Learning the ARTS of Search for Automated Discovery
Pith reviewed 2026-06-26 12:01 UTC · model grok-4.3
The pith
A reasoning language model improves hypothesis search by diagnosing execution logs to separate faulty implementations from bad ideas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
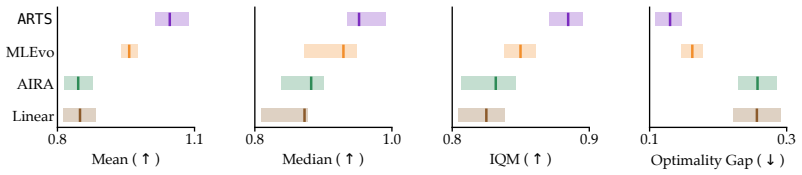
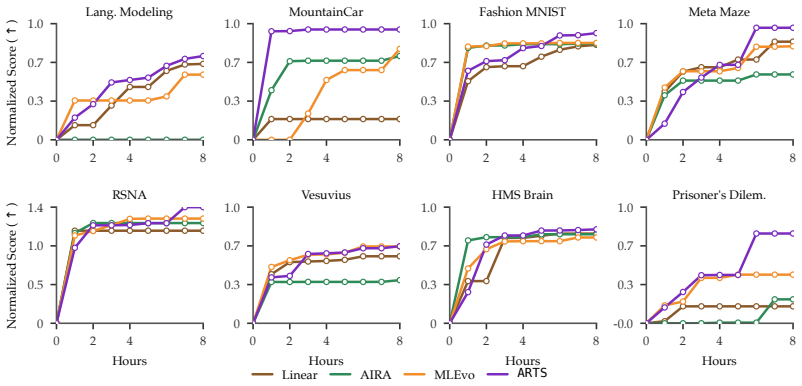
ARTS deploys a reasoning language model to inspect prior execution logs, diagnose whether earlier failures arose from faulty implementations or bad hypotheses, and select the hypothesis to build on next. Test-time training instills the knowledge of the search tree in the model weights to handle growing context. Across 22 tasks from MLGym and MLEBench, ARTS outperforms leading algorithms with over 15.3 percent relative improvement in the normalized score. With test-time training a Qwen3-4B agent matches closed-source frontier models like Gemini-3 Pro and GPT o3-reasoning with up to 5x lower inference cost. On partially observable RL tasks the test-time trained Qwen3-4B scientist surpasses ART
What carries the argument
Agentic Reasoning for Tree Search (ARTS): a reasoning language model that reads full execution logs to diagnose whether failures stem from bad hypotheses or faulty implementations, then chooses the next hypothesis, with test-time training used to encode the search tree into the model weights.
If this is right
- ARTS raises normalized scores by more than 15.3 percent over leading algorithms on 22 tasks from MLGym and MLEBench.
- A 4B-parameter open model with test-time training reaches the performance of closed-source frontier models at up to 5x lower inference cost.
- On partially observable RL tasks the same small model rediscovers the human-best recurrent-memory solution that standard heuristics discard.
Where Pith is reading between the lines
- The diagnosis step could be added to other iterative search procedures that currently rely only on reward signals.
- Test-time training of search history may prove useful for any long-horizon reasoning task that outgrows fixed context windows.
- Similar log-based diagnosis might reduce wasted experiments in non-ML domains such as automated chemistry or materials design.
Load-bearing premise
A reasoning language model can accurately tell from execution logs alone whether a previous failure was caused by a bad hypothesis or merely by a faulty implementation.
What would settle it
On the same 22 tasks, replace the model's diagnosis step with random selection of the next hypothesis and measure whether the 15.3 percent normalized-score gain disappears.
Figures






read the original abstract
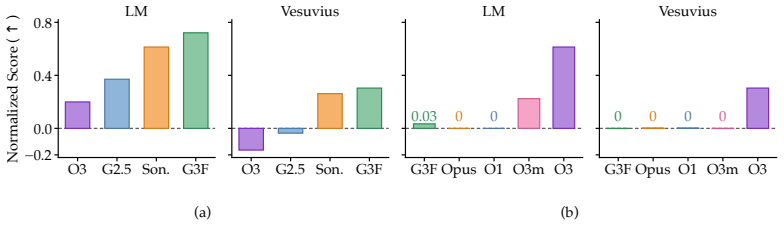
Scientific discovery can be formulated as an iterative search process over the space of hypotheses and experiments. Contemporary methods navigate this space using heuristics such as MCTS. These algorithms conflate the merit of a hypothesis with the quality of its experimental execution. A promising hypothesis with preliminary execution is therefore ranked below a modest hypothesis whose execution is refined. Moreover, prior methods prune the search logs as the search progresses because the accumulated history outgrows the context window. We propose Agentic Reasoning for Tree Search (ARTS), where we deploy a reasoning language model to navigate this space. The model inspects prior execution logs, diagnoses whether earlier failures arose from faulty implementations or bad hypotheses, and selects the hypothesis to build on next. To mitigate challenges with context length, ARTS uses test-time training to instill the knowledge of search tree in the model weights. Across 22 tasks from MLGym and MLEBench, we show that ARTS outperforms leading algorithms, with over 15.3% relative improvement in the normalized score. With test-time training we show that a Qwen3-4B agent can match performance with closed-source frontier models like Gemini-3 Pro and GPT o3-reasoning with upto 5x lower inference cost. We further observe that on partially observable RL tasks, the test-time trained Qwen3-4B scientist surpasses ARTS with the o3 scientist by rediscovering the human-best recurrent-memory solution that heuristic methods prune away.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Agentic Reasoning for Tree Search (ARTS), in which a reasoning LM inspects execution logs to diagnose whether prior failures stem from faulty implementations or flawed hypotheses and then selects the next hypothesis to pursue. Test-time training is used to embed search-tree knowledge into model weights and mitigate context-length limits. On 22 tasks drawn from MLGym and MLEBench the method is reported to deliver >15.3% relative improvement in normalized score over leading baselines; a test-time-trained Qwen3-4B agent is claimed to match closed-source frontier models (Gemini-3 Pro, o3) at up to 5× lower inference cost and, on partially observable RL tasks, to rediscover human-best recurrent-memory solutions that heuristic search prunes.
Significance. If the performance claims prove robust, the separation of hypothesis quality from execution quality via explicit diagnosis would constitute a substantive advance over MCTS-style search for automated discovery. The demonstration that test-time training enables a 4B open model to match much larger closed models is potentially impactful for cost and accessibility. The absence of any quantitative validation of the diagnosis step, however, leaves the source of the reported gains unclear and therefore limits the assessed significance at present.
major comments (3)
- [Experimental results] Experimental results (abstract and §4): the central claims of 15.3% relative improvement and frontier-model parity rest on point estimates without error bars, statistical significance tests, or any description of how the 22 tasks were selected or how scores were normalized.
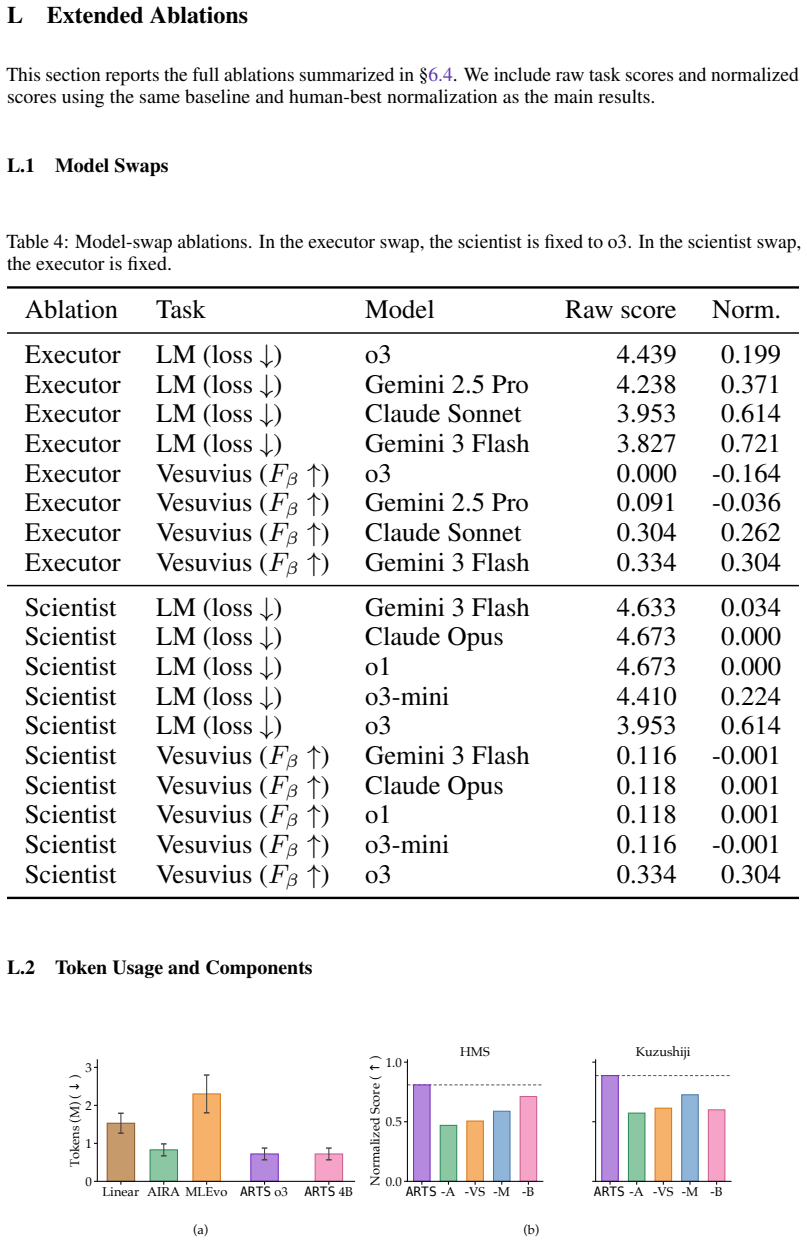
- [Experimental results] Experimental results (abstract and §4): no ablation isolates the contribution of the LM diagnosis step from the test-time training component, so it is impossible to determine whether the reported gains derive from the core innovation or from test-time training alone.
- [Method description] Method description (abstract and §3): the paper provides no quantitative evaluation of diagnosis quality (human agreement, accuracy on held-out logs, or correlation between diagnosis correctness and downstream success), which is the load-bearing assumption distinguishing ARTS from heuristic or MCTS baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting needs for greater statistical rigor and validation of key components. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: Experimental results (abstract and §4): the central claims of 15.3% relative improvement and frontier-model parity rest on point estimates without error bars, statistical significance tests, or any description of how the 22 tasks were selected or how scores were normalized.
Authors: We agree that the current results would benefit from additional statistical detail. In the revision we will report means and standard deviations across three independent runs per task (varying random seeds for both the search and test-time training), include Wilcoxon signed-rank tests for significance against baselines, describe the task selection (all 22 tasks from MLGym and MLEBench that provide executable environments and ground-truth metrics), and explicitly state the normalization procedure (per-task min-max scaling to [0,1] using the range of scores observed across all evaluated methods). revision: yes
-
Referee: Experimental results (abstract and §4): no ablation isolates the contribution of the LM diagnosis step from the test-time training component, so it is impossible to determine whether the reported gains derive from the core innovation or from test-time training alone.
Authors: This is a fair criticism. The revised §4 will contain two new ablation studies: (i) ARTS with the diagnosis step replaced by standard MCTS value estimation, and (ii) a non-ARTS baseline agent equipped with the same test-time training procedure. These comparisons will quantify the incremental benefit of the explicit diagnosis mechanism over test-time training alone. revision: yes
-
Referee: Method description (abstract and §3): the paper provides no quantitative evaluation of diagnosis quality (human agreement, accuracy on held-out logs, or correlation between diagnosis correctness and downstream success), which is the load-bearing assumption distinguishing ARTS from heuristic or MCTS baselines.
Authors: We accept that direct validation of the diagnosis step strengthens the central claim. The revision will add a new subsection in §3 reporting: (a) human evaluation on a random sample of 100 execution logs with two annotators, including Cohen’s kappa for inter-annotator agreement, (b) accuracy of the model’s diagnoses against the human labels, and (c) correlation between diagnosis correctness and subsequent improvement in normalized task score. These metrics will be presented alongside the end-to-end results. revision: yes
Circularity Check
No circularity: empirical method evaluated on external fixed benchmarks
full rationale
The paper proposes the ARTS algorithm as an agentic search procedure that deploys a reasoning LM to inspect execution logs and diagnose failure causes, then reports normalized-score gains on 22 fixed tasks from MLGym and MLEBench against external baselines. No equations, derivations, or first-principles predictions appear; performance is measured by direct empirical comparison on held-out benchmarks whose success criteria are independent of the method's internal diagnosis step. No self-citation chains, fitted parameters renamed as predictions, or self-definitional loops are present. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning at the edge of the statistical precipice
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron Courville, and Marc G Belle- mare. Deep reinforcement learning at the edge of the statistical precipice. Advances in Neural Information Processing Systems, 2021
2021
-
[2]
The surprising effectiveness of test-time training for few-shot learning
Ekin Akyürek, Mehul Damani, Adam Zweiger, Linlu Qiu, Han Guo, Jyothish Pari, Yoon Kim, and Jacob Andreas. The surprising effectiveness of test-time training for few-shot learning. In Forty-second International Conference on Machine Learning, 2025. URL https: //openreview.net/forum?id=asgBo3FNdg
2025
-
[3]
Seungju Back, Dongwoo Lee, Naun Kang, Taehee Lee, S. K. Hong, Youngjune Gwon, and Sungjin Ahn. Understanding lora as knowledge memory: An empirical analysis, 2026. URL https://arxiv.org/abs/2603.01097
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models. Nature, 624:570–578, 2023
2023
-
[5]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016. URLhttps://arxiv.org/abs/1606.01540
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Toward understanding in-context vs
Bryan Chan, Xinyi Chen, András György, and Dale Schuurmans. Toward understanding in-context vs. in-weight learning. In The Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=aKJr5NnN8U
2025
-
[7]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M ˛ adry. Mle-bench: Evaluating machine learning agents on machine learning engineering, 2024. URL https://arxiv.org/abs/2410.07095
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
MARS: Modular Agent with Reflective Search for Automated AI Research
Jiefeng Chen, Bhavana Dalvi Mishra, Jaehyun Nam, Rui Meng, Tomas Pfister, and Jinsung Yoon. Mars: Modular agent with reflective search for automated ai research, 2026. URL https://arxiv.org/abs/2602.02660
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Sela: Tree-search enhanced llm agents for automated machine learning, 2024
Yizhou Chi, Yizhang Lin, Sirui Hong, Duyi Pan, Yaying Fei, Guanghao Mei, Bangbang Liu, Tianqi Pang, Jacky Kwok, Ceyao Zhang, Bang Liu, and Chenglin Wu. Sela: Tree-search enhanced llm agents for automated machine learning, 2024. URL https://arxiv.org/abs/ 2410.17238
-
[10]
Arc prize 2024: Technical report, 2025
Francois Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. Arc prize 2024: Technical report, 2025. URLhttps://arxiv.org/abs/2412.04604
-
[11]
Dean De Cock. Ames, iowa: Alternative to the boston housing data as an end of semester regression project. Journal of Statistics Education, 19(3), 2011. doi: 10.1080/10691898.2011. 11889627. URLhttps://doi.org/10.1080/10691898.2011.11889627
-
[12]
Gemini 3 flash, 2025
Google DeepMind. Gemini 3 flash, 2025. URL https://deepmind.google/models/ gemini/flash/
2025
-
[13]
MLEvolve: An autonomous system for end-to-end machine learning algorithm design and optimization.https: //github.com/InternScience/MLEvolve, 2026
Shangheng Du, Xiangchao Yan, Shiyang Feng, Bo Zhang, Lei Bai, et al. MLEvolve: An autonomous system for end-to-end machine learning algorithm design and optimization.https: //github.com/InternScience/MLEvolve, 2026. GitHub repository
2026
-
[14]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewart, Bogdan Grechuk, Tetiana Grechuk, S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, 12...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[17]
Llm-first search: Self-guided exploration of the solution space, 2025
Nathan Herr, Tim Rocktäschel, and Roberta Raileanu. Llm-first search: Self-guided exploration of the solution space, 2025. URLhttps://arxiv.org/abs/2506.05213
-
[18]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?, 2024. URLhttps://arxiv.org/abs/2404.06654
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
2022
-
[20]
Mlagentbench: Evaluating language agents on machine learning experimentation, 2024
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation, 2024. URL https://arxiv.org/abs/2310. 03302
2024
-
[21]
Multi-turn code generation through single-step re- wards
Arnav Kumar Jain, Gonzalo Gonzalez-Pumariega, Wayne Chen, Alexander M Rush, Went- ing Zhao, and Sanjiban Choudhury. Multi-turn code generation through single-step re- wards. In Forty-second International Conference on Machine Learning, 2025. URL https: //openreview.net/forum?id=aJeLhLcsh0
2025
-
[22]
AIDE: AI-Driven Exploration in the Space of Code
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code, 2025. URL https: //arxiv.org/abs/2502.13138
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Titanic - machine learning from disaster, 2012
Kaggle. Titanic - machine learning from disaster, 2012. URL https://www.kaggle.com/c/ titanic. Kaggle competition. Accessed: 2026-05-07. 13
2012
-
[24]
Histopathologic cancer detection, 2018
Kaggle. Histopathologic cancer detection, 2018. URL https://www.kaggle.com/ competitions/histopathologic-cancer-detection. Kaggle competition. Accessed: 2026-05-07
2018
-
[25]
Toxic comment classification challenge, 2018
Kaggle. Toxic comment classification challenge, 2018. URL https://www.kaggle.com/ competitions/jigsaw-toxic-comment-classification-challenge . Kaggle competi- tion. Accessed: 2026-05-07
2018
-
[26]
APTOS 2019 blindness detection, 2019
Kaggle. APTOS 2019 blindness detection, 2019. URL https://www.kaggle.com/ competitions/aptos2019-blindness-detection. Kaggle competition. Accessed: 2026- 05-07
2019
-
[27]
RSNA-MICCAI brain tumor radiogenomic classifica- tion, 2021
Kaggle. RSNA-MICCAI brain tumor radiogenomic classifica- tion, 2021. URL https://www.kaggle.com/competitions/ rsna-miccai-brain-tumor-radiogenomic-classification . Kaggle competition. Accessed: 2026-05-07
2021
-
[28]
Spaceship titanic, 2022
Kaggle. Spaceship titanic, 2022. URL https://www.kaggle.com/competitions/ spaceship-titanic. Kaggle competition. Accessed: 2026-05-07
2022
-
[29]
Vesuvius challenge - ink detection, 2023
Kaggle. Vesuvius challenge - ink detection, 2023. URL https://www.kaggle.com/ competitions/vesuvius-challenge-ink-detection . Kaggle competition. Accessed: 2026-05-07
2023
-
[30]
HMS - harmful brain activity classification, 2024
Kaggle. HMS - harmful brain activity classification, 2024. URL https://www.kaggle.com/ competitions/hms-harmful-brain-activity-classification . Kaggle competition. Accessed: 2026-05-07
2024
-
[31]
autoresearch: AI agents running research on single-GPU nanochat train- ing automatically
Andrej Karpathy. autoresearch: AI agents running research on single-GPU nanochat train- ing automatically. https://github.com/karpathy/autoresearch, March 2026. GitHub repository
2026
-
[32]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Techni- cal report, University of Toronto, 2009. URL https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf
2009
-
[33]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution, 2025. URL https://arxiv.org/abs/2509.19349
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
I-mcts: Enhancing agentic automl via introspective monte carlo tree search, 2026
Zujie Liang, Feng Wei, Wujiang Xu, Lin Chen, Yuxi Qian, and Xinhui Wu. I-mcts: Enhancing agentic automl via introspective monte carlo tree search, 2026. URL https://arxiv.org/ abs/2502.14693
-
[35]
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024. doi: 10.1162/tacl_a_00638. URLhttps://aclanthology.org/2024.tacl-1.9/
-
[36]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024. URL https: //arxiv.org/abs/2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Discoverybench: Towards data-driven discovery with large language mod- els
Bodhisattwa Prasad Majumder, Harshit Surana, Dhruv Agarwal, Bhavana Dalvi Mishra, Abhijeetsingh Meena, Aryan Prakhar, Tirth V ora, Tushar Khot, Ashish Sabharwal, and Peter Clark. Discoverybench: Towards data-driven discovery with large language mod- els. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.n...
2025
-
[38]
MLGym: A new framework and benchmark for advancing AI research agents
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Mikhail Plekhanov, Amar Budhiraja, Despoina Magka, Vladislav V orotilov, Gaurav Chaurasia, Dieuwke Hupkes, Ricardo Silveira Cabral, Tatiana Shavrina, Jakob Nicolaus Foerster, Yoram Bachrach, William Yang Wang, and Roberta Raileanu. MLGym: A new framework and ben...
-
[39]
URLhttps://openreview.net/forum?id=ryTr83DxRq. 14
-
[40]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Introducing openai o3 and o4-mini, Apr 2025
OpenAI. Introducing openai o3 and o4-mini, Apr 2025. URL https://openai.com/index/ introducing-o3-and-o4-mini/
2025
-
[42]
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems...
-
[43]
To backtrack or not to backtrack: When sequential search limits model reasoning, 2025
Tian Qin, David Alvarez-Melis, Samy Jelassi, and Eran Malach. To backtrack or not to backtrack: When sequential search limits model reasoning, 2025. URL https://arxiv.org/ abs/2504.07052
-
[44]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URLhttps://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve
2025
-
[46]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Towards execution-grounded automated ai research, 2026
Chenglei Si, Zitong Yang, Yejin Choi, Emmanuel Candès, Diyi Yang, and Tatsunori Hashimoto. Towards execution-grounded automated ai research, 2026. URL https://arxiv.org/abs/ 2601.14525
-
[48]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): Rnns with expressive hidden states, 2025. URL https: //arxiv.org/abs/2407.04620
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Ghiringhelli, Takenori Yamamoto, Yury Lysogorskiy, Lars Blu- menthal, Thomas Hammerschmidt, Jacek R
Christopher Sutton, Luca M. Ghiringhelli, Takenori Yamamoto, Yury Lysogorskiy, Lars Blu- menthal, Thomas Hammerschmidt, Jacek R. Golebiowski, Xiangyue Liu, Angelo Ziletti, and Matthias Scheffler. Crowd-sourcing materials-science challenges with the NOMAD 2018 Kag- gle competition. npj Computational Materials, 5:111, 2019. doi: 10.1038/s41524-019-0239-3. U...
-
[50]
The plant pathology challenge 2020 data set to classify foliar disease of apples
Ranjita Thapa, Kai Zhang, Noah Snavely, Serge Belongie, and Awais Khan. The plant pathology challenge 2020 data set to classify foliar disease of apples. Applications in Plant Sciences, 8(9):e11390, 2020. doi: https://doi.org/10.1002/aps3.11390. URL https: //bsapubs.onlinelibrary.wiley.com/doi/abs/10.1002/aps3.11390
-
[51]
AI research agents for machine learning: Search, exploration, and generalization in MLE-bench
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, RISHI HAZRA, Nicolas Baldwin, Alexis Audran-Reiss, Michael Kuchnik, Despoina Magka, Minqi Jiang, Alisia Maria Lupidi, Andrei Lupu, Roberta Raileanu, Tatiana Shavrina, Kelvin Niu, Jean-Christophe Gagnon-Audet, Michael Shvartsman, Shagun Sodhani, Alexander H Miller, Abhishek Charnalia, Derek Dun- field, Ca...
2026
-
[52]
Amplifying human performance in combinatorial competitive programming, 2024
Petar Veliˇckovi´c, Alex Vitvitskyi, Larisa Markeeva, Borja Ibarz, Lars Buesing, Matej Ba- log, and Alexander Novikov. Amplifying human performance in combinatorial competitive programming, 2024. URLhttps://arxiv.org/abs/2411.19744
-
[53]
Group-evolving agents: Open-ended self-improvement via experience sharing
Zhaotian Weng, Antonis Antoniades, Deepak Nathani, Zhen Zhang, Xiao Pu, and Xin Eric Wang. Group-evolving agents: Open-ended self-improvement via experience sharing, 2026. URLhttps://arxiv.org/abs/2602.04837
-
[54]
Hjalmar Wijk, Tao Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Josh Clymer, Jai Dhyani, Elena Ericheva, Katharyn Garcia, Brian Goodrich, Nikola Jurkovic, Holden Karnofsky, Megan Kinniment, Aron Lajko, Seraphina Nix, Lucas Sato, William Saunders, Maksym Taran, Ben West, and Elizabeth Barnes. Re-bench: Evaluating...
-
[55]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017. URL https://arxiv.org/abs/1708. 07747
2017
-
[56]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 11809–11822. Curran Associates, Inc.,...
2023
-
[58]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
MinAtar: An Atari-Inspired Testbed for Thorough and Reproducible Reinforcement Learning Experiments
Kenny Young and Tian Tian. Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments, 2019. URLhttps://arxiv.org/abs/1903.03176
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[60]
Learning to Discover at Test Time
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time, 2026. URLhttps://arxiv.org/abs/2601.16175
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity, 2026
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael Tomz, Christopher D Manning, and Weiyan Shi. Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity, 2026. URLhttps://openreview.net/forum?id=9jQkmGunGo
2026
-
[62]
the next logical leap
Stephen Zhang, Mustafa Khan, and Vardan Papyan. Attention sinks: A ’catch, tag, release’ mechanism for embeddings. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=r8UWp9JeJi. 16 Appendix Contents AHMS Search Trajectory:ARTSvs. AIRA . . . . . . . . . . . . . . . . . . . . . . . . . . ...
2026
-
[63]
CanARTSseparate a promising hypothesis from a bad execution?
-
[64]
Does auditing identify the root cause of failed or regressed experiments?
-
[65]
Does the scientist reason from logs rather than only follow final scores?
-
[66]
Does reasoning-based parent selection spend budget better than heuristic selection?
-
[67]
Can the scientist propose directions that are not already in the tree?
-
[68]
Does verbalized sampling preserve enough diversity?
-
[69]
why” with “that
How do baselines fail differently under the same budget? We answer each question separately below. F.1 CanARTSseparate a promising hypothesis from a bad execution? Answer: yes.The logs show that ARTS often preserves a promising hypothesis after a flawed implementation. On HMS Brain Activity, the task is to predict seizure-related activity from EEG spectro...
2019
-
[70]
Lets you understand EXACTLY what was tried and why it succeeded or failed
INSPECT nodes -- see the actual commands and output the executor ran for any node. Lets you understand EXACTLY what was tried and why it succeeded or failed
-
[71]
CatBoost (0.91) + LightGBM (0.90) plateau -- try feature engineering next
READ files -- see the contents of any workspace file (e.g. target.py, evaluate.py, baseline.py, strategy.py). Lets you understand the task code, opponent strategy, evaluation logic, or data format before proposing an experiment. Respond in EXACTLY this format: INSPECT: node_id_1, node_id_2 [OR] INSPECT: NONE READ: filename1.py, filename2.py [OR] READ: NON...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.