Adding Robust Code-Switching Capabilities to High Performance Multilingual ASR
Pith reviewed 2026-06-26 11:59 UTC · model grok-4.3
The pith
Bayesian factorized adaptation integrates code-switching capabilities into multilingual ASR models while preserving monolingual performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
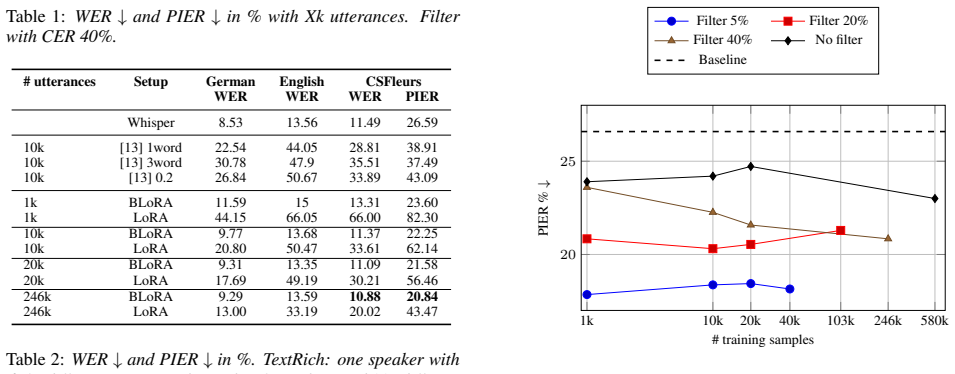
Bayesian factorized adaptation learns to efficiently integrate switching-relevant knowledge into strong pretrained models without overwriting existing capabilities. Requiring only a small amount of synthetic data, the approach reduces transcription errors by 32.87% on code-switched words while improving overall WER by 5.31%, all while maintaining mono-lingual performance. Results demonstrate that effective CSW adaptation depends more on knowledge integration than data complexity.
What carries the argument
Bayesian factorized adaptation, which learns to efficiently integrate switching-relevant knowledge into strong pretrained models without overwriting existing capabilities.
If this is right
- Reduces transcription errors by 32.87% on code-switched words
- Improves overall WER by 5.31%
- Maintains mono-lingual performance
- Requires only a small amount of synthetic data
- Effective CSW adaptation depends more on knowledge integration than data complexity
Where Pith is reading between the lines
- The same modular update strategy could extend to other multilingual speech tasks that involve language mixing.
- Targeted adaptation of this kind may lower reliance on large collections of real code-switched recordings.
- The results point toward modular parameter updates as a general route for adding new linguistic behaviors to large pretrained models.
- Real-world systems operating in bilingual communities could deploy such adaptations with minimal additional data collection.
Load-bearing premise
Bayesian factorized adaptation can efficiently integrate switching-relevant knowledge into strong pretrained models without overwriting existing monolingual capabilities when trained on limited synthetic data.
What would settle it
A held-out evaluation in which the adapted model shows higher error rates on monolingual test sets or fails to reduce code-switched word errors relative to the unadapted baseline.
Figures
read the original abstract
Code-switching (CSW) remains challenging for large multi-lingual ASR systems in real-world deployment. While fine-tuning on synthetic CSW data is possible, it generally degrades strong monolingual baselines. Our goal is to preserve these capabilities while extending models to handle complex code-switching, including morphological variations across languages. We propose Bayesian factorized adaptation, which learns to efficiently integrate switching-relevant knowledge into strong pretrained models without overwriting existing capabilities. Requiring only a small amount of synthetic data, our approach reduces transcription errors by 32.87% on code-switched words while improving overall WER by 5.31%, all while maintaining mono-lingual performance. Our results demonstrate that effective CSW adaptation depends more on knowledge integration than data complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Bayesian factorized adaptation as a method to add robust code-switching (CSW) capabilities to pretrained high-performance multilingual ASR models. It claims that, unlike standard fine-tuning on synthetic CSW data which degrades monolingual baselines, this approach efficiently integrates switching-relevant knowledge using only a small amount of synthetic data. The central empirical results are a 32.87% reduction in transcription errors on code-switched words, a 5.31% improvement in overall WER, and preservation of monolingual performance. The paper concludes that effective CSW adaptation depends more on knowledge integration than data complexity.
Significance. If the reported performance gains are reproducible and statistically supported, the work would offer a practical advance for multilingual ASR deployment in code-switching scenarios common in real-world speech. The Bayesian factorized adaptation strategy for preserving pretrained monolingual capabilities while extending to CSW with minimal data could inform efficient adaptation techniques in other multilingual speech and language tasks. The emphasis on integration over data volume provides a useful framing for future low-resource adaptation research.
major comments (1)
- [Abstract] Abstract: The manuscript states precise quantitative claims (32.87% reduction on code-switched words and 5.31% overall WER improvement) but supplies no experimental setup, test sets, baselines, number of runs, error bars, or statistical tests. These details are load-bearing for the central empirical claim and must be provided to allow verification that the data support the stated improvements.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and recommendation. We agree that the abstract requires additional context to support its quantitative claims and will revise it to include a concise description of the experimental setup, test sets, baselines, and statistical reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states precise quantitative claims (32.87% reduction on code-switched words and 5.31% overall WER improvement) but supplies no experimental setup, test sets, baselines, number of runs, error bars, or statistical tests. These details are load-bearing for the central empirical claim and must be provided to allow verification that the data support the stated improvements.
Authors: We acknowledge that the current abstract does not include these supporting details. The full experimental setup, test sets (including code-switched and monolingual evaluation data), baselines, number of runs, and statistical reporting (error bars and significance tests) are described in Sections 3 (Methodology) and 4 (Experiments and Results) of the manuscript. To address the referee's concern, we will revise the abstract to incorporate a brief summary of the experimental protocol, datasets, and statistical methodology while preserving its length constraints. This change will make the central claims verifiable directly from the abstract. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical adaptation technique (Bayesian factorized adaptation) trained on limited synthetic code-switched data, with performance gains reported as measured outcomes on transcription error rates. No derivation chain, equations, or self-referential definitions are present in the provided abstract or description; the central claims are experimental results rather than quantities obtained by fitting parameters to the target metrics or by self-citation that reduces the result to its inputs. The method is positioned as an engineering approach whose success is validated externally via WER measurements, making the work self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard Bayesian inference for model adaptation
Reference graph
Works this paper leans on
-
[1]
Introduction Code-switching automatic speech recognition addresses the growing need to recognize multilingual speech where speak- ers seamlessly alternate between languages. While multilingual speech recognition has been studied for decades through lan- guage identification [1], cross-language acoustic modeling [2], and multilingual articulatory feature i...
-
[2]
Adding Robust Code-Switching Capabilities to High Performance Multilingual ASR
need real code-switching training data to be useful. In each scenario, work without real training data mainly ex- plores different ways of generating synthetic data and utilizing it for improving code-switching capabilities. Work in [9] tack- les scenario 1: they introduce a feature level mixup of TTS and real data, as well as a code-switching bias loss e...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Experimental Design and Motivation 2.1. Deliberate Choice of Language Pair: English-German as a Challenge We deliberately select English-German code-switching to eval- uate our approach under the most challenging conditions: The Whisper model achieves WER of 8.53% on German and 13.56% on English (CommonV oice 14 [23]), among its strongest performances acr...
-
[4]
Experiments and Results 3.1. Experimental Setup For fine-tuning we used the same setup for: •LoRA: Standard low-rank adaptation (rankr=32) •BLoRA: Bayesian Low-Rank Factorization with KL regular- ization (rankr=32,λ KL =0.5 ) with learning rate1e −3, warmup steps2000and weight decay of5e −4 for a maximum of30000steps, used with Whisper v3 turbo. Following...
-
[5]
This paper demonstrates that this framing breaks down precisely where it matters most: when the base model is already strong
Conclusion Code-switching ASR adaptation is often framed as a data prob- lem: synthesize better code-switching speech, and performance will follow. This paper demonstrates that this framing breaks down precisely where it matters most: when the base model is already strong. We show that standard fine-tuning on syn- thetic data consistently degrades both mo...
-
[6]
Generative AI was not used to generate scientific content, experimental re- sults, data analyses, or conclusions
Generative AI Use Disclosure The authors used generative AI tools only for language edit- ing, readability improvements, and figure editing. Generative AI was not used to generate scientific content, experimental re- sults, data analyses, or conclusions
-
[7]
101135798, project Meetween (My Personal AI Mediator for Virtual MEETtings BetWEEN People) and European Union’s Horizon Europe programme grant agreement No
Acknowledgment This work was supported in part by the European Union’s Horizon research programme under grant agreement No. 101135798, project Meetween (My Personal AI Mediator for Virtual MEETtings BetWEEN People) and European Union’s Horizon Europe programme grant agreement No. 101213369 (DVPS). The authors gratefully acknowledge computing time provided...
-
[8]
Lvcsr-based language iden- tification,
T. Schultz, I. Rogina, and A. Waibel, “Lvcsr-based language iden- tification,” in1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, vol. 2. IEEE, 1996, pp. 781–784
1996
-
[9]
Experiments on cross-language acous- tic modeling
T. Schultz and A. Waibel, “Experiments on cross-language acous- tic modeling.” inINTERSPEECH, 2001, pp. 2721–2724
2001
-
[10]
Integrating mul- tilingual articulatory features into speech recognition
S. St ¨uker, F. Metze, T. Schultz, and A. Waibel, “Integrating mul- tilingual articulatory features into speech recognition.” inINTER- SPEECH, 2003, pp. 1033–1036
2003
-
[11]
Seame: a mandarin- english code-switching speech corpus in south-east asia
D.-C. Lyu, T. P. Tan, E. Chng, and H. Li, “Seame: a mandarin- english code-switching speech corpus in south-east asia.” inIn- terspeech, vol. 10, 2010, pp. 1986–1989
2010
-
[12]
Arzen: A speech corpus for code-switched egyptian arabic-english,
I. Hamed, N. T. Vu, and S. Abdennadher, “Arzen: A speech corpus for code-switched egyptian arabic-english,” inProceedings of the twelfth language resources and evaluation conference, 2020, pp. 4237–4246
2020
-
[13]
End-to-end speech translation for code switched speech,
O. Weller, M. Sperber, T. Pires, H. Setiawan, C. Gollan, D. Telaar, and M. Paulik, “End-to-end speech translation for code switched speech,”arXiv preprint arXiv:2204.05076, 2022
-
[14]
Decm: Evaluating bilin- gual asr performance on a code-switching/mixing benchmark,
E. Y . Ugan, N.-Q. Pham, and A. Waibel, “Decm: Evaluating bilin- gual asr performance on a code-switching/mixing benchmark,” inProceedings Of The 2024 Joint International Conference On Computational Linguistics, Language Resources And Evaluation (LREC-COLING 2024), 2024, pp. 4468–4475
2024
-
[15]
Leveraging llm for augmenting textual data in code-switching asr: Arabic as an example,
S. Alharbi, R. Binmuqbil, A. Ali, R. Aloraini, S. Bari, A. Alow- isheq, and Y . Alonaizan, “Leveraging llm for augmenting textual data in code-switching asr: Arabic as an example,”Proceedings of SynData4GenAI, 2024
2024
-
[16]
Improving low resource code-switched asr using augmented code-switched tts,
Y . Sharma, B. Abraham, K. Taneja, and P. Jyothi, “Improving low resource code-switched asr using augmented code-switched tts,” inProc. Interspeech 2020, 2020, pp. 4771–4775
2020
-
[17]
Towards one model to rule all: Multilingual strategy for dialectal code- switching arabic asr,
S. A. Chowdhury, A. Hussein, A. Abdelali, and A. Ali, “Towards one model to rule all: Multilingual strategy for dialectal code- switching arabic asr,” inProc. Interspeech 2021, 2021, pp. 2466– 2470
2021
-
[18]
Arabic code- switching speech recognition using monolingual data,
A. Ali, S. A. Chowdhury, A. Hussein, and Y . Hifny, “Arabic code- switching speech recognition using monolingual data,” inProc. Interspeech 2021, 2021, pp. 3475–3479
2021
-
[19]
Adapting lan- guage balance in code-switching speech,
E. Y . Ugan, N.-Q. Pham, and A. Waibel, “Adapting lan- guage balance in code-switching speech,”arXiv preprint arXiv:2510.18724, 2025
-
[20]
T. Nguyen and H.-D. Tran, “Can we train asr systems on code- switch without real code-switch data? case study for singapore’s languages,”arXiv preprint arXiv:2506.14177, 2025
-
[21]
Cs-fleurs: A massively multilingual and code-switched speech dataset,
B. Yan, I. Hamed, S. Shimizu, V . S. Lodagala, W. Chen, O. Iakovenko, B. Talafha, A. Hussein, A. Polok, K. Changet al., “Cs-fleurs: A massively multilingual and code-switched speech dataset,” inProc. Interspeech 2025, 2025, pp. 743–747
2025
-
[22]
Language- agnostic code-switching in sequence-to-sequence speech recogni- tion,
E. Y . Ugan, C. Huber, J. Hussain, and A. Waibel, “Language- agnostic code-switching in sequence-to-sequence speech recogni- tion,”arXiv preprint arXiv:2210.08992, 2022
-
[23]
An end-to-end language-tracking speech recognizer for mixed- language speech,
H. Seki, S. Watanabe, T. Hori, J. Le Roux, and J. R. Hershey, “An end-to-end language-tracking speech recognizer for mixed- language speech,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 4919–4923
2018
-
[24]
reduc- ing multilingual context confusion for end-to-end code-switching automatic speech recognition,
S. Zhang, J. Yi, Z. Tian, J. Tao, Y . T. Yeung, and L. Deng, “reduc- ing multilingual context confusion for end-to-end code-switching automatic speech recognition,” inProc. Interspeech 2022, 2022, pp. 3894–3898
2022
-
[25]
Beyond monolingual limits: Fine-tuning monolingual asr for yoruba-english code-switching,
O. B. Babatunde, V . T. Olufemi, E. Bolarinwa, K. Y . Moshood, and C. C. Emezue, “Beyond monolingual limits: Fine-tuning monolingual asr for yoruba-english code-switching,” inProceed- ings of the 7th Workshop on Computational Approaches to Lin- guistic Code-Switching, 2025, pp. 18–25
2025
-
[26]
Weight factorization and centralization for continual learning in speech recognition,
E. Ugan, N.-Q. Pham, and A. Waibel, “Weight factorization and centralization for continual learning in speech recognition,” in Proc. Interspeech 2025, 2025, pp. 2200–2204
2025
-
[27]
Adapting whisper for parameter-efficient code-switching speech recognition via soft prompt tuning,
H. Yang, Y . Peng, H. Huang, and S. Li, “Adapting whisper for parameter-efficient code-switching speech recognition via soft prompt tuning,”arXiv preprint arXiv:2506.21576, 2025
-
[28]
Bayesian low-rank fac- torization for robust model adaptation,
E. Y . Ugan, N.-Q. Pham, and A. Waibel, “Bayesian low-rank fac- torization for robust model adaptation,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 18 432–18 436
2026
-
[29]
Data augmentation for end-to-end code-switching speech recognition,
C. Du, H. Li, Y . Lu, L. Wang, and Y . Qian, “Data augmentation for end-to-end code-switching speech recognition,” in2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 194–200
2021
-
[30]
Com- mon voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Hen- retty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Com- mon voice: A massively-multilingual speech corpus,” inProceed- ings of the twelfth language resources and evaluation conference, 2020, pp. 4218–4222
2020
-
[31]
A formal grammar for code- switching,
S. Poplack and D. Sankoff, “A formal grammar for code- switching,”Papers in Linguistics: International Journal of Hu- man Communication, vol. 14, no. 1, pp. 3–45, 1981
1981
-
[32]
Xtts: a mas- sively multilingual zero-shot text-to-speech model,
E. Casanova, K. Davis, E. G ¨olge, G. G ¨oknar, I. Gulea, L. Hart, A. Aljafari, J. Meyer, R. Morais, S. Olayemiet al., “Xtts: a mas- sively multilingual zero-shot text-to-speech model,” inProc. In- terspeech 2024, 2024, pp. 4978–4982
2024
-
[33]
Efficient weight factorization for multilingual speech recognition,
N.-Q. Pham, T.-N. Nguyen, S. St ¨uker, and A. Waibel, “Efficient weight factorization for multilingual speech recognition,”arXiv preprint arXiv:2105.03010, 2021
-
[34]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.”ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[35]
Pier: A novel metric for evaluating what matters in code-switching,
E. Y . Ugan, N.-Q. Pham, L. B ¨armann, and A. Waibel, “Pier: A novel metric for evaluating what matters in code-switching,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[36]
S. Ma, L. Dong, S. Huang, D. Zhang, A. Muzio, S. Sing- hal, H. H. Awadalla, X. Song, and F. Wei, “Deltalm: Encoder- decoder pre-training for language generation and translation by augmenting pretrained multilingual encoders,”arXiv preprint arXiv:2106.13736, 2021
-
[37]
Few-shot learning translation from new languages,
C. Mullov and A. Waibel, “Few-shot learning translation from new languages,” inProceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing, 2025, pp. 3309– 3330
2025
-
[38]
Unsupervised cross-lingual representation learning for speech recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsupervised cross-lingual representation learning for speech recognition,”arXiv preprint arXiv:2006.13979, 2020
-
[39]
Recurrent neural network language modeling for code switching conversational speech,
H. Adel, N. T. Vu, F. Kraus, T. Schlippe, H. Li, and T. Schultz, “Recurrent neural network language modeling for code switching conversational speech,” in2013 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2013, pp. 8411–8415
2013
-
[40]
Code-switching language modeling using syntax-aware multi-task learning,
G. I. Winata, A. Madotto, C.-S. Wu, and P. Fung, “Code-switching language modeling using syntax-aware multi-task learning,” in Proceedings of the Third Workshop on Computational Approaches to Linguistic Code-Switching, 2018, pp. 62–67
2018
-
[41]
An exhaustive evaluation of tts-and vc-based data augmentation for asr,
S. Ogun, V . Colotte, and E. Vincent, “An exhaustive evaluation of tts-and vc-based data augmentation for asr,”arXiv preprint arXiv:2503.08954, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.