VQActFlow: Vector-Quantized Action Mode Steering for Multi-Task Robot Manipulation
Pith reviewed 2026-06-26 14:13 UTC · model grok-4.3
The pith
VQActFlow tokenizes robot action chunks into a discrete codebook and generates steered sequences with variational flow matching to select correct modes in multi-task manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
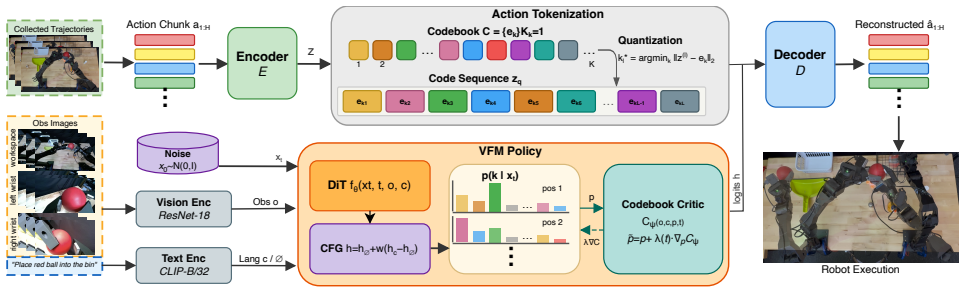
Tokenizing continuous actions into a learned discrete codebook separates modes at the representation level; variational flow matching then generates code sequences that preserve an explicit mode preference, which inference-time classifier-free guidance and a codebook critic can steer toward the instructed and feasible action mode.
What carries the argument
Vector-quantized action codebook combined with variational flow matching that maintains and steers an explicit mode preference throughout sequence generation.
If this is right
- Language conditioning can reliably steer the policy to the instructed action mode without retraining.
- The codebook critic supplies an additional feasibility signal that reduces execution of infeasible actions.
- Explicit mode tracking improves performance across qualitatively different tasks on the same robot platform.
- The same architecture transfers from simulation benchmarks to physical humanoid and bimanual hardware.
Where Pith is reading between the lines
- The discrete codebook could support reusable sub-sequences across tasks if the learned codes prove composable.
- Guidance mechanisms developed here might extend to other conditioning signals such as goal images or force feedback.
- If the mode separation holds, the approach may reduce interference between tasks that share visual contexts but require different action styles.
Load-bearing premise
Tokenizing continuous actions into a learned discrete codebook separates these modes at the representation level and thereby offers structural advantages for multi-task learning.
What would settle it
If a continuous-action baseline matches or exceeds VQActFlow success rates on the LIBERO benchmarks, the Unitree G1 whole-body tasks, or the ALOHA bimanual contact-rich tasks, the claimed structural advantage of the discrete codebook would be falsified.
Figures




read the original abstract
Multi-task robot manipulation policies are challenging to learn from demonstration because traditionally a single network must select among qualitatively different action modes from a multimodal demonstration distribution, conditioned on language and visual context. A wrong mode selection means executing the wrong task or an action infeasible in the scene. Tokenizing continuous actions into a learned discrete codebook separates these modes at the representation level, offering structural advantages for multi-task learning. We propose VQActFlow, a multi-task manipulation policy that tokenizes action chunks and generates code sequences via Variational Flow Matching. VQActFlow maintains an explicit preference over action modes throughout generation. Inference-time guidance acts on this preference to steer mode commitment. We instantiate this with classifier-free guidance over language conditioning, which steers the policy toward the instructed action mode, and a learned codebook critic that supplies a complementary feasibility signal. We evaluate VQActFlow on three platforms: the LIBERO simulation benchmarks, a Unitree G1 humanoid performing whole-body pick-and-place, and an ALOHA-style bimanual platform performing contact-rich tasks. Across these benchmarks, VQActFlow outperforms both continuous and discrete baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VQActFlow, a multi-task robot manipulation policy that tokenizes continuous action chunks into a learned discrete codebook and generates code sequences via Variational Flow Matching. It maintains an explicit preference over action modes and uses inference-time guidance via classifier-free guidance on language conditioning plus a learned codebook critic for feasibility. The central claim is that this discretization separates action modes at the representation level and yields outperformance over both continuous and discrete baselines on the LIBERO simulation benchmarks, whole-body pick-and-place on a Unitree G1 humanoid, and contact-rich tasks on an ALOHA-style bimanual platform.
Significance. If the quantitative results hold and an ablation confirms that the VQ discretization (rather than the flow-matching or guidance machinery) drives the gains, the work could provide a useful structural approach to handling multimodal action distributions in multi-task settings.
major comments (2)
- [Method] Method section: the motivating assumption that tokenizing actions into a learned discrete codebook separates modes at the representation level is not isolated; the description combines VQ with Variational Flow Matching, classifier-free guidance, and a codebook critic, but no ablation is reported that holds the flow-matching and guidance components fixed while removing the codebook.
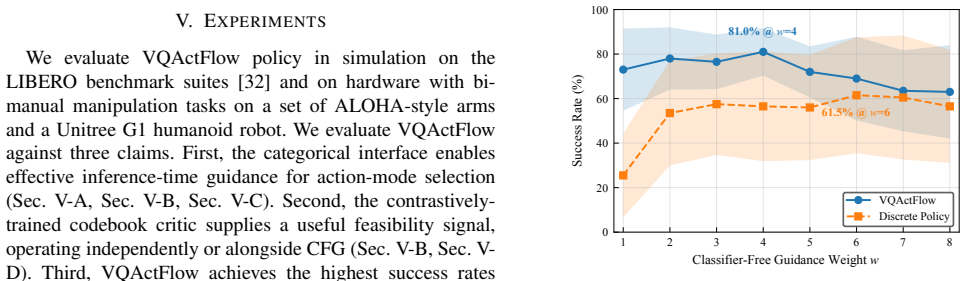
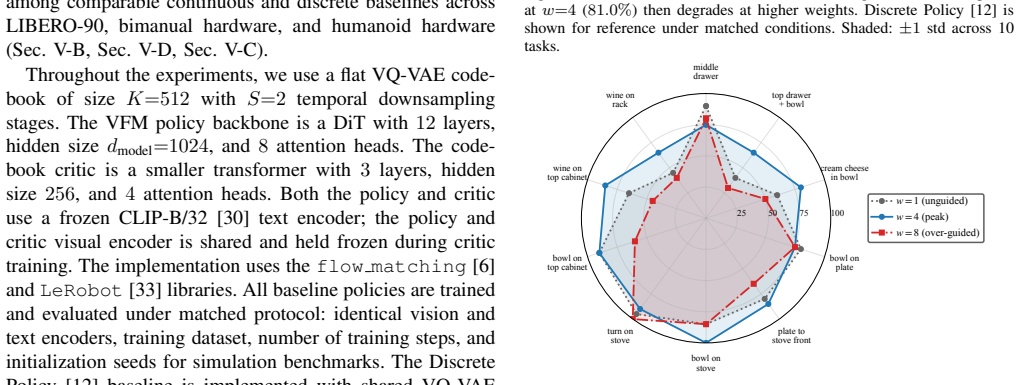
- [Experiments] Experiments section: the claim of outperformance across three platforms is stated without reference to specific quantitative metrics, baseline details, error bars, or statistical significance tests, making it impossible to assess whether the data support the central claim.
minor comments (1)
- [Abstract] Abstract: the motivation and method components are densely packed; separating the description of the codebook critic from the guidance mechanism would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Method] Method section: the motivating assumption that tokenizing actions into a learned discrete codebook separates modes at the representation level is not isolated; the description combines VQ with Variational Flow Matching, classifier-free guidance, and a codebook critic, but no ablation is reported that holds the flow-matching and guidance components fixed while removing the codebook.
Authors: We agree that the manuscript would be strengthened by an ablation that holds the Variational Flow Matching and guidance components fixed while removing the codebook. Our current experiments compare against continuous and alternative discrete baselines, but do not isolate the VQ discretization in this manner. We will add the requested ablation in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section: the claim of outperformance across three platforms is stated without reference to specific quantitative metrics, baseline details, error bars, or statistical significance tests, making it impossible to assess whether the data support the central claim.
Authors: The full manuscript contains tables with success rates, baseline comparisons (including Diffusion Policy, RT-1, and discrete tokenization variants), means and standard deviations over multiple random seeds, and notes on evaluation protocol for all three platforms. We will revise the experiments section to explicitly cite these metrics, detail the baselines, and reference the statistical reporting already present in the tables. revision: yes
Circularity Check
No circularity: empirical method proposal with no self-referential derivations or fitted predictions
full rationale
The paper proposes VQActFlow as a combination of vector quantization for action tokenization, variational flow matching for code-sequence generation, and inference-time guidance mechanisms. No mathematical derivation chain, uniqueness theorem, or first-principles prediction is presented that reduces to its own inputs by construction. The central motivation (mode separation via discretization) is stated as an assumption rather than derived, and performance claims are benchmark comparisons that remain externally falsifiable. No self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. The method is self-contained as an engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking,
H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V . Ku- mar, “Roboagent: Generalization and efficiency in robot manipulation via semantic augmentations and action chunking,” inProc. IEEE Int. Conf. Robot. Autom., 2024, pp. 4788–4795
2024
-
[2]
Hierarchical diffusion policy for kinematics-aware multi-task robotic manipulation,
X. Ma, S. Patidar, I. Haughton, and S. James, “Hierarchical diffusion policy for kinematics-aware multi-task robotic manipulation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2024, pp. 18 081–18 090
2024
-
[3]
Behavior generation with latent actions,
S. Lee, Y . Wang, H. Etukuru, H. J. Kim, N. M. M. Shafiullah, and L. Pinto, “Behavior generation with latent actions,” inProc. Int. Conf. Mach. Learn., 2024, pp. 26 991–27 008
2024
-
[4]
A survey of optimization-based task and motion planning: From classical to learning approaches,
Z. Zhao, S. Cheng, Y . Ding, Z. Zhou, S. Zhang, D. Xu, and Y . Zhao, “A survey of optimization-based task and motion planning: From classical to learning approaches,”IEEE/ASME Trans. Mechatronics, vol. 30, no. 4, pp. 2799–2825, 2024
2024
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”Int. J. Robot. Res., vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[6]
Y . Lipman, M. Havasi, P. Holderrieth, N. Shaul, M. Le, B. Karrer, R. T. Chen, D. Lopez-Paz, H. Ben-Hamu, and I. Gat, “Flow matching guide and code,”arXiv:2412.06264, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision-language-action flow model for general robot control,”arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Proc. Adv. Neural Inf. Process. Syst., vol. 34, pp. 8780– 8794, 2021
2021
-
[10]
Planning with diffusion for flexible behavior synthesis,
M. Janner, Y . Du, J. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” inProc. Int. Conf. Mach. Learn., 2022, pp. 9902–9915
2022
-
[11]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Proc. Adv. Neural Inf. Process. Syst., vol. 30, 2017
2017
-
[12]
Discrete policy: Learning disentangled action space for multi-task robotic manipulation,
K. Wu, Y . Zhu, J. Li, J. Wen, N. Liu, Z. Xu, and J. Tang, “Discrete policy: Learning disentangled action space for multi-task robotic manipulation,” inProc. IEEE Int. Conf. Robot. Autom., 2025, pp. 8811–8818
2025
-
[13]
Variational flow matching for graph generation,
F. Eijkelboom, G. Bartosh, C. Andersson Naesseth, M. Welling, and J.-W. van de Meent, “Variational flow matching for graph generation,” Proc. Adv. Neural Inf. Process. Syst., vol. 37, pp. 11 735–11 764, 2024
2024
-
[14]
Purrception: Variational flow matching for vector-quantized image generation,
R.-A. Matis ¸an, V . T. Hu, G. Bartosh, B. Ommer, C. G. Snoek, M. Welling, J.-W. van de Meent, M. M. Derakhshani, and F. Eijkel- boom, “Purrception: Variational flow matching for vector-quantized image generation,”arXiv:2510.01478, 2025
-
[15]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Proc. Adv. Neural Inf. Process. Syst., vol. 33, pp. 6840–6851, 2020
2020
-
[16]
Diffuseloco: Real-time legged locomotion control with diffusion from offline datasets,
X. Huang, Y . Chi, R. Wang, Z. Li, X. B. Peng, S. Shao, B. Nikolic, and K. Sreenath, “Diffuseloco: Real-time legged locomotion control with diffusion from offline datasets,” inProc. Conf. Robot Learn., 2025, pp. 1567–1589. 0 1 2 3 4 5 6 time (s) 102 103 104 ‖ ⃛θ‖ (rad/s3) VQActFlow CFM Fig. 9. Motion smoothness comparison between VQActFlow and CFM for bim...
2025
-
[17]
Hybrid diffusion for simultaneous symbolic and continuous planning,
S. H. Høeg, A. Vaaler, C. Liu, O. Egeland, and Y . Du, “Hybrid diffusion for simultaneous symbolic and continuous planning,”IEEE Robot. Autom. Lett., 2026
2026
-
[18]
Discrete flow matching,
I. Gat, T. Remez, N. Shaul, F. Kreuk, R. T. Chen, G. Synnaeve, Y . Adi, and Y . Lipman, “Discrete flow matching,”Proc. Adv. Neural Inf. Process. Syst., vol. 37, pp. 133 345–133 385, 2024
2024
-
[19]
Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design,
A. Campbell, J. Yim, R. Barzilay, T. Rainforth, and T. Jaakkola, “Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design,” inProc. Int. Conf. Mach. Learn., 2024, pp. 5453–5512
2024
-
[20]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuonget al., “Openvla: An open-source vision-language-action model,” inProc. Conf. Robot Learn., 2025, pp. 2679–2713
2025
-
[21]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine, “Fast: Efficient action tokenization for vision-language-action models,”arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Oat: Ordered action tokenization,
C. Liu, X. Han, J. Gao, Y . Zhao, H. Chen, and Y . Du, “Oat: Ordered action tokenization,”arXiv:2602.04215, 2026
-
[23]
Guided flows for generative modeling and decision making,
Q. Zheng, M. Le, N. Shaul, Y . Lipman, A. Grover, and R. T. Chen, “Guided flows for generative modeling and decision making,” arXiv:2311.13443, 2023
-
[24]
Safediffuser: Safe planning with diffusion probabilistic models,
W. Xiao, T.-H. Wang, C. Gan, R. Hasani, M. Lechner, and D. Rus, “Safediffuser: Safe planning with diffusion probabilistic models,” in Proc. Int. Conf. Learn. Represent., 2023
2023
-
[25]
Physics-informed diffusion models,
J.-H. Bastek, W. Sun, and D. Kochmann, “Physics-informed diffusion models,” inProc. Int. Conf. Learn. Represent., vol. 2025, 2025, pp. 3360–3385
2025
-
[26]
Model-based diffusion for trajectory optimization,
C. Pan, Z. Yi, G. Shi, and G. Qu, “Model-based diffusion for trajectory optimization,”Proc. Adv. Neural Inf. Process. Syst., vol. 37, pp. 57 914–57 943, 2024
2024
-
[27]
Taming transformers for high- resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high- resolution image synthesis,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 12 873–12 883
2021
-
[28]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 4195–4205
2023
-
[29]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778
2016
-
[30]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inProc. Int. Conf. Mach. Learn., 2021, pp. 8748–8763
2021
-
[31]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”Proc. Adv. Neural Inf. Process. Syst., vol. 36, pp. 44 776–44 791, 2023
2023
-
[33]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github.com/huggingface/lerobot, 2024
2024
-
[34]
Twist2: Scalable, portable, and holistic humanoid data collection system,
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu, “Twist2: Scalable, portable, and holistic humanoid data collection system,”arXiv:2511.02832, 2025
-
[35]
Xrobotoolkit: A cross-platform framework for robot teleoperation,
Z. Zhao, L. Yu, K. Jing, and N. Yang, “Xrobotoolkit: A cross-platform framework for robot teleoperation,” inProc. IEEE/SICE Int. Symp. Syst. Integr., 2026, pp. 15–20
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.