Finite-Sample Performance of Gradient Descent in Logistic Regression with Gaussian Design
Pith reviewed 2026-06-26 12:27 UTC · model grok-4.3
The pith
Gradient descent on logistic regression reaches an l2 error of order sqrt of theta-star norm to the fifth times d over n with linear convergence under small stepsize.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under small O(1) stepsize and zero initialization, gradient descent linearly converges to a small neighborhood of theta* achieving an l2 error of order O(sqrt(||theta*||_2^5 d/n)). A faster local linear convergence to the same statistical error holds under a large Theta(||theta*||) stepsize. The gradient of the logistic loss satisfies an approximate invertibility condition that enables the contraction mapping for both empirical and population iterates.
What carries the argument
Approximate invertibility condition (AIC) on the gradient of the logistic loss, established by uniform control of empirical-population deviations via covering and peeling, followed by contraction of population GD iterates via eigenvalues of population Hessian matrices.
If this is right
- Gradient descent attains the stated non-asymptotic l2 estimation rate under the given initialization and stepsize.
- Local linear convergence accelerates when the stepsize is scaled up to Theta of the norm of theta-star.
- A novel efficient estimator constructed from recent work reaches the sharper rate Theta of sqrt of (norm of theta-star times d over n), showing prior non-asymptotic bounds have suboptimal dependence on the signal strength.
- In many regimes the tight statistical error rate is therefore Theta of sqrt of (norm of theta-star times d over n).
Where Pith is reading between the lines
- The improved rate achieved by the novel estimator suggests that a refined stepsize schedule or analysis might allow plain gradient descent to reach the same dependence on theta-star norm.
- The approximate invertibility technique may extend to other generalized linear models whose link functions produce comparable Hessian eigenvalue behavior.
- The guarantees are most relevant in regimes where dimension d grows with sample size n but the signal strength remains moderate.
Load-bearing premise
The gradient of the logistic loss satisfies an approximate invertibility condition that supports contraction mapping for the iterates.
What would settle it
An explicit counter-example or simulation in which the empirical gradient deviates from its population counterpart enough to violate the approximate invertibility condition, causing GD iterates to fail to contract linearly into the claimed neighborhood, would falsify the result.
Figures
read the original abstract
We consider the parameter estimation problem in logistic regression with Gaussian design: the estimation of a fixed unknown parameter $\theta^*\in \mathbb{R}^d$ ($\|\theta^*\|_2\ge 1$) from $n$ i.i.d. samples $\{(x_i,y_i)\}_{i=1}^n$, where $x_i\sim N(0,I_d)$ and $y_i|x_i \sim {\rm Bernoulli}(1/(1+\exp(-x_i^\top \theta^*)))$. Our main aim is to characterize the finite-sample estimation performance and convergence behavior of gradient descent (GD) on the maximum likelihood objective (i.e., the logistic loss). Under small $O(1)$ stepsize and $0$ initialization, we show that GD linearly converges to a small neighborhood of $\theta^*$ achieving an $\ell_2$ error of order $O(\sqrt{\|\theta^*\|_2^5d/n})$. This substantially goes beyond existing theoretical results that lack non-asymptotic estimation error rate and exhibit much slower parameter convergence. We also establish a faster local linear convergence to the same statistical error under a large $\Theta(\|\theta^*\|_2)$ stepsize. The main technical component is to show that the gradient of the logistic loss satisfies a certain approximate invertibility condition (AIC). To that end, we uniformly control the deviation of the gradient from its population counterpart by covering and peeling arguments, and then show that the population GD is a contraction by a delicate analysis based on the eigenvalues of population Hessian matrices. Finally, we build upon the recent work Matsumoto and Mazumdar (2025) and devise a novel efficient estimator that attains a sharper rate in high dimensions. This indicates that the existing non-asymptotic guarantees exhibit sub-optimal dependence on $\|\theta^*\|_2$, and that in many regimes $\Theta(\sqrt{\|\theta^*\|_2d/n})$ is the tight estimation error rate. Numerical examples are provided to corroborate our theoretical results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes finite-sample behavior of gradient descent (GD) on the logistic loss for parameter estimation in logistic regression with Gaussian design x_i ~ N(0,I_d). With small O(1) stepsize and zero initialization, GD is claimed to converge linearly to a neighborhood of θ* with ℓ2 error O(√(||θ*||_2^5 d/n)). A faster local linear convergence is shown under Θ(||θ*||_2) stepsize. The key technical step is establishing an approximate invertibility condition (AIC) on the gradient via covering/peeling for uniform deviation bounds and eigenvalue analysis of the population Hessian; a sharper estimator attaining O(√(||θ*||_2 d/n)) is constructed by building on Matsumoto and Mazumdar (2025).
Significance. If the non-asymptotic rates and AIC hold, the work supplies explicit finite-sample guarantees for GD in logistic regression that track the dependence on ||θ*||_2 (previously missing in the literature) and indicates near-optimality of the statistical radius in certain regimes. The combination of uniform deviation arguments with contraction mapping via population Hessian eigenvalues is a standard and appropriate technique for this setting.
major comments (3)
- [AIC proof (covering/peeling + population contraction)] The central contraction-mapping argument rests on the approximate invertibility condition (AIC). The claimed statistical radius contains an ||θ*||_2^5 factor inside the square root; this indicates that either the uniform deviation bound or the contraction modulus in the AIC proof degrades polynomially with ||θ*||_2. It is therefore necessary to verify explicitly that an O(1) stepsize still yields a contraction factor strictly less than 1 uniformly in the regime ||θ*||_2 ≫ 1 (see the population-Hessian eigenvalue analysis).
- [Population Hessian analysis] The eigenvalue analysis of the population Hessian that establishes contractivity of the population GD map must be checked for its dependence on ||θ*||_2. The logistic Hessian involves factors of the form σ'(x^T θ) x x^T whose smallest eigenvalues can deteriorate when ||θ*||_2 grows, potentially violating the uniform contraction needed for the claimed linear convergence rate.
- [Local convergence statement] The faster local linear convergence result under the larger Θ(||θ*||_2) stepsize is stated to reach the same statistical radius; the local neighborhood size in which this larger stepsize is valid must be shown to contain the statistical ball of radius O(√(||θ*||_2^5 d/n)) without circularity.
minor comments (2)
- [Notation section] Notation for the logistic loss and its gradient should be introduced once and used consistently; the transition between empirical and population quantities is occasionally ambiguous.
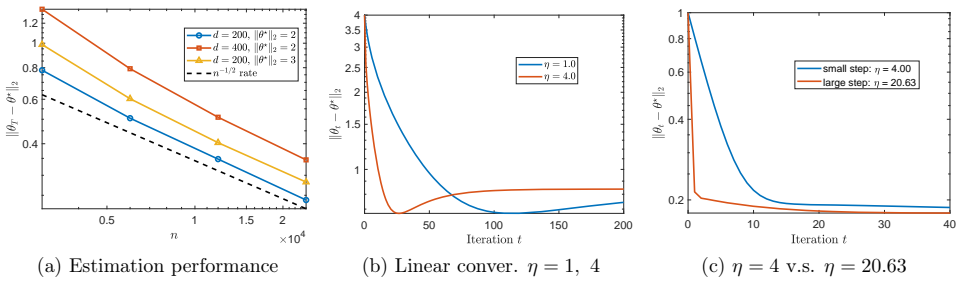
- [Numerical examples] The numerical experiments section would benefit from explicit reporting of the observed dependence of the error on ||θ*||_2 to corroborate the ||θ*||_2^5 factor.
Simulated Author's Rebuttal
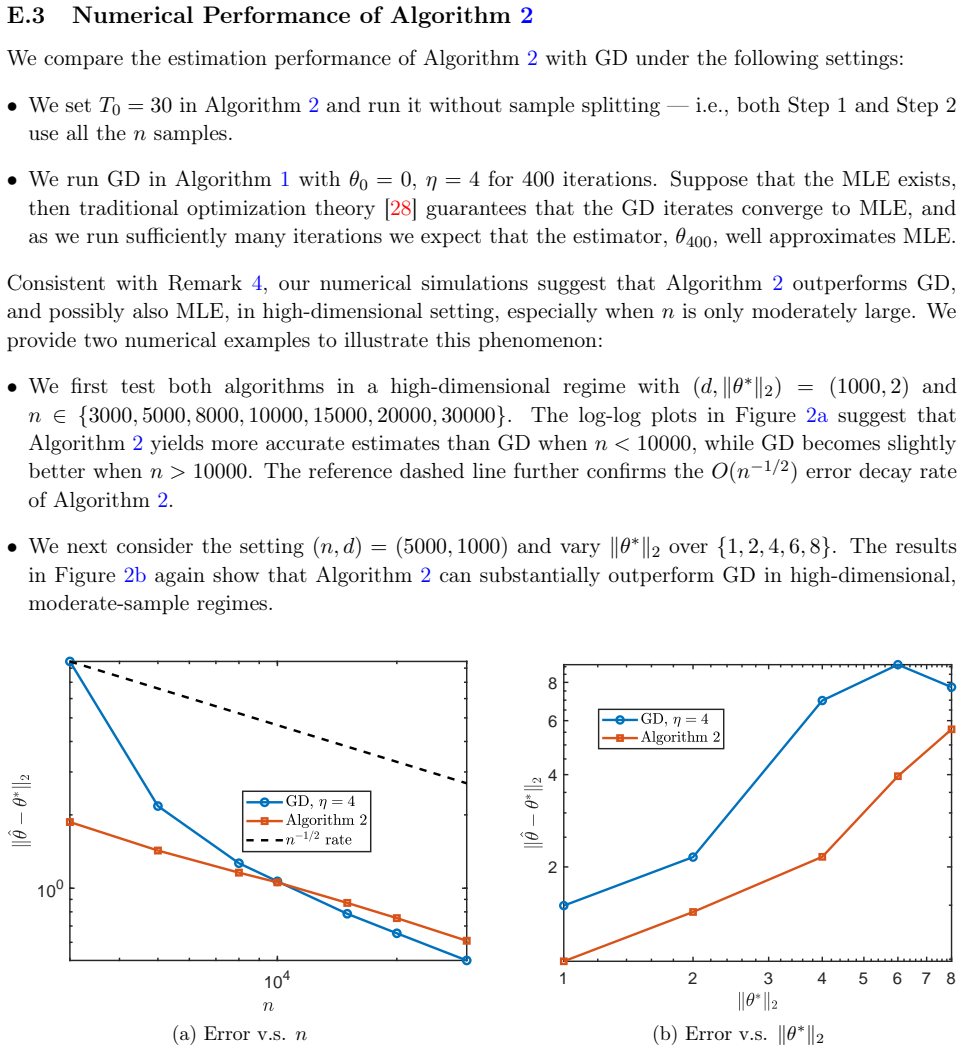
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment point by point below, providing clarifications from the existing analysis and indicating where revisions will be made.
read point-by-point responses
-
Referee: [AIC proof (covering/peeling + population contraction)] The central contraction-mapping argument rests on the approximate invertibility condition (AIC). The claimed statistical radius contains an ||θ*||_2^5 factor inside the square root; this indicates that either the uniform deviation bound or the contraction modulus in the AIC proof degrades polynomially with ||θ*||_2. It is therefore necessary to verify explicitly that an O(1) stepsize still yields a contraction factor strictly less than 1 uniformly in the regime ||θ*||_2 ≫ 1 (see the population-Hessian eigenvalue analysis).
Authors: The polynomial dependence on ||θ*||_2 in the statistical radius arises exclusively from the uniform deviation bounds derived via the covering and peeling arguments (which must control the tails of the logistic gradient under large signal strength). The contraction modulus itself remains strictly less than 1 with an O(1) stepsize, uniformly over ||θ*||_2 ≥ 1. This follows from the population Hessian eigenvalue analysis, which yields a contraction factor of at most 1 − c for an absolute constant c > 0 independent of ||θ*||_2. We will insert an explicit lemma stating this uniform lower bound on the contraction factor to make the separation between deviation and contraction transparent. revision: yes
-
Referee: [Population Hessian analysis] The eigenvalue analysis of the population Hessian that establishes contractivity of the population GD map must be checked for its dependence on ||θ*||_2. The logistic Hessian involves factors of the form σ'(x^T θ) x x^T whose smallest eigenvalues can deteriorate when ||θ*||_2 grows, potentially violating the uniform contraction needed for the claimed linear convergence rate.
Authors: Although individual realizations of σ'(x^T θ)xx^T can be small for large ||θ*||_2, the population expectation E[σ'(x^T θ*)xx^T] admits a uniform positive lower bound on its minimal eigenvalue (at least 1/8) for all ||θ*||_2 ≥ 1 under Gaussian design. This is established by reducing to a one-dimensional expectation over the marginal projection and using the fact that the logistic variance function remains sufficiently positive in expectation. The O(1) stepsize is chosen smaller than the reciprocal of the uniform upper bound on the Hessian operator norm, preserving the contraction. We will expand the eigenvalue section with the full uniform bounds and the explicit stepsize restriction. revision: yes
-
Referee: [Local convergence statement] The faster local linear convergence result under the larger Θ(||θ*||_2) stepsize is stated to reach the same statistical radius; the local neighborhood size in which this larger stepsize is valid must be shown to contain the statistical ball of radius O(√(||θ*||_2^5 d/n)) without circularity.
Authors: The region of validity for the Θ(||θ*||_2) stepsize is a ball of radius Ω(1/||θ*||_2) around θ*, whose size is independent of n and d. Because the statistical radius O(√(||θ*||_2^5 d/n)) tends to zero as n → ∞ (for fixed d and ||θ*||_2), there exists N0 such that for all n ≥ N0 the statistical ball lies strictly inside the local region. The local contraction is proved on the population map; the finite-sample deviation is controlled separately via the AIC and does not enter the definition of the local neighborhood. We will add an explicit comparison of the two radii in the local-convergence section to eliminate any appearance of circularity. revision: yes
Circularity Check
Minor self-citation for secondary sharper estimator; central GD convergence derived independently
full rationale
The paper's core derivation establishes linear convergence of GD to a neighborhood of size O(√(||θ*||₂⁵ d/n)) by proving the approximate invertibility condition (AIC) via uniform deviation bounds (covering/peeling) on the empirical gradient and eigenvalue analysis of the population Hessian to show contraction. This analysis is self-contained and does not reduce to any fitted input, self-definition, or prior self-citation. The only self-citation appears in the final paragraph, where Matsumoto and Mazumdar (2025) is invoked solely to construct an auxiliary efficient estimator with improved rate; this does not support or justify the main finite-sample GD claim. No other patterns (self-definitional, fitted predictions, ansatz smuggling, or renaming) are present. The result is therefore a standard first-principles analysis with one non-load-bearing self-citation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Covariates x_i are i.i.d. N(0, I_d)
- ad hoc to paper Gradient of logistic loss satisfies approximate invertibility condition (AIC)
Reference graph
Works this paper leans on
-
[1]
Pedro Abdalla, Radu Balan, and Junren Chen. Robust uniform recovery of structured signals from nonlinear observations.arXiv preprint arXiv:2604.20075, 2026
Pith/arXiv arXiv 2026
-
[2]
Model selection and minimax estimation in generalized linear models.IEEE Transactions on Information Theory, 62(6):3721–3730, 2016
Felix Abramovich and Vadim Grinshtein. Model selection and minimax estimation in generalized linear models.IEEE Transactions on Information Theory, 62(6):3721–3730, 2016
2016
-
[3]
Gradient descent converges linearly for logistic regres- sion on separable data
Kyriakos Axiotis and Maxim Sviridenko. Gradient descent converges linearly for logistic regres- sion on separable data. InInternational Conference on Machine Learning, pages 1302–1319. PMLR, 2023
2023
-
[4]
Rademacher and gaussian complexities: Risk bounds and structural results.Journal of machine learning research, 3(Nov):463–482, 2002
Peter L Bartlett and Shahar Mendelson. Rademacher and gaussian complexities: Risk bounds and structural results.Journal of machine learning research, 3(Nov):463–482, 2002
2002
-
[5]
Oxford University Press, February 2013
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, February 2013
2013
-
[6]
The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression.The Annals of Statistics, 48(1):27–42, 2020
Emmanuel J Candès and Pragya Sur. The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression.The Annals of Statistics, 48(1):27–42, 2020. 11
2020
-
[7]
Hugo Chardon, Matthieu Lerasle, and Jaouad Mourtada. Finite-sample performance of the maximum likelihood estimator in logistic regression.arXiv preprint arXiv:2411.02137, 2024
arXiv 2024
-
[8]
Junren Chen, Lijun Ding, Dong Xia, and Ming Yuan. A unified approach to statistical estima- tion under nonlinear observations: tensor estimation and low-rank factorization.arXiv preprint arXiv:2510.16965, 2025
arXiv 2025
-
[9]
One-bit phase retrieval: Optimal rates and efficient algorithms
Junren Chen and Ming Yuan. One-bit phase retrieval: Optimal rates and efficient algorithms. IEEE Transactions on Information Theory, 2026
2026
-
[10]
Gradient descent on neural networks typically occurs at the edge of stability
Jeremy Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. InInternational Conference on Learning Representations, 2021
2021
-
[11]
Nbiht: An efficient algorithm for 1-bit compressed sensing with optimal error decay rate.IEEE Transactions on Information Theory, 68(2):1157–1177, 2021
Michael P Friedlander, Halyun Jeong, Yaniv Plan, and Özgür Yılmaz. Nbiht: An efficient algorithm for 1-bit compressed sensing with optimal error decay rate.IEEE Transactions on Information Theory, 68(2):1157–1177, 2021
2021
-
[12]
Academic press, 2013
Morris W Hirsch, Stephen Smale, and Robert L Devaney.Differential equations, dynamical systems, and an introduction to chaos. Academic press, 2013
2013
-
[13]
On the sample complexity of parameter estimation in logistic regression with normal design
Daniel Hsu and Arya Mazumdar. On the sample complexity of parameter estimation in logistic regression with normal design. InThe Thirty Seventh Annual Conference on Learning Theory, pages 2418–2437. PMLR, 2024
2024
-
[14]
Robust 1- bit compressive sensing via binary stable embeddings of sparse vectors.IEEE Transactions on Information Theory, 59(4):2082–2102, 2013
Laurent Jacques, Jason N Laska, Petros T Boufounos, and Richard G Baraniuk. Robust 1- bit compressive sensing via binary stable embeddings of sparse vectors.IEEE Transactions on Information Theory, 59(4):2082–2102, 2013
2082
-
[15]
The implicit bias of gradient descent on nonseparable data
Ziwei Ji and Matus Telgarsky. The implicit bias of gradient descent on nonseparable data. In Conference on learning theory, pages 1772–1798. PMLR, 2019
2019
-
[16]
Efficient learning of gener- alized linear and single index models with isotonic regression.Advances in Neural Information Processing Systems, 24, 2011
Sham M Kakade, Varun Kanade, Ohad Shamir, and Adam Kalai. Efficient learning of gener- alized linear and single index models with isotonic regression.Advances in Neural Information Processing Systems, 24, 2011
2011
-
[17]
The isotron algorithm: High-dimensional isotonic regres- sion
Adam Tauman Kalai and Ravi Sastry. The isotron algorithm: High-dimensional isotonic regres- sion. InCOLT, volume 1, page 9, 2009
2009
-
[18]
Finite sample rates for logistic regression with small noise or few samples.Sankhya A, pages 1–70, 2024
Felix Kuchelmeister and Sara van de Geer. Finite sample rates for logistic regression with small noise or few samples.Sankhya A, pages 1–70, 2024
2024
-
[19]
Springer
Michel Ledoux and Michel Talagrand.Probability in Banach Spaces: isoperimetry and processes, volume 23. Springer
-
[20]
On the sample complexity of pac learning half-spaces against the uniform distribution.IEEE Transactions on Neural Networks, 6(6):1556–1559, 1995
Philip M Long. On the sample complexity of pac learning half-spaces against the uniform distribution.IEEE Transactions on Neural Networks, 6(6):1556–1559, 1995
1995
-
[21]
Robust multivariate mean estimation: The optimality of trimmed mean.The Annals of Statistics, 49(1):393–410, 2021
Gábor Lugosi and Shahar Mendelson. Robust multivariate mean estimation: The optimality of trimmed mean.The Annals of Statistics, 49(1):393–410, 2021. 12
2021
-
[22]
Binary iterative hard thresholding converges with optimal number of measurements for 1-bit compressed sensing.Journal of the ACM, 71(5):1–64, 2024
Namiko Matsumoto and Arya Mazumdar. Binary iterative hard thresholding converges with optimal number of measurements for 1-bit compressed sensing.Journal of the ACM, 71(5):1–64, 2024
2024
-
[23]
Learning sparse generalized linear models with binary outcomes via iterative hard thresholding
Namiko Matsumoto and Arya Mazumdar. Learning sparse generalized linear models with binary outcomes via iterative hard thresholding. InProceedings of Thirty Eighth Conference on Learning Theory, volume 291 ofProceedings of Machine Learning Research, pages 3933–4032. PMLR, 30 Jun–04 Jul 2025
2025
-
[24]
Nelder.Generalized linear models
Peter McCullagh and John A. Nelder.Generalized linear models. Routledge, 2019
2019
-
[25]
Si Yi Meng, Baptiste Goujaud, Antonio Orvieto, and Christopher De Sa. Gradient descent on logistic regression: Do large step-sizes work with data on the sphere?arXiv preprint arXiv:2507.11228, 2025
arXiv 2025
-
[26]
Si Yi Meng, Antonio Orvieto, Daniel Yiming Cao, and Christopher De Sa. Gradient descent on logistic regression with non-separable data and large step sizes.arXiv preprint arXiv:2406.05033, 2024
arXiv 2024
-
[27]
Convergence of gradient descent on separable data
Mor Shpigel Nacson, Jason Lee, Suriya Gunasekar, Pedro Henrique Pamplona Savarese, Nathan Srebro, and Daniel Soudry. Convergence of gradient descent on separable data. InThe 22nd International Conference on Artificial Intelligence and Statistics, pages 3420–3428. PMLR, 2019
2019
-
[28]
Springer, 2018
Yurii Nesterov et al.Lectures on convex optimization, volume 137. Springer, 2018
2018
-
[29]
Phase retrieval using alternating mini- mization.Advances in Neural Information Processing Systems, 26, 2013
Praneeth Netrapalli, Prateek Jain, and Sujay Sanghavi. Phase retrieval using alternating mini- mization.Advances in Neural Information Processing Systems, 26, 2013
2013
-
[30]
High-dimensionalestimationwithgeometric constraints.Information and Inference: A Journal of the IMA, 6(1):1–40, 2017
YanivPlan, RomanVershynin, andElenaYudovina. High-dimensionalestimationwithgeometric constraints.Information and Inference: A Journal of the IMA, 6(1):1–40, 2017
2017
-
[31]
Onpaclearningusingwinnow, perceptron, andaperceptron-likealgorithm
RoccoAServedio. Onpaclearningusingwinnow, perceptron, andaperceptron-likealgorithm. In Proceedings of the Twelfth Annual Conference on Computational learning theory, pages 296–307, 1999
1999
-
[32]
The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
2018
-
[33]
A bound for the error in the normal approximation to the distribution of a sum of dependent random variables
Charles Stein. A bound for the error in the normal approximation to the distribution of a sum of dependent random variables. InProceedings of the sixth Berkeley symposium on mathematical statistics and probability, volume 2: Probability theory, volume 6, pages 583–603. University of California Press, 1972
1972
-
[34]
Use of exchangeable pairs in the analysis of simulations.Lecture Notes-Monograph Series, pages 1–26, 2004
Charles Stein, Persi Diaconis, Susan Holmes, and Gesine Reinert. Use of exchangeable pairs in the analysis of simulations.Lecture Notes-Monograph Series, pages 1–26, 2004
2004
-
[35]
From logistic regression to the perceptron algorithm: Exploring gradient descent with large step sizes
Alexander Tyurin. From logistic regression to the perceptron algorithm: Exploring gradient descent with large step sizes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20938–20946, 2025. 13
2025
-
[36]
Cambridge University Press, 2018
Roman Vershynin.High-dimensional probability: An introduction with applications in data sci- ence, volume 47. Cambridge University Press, 2018
2018
-
[37]
Large stepsize gradient descent for logistic loss: Non-monotonicity of the loss improves optimization efficiency
Jingfeng Wu, Peter L Bartlett, Matus Telgarsky, and Bin Yu. Large stepsize gradient descent for logistic loss: Non-monotonicity of the loss improves optimization efficiency. InThe Thirty Seventh Annual Conference on Learning Theory, pages 5019–5073. PMLR, 2024
2024
-
[38]
Implicit bias of gradient descent for logistic regression at the edge of stability.Advances in Neural Information Processing Systems, 36:74229–74256, 2023
Jingfeng Wu, Vladimir Braverman, and Jason D Lee. Implicit bias of gradient descent for logistic regression at the edge of stability.Advances in Neural Information Processing Systems, 36:74229–74256, 2023
2023
-
[39]
Jingfeng Wu, Pierre Marion, and Peter Bartlett. Large stepsizes accelerate gradient descent for regularized logistic regression.arXiv preprint arXiv:2506.02336, 2025
arXiv 2025
-
[40]
Gradient descent converges arbitrarily fast for logistic regression via large and adaptive stepsizes
Ruiqi Zhang, Jingfeng Wu, and Peter Bartlett. Gradient descent converges arbitrarily fast for logistic regression via large and adaptive stepsizes. InForty-second International Conference on Machine Learning, 2025
2025
-
[41]
Ruiqi Zhang, Jingfeng Wu, Licong Lin, and Peter L Bartlett. Minimax optimal convergence of gradient descent in logistic regression via large and adaptive stepsizes.arXiv preprint arXiv:2504.04105, 2025. A Proof of Theorem 1 (GD with Small Stepsize) The main ingredient is an approximate invertibility condition (AIC) that controls ∥u−θ ∗ −η·h θ∗(u)∥2,∀u∈B d...
arXiv 2025
-
[42]
C.1 Bounding| ˆλ− ∥θ ∗∥2|(norm estimation error) In order to bound|ˆλ− ∥θ ∗∥2|= q−1(ˆv⊤ˆr)− ∥θ∗∥2 ,we shall start with bounding ˆv⊤ˆr−q(∥θ∗∥2)
In fact, by assuming the bound in Lemma 1 holds (this is within the probability promised in Theorem 3), then we have ∥θ∗∥2 ˆr− θ∗ ∥θ∗∥2 2 ≲polylog(n) r ∥θ∗∥2d n + ∥θ∗∥2d n .(70) In the remainder of this appendix, we focus on bounding the norm estimation error,|ˆλ− ∥θ ∗∥2|. C.1 Bounding| ˆλ− ∥θ ∗∥2|(norm estimation error) In order to bound|ˆλ− ∥θ ∗∥2|= q−1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.