Context-Aware Autoregressive Diffusion for Gloss-Wise Sign Language Production
Pith reviewed 2026-06-26 14:17 UTC · model grok-4.3
The pith
Gloss-wise autoregressive diffusion produces more accurate and natural sign language sequences by modeling coarticulation through context conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Context-aware Gloss-wise AutoRegressive Diffusion model (GARD) achieves superior performance over existing SLP methods in linguistic accuracy and motion similarity on the Phoenix-T and CSL-Daily datasets. It does so by modeling coarticulation via conditioning on semantic and kinematic contexts together with Inter-Gloss Transition Guidance and the Global Motion Harmonizer to ensure seamless pose consistency and natural continuity between glosses.
What carries the argument
GARD, the gloss-wise autoregressive diffusion framework that conditions generation on semantic and kinematic contexts to model coarticulation, supported by gradient-based Inter-Gloss Transition Guidance and Global Motion Harmonizer.
If this is right
- Individual glosses can be controlled more accurately in generated sign language sentences.
- Longer sign language sequences suffer less from temporal drift and hand motion blur.
- Both linguistic accuracy and motion similarity metrics improve compared to end-to-end generation methods.
- Natural continuity between glosses is achieved through boundary alignment and sequence refinement.
Where Pith is reading between the lines
- This gloss-wise strategy may extend to other autoregressive generation tasks in animation or robotics where unit-level control improves overall coherence.
- Testing on additional sign language datasets could reveal whether the context conditioning generalizes across different languages and dialects.
- Combining this diffusion approach with real-time input might enable more responsive sign language translation systems.
Load-bearing premise
That conditioning on semantic and kinematic contexts combined with the Inter-Gloss Transition Guidance and Global Motion Harmonizer produces seamless pose consistency and natural continuity between glosses without introducing new artifacts or reducing linguistic fidelity.
What would settle it
A direct comparison on the Phoenix-T and CSL-Daily datasets where GARD fails to outperform existing methods in both linguistic accuracy and motion similarity metrics, or where generated motions show visible inconsistencies at gloss boundaries.
Figures

read the original abstract
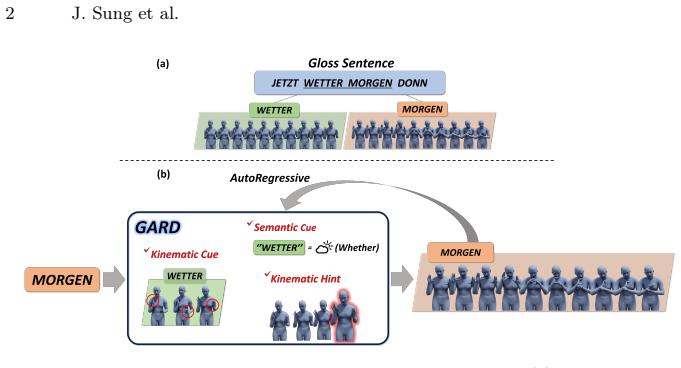
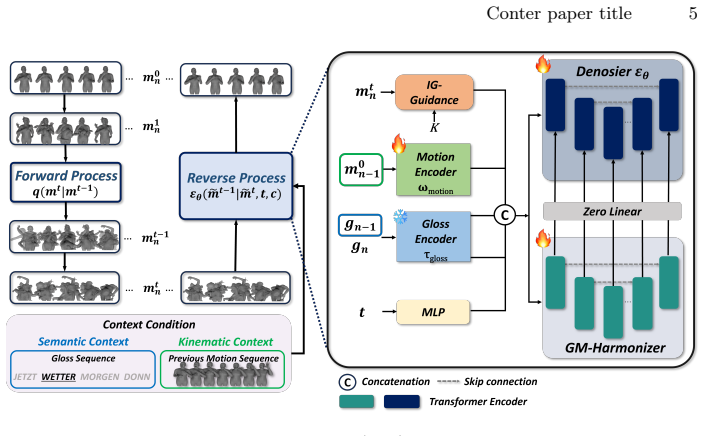
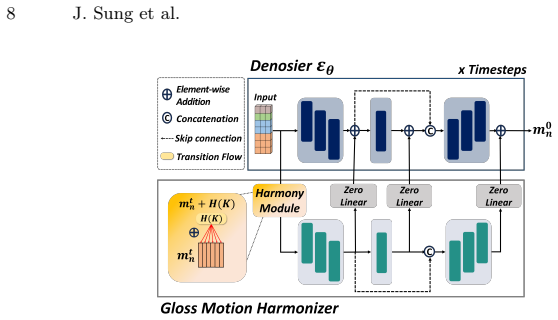
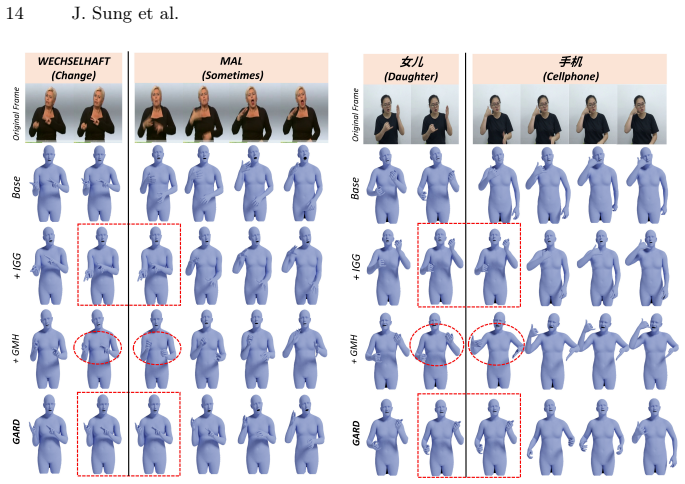
To generate natural and accurate sentence-level sign language, synthesizing the "gloss", the fundamental semantic unit, is essential. However, most current sign-language production (SLP) methods generate entire sequences at once. While this end-to-end approach is often efficient, it is prone to temporal drift and hand motion blur as sentences get longer, and fails to accurately control individual glosses. In this paper, we propose the Context-aware Gloss-wise AutoRegressive Diffusion model (GARD), a gloss-wise diffusion framework that models coarticulation by conditioning on both semantic (linguistic) and kinematic (motion) contexts. To ensure natural continuity between gloss motions, GARD introduces two additional strategies: i) Inter-Gloss Transition Guidance, which applies gradient-based guidance to kinematically align inter-gloss boundaries and ensure seamless pose consistency. ii) Global Motion Harmonizer, refining the entire gloss motion sequence based on the boundary poses adjusted by Inter-Gloss Transition Guidance. Extensive experiments on Phoenix-T and CSL-Daily datasets demonstrate that GARD achieves superior performance over existing SLP methods in terms of both linguistic accuracy and motion similarity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Context-aware Gloss-wise AutoRegressive Diffusion model (GARD) for sign language production (SLP). It generates sentence-level signs gloss by gloss via an autoregressive diffusion process conditioned on both semantic (linguistic) and kinematic (motion) contexts to model coarticulation. Two additional components are introduced: Inter-Gloss Transition Guidance, which uses gradient-based guidance to kinematically align inter-gloss boundaries, and a Global Motion Harmonizer that refines the full sequence based on the adjusted boundary poses. The central claim is that extensive experiments on the Phoenix-T and CSL-Daily datasets show GARD achieves superior performance over existing SLP methods in both linguistic accuracy and motion similarity.
Significance. If the empirical results hold, the work could advance SLP by offering improved control over individual glosses and better handling of coarticulation and temporal drift in longer sequences through a gloss-wise diffusion approach with dual-context conditioning and guidance mechanisms. This addresses known limitations of end-to-end sequence generation methods.
major comments (1)
- [Abstract] Abstract: The abstract asserts that GARD achieves superior performance over existing SLP methods on Phoenix-T and CSL-Daily in terms of linguistic accuracy and motion similarity, but supplies no quantitative metrics, baseline comparisons, ablation results, or error analysis. This prevents verification of whether the data supports the central claim.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that GARD achieves superior performance over existing SLP methods on Phoenix-T and CSL-Daily in terms of linguistic accuracy and motion similarity, but supplies no quantitative metrics, baseline comparisons, ablation results, or error analysis. This prevents verification of whether the data supports the central claim.
Authors: The referee is correct that the abstract states the performance claim at a high level without embedding specific numbers or comparisons. The manuscript body (Sections 4–5) contains the full quantitative results, baselines, ablations, and error analysis on both datasets. To improve verifiability directly from the abstract, we will revise it to include the key reported metrics (e.g., specific gains in BLEU, DTW, and motion similarity scores) while preserving its concise nature. revision: yes
Circularity Check
No significant circularity; empirical model proposal with external evaluation
full rationale
The paper introduces GARD as a novel gloss-wise autoregressive diffusion framework with semantic/kinematic conditioning, Inter-Gloss Transition Guidance, and Global Motion Harmonizer. These are architectural choices and training strategies presented as new contributions, then evaluated for superiority on external benchmark datasets (Phoenix-T, CSL-Daily) using standard linguistic and motion metrics. No derivation reduces a claimed prediction to an input by construction, no parameter is fitted then renamed as a prediction, and no load-bearing premise rests on a self-citation chain. The central claims are empirical performance results rather than tautological or self-referential mathematics, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion and autoregressive training hyperparameters
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Arkushin, R.S., Moryossef, A., Fried, O.: Ham2pose: Animating sign language no- tation into pose sequences. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 21046–21056 (2023)
2023
-
[2]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR)
Baltatzis, V., Potamias, R.A., Ververas, E., Sun, G., Deng, J., Zafeiriou, S.: Neu- ral sign actors: A diffusion model for 3d sign language production from text. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR). pp. 1985–1995 (June 2024)
1985
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bao, F., Nie, S., Xue, K., Cao, Y., Li, C., Su, H., Zhu, J.: All are worth words: A vit backbone for diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22669–22679 (2023)
2023
-
[4]
Advances in neural information pro- cessing systems28(2015)
Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N.: Scheduled sampling for sequence prediction with recurrent neural networks. Advances in neural information pro- cessing systems28(2015)
2015
-
[5]
In: Proceedings of the 3rd international conference on knowledge discovery and data mining
Berndt, D.J., Clifford, J.: Using dynamic time warping to find patterns in time series. In: Proceedings of the 3rd international conference on knowledge discovery and data mining. pp. 359–370 (1994)
1994
-
[6]
Bragg, D., Koller, O., Bellard, M., Berke, L., Boudreault, P., Braffort, A., Caselli, N., Huenerfauth, M., Kacorri, H., Verhoef, T., et al.: Sign language recognition, generation,andtranslation:Aninterdisciplinaryperspective.In:Proceedingsofthe 21st international ACM SIGACCESS conference on computers and accessibility. pp. 16–31 (2019)
2019
-
[7]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Camgoz, N.C., Hadfield, S., Koller, O., Ney, H., Bowden, R.: Neural sign language translation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7784–7793 (2018)
2018
-
[8]
Channer, C.S.: Coarticulation in american sign language fingerspelling (2012)
2012
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing your commands via motion diffusion in latent space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18000–18010 (2023)
2023
- [10]
-
[11]
Advances in Neural Information Processing Systems35, 17043–17056 (2022)
Chen, Y., Zuo, R., Wei, F., Wu, Y., Liu, S., Mak, B.: Two-stream network for sign language recognition and translation. Advances in Neural Information Processing Systems35, 17043–17056 (2022)
2022
-
[12]
In: 2024 IEEE 18th Interna- tional Conference on Automatic Face and Gesture Recognition (FG)
Dong, L., Chaudhary, L., Xu, F., Wang, X., Lary, M., Nwogu, I.: Signavatar: Sign language 3d motion reconstruction and generation. In: 2024 IEEE 18th Interna- tional Conference on Automatic Face and Gesture Recognition (FG). pp. 1–10. IEEE (2024)
2024
-
[13]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
Dong, L., Wang, X., Nwogu, I.: Word-conditioned 3D American Sign Language motion generation. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 9993–9999. Association for Computational Linguistics, Miami, Florida, USA (Nov 2024). https://doi.org/10.18653/v1/2024.findings-emnlp.584
-
[14]
arXiv preprint arXiv:2308.16082 (2023)
Fang, S., Sui, C., Zhou, Y., Zhang, X., Zhong, H., Zhao, M., Tian, Y., Chen, C.: Signdiff: Diffusion models for american sign language production. arXiv preprint arXiv:2308.16082 (2023)
-
[15]
arXiv preprint arXiv:2405.15439 (2024) 16 J
Geng, Z., Han, C., Hayder, Z., Liu, J., Shah, M., Mian, A.: Text-guided 3d human motion generation with keyframe-based parallel skip transformer. arXiv preprint arXiv:2405.15439 (2024) 16 J. Sung et al
-
[16]
In: Computer Graphics Forum
Ghorbani, S., Wloka, C., Etemad, A., Brubaker, M.A., Troje, N.F.: Probabilistic character motion synthesis using a hierarchical deep latent variable model. In: Computer Graphics Forum. vol. 39, pp. 225–239. Wiley Online Library (2020)
2020
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gong, J., Foo, L.G., He, Y., Rahmani, H., Liu, J.: Llms are good sign language translators. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18362–18372 (2024)
2024
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating di- verse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5152–5161 (June 2022)
2022
-
[19]
In: Proceedings of the 28th ACM international conference on multimedia
Guo, C., Zuo, X., Wang, S., Zou, S., Sun, Q., Deng, A., Gong, M., Cheng, L.: Action2motion: Conditioned generation of 3d human motions. In: Proceedings of the 28th ACM international conference on multimedia. pp. 2021–2029 (2020)
2021
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[21]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
In: Proceedings of the 29th ACM International Conference on Multimedia
Huang, W., Pan, W., Zhao, Z., Tian, Q.: Towards fast and high-quality sign lan- guage production. In: Proceedings of the 29th ACM International Conference on Multimedia. pp. 3172–3181 (2021)
2021
-
[23]
In: BMVC
Hwang, E.J., Kim, J.H., Park, J.C.: Non-autoregressive sign language production with gaussian space. In: BMVC. vol. 1, p. 3 (2021)
2021
-
[24]
In: 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG)
Hwang, E.J., Lee, H., Park, J.C.: A gloss-free sign language production with dis- crete representation. In: 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). pp. 1–6. IEEE (2024)
2024
-
[25]
Advances in Neural Information Processing Systems36, 20067–20079 (2023)
Jiang, B., Chen, X., Liu, W., Yu, J., Yu, G., Chen, T.: Motiongpt: Human motion as a foreign language. Advances in Neural Information Processing Systems36, 20067–20079 (2023)
2023
-
[26]
In: Pro- ceedings of the IEEE/CVF international conference on computer vision
Jiao, P., Min, Y., Li, Y., Wang, X., Lei, L., Chen, X.: Cosign: Exploring co- occurrence signals in skeleton-based continuous sign language recognition. In: Pro- ceedings of the IEEE/CVF international conference on computer vision. pp. 20676– 20686 (2023)
2023
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Karunratanakul, K., Preechakul, K., Suwajanakorn, S., Tang, S.: Guided mo- tion diffusion for controllable human motion synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2151–2162 (2023)
2023
-
[28]
In: Text sum- marization branches out
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text sum- marization branches out. pp. 74–81 (2004)
2004
-
[29]
Transactions of the Association for Computational Linguistics8, 726–742 (2020)
Liu, Y., Gu, J., Goyal, N., Li, X., Edunov, S., Ghazvininejad, M., Lewis, M., Zettlemoyer, L.: Multilingual denoising pre-training for neural machine translation. Transactions of the Association for Computational Linguistics8, 726–742 (2020)
2020
-
[30]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
The handbook of linguistic human rights pp
Manning, V., Murray, J.J., Bloxs, A.: Linguistic human rights in the work of the world federation of the deaf. The handbook of linguistic human rights pp. 267–280 (2022)
2022
-
[32]
In: ISSP 2024-13th International Seminar on Speech Production
Mertz, J., Pagel, L., Perniss, P., Turco, G., Mücke, D.: Coarticulation in sign lan- guage: A kinematic study on french sign language (lsf) using electromagnetic artic- ulography (ema). In: ISSP 2024-13th International Seminar on Speech Production. pp. 51–54. ISCA (2024)
2024
-
[33]
Murray, J.: World federation of the deaf (2020) Conter paper title 17
2020
-
[34]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
2002
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single im- age. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10975–10985 (2019)
2019
-
[36]
In: European conference on computer vision
Petrovich, M., Black, M.J., Varol, G.: Temos: Generating diverse human motions from textual descriptions. In: European conference on computer vision. pp. 480–
-
[37]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[38]
In: European Conference on Computer Vision
Saunders, B., Camgoz, N.C., Bowden, R.: Progressive transformers for end-to-end sign language production. In: European Conference on Computer Vision. pp. 687–
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Saunders, B., Camgoz, N.C., Bowden, R.: Mixed signals: Sign language production via a mixture of motion primitives. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1919–1929 (2021)
1919
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Saunders,B.,Camgoz,N.C.,Bowden,R.:Signingatscale:Learningtoco-articulate signs for large-scale photo-realistic sign language production. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5141– 5151 (2022)
2022
-
[41]
ACM Sigaccess Accessibility and Computing (93), 31–38 (2009)
Segouat, J.: A study of sign language coarticulation. ACM Sigaccess Accessibility and Computing (93), 31–38 (2009)
2009
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shan, W., Liu, Z., Zhang, X., Wang, Z., Han, K., Wang, S., Ma, S., Gao, W.: Diffusion-based 3d human pose estimation with multi-hypothesis aggregation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14761–14771 (2023)
2023
-
[43]
Journal of deaf studies and deaf education10(1), 3–37 (2005)
Stokoe Jr, W.C.: Sign language structure: An outline of the visual communication systems of the american deaf. Journal of deaf studies and deaf education10(1), 3–37 (2005)
2005
-
[45]
In: 2022 International Conference on 3D Vision (3DV)
Stoll, S., Mustafa, A., Guillemaut, J.Y.: There and back again: 3d sign language generation from text using back-translation. In: 2022 International Conference on 3D Vision (3DV). pp. 187–196. IEEE (2022)
2022
-
[46]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Tang, S., He, J., Cheng, L., Wu, J., Guo, D., Hong, R.: Discrete to continuous: Generating smooth transition poses from sign language observations. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 3481–3491 (2025)
2025
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tang, S., He, J., Guo, D., Wei, Y., Li, F., Hong, R.: Sign-idd: Iconicity disentangled diffusion for sign language production. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7266–7274 (2025)
2025
-
[48]
In: ACM International Con- ference on Multimedia (ACM MM) (Oct 2022)
Tang, S., Hong, R., Guo, D., Wang, M.: Gloss semantic-enhanced network with online back-translation for sign language production. In: ACM International Con- ference on Multimedia (ACM MM) (Oct 2022)
2022
-
[49]
ACM Transactions on Multimedia Comput- ing, Communications, and Applications (2024) 18 J
Tang, S., Xue, F., Wu, J., Wang, S., Hong, R.: Gloss-driven conditional diffusion models for sign language production. ACM Transactions on Multimedia Comput- ing, Communications, and Applications (2024) 18 J. Sung et al
2024
-
[50]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. arXiv preprint arXiv:2209.14916 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[52]
arXiv preprint arXiv:2202.05383 (2022)
Viegas, C., Inan, M., Quandt, L., Alikhani, M.: Including facial expressions in con- textual embeddings for sign language generation. arXiv preprint arXiv:2202.05383 (2022)
-
[53]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Xie, P., Peng, T., Du, Y., Zhang, Q.: Sign language production with latent motion transformer. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 3024–3034 (2024)
2024
-
[54]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xie, P., Zhang, Q., Taiying, P., Tang, H., Du, Y., Li, Z.: G2p-ddm: Generating sign pose sequence from gloss sequence with discrete diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 6234–6242 (2024)
2024
-
[55]
In: The Twelfth International Conferenceon LearningRepresentations(2024),https://openreview.net/forum? id=gd0lAEtWso
Xie, Y., Jampani, V., Zhong, L., Sun, D., Jiang, H.: Omnicontrol: Control any joint at any time for human motion generation. In: The Twelfth International Conferenceon LearningRepresentations(2024),https://openreview.net/forum? id=gd0lAEtWso
2024
-
[56]
arXiv preprint arXiv:2406.07119 (2024)
Yin, A., Li, H., Shen, K., Tang, S., Zhuang, Y.: T2s-gpt: Dynamic vector quan- tization for autoregressive sign language production from text. arXiv preprint arXiv:2406.07119 (2024)
-
[57]
Yin, K., Moryossef, A., Hochgesang, J., Goldberg, Y., Alikhani, M.: Including signed languages in natural language processing. In: Proceedings of the 59th An- nual Meeting of the Association for Computational Linguistics and the 11th In- ternational Joint Conference on Natural Language Processing (Volume 1: Long Papers). pp. 7347–7360 (2021)
2021
-
[58]
In: European Conference on Computer Vision
Yu,Z.,Huang,S.,Cheng,Y.,Birdal,T.:Signavatars:Alarge-scale3dsignlanguage holistic motion dataset and benchmark. In: European Conference on Computer Vision. pp. 1–19. Springer (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[60]
IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024)
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondiffuse: Text-driven human motion generation with diffusion model. IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024)
2024
-
[61]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, H., Zhou, W., Qi, W., Pu, J., Li, H.: Improving sign language translation with monolingual data by sign back-translation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1316–1325 (2021)
2021
-
[62]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019)
2019
-
[63]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zuo, R., Potamias, R.A., Ververas, E., Deng, J., Zafeiriou, S.: Signs as tokens: A retrieval-enhanced multilingual sign language generator. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23806–23816 (2025)
2025
-
[64]
In: European Conference on Computer Vision
Zuo,R.,Wei,F.,Chen,Z.,Mak,B.,Yang,J.,Tong,X.:Asimplebaselineforspoken language to sign language translation with 3d avatars. In: European Conference on Computer Vision. pp. 36–54. Springer (2024)
2024
-
[65]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Zuo, R., Wei, F., Mak, B.: Towards online continuous sign language recognition and translation. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 11050–11067 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.