Atomistic Language Models Understand and Generate Materials
Pith reviewed 2026-06-26 14:53 UTC · model grok-4.3
The pith
Atomistic Language Models map language embeddings continuously into diffusion space to generate and optimize crystals from text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
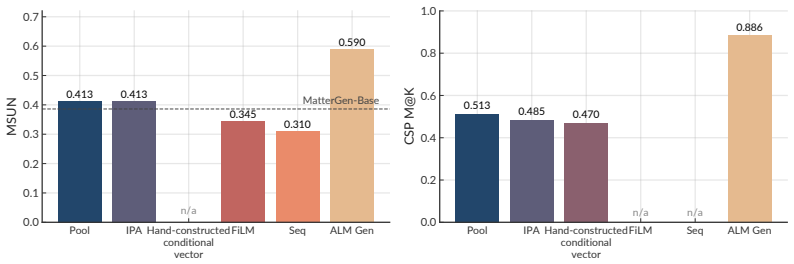
By unifying a pretrained atomistic encoder, large language model, and denoising diffusion model through purely continuous projectors and staged training, ALMs achieve state-of-the-art results on crystal structure prediction and de novo generation. ALMs are enabled by a continuous bridge that maps language model embeddings directly into the steering space of atomistic diffusion, and are assisted by Text-to-Crystal Feynman-Kac (T2C-FK), a particle-based sampler that scores partial denoising trajectories to enforce stoichiometric targets at inference time.
What carries the argument
The continuous bridge that maps language model embeddings directly into the steering space of atomistic diffusion, together with staged training of the unified components.
If this is right
- ALMs can take 3D atom coordinates or natural-language prompts as input and output optimized crystal structures.
- The Text-to-Crystal Feynman-Kac sampler enforces exact stoichiometry during the denoising process at inference time.
- A new benchmark, ALM Bench, provides standardized evaluation for text-conditioned crystal generation and optimization tasks.
- The architecture supports native multimodality without fine-tuning the language model on textual encodings of structures.
Where Pith is reading between the lines
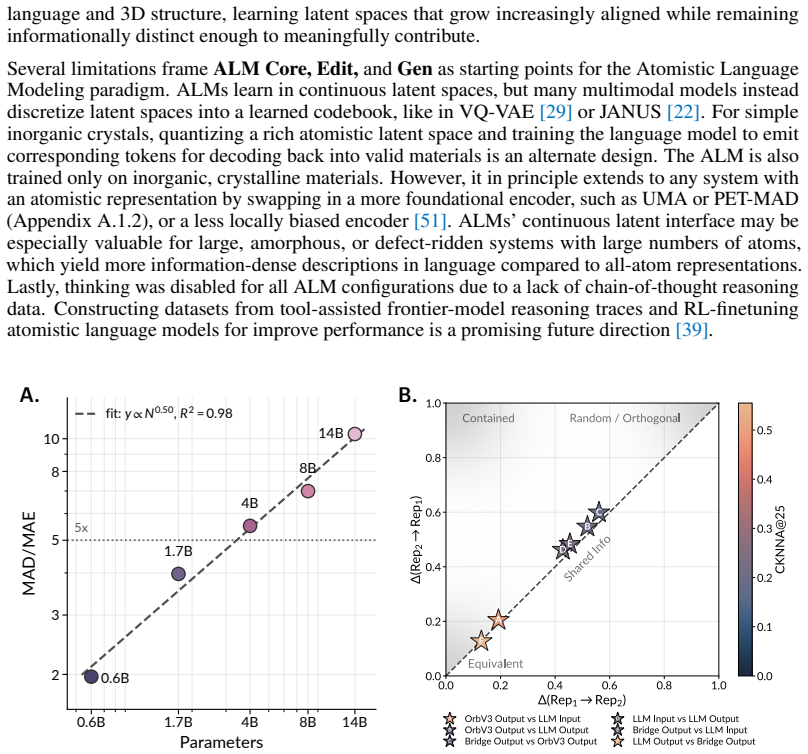
- If the continuous projectors generalize, the same bridging technique could connect language models to other continuous generative models beyond diffusion, such as flow-matching frameworks for molecules.
- Success on crystal tasks suggests the method might extend to non-periodic systems like molecules or surfaces once equivalent atomistic encoders are swapped in.
- The staged training schedule implies that freezing the atomistic encoder early prevents catastrophic forgetting of structural priors when the language component is added.
Load-bearing premise
Mapping language-model embeddings directly into the steering space of atomistic diffusion via continuous projectors preserves enough atomistic detail to beat prior separate-tool or lossy-text methods without creating new interface failures.
What would settle it
A head-to-head test on the ALM Bench where text-prompted structures generated by the unified ALM model show lower success rates or worse property matches than an equivalent pipeline that keeps the language model and diffusion model as separate tools.
Figures
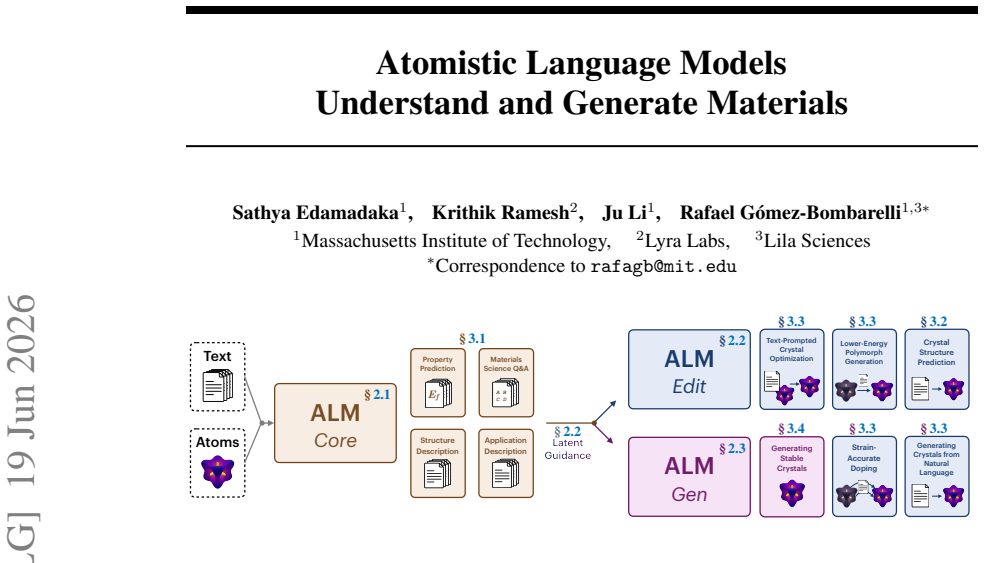
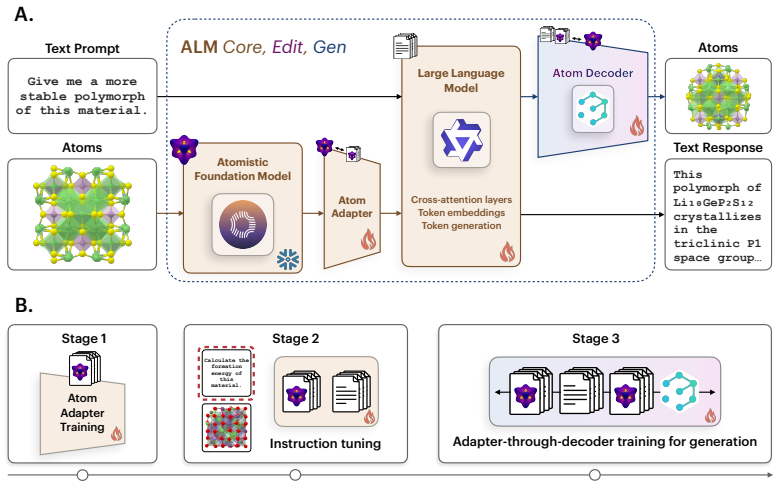


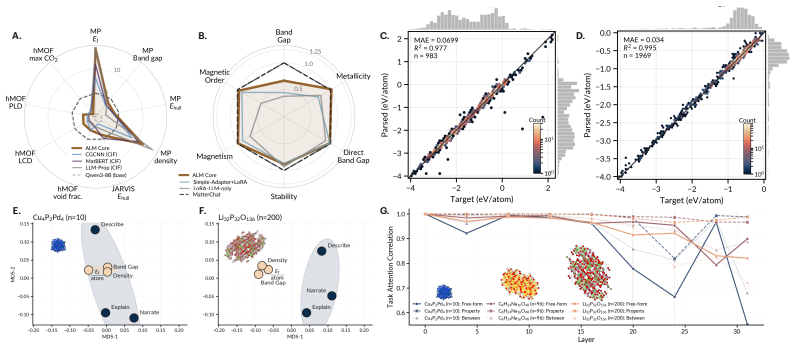
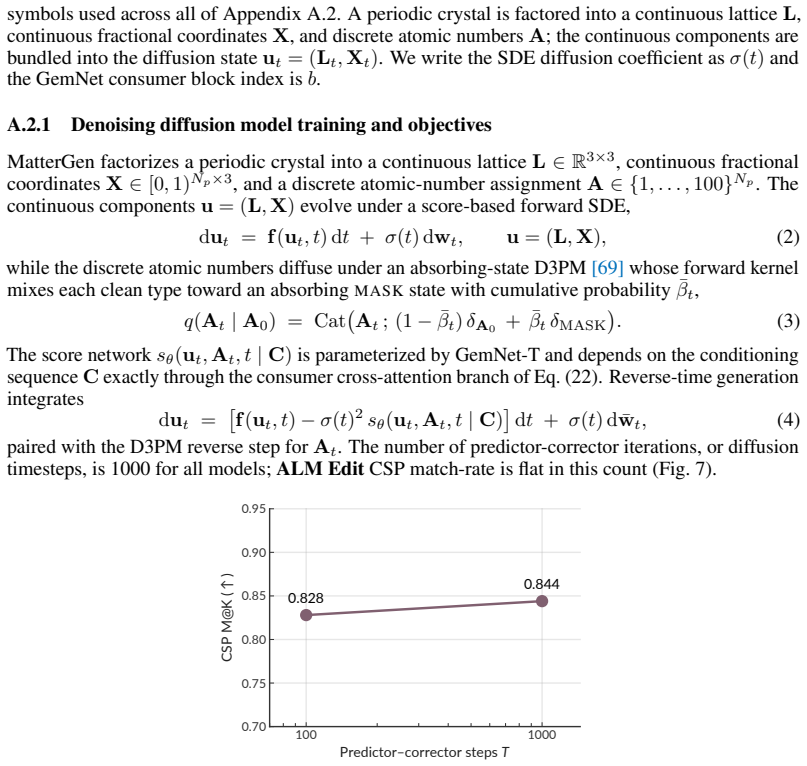
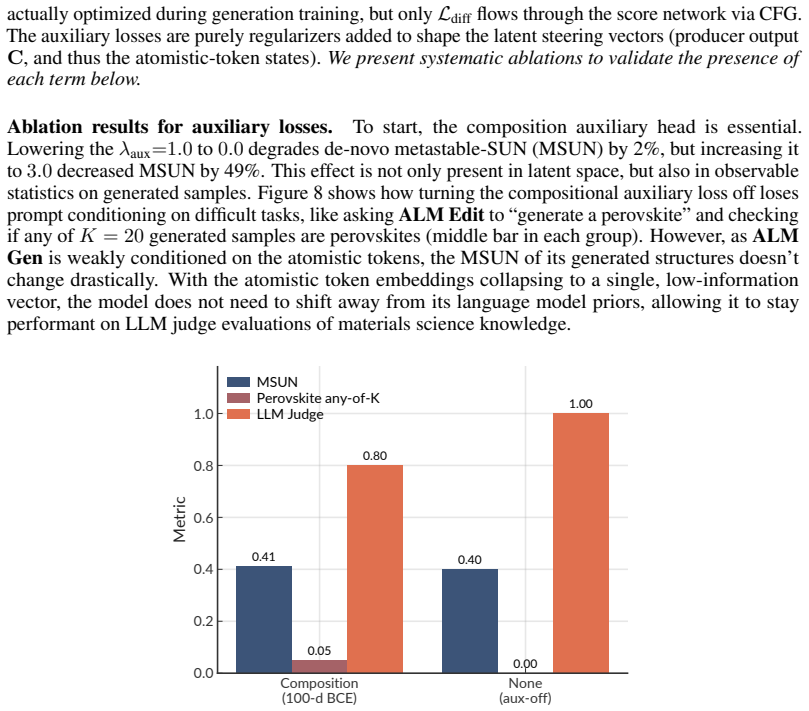
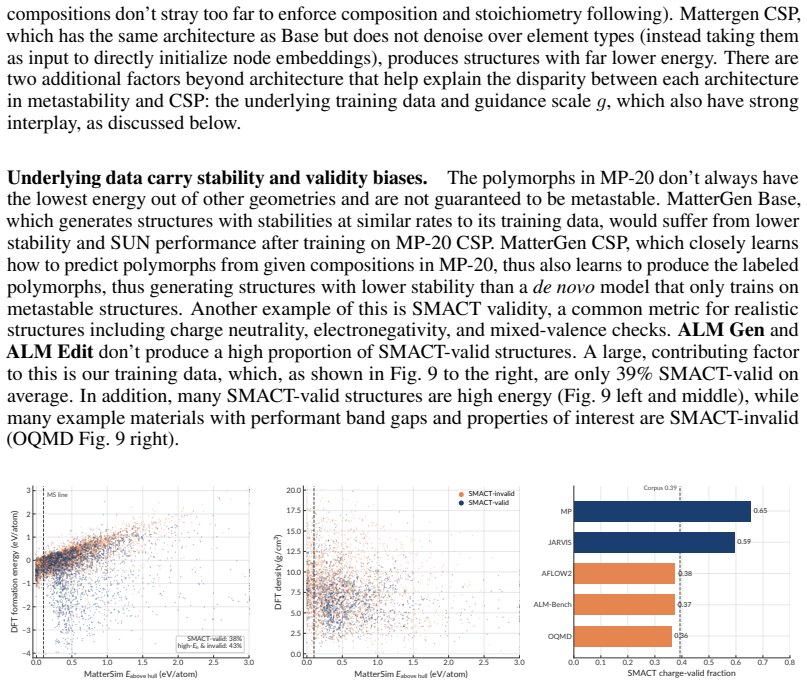
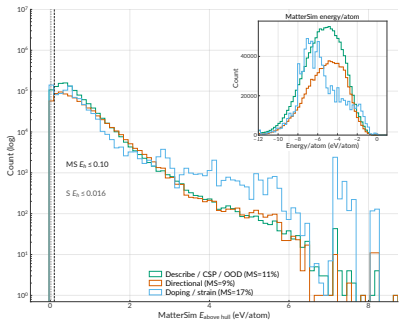
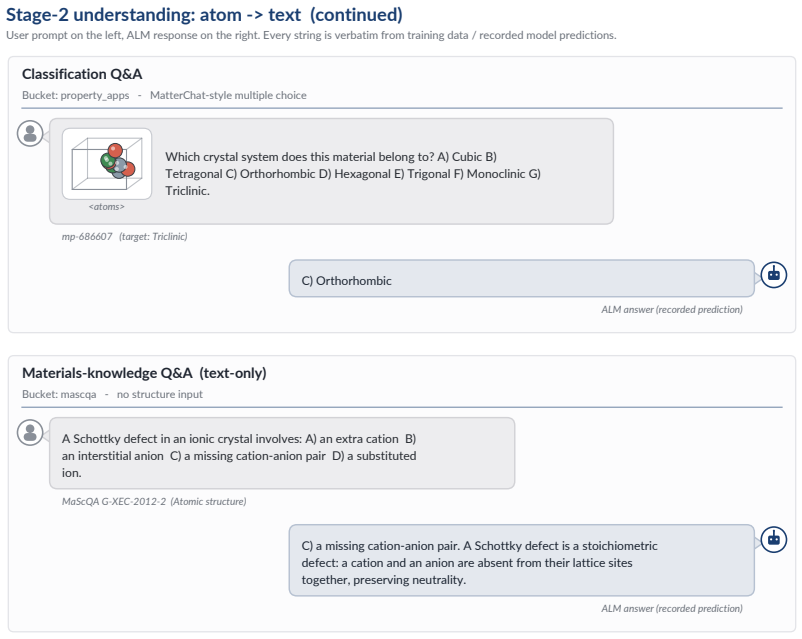
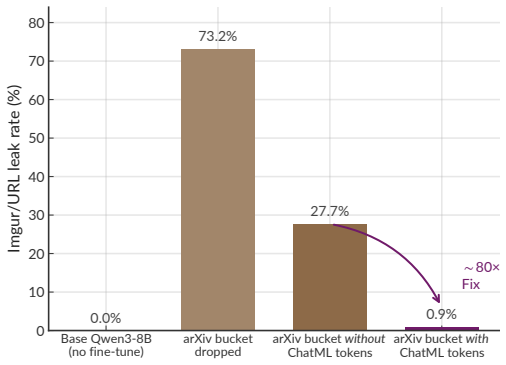
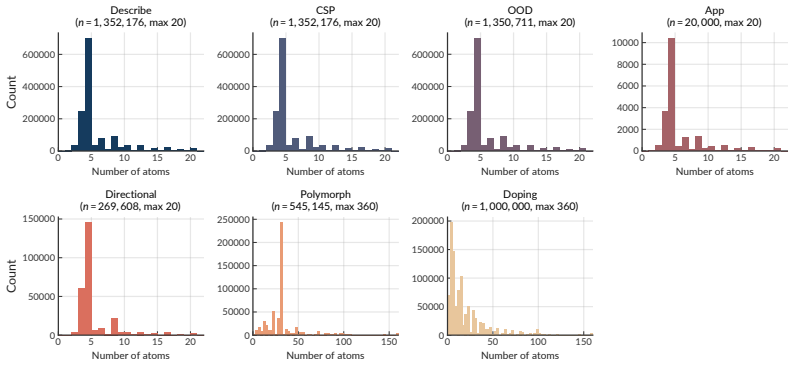
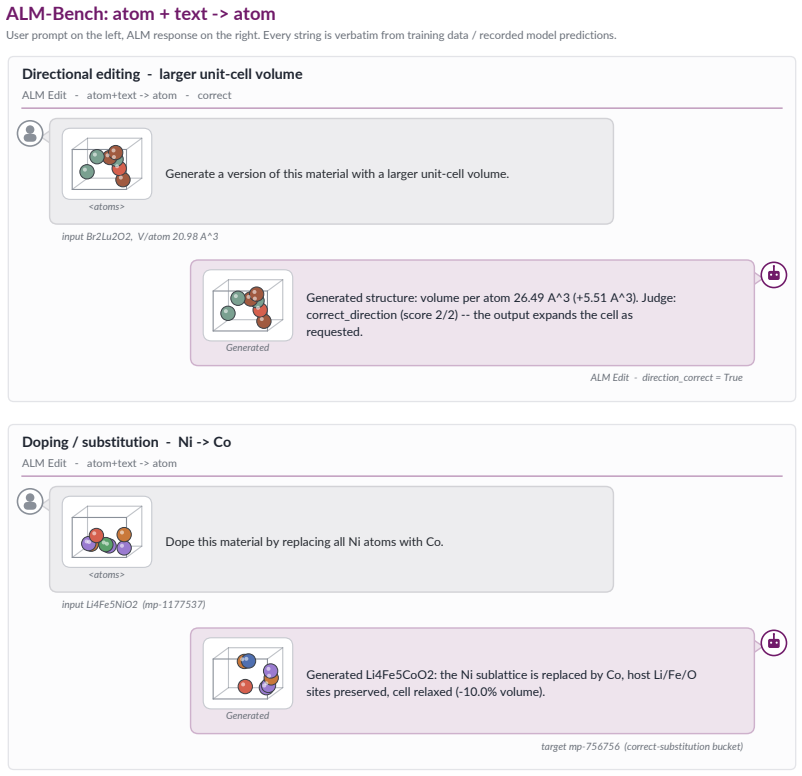

read the original abstract
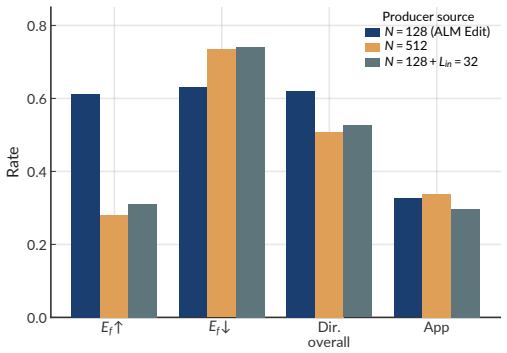
Atomistic structure and natural language have long been modeled separately, with language models either calling atomistic models as tools or being fine-tuned on lossy textual encodings that discard atomistic information. We introduce Atomistic Language Models (ALMs) to pursue native multimodality, in which a single language backbone understands atomistic structures, generates materials from natural language, and optimizes crystal structures as instructed by text. By unifying a pretrained atomistic encoder, large language model, and denoising diffusion model through purely continuous projectors and staged training, ALMs achieve state-of-the-art results on crystal structure prediction and de novo generation. ALMs are enabled by a continuous bridge that maps language model embeddings directly into the steering space of atomistic diffusion, and are assisted by Text-to-Crystal Feynman-Kac (T2C-FK), a particle-based sampler that scores partial denoising trajectories to enforce stoichiometric targets at inference time. To evaluate the ability of ALMs to optimize and generate materials from natural-language prompts and 3D atom-coordinate inputs, we introduce ALM Bench, the first benchmark for text-conditioned crystal generation and optimization. Code, training data, and model weights will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Atomistic Language Models (ALMs) that integrate a pretrained atomistic encoder, a large language model, and a denoising diffusion model using purely continuous projectors and staged training. This enables the model to understand atomistic structures from 3D inputs, generate materials from natural language prompts, and optimize crystal structures as instructed by text. The authors claim state-of-the-art results on crystal structure prediction and de novo generation, introduce the Text-to-Crystal Feynman-Kac (T2C-FK) sampler for enforcing stoichiometric targets, and propose the ALM Bench benchmark for evaluating text-conditioned crystal generation and optimization.
Significance. If the results hold and the continuous bridge preserves atomistic information effectively without introducing interface failure modes, this work could represent a significant advance in creating native multimodal models for materials science, moving beyond tool-calling or lossy text encodings. The introduction of a new benchmark and the planned release of code and models would contribute to reproducibility and further research in the field.
major comments (1)
- [Abstract] Abstract: The abstract asserts state-of-the-art results on crystal structure prediction and de novo generation but provides no quantitative metrics, baselines, error bars, or dataset details. This absence makes it impossible to evaluate whether the central claim is supported by the data or experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and will revise the abstract accordingly to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts state-of-the-art results on crystal structure prediction and de novo generation but provides no quantitative metrics, baselines, error bars, or dataset details. This absence makes it impossible to evaluate whether the central claim is supported by the data or experiments.
Authors: We agree that the abstract should include key quantitative results to substantiate the SOTA claims. The full manuscript reports these metrics (including baselines, error bars, and dataset details) in the Experiments section, but we acknowledge the abstract must be self-contained. In the revision we will add concise quantitative highlights, such as the specific performance gains on crystal structure prediction and de novo generation tasks, along with brief dataset references. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description outline an architecture that unifies pretrained components via continuous projectors and staged training, with a new sampler (T2C-FK) and benchmark (ALM Bench). No equations, parameter-fitting steps presented as predictions, or load-bearing self-citations are supplied that would allow any reduction of a claimed result to its own inputs by construction. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
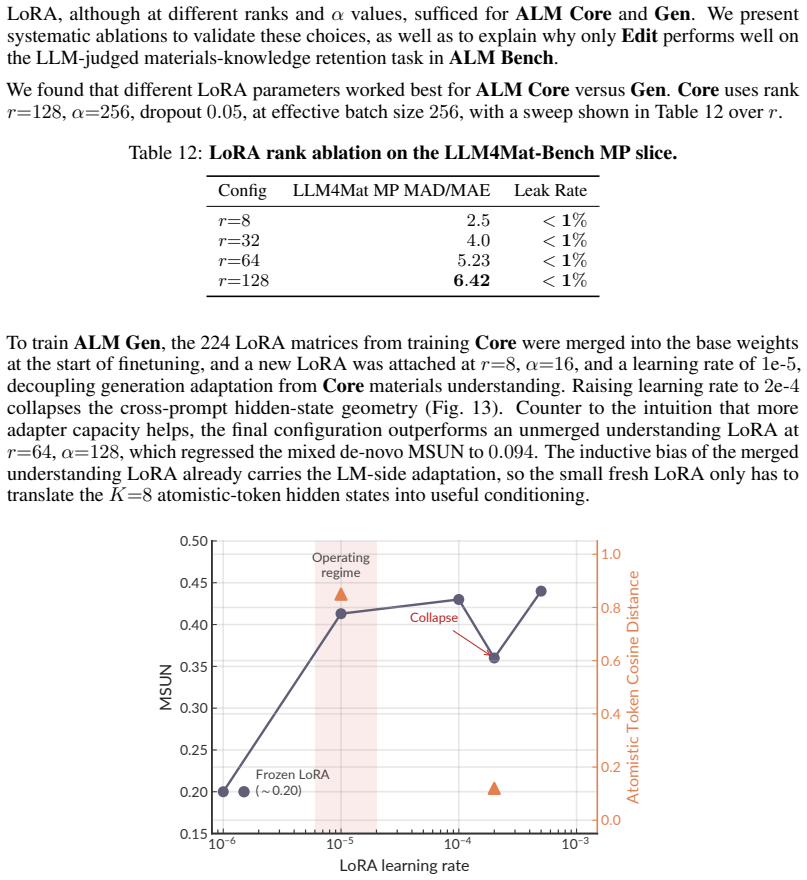
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wood, Misko Dzamba, Xiang Fu, Meng Gao, Muhammed Shuaibi, Luis Barroso-Luque, Kareem Abdelmaqsoud, Vahe Gharakhanyan, John R
Brandon M. Wood, Misko Dzamba, Xiang Fu, Meng Gao, Muhammed Shuaibi, Luis Barroso-Luque, Kareem Abdelmaqsoud, Vahe Gharakhanyan, John R. Kitchin, Daniel S. Levine, Kyle Michel, Anuroop Sriram, Taco Cohen, Abhishek Das, Ammar Rizvi, Sushree Jagriti Sahoo, Zachary W. Ulissi, and C. Lawrence Zitnick. Uma: A family of universal models for atoms, 2026
2026
-
[2]
Ilyes Batatia, Philipp Benner, Yuan Chiang, Alin M. Elena, Dávid P. Kovács, Janosh Riebesell, Xavier R. Advincula, Mark Asta, Matthew Avaylon, William J. Baldwin, Fabian Berger, Noam Bernstein, Arghya Bhowmik, Filippo Bigi, Samuel M. Blau, Vlad C ˘arare, Michele Ceriotti, Sanggyu Chong, James P. Darby, Sandip De, Flaviano Della Pia, V olker L. Deringer, R...
Pith/arXiv arXiv 2025
-
[3]
Orb-v3: atomistic simulation at scale, 2025
Benjamin Rhodes, Sander Vandenhaute, Vaidotas Šimkus, James Gin, Jonathan Godwin, Tim Duignan, and Mark Neumann. Orb-v3: atomistic simulation at scale, 2025
2025
-
[4]
Antunes, Keith T
Luis M. Antunes, Keith T. Butler, and Ricardo Grau-Crespo. Crystal structure generation with autoregressive large language modeling.Nature Communications, 15(1):10570, December 2024
2024
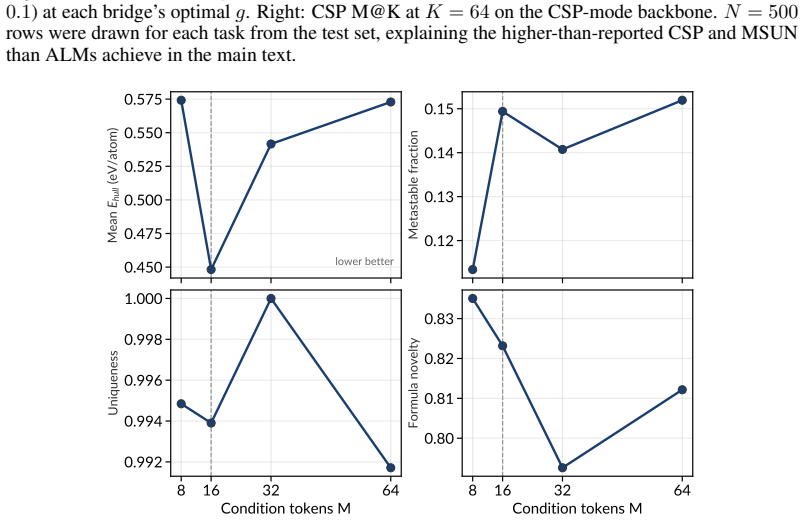
-
[5]
Plaid++: A preference aligned language model for targeted inorganic materials design, 2026
Andy Xu, Rohan Desai, Larry Wang, Ethan Ritz, and Gabriel Hope. Plaid++: A preference aligned language model for targeted inorganic materials design, 2026
2026
-
[6]
Lawrence Zitnick, and Zachary Ulissi
Nate Gruver, Anuroop Sriram, Andrea Madotto, Andrew Gordon Wilson, C. Lawrence Zitnick, and Zachary Ulissi. Fine-tuned language models generate stable inorganic materials as text. In International Conference on Learning Representations (ICLR), 2024. arXiv:2402.04379. 12
arXiv 2024
-
[7]
Less can be more for predicting properties with large language models
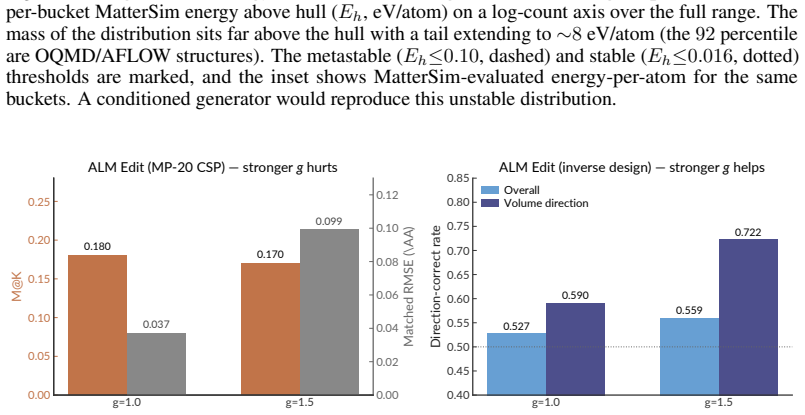
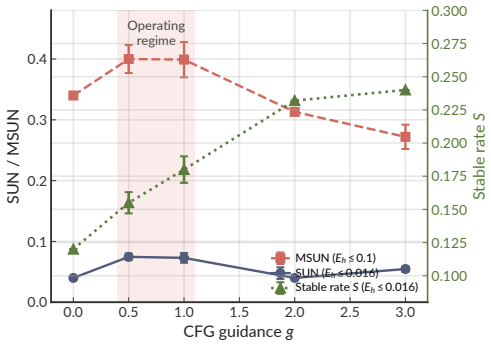
Nawaf Alampara, Santiago Miret, and Kevin Maik Jablonka. Mattext: Do language models need more than text & scale for materials modeling?, 2024. arXiv:2406.17295; v3 (2025) retitled "Less can be more for predicting properties with large language models"
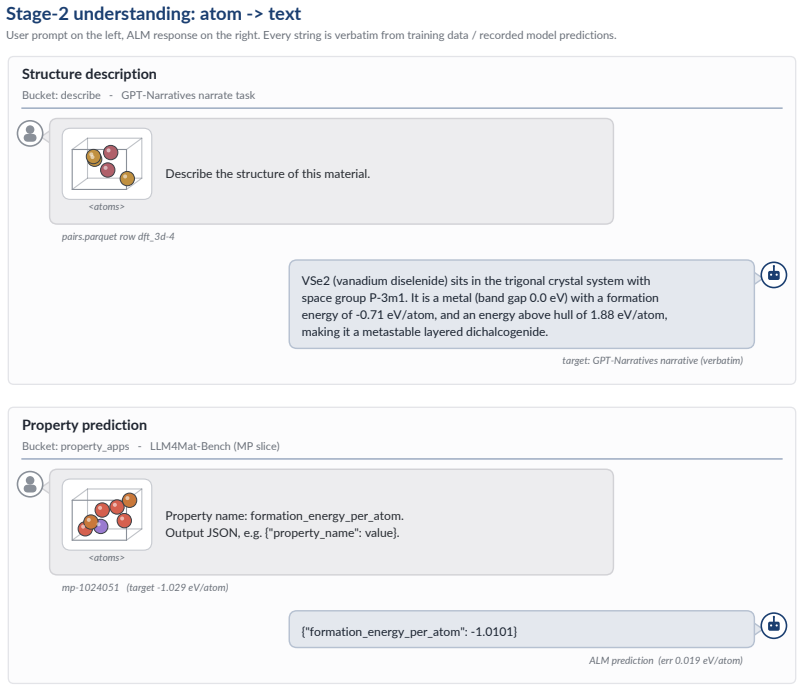
arXiv 2024
-
[8]
Tanishq Gupta, Mohd Zaki, N. M. Anoop Krishnan, and Mausam. Matscibert: A materials domain language model for text mining and information extraction.npj Computational Materials, 8(1):102, 2022. arXiv:2109.15290
arXiv 2022
-
[9]
Universally converging representations of matter across scientific foundation models, 2025
Sathya Edamadaka, Soojung Yang, Ju Li, and Rafael Gómez-Bombarelli. Universally converging representations of matter across scientific foundation models, 2025
2025
-
[10]
Keisuke Ozawa, Teppei Suzuki, Shunsuke Tonogai, and Tomoya Itakura. Graph-text contrastive learning of inorganic crystal structure toward a foundation model of inorganic materials.Science and Technology of Advanced Materials: Methods, 4(1):2406219, December 2024
2024
-
[11]
Towards end-to-end automation of ai research.Nature, 651(8107):914–919, March 2026
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of ai research.Nature, 651(8107):914–919, March 2026
2026
-
[12]
Crystal diffusion variational autoencoder for periodic material generation
Tian Xie, Xiang Fu, Octavian-Eugen Ganea, Regina Barzilay, and Tommi Jaakkola. Crystal diffusion variational autoencoder for periodic material generation. InInternational Conference on Learning Representations (ICLR), 2022. arXiv:2110.06197
arXiv 2022
-
[13]
Crystal structure prediction by joint equivariant diffusion
Rui Jiao, Wenbing Huang, Peijia Lin, Jiaqi Han, Pin Chen, Yutong Lu, and Yang Liu. Crystal structure prediction by joint equivariant diffusion. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. arXiv:2309.04475
arXiv 2023
-
[14]
A generative model for inorganic materials design.Nature, 639(8055):624–632, March 2025
Claudio Zeni, Robert Pinsler, Daniel Zügner, Andrew Fowler, Matthew Horton, Xiang Fu, Zilong Wang, Aliaksandra Shysheya, Jonathan Crabbé, Shoko Ueda, Roberto Sordillo, Lixin Sun, Jake Smith, Bichlien Nguyen, Hannes Schulz, Sarah Lewis, Chin-Wei Huang, Ziheng Lu, Yichi Zhou, Han Yang, Hongxia Hao, Jielan Li, Chunlei Yang, Wenjie Li, Ryota Tomioka, and Tian...
2025
-
[15]
Gaunt, Brendan McMorrow, Danilo J
Sherry Yang, Simon Batzner, Ruiqi Gao, Muratahan Aykol, Alexander L. Gaunt, Brendan McMorrow, Danilo J. Rezende, Dale Schuurmans, Igor Mordatch, and Ekin D. Cubuk. Generative hierarchical materials search. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024. arXiv:2409.06762
arXiv 2024
-
[16]
Musgrave III, Anirban Chandra, Abhirup Patra, Detlef Hohl, Connor W
Bowen Deng, Bohan Li, Matthew Cox, Hoje Chun, Juno Nam, Artur Lyssenko, Sathya Edamadaka, Jurgis Ruza, Xiaochen Du, Nofit Segal, Jesus Diaz Sanchez, Mingrou Xie, Ty Perez, Yu Yao, Miguel Steiner, Sauradeep Majumdar, Charles B. Musgrave III, Anirban Chandra, Abhirup Patra, Detlef Hohl, Connor W. Coley, Ju Li, and Rafael Gómez-Bombarelli. Harnessing atomist...
2026
-
[17]
Lu, Thomas Christensen, and Marin Soljaˇci´c
Viggo Moro, Charlotte Loh, Rumen Dangovski, Ali Ghorashi, Andrew Ma, Zhuo Chen, Samuel Kim, Peter Y . Lu, Thomas Christensen, and Marin Soljaˇci´c. Multimodal foundation models for material property prediction and discovery.Newton, 1(1):100016, March 2025
2025
-
[18]
Yuta Suzuki, Tatsunori Taniai, Ryo Igarashi, Kotaro Saito, Naoya Chiba, Yoshitaka Ushiku, and Kanta Ono. Bridging text and crystal structures: Literature-driven contrastive learning for materials science.Machine Learning: Science and Technology, 6(3):035006, September 2025. arXiv:2501.12919
arXiv 2025
-
[19]
Mahoney, Andy Nonaka, and Zhi Jackie Yao
Yingheng Tang, Wenbin Xu, Jie Cao, Weilu Gao, Steven Farrell, Benjamin Erichson, Michael W. Mahoney, Andy Nonaka, and Zhi Jackie Yao. A multimodal large language model for materials science.Nature Machine Intelligence, 8(4):588–601, April 2026
2026
-
[20]
Cooper, and Yejin Choi
Jiyu Cui, Fang Wu, Haokai Zhao, Minggao Feng, Xenophon Evangelopoulos, Andrew I. Cooper, and Yejin Choi. L2m3of: A large language multimodal model for metal-organic frameworks, 2025. 13
2025
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. arXiv:2304.08485
Pith/arXiv arXiv 2023
-
[22]
Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025
2025
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings of Machine Learning Research, pages 19730–19742. PMLR, 2023. arXiv:...
Pith/arXiv arXiv 2023
-
[24]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[25]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022
2022
-
[26]
Llm4mat-bench: benchmarking large language models for materials property prediction
Andre Niyongabo Rubungo, Kangming Li, Jason Hattrick-Simpers, and Adji Bousso Dieng. Llm4mat-bench: benchmarking large language models for materials property prediction. Machine Learning: Science and Technology, 6(2):020501, 2025. arXiv:2411.00177
arXiv 2025
-
[27]
Gleason, Ali Ramlaoui, Andy Xu, Georgia Channing, Daniel Levy, Clémentine Fourrier, Nikita Kazeev, Chaitanya K
Siddharth Betala, Samuel P. Gleason, Ali Ramlaoui, Andy Xu, Georgia Channing, Daniel Levy, Clémentine Fourrier, Nikita Kazeev, Chaitanya K. Joshi, Sékou-Oumar Kaba, Félix Therrien, Alex Hernandez-Garcia, Rocío Mercado, N. M. Anoop Krishnan, and Alexandre Duval. Lemat-genbench: A unified evaluation framework for crystal generative models, 2026
2026
-
[28]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski,...
Pith/arXiv arXiv 2022
-
[29]
Neural discrete representation learning
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6306–6315, 2017. arXiv:1711.00937
Pith/arXiv arXiv 2017
-
[30]
Atomic cluster expansion for accurate and transferable interatomic potentials
Ralf Drautz. Atomic cluster expansion for accurate and transferable interatomic potentials. Physical Review B, 99(1):014104, January 2019
2019
-
[31]
Ganose and Anubhav Jain
Alex M. Ganose and Anubhav Jain. Robocrystallographer: automated crystal structure text descriptions and analysis.MRS Communications, 9(3):874–881, September 2019
2019
-
[32]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. arXiv:2106.09685
Pith/arXiv arXiv 2022
-
[33]
Alexander H. Liu, Andy Ehrenberg, Andy Lo, Clément Denoix, Corentin Barreau, Guillaume Lample, Jean-Malo Delignon, Khyathi Raghavi Chandu, Patrick von Platen, Pavankumar Reddy Muddireddy, Sanchit Gandhi, Soham Ghosh, Srijan Mishra, Thomas Foubert, Abhinav Rastogi, Adam Yang, Albert Q. Jiang, Alexandre Sablayrolles, Amélie Héliou, Amélie Martin, Anmol 14 A...
2025
-
[34]
Luhuan Wu, Brian L. Trippe, Christian A. Naesseth, David M. Blei, and John P. Cunningham. Practical and asymptotically exact conditional sampling in diffusion models. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023, 2023. arXiv...
arXiv 2023
-
[35]
A general framework for inference-time scaling and steering of diffusion models
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025), PMLR 267, pages 55810–55827, 2025. arXiv:2501.06848
arXiv 2025
-
[36]
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, and Kristin A. Persson. Commentary: The materials project: A materials genome approach to accelerating materials innovation.APL Materials, 1(1):011002, 2013
2013
-
[37]
Schoenholz, Muratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk
Amil Merchant, Simon Batzner, Samuel S. Schoenholz, Muratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk. Scaling deep learning for materials discovery.Nature, 624(7990):80–85, December 2023
2023
-
[38]
1.5 million materials narratives generated by chatbots.Scientific Data, 11(1):1060, September 2024
Yang Jeong Park, Sung Eun Jerng, Sungroh Yoon, and Ju Li. 1.5 million materials narratives generated by chatbots.Scientific Data, 11(1):1060, September 2024
2024
-
[39]
Crystalreasoner: Reasoning and rl for property-conditioned crystal structure generation, 2026
Yuyang Wu, Stefano Falletta, Delia McGrath, and Sherry Yang. Crystalreasoner: Reasoning and rl for property-conditioned crystal structure generation, 2026
2026
-
[40]
Camel: Communicative agents for "mind" exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for "mind" exploration of large language model society. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023. arXiv:2303.17760
Pith/arXiv arXiv 2023
-
[41]
Garrity, Andrew C
Kamal Choudhary, Kevin F. Garrity, Andrew C. E. Reid, Brian DeCost, Adam J. Biacchi, Angela R. Hight Walker, Zachary Trautt, Jason Hattrick-Simpers, A. Gilad Kusne, Andrea Centrone, Albert Davydov, Jie Jiang, Ruth Pachter, Gowoon Cheon, Evan Reed, Ankit Agrawal, Xiaofeng Qian, Vinit Sharma, Houlong Zhuang, Sergei V . Kalinin, Bobby G. Sumpter, Ghanshyam P...
2020
-
[42]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling (COLM), 2024. arXiv:2311.12022. 15
Pith/arXiv arXiv 2024
-
[43]
Benjamin Kurt Miller, Ricky T. Q. Chen, Anuroop Sriram, and Brandon M. Wood. Flowmm: Generating materials with riemannian flow matching. InProceedings of the 41st International Conference on Machine Learning (ICML), pages 35664–35686, 2024. arXiv:2406.04713
arXiv 2024
-
[44]
Crystalflow: a flow-based generative model for crystalline materials
Xiaoshan Luo, Zhenyu Wang, Qingchang Wang, Xuechen Shao, Jian Lv, Lei Wang, Yanchao Wang, and Yanming Ma. Crystalflow: a flow-based generative model for crystalline materials. Nature Communications, 16(1):9267, 2025. arXiv:2412.11693
arXiv 2025
-
[45]
Philipp Höllmer, Thomas Egg, Maya M. Martirossyan, Eric Fuemmeler, Zeren Shui, Amit Gupta, Pawan Prakash, Adrian Roitberg, Mingjie Liu, George Karypis, Mark Transtrum, Richard G. Hennig, Ellad B. Tadmor, and Stefano Martiniani. Open materials generation with stochastic interpolants. InProceedings of the 42nd International Conference on Machine Learning (I...
arXiv 2025
-
[46]
Multimodal crystal flow: Any-to-any modality generation for unified crystal modeling, 2026
Kiyoung Seong, Sungsoo Ahn, Sehui Han, and Changyoung Park. Multimodal crystal flow: Any-to-any modality generation for unified crystal modeling, 2026
2026
-
[47]
Maya M. Martirossyan, Thomas Egg, Philipp Hoellmer, George Karypis, Mark Transtrum, Adrian Roitberg, Mingjie Liu, Richard G. Hennig, Ellad B. Tadmor, and Stefano Martiniani. All that structure matches does not glitter. InAdvances in Neural Information Processing Systems 39 (NeurIPS 2025) Datasets and Benchmarks Track, 2025. arXiv:2509.12178
arXiv 2025
-
[48]
Wyckoff transformer: Generation of symmetric crystals
Nikita Kazeev, Wei Nong, Ignat Romanov, Ruiming Zhu, Andrey Ustyuzhanin, Shuya Yamazaki, and Kedar Hippalgaonkar. Wyckoff transformer: Generation of symmetric crystals. In Proceedings of the 42nd International Conference on Machine Learning (ICML), pages 29495–29526, 2025. arXiv:2503.02407
arXiv 2025
-
[49]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models, 2022
2022
-
[50]
Ranking the information content of distance measures.PNAS Nexus, 1(2):pgac039, 05 2022
Aldo Glielmo, Claudio Zeni, Bingqing Cheng, Gábor Csányi, and Alessandro Laio. Ranking the information content of distance measures.PNAS Nexus, 1(2):pgac039, 05 2022
2022
-
[51]
Krishnapriyan
Tobias Kreiman, Yutong Bai, Fadi Atieh, Elizabeth Weaver, Eric Qu, and Aditi S. Krishnapriyan. Transformers discover molecular structure without graph priors, 2025
2025
-
[52]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, volume 235 ofProceedings of Machine Learning Research, pages 20617–20642. PMLR, 2024. arXiv:2405.07987
Pith/arXiv arXiv 2024
-
[53]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of Chemical Information and Computer Sciences, 28(1):31–36, February 1988
1988
-
[54]
Self-referencing embedded strings (selfies): A 100% robust molecular string representation
Mario Krenn, Florian Häse, AkshatKumar Nigam, Pascal Friederich, and Alán Aspuru-Guzik. Self-referencing embedded strings (selfies): A 100% robust molecular string representation. Machine Learning: Science and Technology, 1(4):045024, December 2020. arXiv:1905.13741
arXiv 2020
-
[55]
Shengchao Liu, Weili Nie, Chengpeng Wang, Jiarui Lu, Zhuoran Qiao, Ling Liu, Jian Tang, Chaowei Xiao, and Animashree Anandkumar. Multi-modal molecule structure–text model for text-based retrieval and editing.Nature Machine Intelligence, 5(12):1447–1457, 2023. arXiv:2212.10789
arXiv 2023
-
[56]
Llm-fusion: A novel multimodal fusion model for accelerated material discovery, 2025
Onur Boyar, Indra Priyadarsini, Seiji Takeda, and Lisa Hamada. Llm-fusion: A novel multimodal fusion model for accelerated material discovery, 2025
2025
-
[57]
Towards 3d molecule-text interpretation in language models
Sihang Li, Zhiyuan Liu, Yanchen Luo, Xiang Wang, Xiangnan He, Kenji Kawaguchi, Tat-Seng Chua, and Qi Tian. Towards 3d molecule-text interpretation in language models. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2401.13923. 16
arXiv 2024
-
[58]
Translation between molecules and natural language
Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. Translation between molecules and natural language. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 375–413, 2022. arXiv:2204.11817
arXiv 2022
-
[59]
A merged molecular representation learning for molecular properties prediction with a web-based service.Scientific Reports, 11(1):11028, May 2021
Hyunseob Kim, Jeongcheol Lee, Sunil Ahn, and Jongsuk Ruth Lee. A merged molecular representation learning for molecular properties prediction with a web-based service.Scientific Reports, 11(1):11028, May 2021
2021
-
[60]
Can large language models empower molecular property prediction?, 2023
Chen Qian, Huayi Tang, Zhirui Yang, Hong Liang, and Yong Liu. Can large language models empower molecular property prediction?, 2023
2023
-
[61]
Multimodal fusion with relational learning for molecular property prediction.Communications Chemistry, 8(1):200, July 2025
Zhengyang Zhou, Yunrui Li, Pengyu Hong, and Hao Xu. Multimodal fusion with relational learning for molecular property prediction.Communications Chemistry, 8(1):200, July 2025
2025
-
[62]
Rand, and Adji Bousso Dieng
Andre Niyongabo Rubungo, Craig Arnold, Barry P. Rand, and Adji Bousso Dieng. Llm-prop: predicting the properties of crystalline materials using large language models.npj Computational Materials, 11(1):186, June 2025
2025
-
[63]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat gans on image synthesis. InAdvances in Neural Information Processing Systems 34 (NeurIPS 2021), pages 8780–8794,
2021
-
[64]
Perception encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Daniel Li, Piotr Dollár, and Christoph Feichtenhofer. Perception encoder: The best visual embeddings are not at the output of the network. InAdvances in N...
Pith/arXiv arXiv 2025
-
[65]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296–26306, 2024. arXiv:2310.03744
Pith/arXiv arXiv 2024
-
[66]
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier J. Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, and João Carreira. Perceiver io: A general architecture for structured inputs & outputs. InInternational Conference on Lea...
Pith/arXiv arXiv 2022
-
[67]
Finite scalar quantization: Vq-vae made simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple. InInternational Conference on Learning Representations (ICLR), 2024. arXiv:2309.15505
Pith/arXiv arXiv 2024
-
[68]
Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models, 2023
2023
-
[69]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, pages 17981–17993, 2021. arXiv:2107.03006
arXiv 2021
-
[70]
Generating images with multimodal language models
Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov. Generating images with multimodal language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36,
-
[71]
Ms-diffusion: Multi-subject zero-shot image personalization with layout guidance
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi-subject zero-shot image personalization with layout guidance. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
- [72]
-
[73]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3813–3824, 2023. arXiv:2302.05543. 17
Pith/arXiv arXiv 2023
-
[74]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[75]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019. arXiv:1711.05101
Pith/arXiv arXiv 2019
-
[76]
Nian Liu, Nikita Kazeev, Stephen Gregory Dale, Artem Maevskiy, Yuwei Zeng, Ryoji Kubo, Pengru Huang, Thomas Laurent, Yann LeCun, Kostya S. Novoselov, and Xavier Bresson. Crys-jepa: Accelerating crystal discovery via embedding screening and generative refinement, 2026. 18 Appendix A Architecture design choices and ablations . . . . . . . . . . . . . . . . ...
arXiv 2026
-
[77]
n=Kgenerations per row
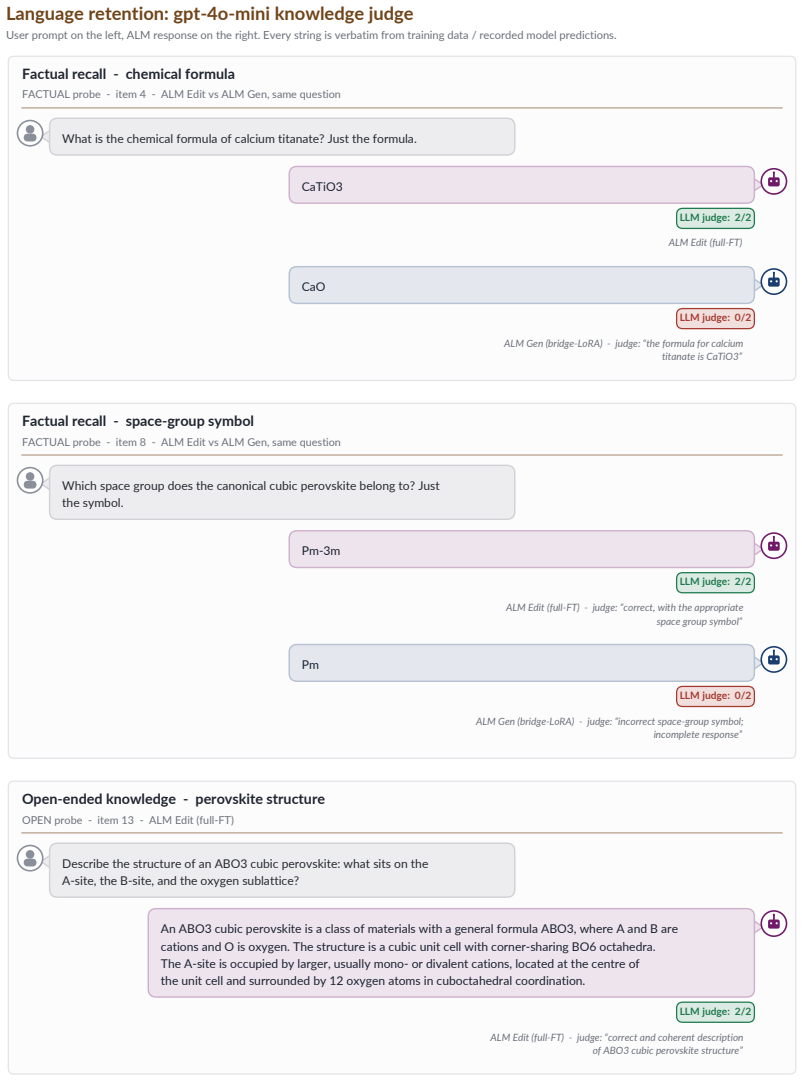
Alongside the mean score (normalized to [0,1] in Table 1) we track an independent degeneracy diagnostic,loop-rate: the fraction of answers whose most-frequent 4-gram repeats ≥4 times. Figures 28 and 29 demonstrate examples of the LLM judge. D.2 Crystal structure prediction metric details This section fixes the exact, reproducible definitions of the CSP me...
2020
-
[78]
partially correct; second oxide is incomplete and lacks an application
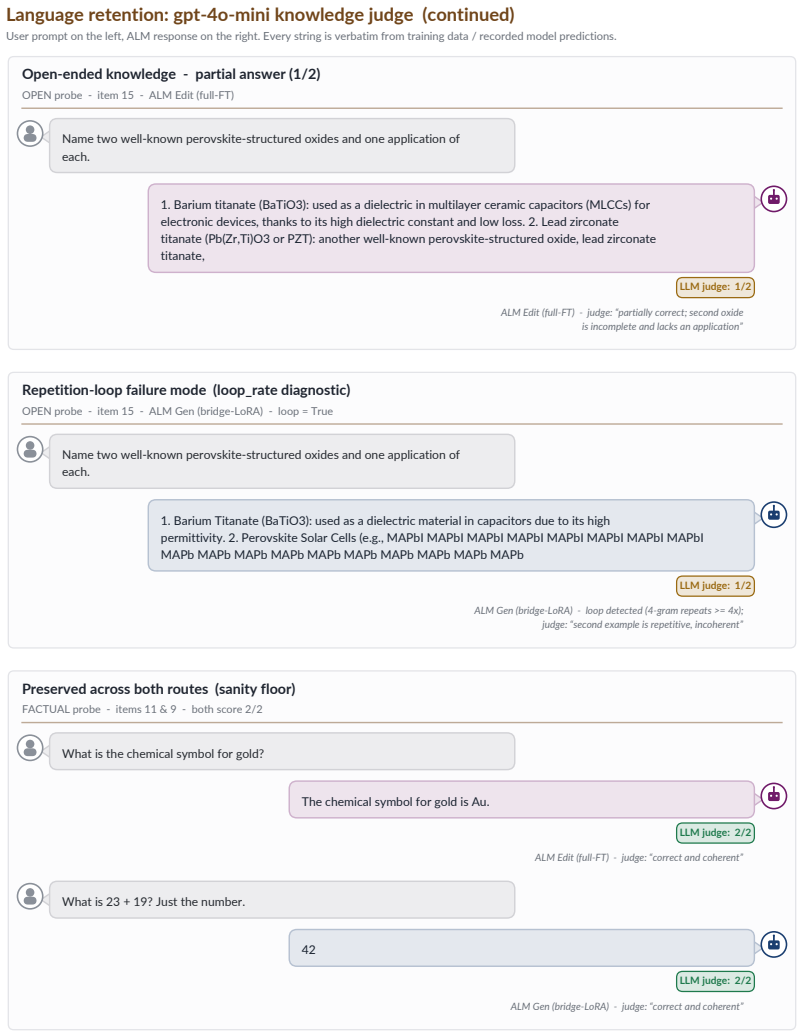
Barium titanate (BaTiO3): used as a dielectric in multilayer ceramic capacitors (MLCCs) for electronic devices, thanks to its high dielectric constant and low loss. 2. Lead zirconate titanate (Pb(Zr,Ti)O3 or PZT): another well-known perovskite-structured oxide, lead zirconate titanate, ALM Edit (full-FT) - judge: “partially correct; second oxide is incomp...
-
[79]
second example is repetitive, incoherent
Barium Titanate (BaTiO3): used as a dielectric material in capacitors due to its high permittivity. 2. Perovskite Solar Cells (e.g., MAPbI MAPbI MAPbI MAPbI MAPbI MAPbI MAPbI MAPbI MAPb MAPb MAPb MAPb MAPb MAPb MAPb MAPb MAPb MAPb ALM Gen (bridge-LoRA) - loop detected (4-gram repeats >= 4x); judge: “second example is repetitive, incoherent” LLM judge: 1/2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.