Wiegmann, Magdalena Wolska, and Eva Zangerle. Overview of Pan 2023: Authorship Verification, Multi-author Wri...
2023
-
[8]
SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis.CoRR abs/2403.01976, 2024
Hengxing Cai, Xiaochen Cai, Junhan Chang, Sihang Li, Lin Yao, Changxin Wang, Zhifeng Gao, Hongshuai Wang, Yongge Li, Mujie Lin, Shuwen Yang, Jiankun Wang, Mingjun Xu, Jin Huang, Xi Fang, Jiaxi Zhuang, Yuqi Yin, Yaqi Li, Changhong Chen, Zheng Cheng, Zifeng Zhao, Linfeng Zhang, and Guolin Ke. SciAssess: Benchmarking LLM Proficiency in Scientific Literature ...
arXiv 2024
-
[9]
Bench- marking Large Language Models in Retrieval-Augmented Gen- eration
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. Bench- marking Large Language Models in Retrieval-Augmented Gen- eration. InAAAI Conference on Artificial Intelligence (AAAI), pages 17754–17762. AAAI, 2024. 2, 3, 16
2024
-
[10]
Position Paper: How Should We Responsibly Adopt LLMs in the Peer Review Process? InFindings of the Associa- tion for Computational Linguistics: EACL (EACL Findings), pages 151–165
Juhwan Choi, JungMin Yun, Changhun Kim, and YoungBin Kim. Position Paper: How Should We Responsibly Adopt LLMs in the Peer Review Process? InFindings of the Associa- tion for Computational Linguistics: EACL (EACL Findings), pages 151–165. ACL, 2026. 1
2026
-
[11]
DeepSeek AI.https://deepseek.ai/
DeepSeek. DeepSeek AI.https://deepseek.ai/. 3
-
[12]
Wal- lace
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C. Wal- lace. ERASER: A Benchmark to Evaluate Rationalized NLP Models. InAnnual Meeting of the Association for Computa- tional Linguistics (ACL), pages 4443–4458. ACL, 2020. 4, 14
2020
-
[13]
Yu, and Wenpeng Yin
Jiangshu Du, Yibo Wang, Wenting Zhao, Zhongfen Deng, Shuaiqi Liu, Renze Lou, Henry Peng Zou, Pranav Narayanan Venkit, Nan Zhang, Mukund Srinath, Haoran Zhang, Vipul Gupta, Yinghui Li, Tao Li, Fei Wang, Qin Liu, Tianlin Liu, Pengzhi Gao, Congying Xia, Chen Xing, Cheng Jiayang, Zhaowei Wang, Ying Su, Raj Sanjay Shah, Ruohao Guo, Jing Gu, Haoran Li, Kangda W...
2024
-
[14]
Fleiss’ kappa statistic without paradoxes.Quality & Quantity, 2015
Rosa Falotico and Piero Quatto. Fleiss’ kappa statistic without paradoxes.Quality & Quantity, 2015. 17
2015
-
[15]
GPTScore: Evaluate as You Desire
Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. GPTScore: Evaluate as You Desire. InConference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 6556–6576. ACL, 2025. 2
2025
-
[16]
What Needs to Be Done? Occu- pational Therapy Responsibilities and Challenges Regarding Human Rights.Australian Occupational Therapy Journal,
Sandra Maria Galheigo. What Needs to Be Done? Occu- pational Therapy Responsibilities and Challenges Regarding Human Rights.Australian Occupational Therapy Journal,
-
[17]
Gao, Frederick M
Catherine A. Gao, Frederick M. Howard, Nishant D. Shah, and et al. Comparing Scientific Abstracts Generated by ChatGPT to Real Abstracts with Detectors and Blinded Human Reviewers. NPJ Digital Medicine, 2025. 2
2025
-
[18]
Measuring the Developmental Func- tion of Peer Review: A Multi-dimensional, Cross-disciplinary Analysis of Peer Review Reports from 740 Academic Journals
Daniel Garcia-Costa, Flaminio Squazzoni, Bahar Mehmani, and Francisco Grimaldo. Measuring the Developmental Func- tion of Peer Review: A Multi-dimensional, Cross-disciplinary Analysis of Peer Review Reports from 740 Academic Journals. PeerJ Computer Science, 2022. 17
2022
-
[19]
Sebastian Gehrmann, Hendrik Strobelt, and Alexander M. Rush. GLTR: Statistical Detection and Visualization of Gen- erated Text. InAnnual Meeting of the Association for Com- putational Linguistics (ACL), pages 111–116. ACL, 2019. 4, 13
2019
-
[20]
Human-LLM Coevolu- tion: Evidence from Academic Writing
Mingmeng Geng and Roberto Trotta. Human-LLM Coevolu- tion: Evidence from Academic Writing. InFindings of the Association for Computational Linguistics: ACL (ACL Find- ings), pages 12689–12696. ACL, 2025. 13
2025
-
[21]
Peer Reviews of Peer Reviews: A Randomized Controlled Trial and Other Experiments.PLOS One, 2025
Alexander Goldberg, Ivan Stelmakh, Kyunghyun Cho, Alice Oh, Alekh Agarwal, Danielle Belgrave, and Nihar B Shah. Peer Reviews of Peer Reviews: A Randomized Controlled Trial and Other Experiments.PLOS One, 2025. 16
2025
-
[22]
Eval- uating Large Language Models in Generating Synthetic HCI Research Data: a Case Study
Perttu Hämäläinen, Mikke Tavast, and Anton Kunnari. Eval- uating Large Language Models in Generating Synthetic HCI Research Data: a Case Study. InAnnual ACM Conference on Human Factors in Computing Systems (CHI). ACM, 2023. 1
2023
-
[23]
MGTBench: Benchmarking Machine-Generated Text Detection
Xinlei He, Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. MGTBench: Benchmarking Machine-Generated Text Detection. InACM SIGSAC Conference on Computer and Communications Security (CCS). ACM, 2024. 3, 4, 13
2024
-
[24]
ICLR 2024 Reviewer Guide
ICLR. ICLR 2024 Reviewer Guide. https://iclr.cc/Conf erences/2024/ReviewerGuide, 2024. 13
2024
-
[25]
ICLR.https://iclr.cc/, 2025
ICLR. ICLR.https://iclr.cc/, 2025. 3
2025
-
[26]
MathPrompter: Mathematical Reasoning using Large Language Models
Shima Imani, Liang Du, and Harsh Shrivastava. MathPrompter: Mathematical Reasoning using Large Language Models. InAn- nual Meeting of the Association for Computational Linguistics (ACL), pages 37–42. ACL, 2023. 1
2023
-
[27]
Position: The AI Conference Peer Review Crisis Demands Author Feedback and Reviewer Rewards
Jaeho Kim, Yunseok Lee, and Seulki Lee. Position: The AI Conference Peer Review Crisis Demands Author Feedback and Reviewer Rewards. InInternational Conference on Machine Learning (ICML). PMLR, 2025. 2
2025
-
[28]
Burak Kocak, Mehmet Ruhi Onur, Seong Ho Park, Pascal Baltzer, and Matthias Dietzel. Ensuring Peer Review Integrity in the Era of Large Language Models: A Critical Stocktaking of Challenges, Red Flags, and Recommendations.European Journal of Radiology Artificial Intelligence, 2025. 1, 2
2025
-
[29]
Large Language Models are Zero-Shot Reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large Language Models are Zero-Shot Reasoners. InAnnual Conference on Neural Infor- mation Processing Systems (NeurIPS). NeurIPS, 2022. 1
2022
-
[30]
Evaluating the Factual Consistency of Ab- stractive Text Summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the Factual Consistency of Ab- stractive Text Summarization. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346. ACL, 2020. 15
2020
-
[31]
Autoencoding beyond Pixels Using a Learned Similarity Metric
Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, and Ole Winther. Autoencoding beyond Pixels Using a Learned Similarity Metric. InInternational Conference on Machine Learning (ICML), pages 1558–1566. JMLR, 2016. 4, 14
2016
-
[32]
David- son, Veniamin Veselovsky, and Robert West
Giuseppe Russo Latona, Manoel Horta Ribeiro, Tim R. David- son, Veniamin Veselovsky, and Robert West. The AI Review Lottery: Widespread AI-Assisted Peer Reviews Boost Paper Scores and Acceptance Rates.CoRR abs/2405.02150, 2024. 1
arXiv 2024
-
[33]
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küt- tler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAnnual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS,
-
[34]
Miao Li, Jey Han Lau, and Eduard H. Hovy. A Sentiment Consolidation Framework for Meta-Review Generation. InAn- nual Meeting of the Association for Computational Linguistics (ACL), pages 10158–10177. ACL, 2024. 2
2024
-
[35]
Yuqing Liang, Jiancheng Xiao, Wensheng Gan, and Philip S. Yu. Watermarking Techniques for Large Language Models: A Survey.CoRR abs/2409.00089, 2024. 2
arXiv 2024
-
[36]
ROUGE: A Package for Automatic Evalua- tion of Summaries
Chin-Yew Lin. ROUGE: A Package for Automatic Evalua- tion of Summaries. InAnnual Meeting of the Association for Computational Linguistics (ACL), pages 74–81. ACL, 2004. 4, 13
2004
-
[37]
Role-playing Prompt Framework: Generation and Evaluation.CoRR abs/2406.00627, 2024
Xun Liu and Zhengwei Ni. Role-playing Prompt Framework: Generation and Evaluation.CoRR abs/2406.00627, 2024. 2
arXiv 2024
-
[38]
RoBERTa: A Robustly Optimized BERT Pretraining Approach.CoRR abs/1907.11692, 2019
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach.CoRR abs/1907.11692, 2019. 3, 4, 13
Pith/arXiv arXiv 1907
-
[39]
Automatic Analysis of Syntactic Complexity in Second Language Writing.International Journal of Corpus Linguistics, 2010
Xiaofei Lu. Automatic Analysis of Syntactic Complexity in Second Language Writing.International Journal of Corpus Linguistics, 2010. 7, 16
2010
-
[40]
LLM4SR: A Survey on Large Language Models for Scientific Research.CoRR abs/2501.04306, 2025
Ziming Luo, Zonglin Yang, Zexin Xu, Wei Yang, and Xinya Du. LLM4SR: A Survey on Large Language Models for Scientific Research.CoRR abs/2501.04306, 2025. 2 9
arXiv 2025
-
[41]
MTLD, vocd-D, and HD- D: A Vlidation Study of Sophisticated Approaches to Lexical Diversity Assessment.Behavior Research Methods, 2010
Philip M McCarthy and Scott Jarvis. MTLD, vocd-D, and HD- D: A Vlidation Study of Sophisticated Approaches to Lexical Diversity Assessment.Behavior Research Methods, 2010. 7, 16
2010
-
[42]
Interrater Reliability: the Kappa Statistic
Mary L McHugh. Interrater Reliability: the Kappa Statistic. Biochemia Medica, 2012. 7, 17
2012
-
[43]
NeurIPS.https://neurips.cc/
NeurIPS. NeurIPS.https://neurips.cc/. 3
-
[44]
Reviewer Guidelines
NeurIPS. Reviewer Guidelines. https://neurips.cc/Con ferences/2024/ReviewerGuidelines, 2024. 13
2024
-
[45]
OpenAI. GPT-4o. https://openai.com/index/hello-gpt- 4o/, 2024. 3
2024
-
[46]
Using the API
OpenReview. Using the API. https://docs.openreview. net/getting-started/using-the-api. 13
-
[47]
Bleu: a Method for Automatic Evaluation of Machine Translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a Method for Automatic Evaluation of Machine Translation. InAnnual Meeting of the Association for Com- putational Linguistics (ACL), pages 311–318. ACL, 2002. 4, 13
2002
-
[48]
I2C-Huelva at SemEval-2024 Task 8: Boosting AI-Generated Text Detection with Multimodal Mod- els and Optimized Ensembles
Alberto Rodero Peña, Jacinto Mata Vázquez, and Victo- ria Pachón Álvarez. I2C-Huelva at SemEval-2024 Task 8: Boosting AI-Generated Text Detection with Multimodal Mod- els and Optimized Ensembles. InInternational Workshop on Semantic Evaluation (SemEval), pages 845–852. ACL, 2024. 2
2024
-
[49]
Keywords and Their Role in The Reviewing Process (for Authors)
The reVISe Committee. Keywords and Their Role in The Reviewing Process (for Authors). https://ieeevis.org/ye ar/2024/blog/keywords-for-authors, 2020. 3, 4
2024
-
[50]
Develop- ment of the Review Quality Instrument (RQI) for Assessing Peer Reviews of Manuscripts.Journal of Clinical Epidemiol- ogy, 1999
Susan Van Rooyen, Nick Black, and Fiona Godlee. Develop- ment of the Review Quality Instrument (RQI) for Assessing Peer Reviews of Manuscripts.Journal of Clinical Epidemiol- ogy, 1999. 7, 17
1999
-
[51]
Hyun Ryu, Doohyuk Jang, Hyemin S Lee, Joonhyun Jeong, Gyeongman Kim, Donghyeon Cho, Gyouk Chu, Minyeong Hwang, Hyeongwon Jang, Changhun Kim, Haechan Kim, Jina Kim, Joowon Kim, Yoonjeon Kim, Kwanhyung Lee, Chan- jae Park, Heecheol Yun, Gregor Betz, and Eunho Yang. Re- viewScore: Misinformed Peer Review Detection with Large Language Models.CoRR abs/2509.216...
arXiv 2025
-
[52]
Exploring The Potential of ChatGPT in The Peer Review Process:BDM An Observational Study.Diabetes & Metabolic Syndrome: Clinical Research & Reviews, 2024
Ahmed Saad, Nathan Jenko, Sisith Ariyaratne, Nick Birch, Karthikeyan P Iyengar, Arthur Mark Davies, Raju Vaishya, and Rajesh Botchu. Exploring The Potential of ChatGPT in The Peer Review Process:BDM An Observational Study.Diabetes & Metabolic Syndrome: Clinical Research & Reviews, 2024. 2
2024
-
[53]
The Good, the Bad and the Constructive: Automatically Measuring Peer Review’s Utility for Authors
Abdelrahman Sadallah, Tim Baumgärtner, and Ted Briscoe Iryna Gurevych. The Good, the Bad and the Constructive: Automatically Measuring Peer Review’s Utility for Authors. InConference on Empirical Methods in Natural Language Processing (EMNLP), pages 28991–29021. ACL, 2025. 7, 17
2025
-
[54]
Role play with large language models.Nature, 2023
Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models.Nature, 2023. 2
2023
-
[55]
Dong J. Shao and S. Chen. Are We There Yet? Revealing the Risks of Utilizing Large Language Models in Scholarly Peer Review.CoRR abs/2412.01708, 2024. 1
arXiv 2024
-
[56]
Hyungyu Shin, Jingyu Tang, Yoonjoo Lee, Nayoung Kim, Hyunseung Lim, Ji Yong Cho, Hwajung Hong, Moontae Lee, and Juho Kim. Automatically Evaluating the Paper Reviewing Capability of Large Language Models.CoRR abs/2502.17086,
-
[57]
A Sys- tematic Review of Large Language Model (LLM) Evaluations in Clinical Medicine.BMC Medical Informatics and Decision Making, 2025
Sina Shool, Sara Adimi, and Reza Saboori Amleshi. A Sys- tematic Review of Large Language Model (LLM) Evaluations in Clinical Medicine.BMC Medical Informatics and Decision Making, 2025. 2
2025
-
[58]
Defining Quality in Peer Review Reports: A Ccoping Review.Knowledge and Information Systems, 2025
Amanda Sizo, Adriano Lino, Álvaro Rocha, and Luís Paulo Reis. Defining Quality in Peer Review Reports: A Ccoping Review.Knowledge and Information Systems, 2025. 6
2025
-
[59]
DetectLLM: Leveraging Log Rank Information for Zero-Shot Detection of Machine-Generated Text
Jinyan Su, Terry Yue Zhuo, Di Wang, and Preslav Nakov. DetectLLM: Leveraging Log Rank Information for Zero-Shot Detection of Machine-Generated Text. InFindings of the Association for Computational Linguistics: EMNLP (EMNLP Findings), pages 12395–12412. ACL, 2023. 4, 13
2023
-
[60]
Tools Used to Assess The Quality of Peer Review Reports: a Methodological Systematic Review.BMC Medical Research Methodology, 2019
Cecilia Superchi, José Antonio González, Ivan Solà, Erik Cobo, Darko Hren, and Isabelle Boutron. Tools Used to Assess The Quality of Peer Review Reports: a Methodological Systematic Review.BMC Medical Research Methodology, 2019. 6, 16
2019
-
[61]
Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards
Manveer Singh Tamber, Forrest Sheng Bao, Chenyu Xu, Ge Luo, Suleman Kazi, Minseok Bae, Miaoran Li, Ofer Mendelevitch, Renyi Qu, and Jimmy Lin. Benchmarking LLM Faithfulness in RAG with Evolving Leaderboards. InConfer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 799–811. ACL, 2025. 6, 15
2025
-
[62]
Tennant, Jonathan M
Jonathan P. Tennant, Jonathan M. Dugan, Daniel Graziotin, Damien C. Jacques, François Waldner, Daniel Mietchen, Yehia Elkhatib, Lauren B. Collister, Christina K. Pikas, Tom Crick, Paola Masuzzo, Anthony Caravaggi, Devin R. Berg, Kyle E. Niemeyer, Tony Ross-Hellauer, Sara Mannheimer, Lillian Rigling, Daniel S. Katz, Bastian Greshake Tzovaras, Josmel Pachec...
2017
-
[63]
Adversarial at- tacks against Fact Extraction and VERification.CoRR abs/1903.05543, 2019
James Thorne and Andreas Vlachos. Adversarial at- tacks against Fact Extraction and VERification.CoRR abs/1903.05543, 2019. 6
Pith/arXiv arXiv 1903
-
[64]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompt- ing.CoRR abs/2305.04388, 2023. 3
Pith/arXiv arXiv 2023
-
[65]
Visualizing Data using t-SNE.Journal of Machine Learning Research,
Laurens van der Maaten and Geoffrey Hinton. Visualizing Data using t-SNE.Journal of Machine Learning Research,
-
[66]
Using GPT-4 to Write A Scientific Review Article: A Pilot Evaluation Study.BioData Mining, 2024
Zhiping Paul Wang, Priyanka Bhandary, Yizhou Wang, and Jason H Moore. Using GPT-4 to Write A Scientific Review Article: A Pilot Evaluation Study.BioData Mining, 2024. 2
2024
-
[67]
Testing of Detection Tools 10 for AI-Generated Text.International Journal for Educational Integrity, 2023
Debora Weber-Wulff, Alla Anohina-Naumeca, Sonja Bjelob- aba, Tomáš Foltýnek, Jean Guerrero-Dib, Olumide Popoola, Petr Šigut, and Lorna Waddington. Testing of Detection Tools 10 for AI-Generated Text.International Journal for Educational Integrity, 2023. 2
2023
-
[68]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Lan- guage Models. InAnnual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS, 2022. 2, 3
2022
-
[69]
Tim Woelfle, Julian Hirt, Perrine Janiaud, Ludwig Kappos, John P. A. Ioannidis, and Lars G. Hemkens. Benchmarking Human–AI Collaboration for Common Evidence Appraisal Tools.Journal of Clinical Epidemiology, 2024. 2
2024
-
[70]
Position: The Artificial Intelligence and Machine Learning Community Should Adopt a More Transparent and Regulated Peer Review Process
Jing Yang. Position: The Artificial Intelligence and Machine Learning Community Should Adopt a More Transparent and Regulated Peer Review Process. InInternational Conference on Machine Learning (ICML). PMLR, 2025. 2
2025
-
[71]
Sungduk Yu, Man Luo, Avinash Madusu, Vasudev Lal, and Phillip Howard. Is Your Paper Being Reviewed by an LLM? A New Benchmark Dataset and Approach for Detecting AI Text in Peer Review.CoRR abs/2502.19614, 2025. 1, 2
arXiv 2025
-
[72]
Jinman Zhao, Zifan Qian, Linbo Cao, Yining Wang, Yitian Ding, Yulan Hu, Zeyu Zhang, and Zeyong Jin. Role-play Paradox in Large Language models: Reasoning Performance Gains and Ethical Dilemmas.CoRR abs/2409.13979, 2024. 2
arXiv 2024
-
[73]
Large Language Models Penetration in Scholarly Writing and Peer Review.CoRR abs/2502.11193, 2025
Li Zhou, Ruijie Zhang, Xunlian Dai, Daniel Hershcovich, and Haizhou Li. Large Language Models Penetration in Scholarly Writing and Peer Review.CoRR abs/2502.11193, 2025. 1
arXiv 2025
-
[74]
Is LLM a Reliable Reviewer? A Comprehensive Evaluation of LLM on Auto- matic Paper Reviewing Tasks
Ruiyang Zhou, Lu Chen, and Kai Yu. Is LLM a Reliable Reviewer? A Comprehensive Evaluation of LLM on Auto- matic Paper Reviewing Tasks. InInternational Conference on Computational Linguistics (COLING), pages 9340–9351. ACL, 2024. 2
2024
-
[75]
Large Lan- guage Models are Human-Level Prompt Engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large Lan- guage Models are Human-Level Prompt Engineers. InInterna- tional Conference on Learning Representations (ICLR), 2023. 1
2023
-
[76]
Large Language Models for Automated Scholarly Paper Review: A Survey.CoRR abs/2501.10326,
Zhenzhen Zhuang, Jiandong Chen, Hongfeng Xu, Yuwen Jiang, and Jialiang Lin. Large Language Models for Automated Scholarly Paper Review: A Survey.CoRR abs/2501.10326,
-
[77]
beats RoPE by 1.2 BLEU on WMT19 En-De
1, 2 A Prompt Templates A.1 Evaluation Prompt Sample You are a highly experienced machine learning researcher and a very strict reviewer for a premier machine learning conference. Your role as a reviewer demands meticulous attention to technical de- tails, rigorous evaluation of methodological soundness, and thorough assessment of theoretical contribution...
2024
-
[78]
It is an importantissue that the community needs to pay attention to
The paper points out that in the common experimental setup in related work, the private data and pre-training data might overlap. It is an importantissue that the community needs to pay attention to. 3. The results are promising. Weaknesses:
-
[79]
As a result, the contribution of the paper is overstated.2
The paper downplays and misinterprets the contribution of prior work in several places. As a result, the contribution of the paper is overstated.2. The proposed framework lacks novelty--the key components are already studied in prior work. Questions:My major concern is that the paper misinterprets the results from prior work and overstates its contributio...
-
[80]
(2022) DP-fine tuned pre-trained GPT models of various sizes
The paper repeatedly claims that prior work shows DP synthetic text results in a significant loss in downstream algorithms, e.g., ``Previous approacheseither show significant performance loss, or have, as we show, critical design flaws.'' in the abstract, and ``In similar vein, Yue et al. (2022) DP-fine tuned pre-trained GPT models of various sizes. However t...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.