QBioFusion-QSAR: Morgan-Anchored Quantum Multiple Kernel Learning for Small-Data Ligand Classification
Pith reviewed 2026-06-26 13:06 UTC · model grok-4.3
The pith
A quantum fidelity kernel adds localized similarity information to Morgan fingerprints for correcting specific false negatives in a 54-molecule QSAR benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
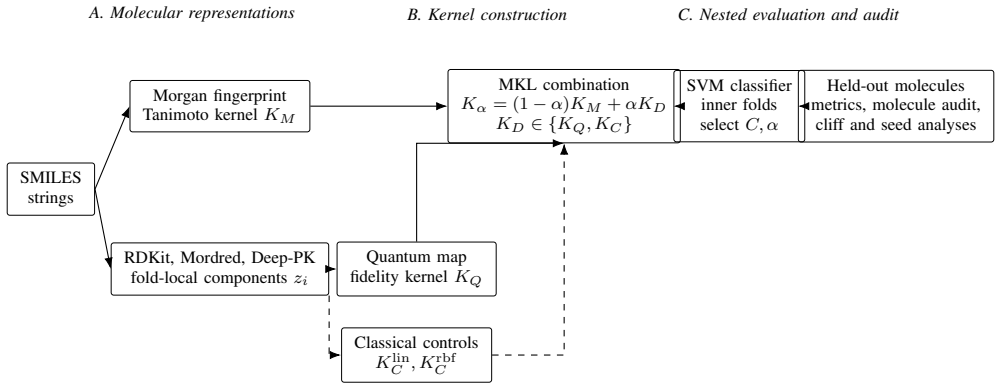
QMKL anchored on a Morgan/Tanimoto kernel and augmented by a quantum fidelity kernel built from fold-local RDKit, Mordred and Deep-PK components functions as an auditable framework that can isolate localized residual contributions from the quantum kernel in small-data, activity-cliff-aware ligand classification, as shown by the targeted prediction flips observed in the primary evaluation on the 54-molecule PsychLight-A set.
What carries the argument
Quantum multiple kernel learning (QMKL) that learns non-negative weights to combine a Morgan/Tanimoto kernel with a quantum fidelity kernel constructed from fold-local descriptor components.
If this is right
- The hybrid model can convert specific false negatives to true positives on activity-cliff molecules.
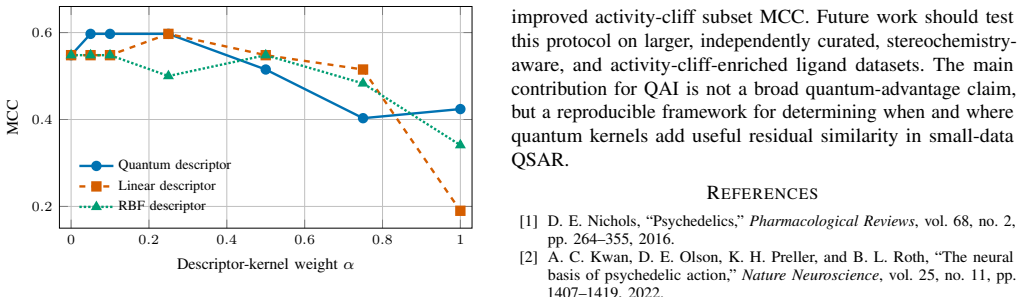
- Activity-cliff subset performance improves when the quantum kernel is included.
- The approach yields an auditable record of which molecules receive residual benefit from the quantum representation.
- Linear and RBF descriptor kernels serve as classical controls that do not produce the same localized flips.
Where Pith is reading between the lines
- The framework may prove more useful for targeted auditing of individual predictions than for blanket performance gains across all data partitions.
- Similar anchored multiple-kernel constructions could be tested on other small-data domains that feature conflicting labels among close analogues.
- Scaling the same protocol to datasets larger than 54 molecules would clarify whether localized quantum contributions remain detectable when more training examples are available.
Load-bearing premise
The quantum fidelity kernel supplies similarity information orthogonal to the Morgan/Tanimoto kernel rather than redundant variation that is absorbed by the learned combination weights.
What would settle it
An experiment in which matched-regularization auditing of the QMKL weights shows zero contribution from the quantum kernel on every molecule, or in which the two tryptamine analogues remain false negatives after the quantum component is added.
Figures
read the original abstract
Small quantitative structure-activity relationship (QSAR) studies are difficult when close molecular analogues have different activity labels. This paper asks whether a quantum kernel can add similarity information to a Morgan/Tanimoto fingerprint model, and which molecules account for the change. QBioFusion-QSAR uses quantum multiple kernel learning (QMKL): a support vector machine combines a Morgan/Tanimoto kernel with a quantum fidelity kernel constructed from fold-local components derived from RDKit and Mordred descriptors and Deep-PK features. Linear and radial basis function descriptor kernels are included as classical controls. On the 54-molecule PsychLight-A benchmark, Morgan/Tanimoto was the strongest single representation. In the primary stratified five-fold evaluation, QMKL increased accuracy from 0.815 to 0.833 and Matthews correlation coefficient (MCC) from 0.613 to 0.645. Matched-regularization auditing attributed the change to N-Me-5-HT and N-Me-tryptamine changing from false-negative to true-positive predictions; activity-cliff subset MCC increased from 0.07 to 0.22. Repeating the five-fold protocol over ten random partitionings showed that learned QMKL did not exceed Morgan/Tanimoto on mean MCC; paired held-out bootstrap intervals for the matched comparison also span zero. These results support QBioFusion-QSAR as an auditable QMKL framework for identifying localized residual quantum-kernel contributions in small-data, activity-cliff-aware ligand classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes QBioFusion-QSAR, a Morgan-anchored quantum multiple kernel learning (QMKL) framework for small-data QSAR ligand classification. It combines a Morgan/Tanimoto kernel with a quantum fidelity kernel built from fold-local RDKit/Mordred/Deep-PK components (plus classical descriptor kernels as controls) inside an SVM. On the 54-molecule PsychLight-A benchmark, Morgan/Tanimoto is the strongest single kernel; a primary stratified 5-fold split shows QMKL lifting accuracy from 0.815 to 0.833 and MCC from 0.613 to 0.645, with matched-regularization auditing attributing the change to N-Me-5-HT and N-Me-tryptamine flipping from false-negative to true-positive. The paper reports that the mean MCC advantage disappears over ten random partitionings and that paired bootstrap intervals span zero, yet concludes that the framework remains useful for auditable identification of localized residual quantum-kernel contributions in activity-cliff settings.
Significance. The provision of concrete metrics, repeated random partitions, and bootstrap intervals is a methodological strength. If the auditable QMKL framework can reliably isolate when the quantum fidelity kernel supplies non-redundant similarity information beyond Morgan/Tanimoto, the approach could be useful for interpreting kernel contributions in small-n, activity-cliff QSAR problems. However, the small sample size (n=54) and the absence of a reproducible mean performance gain limit the immediate significance for general ligand-classification practice.
major comments (2)
- [Abstract and Results] Abstract and primary evaluation protocol: the reported gains (accuracy 0.815→0.833, MCC 0.613→0.645) and the molecule-level attribution via matched-regularization auditing are obtained on a single stratified 5-fold split. The manuscript itself states that the same protocol repeated over ten random partitionings yields no mean MCC advantage and that paired held-out bootstrap intervals span zero. This directly tests whether the quantum fidelity kernel supplies orthogonal similarity information or merely partition-specific variation absorbed by the learned combination weights; the single-split auditing cannot distinguish these cases and therefore weakens the central claim of identifiable residual quantum-kernel contributions.
- [Methods and Evaluation] Evaluation and statistical power: with n=54 the study has limited power to detect small effects. The fact that bootstrap intervals for the matched QMKL vs. Morgan comparison include zero indicates that the observed single-split improvement is compatible with no true difference; any claim that the quantum kernel supplies localized, auditable value therefore requires either larger data or explicit power analysis to be load-bearing.
minor comments (1)
- [Abstract] The abstract could state more explicitly that the framework is offered as an auditing tool even though no consistent mean performance gain is observed, to prevent readers from over-interpreting the single-split numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing statistical rigor and the distinction between single-split auditing and multi-partition performance. We address each major comment below, noting that the manuscript already reports the multi-partition results and bootstrap intervals.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and primary evaluation protocol: the reported gains (accuracy 0.815→0.833, MCC 0.613→0.645) and the molecule-level attribution via matched-regularization auditing are obtained on a single stratified 5-fold split. The manuscript itself states that the same protocol repeated over ten random partitionings yields no mean MCC advantage and that paired held-out bootstrap intervals span zero. This directly tests whether the quantum fidelity kernel supplies orthogonal similarity information or merely partition-specific variation absorbed by the learned combination weights; the single-split auditing cannot distinguish these cases and therefore weakens the central claim of identifiable residual quantum-kernel contributions.
Authors: The manuscript already states that mean MCC advantage disappears over ten random partitionings and that bootstrap intervals span zero. The single stratified split serves as the primary evaluation to demonstrate the matched-regularization auditing procedure on a concrete case where localized improvements occur (N-Me-5-HT and N-Me-tryptamine flipping to true positives, with activity-cliff MCC rising from 0.07 to 0.22). The central claim is not general superiority of QMKL but that the framework enables auditable identification of residual quantum-kernel contributions in specific small-data, activity-cliff partitions when they arise. We will revise the abstract and discussion to frame the single-split results more explicitly as an illustration of the auditing method, while reiterating the multi-partition null result. revision: partial
-
Referee: [Methods and Evaluation] Evaluation and statistical power: with n=54 the study has limited power to detect small effects. The fact that bootstrap intervals for the matched QMKL vs. Morgan comparison include zero indicates that the observed single-split improvement is compatible with no true difference; any claim that the quantum kernel supplies localized, auditable value therefore requires either larger data or explicit power analysis to be load-bearing.
Authors: We agree that n=54 inherently limits power and that the bootstrap intervals spanning zero (already reported) indicate compatibility with no true mean difference. The paper positions QBioFusion-QSAR as a framework for small-data, activity-cliff QSAR where auditing can isolate per-molecule quantum contributions rather than claiming consistent performance gains. No a priori power analysis was performed, as the focus is this specific 54-molecule benchmark; the repeated random partitions and paired bootstrap serve as the empirical variability assessment. We will add a short paragraph in the evaluation section explicitly noting the power limitation and qualifying the auditing claims accordingly. revision: partial
Circularity Check
No significant circularity; standard held-out evaluation on multiple partitions
full rationale
The paper formulates QMKL as a convex combination of Morgan/Tanimoto and quantum fidelity kernels (plus classical controls), fits the combination weights and SVM hyperparameters on training folds of stratified 5-fold CV, and evaluates accuracy/MCC on the corresponding held-out folds. It then repeats the entire protocol over ten random partitionings and reports that mean MCC shows no advantage for QMKL, with bootstrap intervals spanning zero. This structure keeps the reported performance numbers independent of the fitting step; the single-split attribution to N-Me-5-HT and N-Me-tryptamine is presented as an auditing observation rather than a general claim. No self-definitional equations, fitted-input-renamed-as-prediction, or load-bearing self-citations appear in the derivation chain. The evaluation therefore remains falsifiable against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- SVM regularization parameter C
- QMKL kernel combination weights
axioms (1)
- domain assumption The quantum fidelity kernel is a valid positive semi-definite kernel suitable for SVM
Reference graph
Works this paper leans on
-
[1]
Psychedelics,
D. E. Nichols, “Psychedelics,”Pharmacological Reviews, vol. 68, no. 2, pp. 264–355, 2016
2016
-
[2]
The neural basis of psychedelic action,
A. C. Kwan, D. E. Olson, K. H. Preller, and B. L. Roth, “The neural basis of psychedelic action,”Nature Neuroscience, vol. 25, no. 11, pp. 1407–1419, 2022
2022
-
[3]
Mechanisms of signalling and biased agonism in G protein- coupled receptors,
D. Wootten, A. Christopoulos, M. Marti-Solano, M. M. Babu, and P. M. Sexton, “Mechanisms of signalling and biased agonism in G protein- coupled receptors,”Nature Reviews Molecular Cell Biology, vol. 19, no. 10, pp. 638–653, 2018
2018
-
[4]
Predicting the hallucinogenic potential of molecules using artificial intelligence,
F. Urbina, T. Jones, J. S. Harris, S. H. Snyder, T. R. Lane, and S. Ekins, “Predicting the hallucinogenic potential of molecules using artificial intelligence,”ACS Chemical Neuroscience, vol. 15, no. 16, pp. 3078– 3089, 2024
2024
-
[5]
Quantum machine learning in feature Hilbert spaces,
M. Schuld and N. Killoran, “Quantum machine learning in feature Hilbert spaces,”Physical Review Letters, vol. 122, no. 4, article 040504, 2019
2019
-
[6]
Supervised learning with quantum-enhanced feature spaces,
V . Havliceket al., “Supervised learning with quantum-enhanced feature spaces,”Nature, vol. 567, no. 7747, pp. 209–212, 2019
2019
-
[7]
Supervised quantum machine learning models are kernel methods,
M. Schuld, “Supervised quantum machine learning models are kernel methods,” arXiv:2101.11020, 2021
arXiv 2021
-
[8]
Q 2SAR: A quantum multiple kernel learning approach for drug discovery,
A. Giraldo, D. Ruiz, M. Caruso, J. Mancilla, and G. Bellomo, “Q 2SAR: A quantum multiple kernel learning approach for drug discovery,” arXiv:2506.14920, 2025
arXiv 2025
-
[9]
Extended-connectivity fingerprints,
D. Rogers and M. Hahn, “Extended-connectivity fingerprints,”Journal of Chemical Information and Modeling, vol. 50, no. 5, pp. 742–754, 2010
2010
-
[10]
Exposing the limitations of molecular machine learning with activity cliffs,
D. van Tilborg, A. Alenicheva, and F. Grisoni, “Exposing the limitations of molecular machine learning with activity cliffs,”Journal of Chemical Information and Modeling, vol. 62, no. 23, pp. 5938–5951, 2022
2022
-
[11]
RDKit: Open-source cheminformatics,
G. Landrum, “RDKit: Open-source cheminformatics,” 2024. [Online]. Available: https://www.rdkit.org
2024
-
[12]
Mordred: a molecular descriptor calculator,
H. Moriwaki, Y .-S. Tian, N. Kawashita, and T. Takagi, “Mordred: a molecular descriptor calculator,”Journal of Cheminformatics, vol. 10, no. 1, article 4, 2018
2018
-
[13]
Deep-PK: deep learning for small molecule pharmacokinetic and toxicity prediction,
Y . Myung, A. G. C. de Sa, and D. B. Ascher, “Deep-PK: deep learning for small molecule pharmacokinetic and toxicity prediction,”Nucleic Acids Research, vol. 52, no. W1, pp. W469–W475, 2024
2024
-
[14]
Scikit-learn: Machine learning in Python,
F. Pedregosaet al., “Scikit-learn: Machine learning in Python,”Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
2011
-
[15]
Sch ¨olkopf and A
B. Sch ¨olkopf and A. J. Smola,Learning with Kernels. Cambridge, MA, USA: MIT Press, 2002
2002
-
[16]
Multiple kernel learning algorithms,
M. G ¨onen and E. Alpaydin, “Multiple kernel learning algorithms,” Journal of Machine Learning Research, vol. 12, pp. 2211–2268, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.