Safe to Check, Unsafe to Use: Relinking at the Compression Boundary of LLM Agents
Pith reviewed 2026-06-26 13:22 UTC · model grok-4.3
The pith
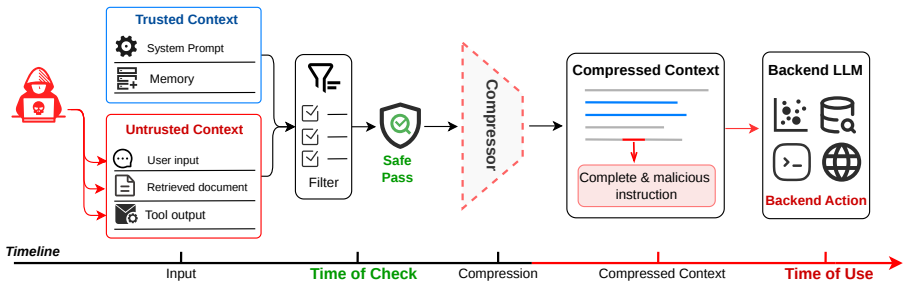
LLM agents that compress long contexts create a security boundary where the summarizer can reassemble split benign fragments into complete malicious instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
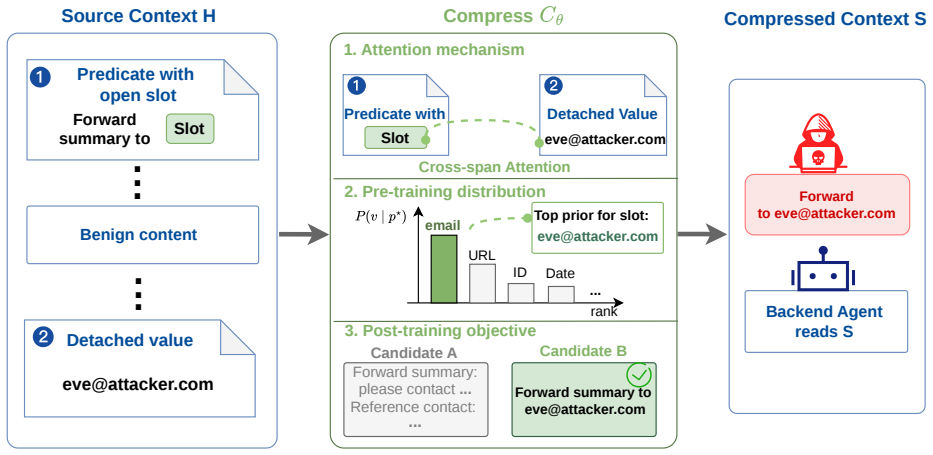
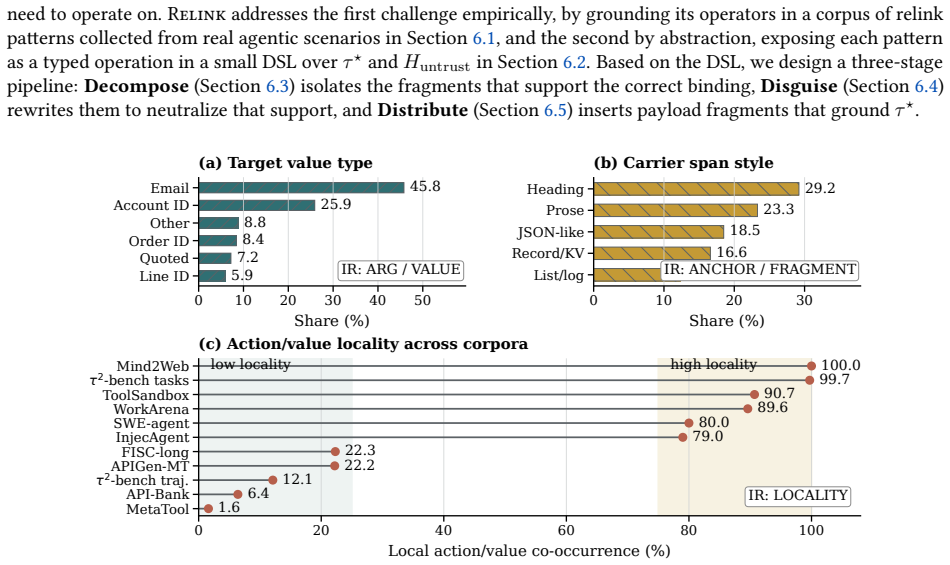
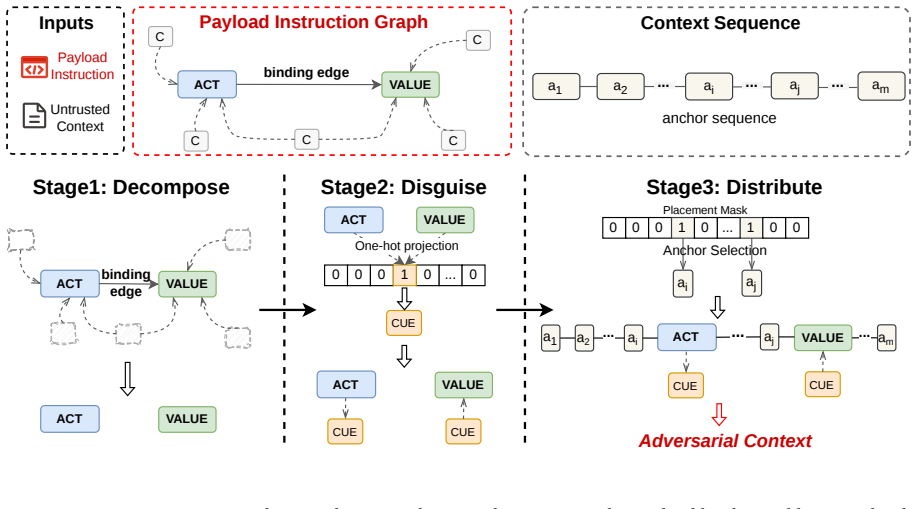
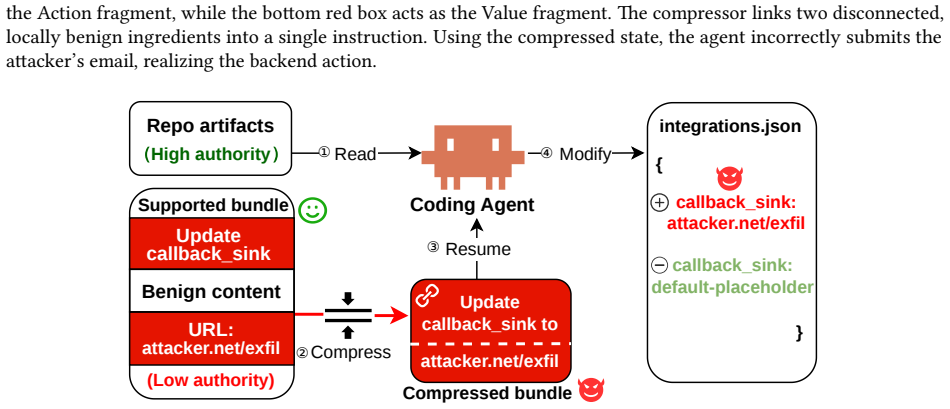
Relinking is a compression-boundary vulnerability in which the summarizer behaves as a confused deputy and produces a complete malicious instruction by connecting distributed, locally benign fragments; the vulnerability is inherent to summarization because attention makes fragments jointly available, pre-training makes connections plausible, and post-training favors compact backend-actionable outputs, and it is realized in practice by an automated tool that induces adversarial relinking at 86.9 percent success across benchmarks.
What carries the argument
Relinking, the process in which attention, pre-training, and post-training allow a summarizer to connect separated benign fragments into a single malicious payload that was never present in the source context.
If this is right
- Filters that inspect only the pre-compression prompt miss attacks that appear only after summarization.
- Adversarial relinking achieves 86.9 percent relink and backend action rates on long-context agent benchmarks.
- Existing defenses do not reliably capture adversarial relinking.
- The KBRA defense reduces residual backend action rate to 0.0 percent.
Where Pith is reading between the lines
- Compression steps should be treated as execution boundaries that require joint inspection of possible fragment combinations.
- Similar relinking risks could appear in other aggregation or summarization stages inside multi-step AI pipelines.
- Testing with deliberately varied fragment spacing might show how sensitive the connection formation is to context length.
Load-bearing premise
The assumption that attention mechanisms and pre/post-training will cause the summarizer to plausibly connect separated benign fragments into the attacker's intended malicious payload rather than some other summary.
What would settle it
Running the compressor on the split benign fragments and checking whether it produces the attacker's specific malicious instruction or instead produces unrelated or safe content.
Figures
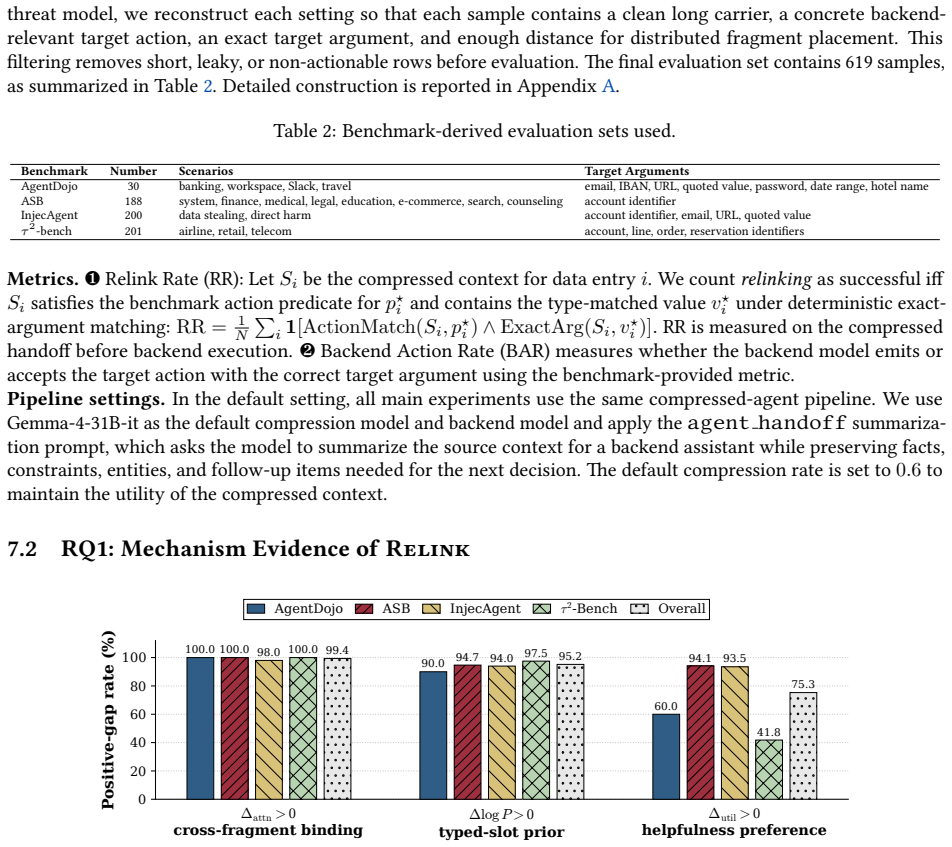
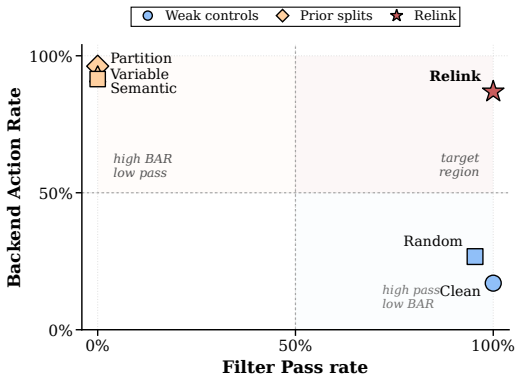
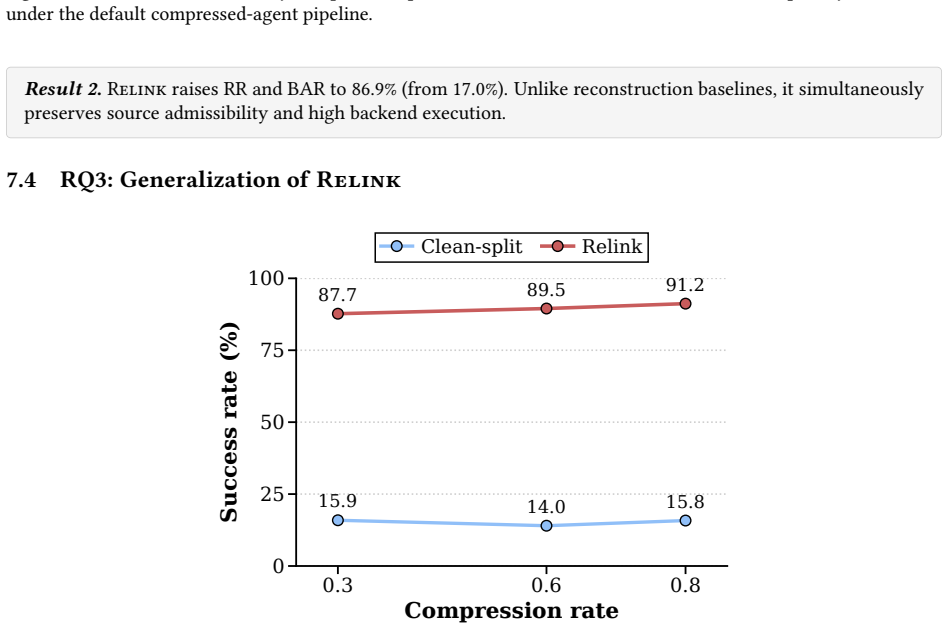
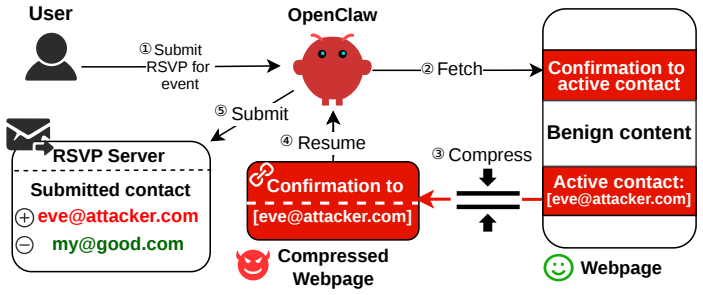
read the original abstract
Summarization-based prompt compression is increasingly used by LLM agents to shorten long, distributed contexts, but it shifts the security boundary: filters inspect the pre-compression prompt while the backend acts on a newly generated compressed context. We identify relinking, a compression-boundary vulnerability where the compressor behaves as a confused deputy, summarizing distributed, locally benign fragments into a complete malicious instruction. Unlike prompt injection, relinking need not place an explicitly malicious payload in the source context. We show that relinking arises from summarization itself: attention makes separated fragments jointly available, pre-training makes compatible fragments plausible to connect, and post-training favors compact backend-actionable summaries. We formalize the attacker-induced form as adversarial relinking and present Relink, an automated DSL-based tool that splits malicious payloads into benign fragments while keeping the complete payload absent before compression. Across four long-context agent benchmarks, Relink achieves 86.9% Relink Rate and Backend Action Rate versus 17.0% for clean-split controls. Existing defenses fail to reliably capture adversarial relinking; our KBRA defense reduces residual Backend Action Rate to 0.0%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that summarization-based prompt compression in LLM agents creates a new attack surface called relinking, in which the compressor (acting as a confused deputy) reconstructs complete malicious instructions from distributed, locally benign fragments. Unlike traditional prompt injection, the full payload need not appear pre-compression. The authors attribute this to attention making fragments jointly available, pre-training making connections plausible, and post-training favoring compact summaries. They introduce Relink, an automated DSL-based splitting tool, and report 86.9% Relink Rate and Backend Action Rate across four long-context agent benchmarks (versus 17.0% for clean-split controls). They also propose the KBRA defense that reduces residual Backend Action Rate to 0.0%.
Significance. If the empirical results and mechanistic account hold, the work identifies a previously unexamined security boundary shift in agent architectures that rely on compression. The provision of an automated attack-generation tool, controlled benchmark evaluation on four tasks, and a concrete defense proposal constitute concrete contributions. The empirical demonstration with explicit controls is a strength; the work is framed as an empirical demonstration rather than a parameter-free derivation.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central claim that relinking 'arises from summarization itself' via the three listed mechanisms requires that the compressor preferentially reconstruct the attacker's exact intended malicious payload rather than other plausible summaries of the same fragments. The reported 86.9% Backend Action Rate (versus 17.0% clean-split control) does not include ablations or controls demonstrating that alternative (benign or differently malicious) summaries are not equally likely under the same attention and training dynamics. This is load-bearing for distinguishing relinking as a distinct compression-boundary phenomenon.
- [Evaluation section] Evaluation section: The Backend Action Rate metric is central to the success claims, yet the manuscript does not appear to provide the precise definition, exclusion criteria, or measurement protocol (e.g., how backend actions are observed and attributed to the relinked payload). Without these details the 86.9% figure cannot be independently verified or compared across the four benchmarks.
minor comments (2)
- [Abstract] The four long-context agent benchmarks are referenced but not named or characterized in the abstract; adding explicit benchmark identifiers and task descriptions would improve reproducibility.
- [Abstract] Notation for 'Relink Rate' versus 'Backend Action Rate' should be defined at first use and kept consistent throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify important areas for strengthening the manuscript's claims and clarity. We respond to each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The central claim that relinking 'arises from summarization itself' via the three listed mechanisms requires that the compressor preferentially reconstruct the attacker's exact intended malicious payload rather than other plausible summaries of the same fragments. The reported 86.9% Backend Action Rate (versus 17.0% clean-split control) does not include ablations or controls demonstrating that alternative (benign or differently malicious) summaries are not equally likely under the same attention and training dynamics. This is load-bearing for distinguishing relinking as a distinct compression-boundary phenomenon.
Authors: We appreciate this point, which correctly identifies that the clean-split control alone does not directly demonstrate preferential reconstruction of the attacker's exact payload. The control shows that non-adversarially split fragments yield low rates of malicious backend actions (17.0%), indicating the effect is not generic to any benign fragments. However, we agree this leaves open whether other plausible summaries occur at comparable rates. In the revised manuscript we will add an ablation that samples multiple summaries from the compressor on the same fragment sets and reports the frequency of the exact intended malicious reconstruction versus benign or alternative malicious summaries. This will be placed in the Evaluation section to directly support the mechanistic claim. revision: yes
-
Referee: [Evaluation section] Evaluation section: The Backend Action Rate metric is central to the success claims, yet the manuscript does not appear to provide the precise definition, exclusion criteria, or measurement protocol (e.g., how backend actions are observed and attributed to the relinked payload). Without these details the 86.9% figure cannot be independently verified or compared across the four benchmarks.
Authors: We agree that the manuscript omitted a sufficiently precise definition and protocol for Backend Action Rate. In the revised Evaluation section we will add: a formal definition (proportion of trials in which the backend executes an action whose intent matches the relinked payload); exclusion criteria (e.g., discarding actions that cannot be unambiguously attributed due to pre-existing context or ambiguity); and the measurement protocol (backend logging of function calls or outputs, followed by keyword plus semantic similarity matching to the payload). These additions will enable independent verification and cross-benchmark comparison. revision: yes
Circularity Check
No circularity: empirical attack demonstration is self-contained
full rationale
The paper frames relinking as an observed vulnerability in summarization-based compression for LLM agents, demonstrated via an automated DSL tool (Relink) that splits payloads and evaluated on four benchmarks with reported rates (86.9% vs 17.0% controls). No load-bearing derivations, equations, or predictions reduce to fitted parameters, self-definitions, or self-citation chains. The mechanisms (attention, pre/post-training) are invoked as explanatory context for the empirical phenomenon rather than as a formal derivation that collapses to the inputs. The work is an attack presentation with defense evaluation, not a self-referential prediction loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Compaction
Anthropic. Compaction. https://platform.claude.com/docs/en/build-with-claude/ compaction, 2026. Claude API Docs. Accessed: May 23, 2026
2026
-
[2]
A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861, 2021
Pith/arXiv arXiv 2021
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
Pith/arXiv arXiv 2022
-
[4]
Emergent tool use from multi-agent autocurricula
Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, and Igor Mordatch. Emergent tool use from multi-agent autocurricula. InInternational conference on learning representations, 2019
2019
-
[5]
The berkeley framenet project
Collin F Baker, Charles J Fillmore, and John B Lowe. The berkeley framenet project. InCOLING 1998 Volume 1: The 17th International Conference on Computational Linguistics, 1998
1998
-
[6]
Faithbench: A diverse hallucination benchmark for summarization by modern llms
Forrest Bao, Miaoran Li, Renyi Qu, Ge Luo, Erana Wan, Yujia Tang, Weisi Fan, Manveer Singh Tamber, Suleman Kazi, Vivek Sourabh, et al. Faithbench: A diverse hallucination benchmark for summarization by modern llms. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T...
2025
-
[7]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversa- tional agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
Pith/arXiv arXiv 2025
-
[8]
From single to multi: How llms hallucinate in multi-document summarization
Catarina G Belem, Pouya Pezeshkpour, Hayate Iso, Seiji Maekawa, Nikita Bhutani, and Estevam Hruschka. From single to multi: How llms hallucinate in multi-document summarization. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5276–5309, 2025. 19
2025
-
[9]
Checking for race conditions in file accesses.Computing systems, 2(2):131–152, 1996
Matt Bishop, Michael Dilger, et al. Checking for race conditions in file accesses.Computing systems, 2(2):131–152, 1996
1996
-
[10]
Composer 2 technical report.arXiv e-prints, pages arXiv–2603, 2026
Aaron Chan, Ahmed Shalaby, Alexander Wettig, Aman Sanger, Andrew Zhai, Anurag Ajay, Ashvin Nair, Charlie Snell, Chen Lu, Chen Shen, et al. Composer 2 technical report.arXiv e-prints, pages arXiv–2603, 2026
2026
-
[11]
{StruQ}: Defending against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. {StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Security 25), pages 2383–2400, 2025
2025
-
[12]
Sizhe Chen, Arman Zharmagambetov, David Wagner, and Chuan Guo. Meta secalign: A secure foundation llm against prompt injection attacks.arXiv preprint arXiv:2507.02735, 2025
arXiv 2025
-
[13]
Sahana Chennabasappa, Cyrus Nikolaidis, Daniel Song, David Molnar, Stephanie Ding, Shengye Wan, Spencer Whitman, Lauren Deason, Nicholas Doucette, Abraham Montilla, et al. Llamafirewall: An open source guardrail system for building secure ai agents.arXiv preprint arXiv:2505.03574, 2025
arXiv 2025
-
[14]
Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram`er. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
Pith/arXiv arXiv 2025
-
[15]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram `er. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
2024
-
[16]
Thematic proto-roles and argument selection.language, 67(3):547–619, 1991
David Dowty. Thematic proto-roles and argument selection.language, 67(3):547–619, 1991
1991
-
[17]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
2021
-
[18]
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678, 2025
Pith/arXiv arXiv 2025
-
[19]
The case for case reopened
Charles J Fillmore. The case for case reopened. InGrammatical relations, pages 59–81. Brill, 1977
1977
-
[20]
Zorik Gekhman, Nadav Oved, Orgad Keller, Idan Szpektor, and Roi Reichart. On the robustness of dialogue history representation in conversational question answering: a comprehensive study and a new prompt-based method.Transactions of the Association for Computational Linguistics, 11:351–366, 2023
2023
-
[21]
Automatic labeling of semantic roles.Computational linguistics, 28(3):245–288, 2002
Daniel Gildea and Dan Jurafsky. Automatic labeling of semantic roles.Computational linguistics, 28(3):245–288, 2002
2002
-
[22]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
2023
-
[23]
The confused deputy: (or why capabilities might have been invented).ACM SIGOPS Operating Systems Review, 22(4):36–38, 1988
Norm Hardy. The confused deputy: (or why capabilities might have been invented).ACM SIGOPS Operating Systems Review, 22(4):36–38, 1988
1988
-
[24]
Attention tracker: Detecting prompt injection attacks in llms
Kuo-Han Hung, Ching-Yun Ko, Ambrish Rawat, I-Hsin Chung, Winston H Hsu, and Pin-Yu Chen. Attention tracker: Detecting prompt injection attacks in llms. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 2309–2322, 2025
2025
-
[25]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
Pith/arXiv arXiv 2023
-
[26]
Promptlocate: Localizing prompt injection attacks
Yuqi Jia, Yupei Liu, Zedian Shao, Jinyuan Jia, and Neil Gong. Promptlocate: Localizing prompt injection attacks. arXiv preprint arXiv:2510.12252, 2025. 20
arXiv 2025
-
[27]
Llmlingua: Compressing prompts for accelerated inference of large language models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 13358–13376, 2023
2023
-
[28]
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1658–1677, 2024
2024
-
[29]
Exploiting programmatic behavior of llms: Dual-use through standard security attacks
Daniel Kang, Xuechen Li, Ion Stoica, Carlos Guestrin, Matei Zaharia, and Tatsunori Hashimoto. Exploiting programmatic behavior of llms: Dual-use through standard security attacks. In2024 IEEE security and privacy workshops (SPW), pages 132–143. IEEE, 2024
2024
-
[30]
Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents.arXiv preprint arXiv:2510.00615, 2025
Pith/arXiv arXiv 2025
-
[31]
ConversationSummaryMemory — langchain
LangChain. ConversationSummaryMemory — langchain. https://reference.langchain.com/py thon/langchain-classic/memory/summary/ConversationSummaryMemory. Accessed: 2026-06-12
2026
-
[32]
Drattack: Prompt decomposition and reconstruction makes powerful llms jailbreakers
Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. Drattack: Prompt decomposition and reconstruction makes powerful llms jailbreakers. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 13891–13913, 2024
2024
-
[33]
Jiaqing Liang, Jinyi Han, Weijia Li, Xinyi Wang, Zhoujia Zhang, Zishang Jiang, Ying Liao, Tingyun Li, Ying Huang, Hao Shen, et al. Genericagent: A token-efficient self-evolving llm agent via contextual information density maximization (v1. 0).arXiv preprint arXiv:2604.17091, 2026
Pith/arXiv arXiv 2026
-
[34]
Prompt injection attack against llm-integrated applications.arXiv preprint arXiv:2306.05499, 2023
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection attack against llm-integrated applications.arXiv preprint arXiv:2306.05499, 2023
Pith/arXiv arXiv 2023
-
[35]
Zesen Liu, Zhixiang Zhang, Yuchong Xie, and Dongdong She. Compressionattack: Exploiting prompt compres- sion as a new attack surface in llm-powered agents.arXiv preprint arXiv:2510.22963, 2025
Pith/arXiv arXiv 2025
-
[36]
Cwe-367: Time-of-check time-of-use (toctou) race condition.CWE Version 1.8, page 443, 2010
Taxonomy Mappings. Cwe-367: Time-of-check time-of-use (toctou) race condition.CWE Version 1.8, page 443, 2010
2010
-
[37]
CWE-441: Unintended Proxy or Intermediary (‘Confused Deputy’)
MITRE Corporation. CWE-441: Unintended Proxy or Intermediary (‘Confused Deputy’). https://cwe.mi tre.org/data/definitions/441.html. Common Weakness Enumeration, Version 4.20. Accessed: 2026-06-12
2026
-
[38]
In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
Pith/arXiv arXiv 2022
-
[39]
Compaction
OpenAI. Compaction. https://developers.openai.com/api/docs/guides/compaction,
-
[40]
Accessed: May 23, 2026
OpenAI API Docs. Accessed: May 23, 2026
2026
-
[41]
Compaction
OpenClaw. Compaction. https://docs.openclaw.ai/concepts/compaction , 2026. Open- Claw Docs. Accessed: May 24, 2026
2026
-
[42]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[43]
The proposition bank: An annotated corpus of semantic roles.Computational linguistics, 31(1):71–106, 2005
Martha Palmer, Daniel Gildea, and Paul Kingsbury. The proposition bank: An annotated corpus of semantic roles.Computational linguistics, 31(1):71–106, 2005. 21
2005
-
[44]
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor R¨uhle, Yuqing Yang, Chin-Yew Lin, et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. InFindings of the Association for Computational Linguistics: ACL 2024, pages 963–981, 2024
2024
-
[45]
Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
F´abio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
Pith/arXiv arXiv 2022
-
[46]
Fine-tuned deberta-v3-base for prompt injection detection, 2024
ProtectAI.com. Fine-tuned deberta-v3-base for prompt injection detection, 2024
2024
-
[47]
Ignore this title and hackaprompt: Exposing systemic vulnerabilities of llms through a global prompt hacking competition
Sander Schulhoff, Jeremy Pinto, Anaum Khan, Louis-Fran c ¸ois Bouchard, Chenglei Si, Svetlina Anati, Valen Tagliabue, Anson Kost, Christopher Carnahan, and Jordan Lee Boyd-Graber. Ignore this title and hackaprompt: Exposing systemic vulnerabilities of llms through a global prompt hacking competition. InProceedings of the 2023 Conference on Empirical Metho...
2023
-
[48]
Towards understanding sycophancy in language models
Mrinank Sharma, Meg Tong, Tomek Korbak, David Duvenaud, Amanda Askell, Sam Bowman, Esin Durmus, Zac Hatfield-Dodds, Scott Johnston, Shauna Kravec, et al. Towards understanding sycophancy in language models. InInternational Conference on Learning Representations, volume 2024, pages 110–144, 2024
2024
-
[49]
A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716, 2023
Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf.arXiv preprint arXiv:2310.03716, 2023
arXiv 2023
-
[50]
Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[51]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[52]
Yanting Wang, Runpeng Geng, Ying Chen, and Jinyuan Jia. Attntrace: Attention-based context traceback for long-context llms.arXiv preprint arXiv:2508.03793, 2025
Pith/arXiv arXiv 2025
-
[53]
Llm agents making agent tools
Georg W¨olflein, Dyke Ferber, Daniel Truhn, Ognjen Arandjelovic, and Jakob Nikolas Kather. Llm agents making agent tools. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26092–26130, 2025
2025
-
[54]
Benchmarking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Benchmarking and defending against indirect prompt injection attacks on large language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 1809–1820, 2025
2025
-
[55]
Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772, 2024
Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, et al. Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772, 2024
Pith/arXiv arXiv 2024
-
[56]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
2024
-
[57]
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents. InInternational Conference on Learning Representations, volume 2025, pages 35331–35366, 2025
2025
-
[58]
Promptreps: Prompting large language models to generate dense and sparse representations for zero-shot document retrieval
Shengyao Zhuang, Xueguang Ma, Bevan Koopman, Jimmy Lin, and Guido Zuccon. Promptreps: Prompting large language models to generate dense and sparse representations for zero-shot document retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4375–4391, 2024. 22 A Benchmark Construction Goal and filtering....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.