DIPBox: A Multi-scale Testing Framework for Tracking Dataset Regeneration
Pith reviewed 2026-06-26 14:13 UTC · model grok-4.3
The pith
DIPBox detects unauthorized dataset regeneration by checking similarity at sample, set, and distribution scales under varying defender access.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
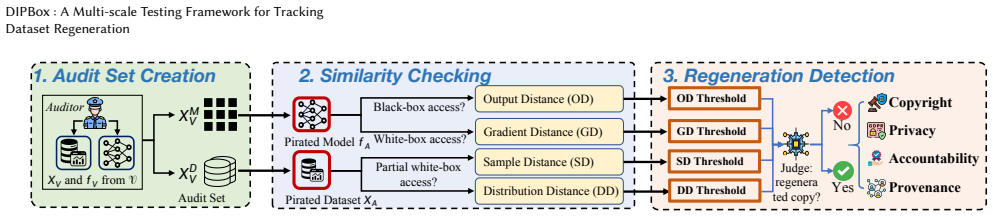
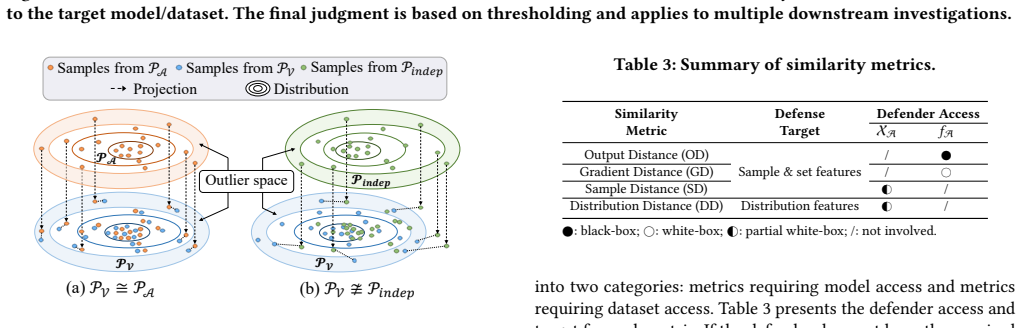
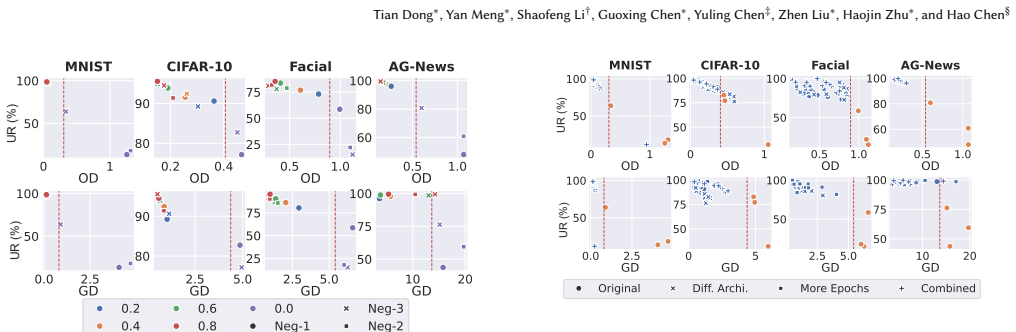
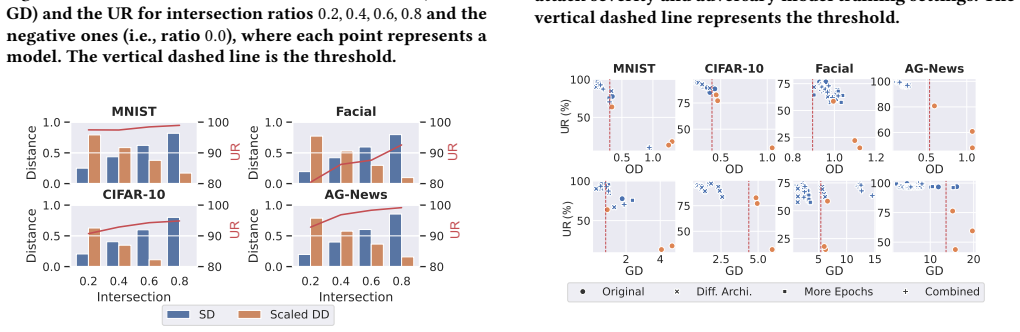
Regeneration that preserves model utility inevitably preserves measurable signals across sample-, set-, and distribution-level features. These signals are captured by four similarity metrics that allow accurate identification of regeneration suspects. DIPBox is the first testing framework that applies multi-scale similarity testing across a spectrum of defender access settings from limited to full information, with a learning-theoretic analysis that formalizes the utility-divergence trade-off and its implied limits on evasive regeneration.
What carries the argument
DIPBox multi-scale similarity testing framework using four metrics on sample-, set-, and distribution-level features, applied across limited-to-full defender information settings.
If this is right
- Regenerated datasets remain identifiable even when they preserve high model utility.
- Detection works under partial defender information about the original dataset.
- An inherent trade-off limits how far regeneration can diverge without sacrificing utility.
- The approach outperforms prior single-scale or point-based tracking methods.
- Robustness holds under three forms of adaptive attack.
Where Pith is reading between the lines
- Multi-scale checks could extend to auditing other data-misuse patterns such as partial extraction or synthetic augmentation.
- License holders might apply the metrics to verify compliance when models are trained on claimed datasets.
- Complete evasion without utility loss may prove impractical, raising the effective cost of unauthorized copying.
Load-bearing premise
Regeneration that keeps model utility must also preserve detectable similarity signals at sample, set, and distribution scales.
What would settle it
A regeneration procedure that trains models to the same accuracy as the original dataset yet produces low scores on all four similarity metrics at every scale.
Figures







read the original abstract
Training datasets have tremendous proprietary value and are vulnerable to unauthorized copying. Existing defenses mainly focus on tracking individual data points, but pay little attention to the threat of dataset regeneration. Through a measurement study of public tumor datasets, we identify substantial real-world partial-dataset replication, raising concerns about potential license noncompliance. To counter the challenge of tracking previously unknown adversarial regeneration, our key insight is that regeneration that preserves model utility inevitably preserves measurable signals across multiple feature scales. We categorize these dataset features into sample-, set-, and distribution-level features and design four similarity metrics to accurately identify regeneration. Based on these metrics, we develop DIPBox, which to our knowledge is the first testing framework that tracks regeneration suspects via multi-scale similarity testing across a spectrum of defender access settings, from limited to full information. We further provide a learning-theoretic analysis that justifies these multi-scale metrics and formalizes an inherent utility--divergence trade-off, implying fundamental limits on evasive regeneration. Extensive experiments on 16 vision and text base datasets, 320 regenerated datasets, and 590 derived models validate that DIPBox outperforms previous solutions while characterizing its robustness and limits under three adaptive attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DIPBox, a multi-scale testing framework for detecting unauthorized dataset regeneration. It categorizes dataset features into sample-, set-, and distribution-level signals, introduces four similarity metrics, develops a testing framework spanning limited to full defender information settings, provides a learning-theoretic analysis of an inherent utility-divergence trade-off, and reports experiments on 16 base datasets, 320 regenerations, and 590 models showing outperformance over prior methods and robustness under three adaptive attacks.
Significance. If the central claims hold, the work would represent a meaningful advance in dataset provenance tracking by moving beyond single-point watermarking to multi-scale detection with formal grounding. The scale of the experimental evaluation (16 base datasets, 320 regenerations, 590 models) and the attempt to derive fundamental limits via learning theory are clear strengths that would support impact in the data-protection and ML-security communities.
major comments (1)
- [Abstract and learning-theoretic analysis] Abstract and learning-theoretic analysis: the claim that 'regeneration that preserves model utility inevitably preserves measurable signals across multiple feature scales' and that the analysis 'implies fundamental limits on evasive regeneration' is load-bearing for the identification accuracy of DIPBox. The analysis does not appear to state explicit assumptions on the class of allowed regenerations (e.g., whether regenerations are restricted to convex combinations, fixed model architectures, or particular divergence families). Without such restrictions it remains possible to construct utility-preserving regenerations that drive the four chosen metrics below detection thresholds, falsifying the inevitability premise.
minor comments (2)
- [Experimental evaluation] The abstract states experiments cover '16 vision and text base datasets' but does not enumerate them; an explicit list (with references) in §5 or the experimental setup would improve reproducibility.
- [Metrics definition] Notation for the four similarity metrics is introduced in the abstract but their precise mathematical definitions (including any hyperparameters) should be stated with numbered equations in the main body rather than deferred to an appendix.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the scale of our experimental evaluation and the learning-theoretic contributions. We address the single major comment below, proposing a targeted revision to clarify assumptions in the analysis section.
read point-by-point responses
-
Referee: Abstract and learning-theoretic analysis: the claim that 'regeneration that preserves model utility inevitably preserves measurable signals across multiple feature scales' and that the analysis 'implies fundamental limits on evasive regeneration' is load-bearing for the identification accuracy of DIPBox. The analysis does not appear to state explicit assumptions on the class of allowed regenerations (e.g., whether regenerations are restricted to convex combinations, fixed model architectures, or particular divergence families). Without such restrictions it remains possible to construct utility-preserving regenerations that drive the four chosen metrics below detection thresholds, falsifying the inevitability premise.
Authors: We appreciate the referee's identification of this point. The learning-theoretic analysis formalizes a utility-divergence trade-off under the standard setting of statistical learning theory, where regenerations are modeled as transformations that preserve downstream model performance (i.e., the regenerated dataset yields models with comparable empirical risk on the task). The analysis shows that maintaining low utility loss requires the regenerated distribution to remain close in specific divergence measures that align with our multi-scale metrics. However, we agree that the manuscript does not explicitly enumerate the precise class of regenerations (e.g., excluding arbitrary non-distribution-preserving maps or architecture-specific attacks). We will revise the analysis section (and corresponding abstract phrasing) to state these assumptions explicitly, including that the inevitability result holds for regenerations that do not fundamentally alter the data-generating process beyond bounded perturbations consistent with utility preservation. We will also add a discussion of the result's scope and potential counterexamples outside these assumptions. This revision will be made without changing the core claims or experiments. revision: yes
Circularity Check
No circularity identified; derivation self-contained via external analysis and experiments
full rationale
The abstract and description present the multi-scale metrics as motivated by an empirical measurement study and justified by a separate learning-theoretic analysis formalizing a utility-divergence trade-off. No quoted equations or steps reduce the claimed predictions or limits to fitted parameters, self-definitions, or self-citation chains. Experiments on 16 base datasets, 320 regenerations, and 590 models provide independent validation. The central inevitability premise is framed as a theorem-derived limit rather than a renaming or ansatz smuggling. This meets the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
10Duke. 2023. Software Copyright – Basics Explained. https://www.10duke.com/resources/glossary/software-copyright
2023
-
[2]
Goodfellow, H
Martín Abadi, Andy Chu, Ian J. Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, 2016. ACM, 308–318
2016
-
[3]
Ehsan Amid, Rohan Anil, Wojciech Kotlowski, and Manfred K. Warmuth
-
[4]
Learning from Randomly Initialized Neural Network Features.CoRR abs/2202.06438 (2022)
arXiv 2022
-
[5]
arXiv. 2026. arXiv moderation. https://info.arxiv.org/help/moderation/index. html
2026
-
[6]
Buse Gul Atli Tekgul and N. Asokan. 2022. On the Effectiveness of Dataset Watermarking. InProceedings of the 2022 ACM on International Workshop on Se- curity and Privacy Analytics (IWSPA ’22). Association for Computing Machinery, 93–99
2022
-
[7]
Ms Aayushi Bansal, Dr Rewa Sharma, and Dr Mamta Kathuria. 2022. A systematic review on data scarcity problem in deep learning: solution and applications.ACM Computing Surveys (Csur)54, 10s (2022), 1–29
2022
-
[8]
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. 2010. A theory of learning from different domains.Machine learning79, 1 (2010), 151–175
2010
-
[9]
Prajjwal Bhargava, Aleksandr Drozd, and Anna Rogers. 2021. Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics. arXiv:2110.01518 [cs.CL]
arXiv 2021
-
[10]
Sutherland, Michael Arbel, and Arthur Gretton
Mikolaj Binkowski, Danica J. Sutherland, Michael Arbel, and Arthur Gretton
-
[11]
In6th International Conference on Learning Representations, ICLR 2018
Demystifying MMD GANs. In6th International Conference on Learning Representations, ICLR 2018
2018
-
[12]
Olivier Bousquet and André Elisseeff. 2002. Stability and generalization.Journal of machine learning research2, Mar (2002), 499–526
2002
-
[13]
Dingfan Chen, Raouf Kerkouche, and Mario Fritz. 2022. Private Set Generation with Discriminative Information. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[14]
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. 2020. GAN-Leaks: A Taxonomy of Membership Inference Attacks against Generative Models. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (CCS ’20). ACM, New York, NY, USA, 343–362
2020
-
[15]
Jialuo Chen, Jingyi Wang, Tinglan Peng, Youcheng Sun, Peng Cheng, Shouling Ji, Xingjun Ma, Bo Li, and Dawn Song. 2022. Copy, Right? A Testing Framework for Copyright Protection of Deep Learning Models. In43rd IEEE Symposium on Security and Privacy, SP 2022. IEEE, 824–841
2022
-
[16]
Jingjing Chen, Xiaobin Wang, Chen Huang, Xin Hu, Xinke Shen, and Dan Zhang
-
[17]
A large finer-grained affective computing EEG dataset.Scientific Data10, 1 (2023), 740
2023
-
[18]
Adam Coates, Andrew Ng, and Honglak Lee. 2011. An analysis of single-layer networks in unsupervised feature learning. InProceedings of the fourteenth inter- national conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 215–223
2011
-
[19]
Former Contributor. 2015. Five Reasons To Copyright Register Your Software Now. https://www.forbes.com/sites/oliverherzfeld/2015/10/26/five-reasons-to- copyright-your-software-now
2015
-
[20]
Luke N Darlow, Elliot J Crowley, Antreas Antoniou, and Amos J Storkey. 2018. Cinic-10 is not imagenet or cifar-10.arXiv preprint arXiv:1810.03505(2018)
Pith/arXiv arXiv 2018
-
[21]
Tian Dong, Shaofeng Li, Guoxing Chen, Minhui Xue, Haojin Zhu, and Zhen Liu
-
[22]
In 30th Annual Network and Distributed System Security Symposium, NDSS 2023
RAI2: Responsible Identity Audit Governing the Artificial Intelligence. In 30th Annual Network and Distributed System Security Symposium, NDSS 2023. The Internet Society
2023
-
[23]
Linkang Du, Min Chen, Mingyang Sun, Shouling Ji, Peng Cheng, Jiming Chen, and Zhikun Zhang. 2024. ORL-AUDITOR: Dataset Auditing in Offline Deep Reinforcement Learning. In31st Annual Network and Distributed System Security Symposium, NDSS 2024. The Internet Society
2024
-
[24]
Linkang Du, Xuanru Zhou, Min Chen, Chusong Zhang, Zhou Su, Peng Cheng, Jiming Chen, and Zhikun Zhang. 2025. SoK: Dataset Copyright Auditing in Machine Learning Systems. InIEEE Symposium on Security and Privacy, SP 2025. IEEE
2025
-
[25]
The Economist. 2024. AI firms will soon exhaust most of the internet’s data. https://www.economist.com/schools-brief/2024/07/23/ai-firms-will-soon- exhaust-most-of-the-internets-data
2024
-
[26]
Bent Fuglede and Flemming Topsøe. 2004. Jensen-Shannon divergence and Hilbert space embedding. InProceedings of the 2004 IEEE International Symposium on Information Theory, ISIT 2004. IEEE, 31
2004
-
[27]
Bronstein
Raja Giryes, Guillermo Sapiro, and Alexander M. Bronstein. 2016. Deep Neural Networks with Random Gaussian Weights: A Universal Classification Strategy? 14 DIPBox: A Multi-scale Testing Framework for Tracking Dataset Regeneration IEEE Trans. Signal Process.64, 13 (2016), 3444–3457
2016
-
[28]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander J. Smola. 2012. A Kernel Two-Sample Test.J. Mach. Learn. Res.13 (2012), 723–773
2012
-
[29]
Besold, and Alexandre M
Kathrin Grosse, Lukas Bieringer, Tarek R. Besold, and Alexandre M. Alahi. 2024. Towards More Practical Threat Models in Artificial Intelligence Security. InProc. of USENIX Security
2024
-
[30]
Frederik Harder, Kamil Adamczewski, and Mijung Park. 2021. DP-MERF: Differ- entially Private Mean Embeddings with RandomFeatures for Practical Privacy- preserving Data Generation. InThe 24th International Conference on Artificial Intelligence and Statistics, AISTATS 2021 (Proceedings of Machine Learning Re- search, Vol. 130). PMLR, 1819–1827
2021
-
[31]
Moritz Hardt, Ben Recht, and Yoram Singer. 2016. Train faster, generalize better: Stability of stochastic gradient descent. InInternational conference on machine learning. PMLR, 1225–1234
2016
-
[32]
Sameed Hayat. 2026. Guardian News Dataset. https://www.kaggle.com/datasets/ sameedhayat/guardian-news-dataset. Accessed: 2026-06-18
2026
-
[33]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProc. of IEEE CVPR
2016
-
[34]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Proba- bilistic Models. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020
2020
-
[35]
Yangsibo Huang, Chun-Yin Huang, Xiaoxiao Li, and Kai Li. 2022. A Dataset Auditing Method for Collaboratively Trained Machine Learning Models.IEEE Transactions on Medical Imaging(2022)
2022
-
[36]
Zonghao Huang, Neil Zhenqiang Gong, and Michael K. Reiter. 2024. A General Framework for Data-Use Auditing of ML Models. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, 2024. ACM
2024
-
[37]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. 2022. Elucidating the Design Space of Diffusion-Based Generative Models. InNeurIPS
2022
-
[38]
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. 2020. Training Generative Adversarial Networks with Limited Data. InProc. NeurIPS
2020
-
[39]
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-Free Generative Adversarial Networks. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021. 852–863
2021
-
[40]
Sander Koelstra, Christian Muhl, Mohammad Soleymani, Jong-Seok Lee, Ashkan Yazdani, Touradj Ebrahimi, Thierry Pun, Anton Nijholt, and Ioannis Patras
-
[41]
Deap: A database for emotion analysis; using physiological signals.IEEE transactions on affective computing3, 1 (2011), 18–31
2011
-
[42]
Berg, Peter N
Neeraj Kumar, Alexander C. Berg, Peter N. Belhumeur, and Shree K. Nayar. 2009. Attribute and simile classifiers for face verification. InIEEE 12th International Conference on Computer Vision, ICCV 2009. IEEE Computer Society, 365–372
2009
-
[43]
Huseyin Kusetogullari, Amir Yavariabdi, Abbas Cheddad, Håkan Grahn, and Johan Hall. 2020. ARDIS: a Swedish historical handwritten digit dataset.Neural Comput. Appl.32, 21 (2020), 16505–16518
2020
-
[44]
Huseyin Kusetogullari, Amir Yavariabdi, Johan Hall, and Niklas Lavesson. 2021. DIGITNET: A Deep Handwritten Digit Detection and Recognition Method Using a New Historical Handwritten Digit Dataset.Big Data Res.23 (2021), 100182
2021
-
[45]
Yiming Li, Yang Bai, Yong Jiang, Yong Yang, Shu-Tao Xia, and Bo Li. 2022. Untar- geted Backdoor Watermark: Towards Harmless and Stealthy Dataset Copyright Protection. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[46]
Yiming Li, Mingyan Zhu, Xue Yang, Yong Jiang, Tao Wei, and Shu-Tao Xia. 2023. Black-box Dataset Ownership Verification via Backdoor Watermarking.IEEE Transactions on Information Forensics and Security(2023), 1–1. doi:10.1109/TIFS. 2023.3265535
-
[47]
Gaoyang Liu, Tianlong Xu, Xiaoqiang Ma, and Chen Wang. 2022. Your Model Trains on My Data? Protecting Intellectual Property of Training Data via Mem- bership Fingerprint Authentication.IEEE Trans. Inf. Forensics Secur.17 (2022), 1024–1037
2022
-
[48]
Hui Liu, Hongzhi Luo, Shaofeng Li, Tian Dong, Guoxing Chen, Yan Meng, and Haojin Zhu. 2023. Privacy Computing with Right to Be Forgotten in Trusted Execution Environment. InIEEE Global Communications Conference (GlobeCom), Kuala Lumpur, Malaysia
2023
-
[49]
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2015. Deep Learning Face Attributes in the Wild. InProceedings of International Conference on Computer Vision (ICCV)
2015
-
[50]
Shayne Longpre, Robert Mahari, Anthony Chen, Naana Obeng-Marnu, Damien Sileo, William Brannon, Niklas Muennighoff, Nathan Khazam, Jad Kabbara, Kartik Perisetla, et al. 2024. A large-scale audit of dataset licensing and attribution in AI.Nature Machine Intelligence6, 8 (2024), 975–987
2024
-
[51]
Shayne Longpre, Robert Mahari, Ariel Lee, Campbell Lund, Hamidah Oderinwale, William Brannon, Nayan Saxena, Naana Obeng-Marnu, Tobin South, Cole Hunter, Kevin Klyman, Christopher Klamm, Hailey Schoelkopf, Nikhil Singh, Manuel Cherep, Ahmad Mustafa Anis, An Dinh, Caroline Chitongo, Da Yin, Damien Sileo, Deividas Mataciunas, Diganta Misra, Emad Alghamdi, En...
2024
-
[52]
Nils Lukas, Edward Jiang, Xinda Li, and Florian Kerschbaum. 2022. SoK: How Robust is Image Classification Deep Neural Network Watermarking?. In43rd IEEE Symposium on Security and Privacy, SP 2022. IEEE, 787–804
2022
-
[53]
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. 2024. LLM Dataset Inference: Did you train on my dataset?. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[54]
Pratyush Maini, Mohammad Yaghini, and Nicolas Papernot. 2021. Dataset Infer- ence: Ownership Resolution in Machine Learning. InInternational Conference on Learning Representations
2021
-
[55]
Bertin Martens. 2018. The importance of data access regimes for artificial in- telligence and machine learning.JRC Digital Economy Working Paper 2018-09 (2018)
2018
-
[56]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and An- drew Y Ng. 2011. Reading digits in natural images with unsupervised feature learning.NIPS Workshop on Deep Learning and Unsupervised Feature Learning (2011)
2011
-
[57]
Google Play. 2024. Intellectual Property Policy. https://support.google.com/ googleplay/android-developer/answer/9888072
arXiv 2024
-
[58]
Girshick, Kaiming He, and Piotr Dollár
Ilija Radosavovic, Raj Prateek Kosaraju, Ross B. Girshick, Kaiming He, and Piotr Dollár. 2020. Designing Network Design Spaces. InProc. of IEEE/CVF CVPR
2020
-
[59]
Arpit Rajauria. 2020. pegasus paraphrase. https://huggingface.co/tuner007/ pegasus_paraphrase
2020
-
[60]
Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid, and Hervé Jégou. 2020. Radioactive data: tracing through training. InProceedings of the 37th International Conference on Machine Learning, ICML 2020 (Proceedings of Machine Learning Research, Vol. 119). PMLR, 8326–8335
2020
-
[61]
Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen
Mark Sandler, Andrew G. Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. MobileNetV2: Inverted Residuals and Linear Bottle- necks. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR
2018
-
[62]
Computer Vision Foundation / IEEE Computer Society, 4510–4520
-
[63]
Saxe, Pang Wei Koh, Zhenghao Chen, Maneesh Bhand, Bipin Suresh, and Andrew Y
Andrew M. Saxe, Pang Wei Koh, Zhenghao Chen, Maneesh Bhand, Bipin Suresh, and Andrew Y. Ng. 2011. On Random Weights and Unsupervised Feature Learn- ing. InProceedings of the 28th International Conference on Machine Learning, ICML 2011. Omnipress, 1089–1096
2011
-
[64]
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. AI models collapse when trained on recursively generated data.Nature631, 8022 (2024), 755–759
2024
-
[65]
Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional net- works for large-scale image recognition.arXiv preprint arXiv:1409.1556(2014)
Pith/arXiv arXiv 2014
-
[66]
Sriperumbudur, Arthur Gretton, Kenji Fukumizu, Bernhard Schölkopf, and Gert R
Bharath K. Sriperumbudur, Arthur Gretton, Kenji Fukumizu, Bernhard Schölkopf, and Gert R. G. Lanckriet. 2010. Hilbert Space Embeddings and Metrics on Probability Measures.J. Mach. Learn. Res.11 (2010), 1517–1561
2010
-
[67]
Mingxing Tan and Quoc V. Le. 2021. EfficientNetV2: Smaller Models and Faster Training. InProceedings of the 38th International Conference on Machine Learning, ICML 2021 (Proceedings of Machine Learning Research, Vol. 139). PMLR, 10096– 10106
2021
-
[68]
Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Well- read students learn better: The impact of student initialization on knowledge distillation.arXiv preprint arXiv:1908.08962(2019)
arXiv 2019
-
[69]
Hadas Unger, CHERGUELAINE Ayoub, and BOUBEKRI Faycal. 2023. CNN News Articles from 2011 to 2022. https://huggingface.co/datasets/AyoubChLin/CNN_ News_Articles_2011-2022
2023
-
[70]
James Vincent. 2023. Meta’s powerful AI language model has leaked online. https://www.theverge.com/2023/3/8/23629362/meta-ai-language- modelllama-leak-online-misuse
2023
-
[71]
Maxim Kuznetsov Vladimir Vorobev. 2023. A paraphrasing model based on ChatGPT paraphrases. https://huggingface.co/humarin/chatgpt_paraphraser_ on_T5_base
2023
-
[72]
Shuo Wang, Sharif Abuadbba, Sidharth Agarwal, Kristen Moore, Ruoxi Sun, Minhui Xue, Surya Nepal, Seyit Camtepe, and Salil Kanhere. 2022. PublicCheck: Public Integrity Verification for Services of Run-time Deep Models. In2023 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 1239–1256
2022
-
[73]
Yifei Wang, Jizhe Zhang, and Yisen Wang. 2024. Do Generated Data Always Help Contrastive Learning?. InThe Twelfth International Conference on Learning Representations
2024
-
[74]
Yifan Yan, Xudong Pan, Mi Zhang, and Min Yang. 2023. Rethinking White-Box Watermarks on Deep Learning Models under Neural Structural Obfuscation. In 32nd USENIX Security Symposium, USENIX Security 2023. USENIX Association, 2347–2364. 15 Tian Dong∗, Yan Meng∗, Shaofeng Li †, Guoxing Chen ∗, Yuling Chen‡, Zhen Liu ∗, Haojin Zhu ∗, and Hao Chen §
2023
-
[75]
Ze Yang, Can Xu, Wei Wu, and Zhoujun Li. 2019. Read, Attend and Comment: A Deep Architecture for Automatic News Comment Generation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP
2019
-
[76]
Association for Computational Linguistics, 5076–5088
-
[77]
Yuxia Zhan, Yan Meng, Yichang Xiong Lu Zhou, Xiaokuan Zhang, Lichuan Ma, Guoxing Chen, Qingqi Pei, and Haojin Zhu. 2024. VPVet: Vetting Privacy Policies of Virtual Reality Apps. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, 2024. ACM
2024
-
[78]
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J. Liu. 2020. PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020 (Proceedings of Machine Learning Research, Vol. 119). PMLR, 11328–11339
2020
-
[79]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang
-
[80]
In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018. Computer Vision Foundation / IEEE Computer Society, 586–595
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.