Post-Training Speech Enhancement Language Models with Perceptual Rewards
Pith reviewed 2026-06-26 14:34 UTC · model grok-4.3
The pith
Post-training autoregressive speech enhancement models with a composite reward from DNSMOS, WER, and UTMOS reaches state-of-the-art on DNS2020.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
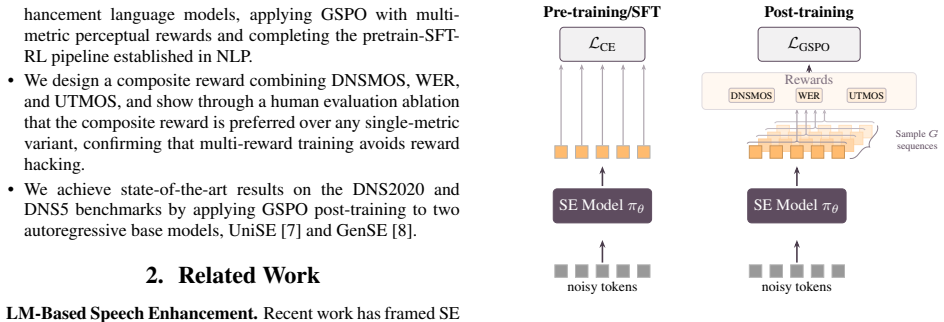
Speech enhancement language models achieve strong results when trained on discrete audio tokens, but their optimization relies on token-level cross-entropy rather than the perceptual metrics used for evaluation. We introduce a post-training stage for autoregressive speech enhancement language models using Group Sequence Policy Optimization (GSPO) with multi-metric perceptual rewards. Our method directly optimizes non-differentiable quality metrics (DNSMOS, WER, and UTMOS) as reward signals, without learned surrogates or offline preference pairs. Applied to two autoregressive base models, UniSE and GenSE, our approach achieves state-of-the-art results on the DNS2020 benchmark. A human evaluat
What carries the argument
Group Sequence Policy Optimization (GSPO) with a composite reward signal built from DNSMOS, WER, and UTMOS, which directly steers token generation toward higher perceptual scores during post-training.
If this is right
- The post-trained UniSE and GenSE models reach state-of-the-art results on the DNS2020 benchmark.
- Human listeners prefer outputs from the composite multi-metric reward over any single-metric training variant.
- Multi-reward optimization prevents the reward hacking that appears when training uses only one perceptual metric.
Where Pith is reading between the lines
- The same post-training recipe could be tested on other autoregressive audio tasks that already use token-based language models.
- Adding a fourth independent metric to the reward composite would provide a direct check on whether the current three-metric set already covers the main failure modes.
- The observed avoidance of reward hacking suggests the method may stabilize training in other settings where evaluation uses multiple non-differentiable scores.
Load-bearing premise
The three metrics DNSMOS, WER, and UTMOS together form a sufficient and unbiased proxy for overall human-perceived speech quality.
What would settle it
A new human listening test on the DNS2020 test set in which listeners rate outputs from the post-trained models lower than single-metric or baseline versions on any quality dimension.
Figures

read the original abstract
Speech enhancement language models achieve strong results when trained on discrete audio tokens, but their optimization relies on token-level cross-entropy rather than the perceptual metrics used for evaluation. We introduce a post-training stage for autoregressive speech enhancement language models using Group Sequence Policy Optimization (GSPO) with multi-metric perceptual rewards. Our method directly optimizes non-differentiable quality metrics (DNSMOS, WER, and UTMOS) as reward signals, without learned surrogates or offline preference pairs. Applied to two autoregressive base models, UniSE and GenSE, our approach achieves state-of-the-art results on the DNS2020 benchmark. A human evaluation ablation further shows that the composite multi-metric reward is preferred over any single-metric variant, confirming that multi-reward optimization avoids the reward hacking observed with single-metric training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a post-training stage for autoregressive speech enhancement language models (applied to UniSE and GenSE) that uses Group Sequence Policy Optimization (GSPO) to directly optimize a composite reward formed from the non-differentiable perceptual metrics DNSMOS, WER, and UTMOS. It claims this yields state-of-the-art results on the DNS2020 benchmark and that a human-evaluation ablation demonstrates the composite reward is preferred over any single-metric variant, thereby avoiding the reward hacking seen with single-metric training.
Significance. If the experimental claims are substantiated with full details, the work would be significant for speech enhancement language models: it shows how to optimize directly for established perceptual metrics without learned surrogates or offline preference data, and the multi-metric human ablation supplies concrete evidence that composite rewards can mitigate single-metric pathologies. The approach is grounded in existing base models and the DNS2020 benchmark.
major comments (2)
- [Abstract] Abstract: the central claims of SOTA performance on DNS2020 and avoidance of reward hacking via the multi-metric reward rest on experimental results, yet the manuscript supplies no baseline comparisons, statistical tests, ablation tables, or human-evaluation protocol details (listener count, significance testing, or inter-rater agreement), rendering the claims unverifiable from the provided text.
- [Abstract] Abstract and results sections: the claim that the composite of DNSMOS, WER, and UTMOS constitutes a sufficient and unbiased proxy for human-perceived quality (and therefore that multi-metric optimization avoids reward hacking) is load-bearing for both the SOTA result and the human-preference conclusion, but the manuscript contains no coverage analysis, correlation study against broader human judgments, or out-of-metric evaluation for artifacts such as unnatural prosody or speaker inconsistency.
minor comments (1)
- The acronym GSPO is introduced without an explicit definition or reference to its original formulation; a brief equation or citation in the methods section would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental detail and validation. We address each major comment below and will revise the manuscript accordingly to strengthen verifiability while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of SOTA performance on DNS2020 and avoidance of reward hacking via the multi-metric reward rest on experimental results, yet the manuscript supplies no baseline comparisons, statistical tests, ablation tables, or human-evaluation protocol details (listener count, significance testing, or inter-rater agreement), rendering the claims unverifiable from the provided text.
Authors: We agree that the abstract and results sections as currently written lack the necessary supporting details to allow independent verification of the SOTA claims and human-evaluation conclusions. In the revised manuscript we will expand both sections to include: (i) explicit baseline comparisons against the original UniSE and GenSE models as well as other DNS2020 methods, (ii) statistical significance tests (e.g., paired t-tests with reported p-values), (iii) complete ablation tables, and (iv) a detailed human-evaluation protocol specifying listener count, significance testing procedure, and inter-rater agreement metric. These additions will be placed in the main text and supplementary material. revision: yes
-
Referee: [Abstract] Abstract and results sections: the claim that the composite of DNSMOS, WER, and UTMOS constitutes a sufficient and unbiased proxy for human-perceived quality (and therefore that multi-metric optimization avoids reward hacking) is load-bearing for both the SOTA result and the human-preference conclusion, but the manuscript contains no coverage analysis, correlation study against broader human judgments, or out-of-metric evaluation for artifacts such as unnatural prosody or speaker inconsistency.
Authors: We acknowledge that the manuscript does not contain explicit coverage analysis, new correlation studies against broader human judgments, or targeted out-of-metric evaluations for artifacts such as prosody or speaker inconsistency. The existing human-preference ablation already provides direct evidence that the composite reward is preferred over single-metric variants, supporting the claim that multi-metric optimization mitigates reward hacking within the evaluated metrics. In revision we will add a dedicated limitations/discussion paragraph that (a) cites prior literature on the correlation of DNSMOS, WER, and UTMOS with human perception and (b) explicitly notes the absence of out-of-metric artifact analysis as a remaining limitation. No new experiments are required for this textual addition. revision: partial
Circularity Check
No circularity detected; method uses external metrics
full rationale
The paper applies Group Sequence Policy Optimization (GSPO) to optimize pre-existing, non-differentiable perceptual metrics (DNSMOS, WER, UTMOS) as reward signals on base models UniSE and GenSE. These metrics are drawn from independent prior work and are not defined, fitted, or derived within the paper itself. No equations, self-definitional loops, fitted-input-as-prediction patterns, or load-bearing self-citations appear in the abstract or described method. The SOTA claims on DNS2020 and human preference results are presented as empirical outcomes of this optimization, not as quantities that reduce to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- relative weights among DNSMOS, WER, and UTMOS in the composite reward
axioms (1)
- domain assumption DNSMOS, WER, and UTMOS are reliable, non-redundant proxies for human speech quality that can be used directly as reward signals without introducing bias or reward hacking when combined.
Reference graph
Works this paper leans on
-
[1]
Introduction Speech enhancement (SE) aims to recover clean speech from degraded signals affected by noise, reverberation, bandwidth limitation, or packet loss. While traditional approaches based on time-domain or time-frequency-domain models [1, 2, 3] have been effective for specific distortion types, recent work reframes SE as a sequence-to-sequence prob...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
SELM [4] tokenizes speech into discrete SSL tokens and uses a language model for contextual enhancement
Related Work LM-Based Speech Enhancement.Recent work has framed SE as a token prediction task using autoregressive language mod- els. SELM [4] tokenizes speech into discrete SSL tokens and uses a language model for contextual enhancement. LLaSE- G1 [5] uses a LLaMA backbone unifying multiple enhance- ment tasks. MaskSR [6] extends masked generative model-...
-
[3]
Methodology 3.1. Base Models We apply GSPO post-training to two autoregressive SE lan- guage models.UniSE[7] is a decoder-only autoregressive LM that unifies speech restoration, speaker extraction, and separa- tion using neural audio codec tokens at 16 kHz.GenSE[8] is an autoregressive LM that uses hierarchical two-stage gen- eration (first semantic token...
-
[4]
Experiments We evaluate GSPO post-training on the DNS2020 blind test set and conduct a human evaluation ablation on the reward compo- sition. 4.1. Setup We conduct an ablation using a human evaluation to understand the effect of various reward signals on the overall model per- formance. To this end, we conduct a pairwise preference test with 21 raters on ...
-
[5]
By directly optimizing non-differentiable quality metrics (DNSMOS, WER, UTMOS) as reward signals, our ap- proach closes the train-eval gap without learned surrogates
Conclusion We introduce post-training for autoregressive speech enhance- ment language models using GSPO with multi-metric percep- tual rewards. By directly optimizing non-differentiable quality metrics (DNSMOS, WER, UTMOS) as reward signals, our ap- proach closes the train-eval gap without learned surrogates. Ap- plied to UniSE and GenSE, GSPO post-train...
-
[6]
All outputs were reviewed and verified by the authors, who take full responsibility for the content of this paper
Generative AI Use Disclosure Generative AI tools were used to assist with polishing the manuscript, writing code for the experiments, and beautifying figures. All outputs were reviewed and verified by the authors, who take full responsibility for the content of this paper
-
[7]
Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,
Y . Luo and N. Mesgarani, “Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 27, no. 8, pp. 1256–1266, 2019
2019
-
[8]
Real Time Speech En- hancement in the Waveform Domain,
A. Defossez, G. Synnaeve, and Y . Adi, “Real Time Speech En- hancement in the Waveform Domain,” inInterspeech, 2020
2020
-
[9]
DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement,
Y . Hu, Y . Liu, S. Lv, M. Xing, S. Zhang, Y . Fuet al., “DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement,” inInterspeech, 2020
2020
-
[10]
SELM: Speech Enhancement Using Discrete Tokens and Lan- guage Models,
Z. Wang, X. Zhu, Z. Zhang, Y . Lv, N. Jiang, G. Zhaoet al., “SELM: Speech Enhancement Using Discrete Tokens and Lan- guage Models,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
2024
-
[11]
LLaSE-G1: Incentivizing Generalization Capability for LLaMA-based Speech Enhancement,
B. Kang, X. Zhu, Z. Zhang, Z. Ye, M. Liu, Z. Wang et al., “LLaSE-G1: Incentivizing Generalization Capability for LLaMA-based Speech Enhancement,” inProceedings of the An- nual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[12]
MaskSR: Masked Language Model for Full-Band Speech Restoration,
X. Li, Q. Wang, and X. Liu, “MaskSR: Masked Language Model for Full-Band Speech Restoration,” inInterspeech, 2024
2024
-
[13]
UniSE: A Unified Framework for Decoder-Only Autoregressive LM-Based Speech Enhancement
H. Yan, C. Liu, S. Xue, X. Liang, and Z. Xue, “UniSE: A Unified Framework for Decoder-only Autoregressive LM-based Speech Enhancement,” 2025, arXiv:2510.20441
work page internal anchor Pith review arXiv 2025
-
[14]
GenSE: Generative Speech Enhancement via Language Models using Hi- erarchical Modeling,
J. Yao, H. Liu, C. Chen, Y . Hu, E. S. Chng, and L. Xie, “GenSE: Generative Speech Enhancement via Language Models using Hi- erarchical Modeling,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[15]
Training Language Models to Follow Instruc- tions with Human Feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkinet al., “Training Language Models to Follow Instruc- tions with Human Feedback,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[16]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model,
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct Preference Optimization: Your Language Model is Secretly a Reward Model,” inAdvances in Neural In- formation Processing Systems (NeurIPS), 2023
2023
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Biet al., “DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models,” 2024, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
DeepSeek-R1 Incentivizes Reasoning in LLMs through Rein- forcement Learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhuet al., “DeepSeek-R1 Incentivizes Reasoning in LLMs through Rein- forcement Learning,”Nature, vol. 645, pp. 633–638, 2025
2025
-
[19]
DNSMOS: A Non- Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A Non- Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppressors,” inIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2021
2021
-
[20]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” inInternational Conference on Machine Learning (ICML), 2023
2023
-
[21]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inInterspeech, 2022
2022
-
[22]
MetricGAN: Gen- erative Adversarial Networks based Black-box Metric Scores Op- timization for Speech Enhancement,
S.-W. Fu, C.-F. Liao, Y . Tsao, and S.-D. Lin, “MetricGAN: Gen- erative Adversarial Networks based Black-box Metric Scores Op- timization for Speech Enhancement,” inInternational Conference on Machine Learning (ICML), 2019
2019
-
[23]
MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement,
S.-W. Fu, C. Yu, T.-A. Hsieh, P. Plantinga, M. Ravanelli, X. Lu et al., “MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement,” inInterspeech, 2021
2021
-
[24]
Aligning Generative Speech Enhancement with Perceptual Feed- back,
H. Li, N. Hou, Y . Hu, J. Yao, S. M. Siniscalchi, X. Zhuanget al., “Aligning Generative Speech Enhancement with Perceptual Feed- back,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026
2026
-
[25]
The PESQetarian: On the Relevance of Goodhart’s Law for Speech Enhancement,
D. de Oliveira, S. Welker, J. Richter, and T. Gerkmann, “The PESQetarian: On the Relevance of Goodhart’s Law for Speech Enhancement,” inInterspeech, 2024
2024
-
[26]
Group Sequence Policy Optimization
C. Zheng, S. Liu, M. Li, X.-H. Chen, B. Yu, C. Gaoet al., “Group Sequence Policy Optimization,” 2025, arXiv:2507.18071
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
AnyEnhance: A Unified Generative Model with Prompt- Guidance and Self-Critic for V oice Enhancement,
J. Zhang, J. Yang, Z. Fang, Y . Wang, Z. Zhang, Z. Wang et al., “AnyEnhance: A Unified Generative Model with Prompt- Guidance and Self-Critic for V oice Enhancement,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 33, pp. 3085–3098, 2025
2025
-
[28]
SpeechAlign: Aligning Speech Generation to Human Prefer- ences,
D. Zhang, Z. Li, S. Li, X. Zhang, P. Wang, Y . Zhouet al., “SpeechAlign: Aligning Speech Generation to Human Prefer- ences,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[29]
Fine- Tuning Text-to-Speech Diffusion Models Using Reinforcement Learning with Human Feedback,
J. Chen, J.-S. Byun, M. Elsner, P. Wang, and A. Perrault, “Fine- Tuning Text-to-Speech Diffusion Models Using Reinforcement Learning with Human Feedback,” inInterspeech, 2025
2025
-
[30]
Koel-TTS: Enhancing LLM based Speech Gen- eration with Preference Alignment and Classifier Free Guidance,
S. S. Hussain, P. Neekhara, X. Yang, E. Casanova, S. Ghosh, R. Fejginet al., “Koel-TTS: Enhancing LLM based Speech Gen- eration with Preference Alignment and Classifier Free Guidance,” inConference on Empirical Methods in Natural Language Pro- cessing (EMNLP), 2025
2025
-
[31]
Fine- grained Preference Optimization Improves Zero-shot Text-to- Speech,
J. Yao, Y . Yang, Y . Pan, Y . Feng, Z. Ning, J. Yeet al., “Fine- grained Preference Optimization Improves Zero-shot Text-to- Speech,” 2025, accepted at IEEE Trans. Audio, Speech, Language Process. arXiv:2502.02950
-
[32]
FlowSE-GRPO: Training Flow Matching Speech Enhancement via Online Reinforcement Learning,
H. Wang, B. Tian, Y . Jiang, Z. Pan, S. Zhao, B. Maet al., “FlowSE-GRPO: Training Flow Matching Speech Enhancement via Online Reinforcement Learning,” inIEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), 2026
2026
-
[33]
Inter-SubNet: Speech Enhancement with Subband Interaction,
J. Chen, W. Rao, Z. Wang, J. Lin, Z. Wu, Y . Wanget al., “Inter-SubNet: Speech Enhancement with Subband Interaction,” inIEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), 2023
2023
-
[34]
Conditional Diffusion Probabilistic Model for Speech Enhancement,
Y .-J. Lu, Z.-Q. Wang, S. Watanabe, A. Richard, C. Yu, and Y . Tsao, “Conditional Diffusion Probabilistic Model for Speech Enhancement,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
2022
-
[35]
Speech Enhancement and Dereverberation with Diffusion-Based Generative Models,
J. Richter, S. Welker, J.-M. Lemercier, B. Lay, and T. Gerkmann, “Speech Enhancement and Dereverberation with Diffusion-Based Generative Models,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2351–2364, 2023
2023
-
[36]
StoRM: A Diffusion-Based Stochastic Regeneration Model for Speech Enhancement and Dereverberation,
J.-M. Lemercier, J. Richter, S. Welker, and T. Gerkmann, “StoRM: A Diffusion-Based Stochastic Regeneration Model for Speech Enhancement and Dereverberation,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 31, pp. 2724–2737, 2023
2023
-
[37]
V oiceFixer: A Unified Framework for High-Fidelity Speech Restoration,
H. Liu, Q. Kong, Q. Tian, Y . Zhao, D. Wang, C. Huanget al., “V oiceFixer: A Unified Framework for High-Fidelity Speech Restoration,” inInterspeech, 2022
2022
-
[38]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” 2017, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhance- ment System For ICASSP 2023 DNS Challenge,
Y . Ju, J. Chen, S. Zhang, S. He, W. Rao, W. Zhuet al., “TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhance- ment System For ICASSP 2023 DNS Challenge,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[40]
The NPU-Elevoc Personalized Speech Enhancement System for ICASSP2023 DNS Challenge,
X. Yan, Y . Yang, Z. Guo, L. Peng, and L. Xie, “The NPU-Elevoc Personalized Speech Enhancement System for ICASSP2023 DNS Challenge,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023
2023
-
[41]
Uni- Flow: Unifying Speech Front-End Tasks via Continuous Genera- tive Modeling,
Z. Wang, Z. Liu, Y . Zhu, X. Li, B. Kang, J. Yaoet al., “Uni- Flow: Unifying Speech Front-End Tasks via Continuous Genera- tive Modeling,” 2025, arXiv:2508.07558
-
[42]
The INTERSPEECH 2020 Deep Noise Sup- pression Challenge: Datasets, Subjective Testing Framework, and Challenge Results,
C. K. A. Reddy, V . Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubeyet al., “The INTERSPEECH 2020 Deep Noise Sup- pression Challenge: Datasets, Subjective Testing Framework, and Challenge Results,” inInterspeech, 2020
2020
-
[43]
ICASSP 2023 Deep Noise Suppression Chal- lenge,
H. Dubey, V . Gopal, R. Cutler, A. Aazami, S. Matusevych, S. Braunet al., “ICASSP 2023 Deep Noise Suppression Chal- lenge,”IEEE Open Journal of Signal Processing, vol. 5, pp. 725– 737, 2024
2023
-
[44]
HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset,
R. Langman, X. Yang, P. Neekhara, S. Hussain, E. Casanova, E. Bakhturinaet al., “HiFiTTS-2: A Large-Scale High Bandwidth Speech Dataset,” inInterspeech, 2025
2025
-
[45]
The Diverse Environ- ments Multi-Channel Acoustic Noise Database (DEMAND): A Database of Multichannel Environmental Noise Recordings,
J. Thiemann, N. Ito, and E. Vincent, “The Diverse Environ- ments Multi-Channel Acoustic Noise Database (DEMAND): A Database of Multichannel Environmental Noise Recordings,” in Proceedings of Meetings on Acoustics (ICA), vol. 19, 2013
2013
-
[46]
A Study on Data Augmentation of Reverberant Speech for Ro- bust Speech Recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A Study on Data Augmentation of Reverberant Speech for Ro- bust Speech Recognition,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.