Surgical Anatomy Recognition with Context Learning using Foundation Representations
Pith reviewed 2026-06-26 12:22 UTC · model grok-4.3
The pith
A 120,000-frame surgical video dataset and context-aware model enable accurate anatomy recognition in minimally invasive procedures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
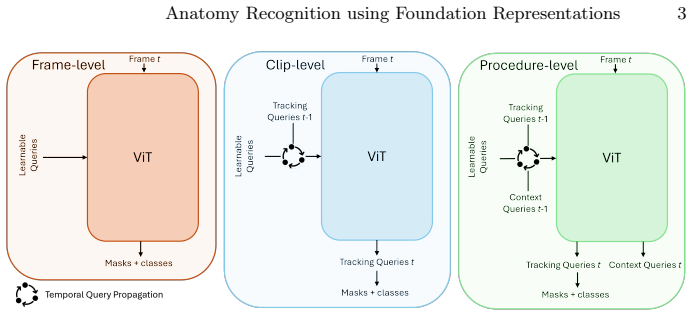
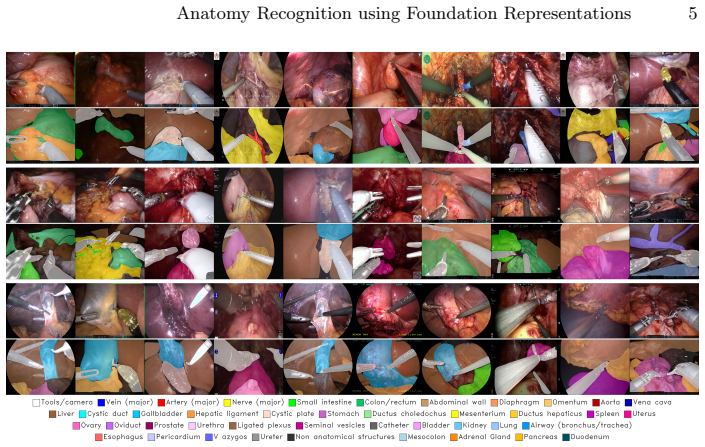
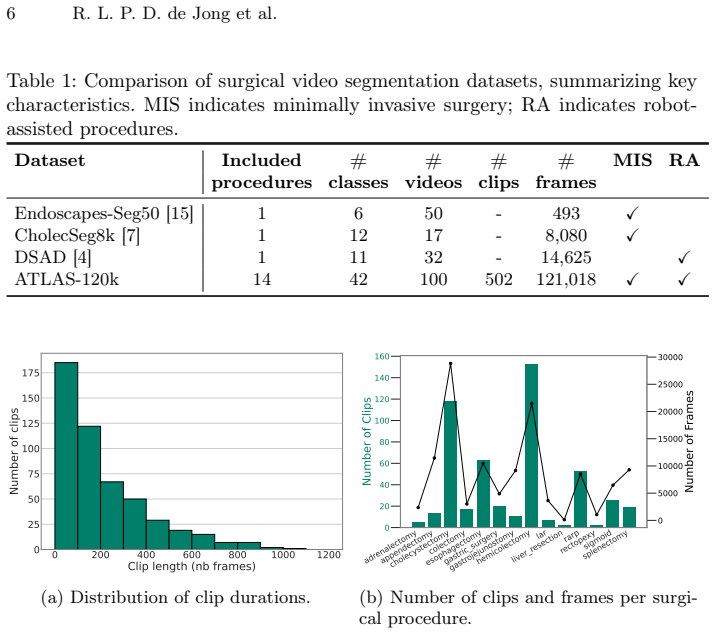
The paper presents ATLAS-120k, a clip-level semantic segmentation dataset comprising over 120,000 annotated frames from 100 surgical videos spanning 14 procedures and multiple modalities, created using a scalable annotation pipeline that integrates expert manual labeling, automated propagation, iterative refinement, and surgeon verification. It also introduces the ATLAS model, a video semantic segmentation architecture that leverages foundation-model embeddings together with lightweight temporal reasoning to incorporate contextual cues such as procedure type, surgical phase, and short-term visual memory, enabling temporally consistent and accurate predictions while maintaining real-time feas
What carries the argument
The ATLAS model, which combines foundation-model embeddings with lightweight temporal reasoning to incorporate procedure context and visual memory for video semantic segmentation of anatomical structures.
If this is right
- Supports development of clinically applicable guidance systems for minimally invasive surgery.
- Produces temporally consistent predictions across video frames.
- Maintains real-time inference speed suitable for live procedures.
- Establishes a practical foundation for robust surgical scene understanding.
Where Pith is reading between the lines
- The same embedding-plus-context design could be tested on instrument tracking or phase recognition tasks within the same videos.
- Public release of the dataset may allow direct comparison of different foundation backbones on surgical data.
- Context cues such as procedure type could be replaced by learned embeddings if procedure labels are unavailable at test time.
Load-bearing premise
The scalable annotation pipeline that integrates expert manual labeling, automated propagation, iterative refinement, and surgeon verification produces annotations of sufficient quality and consistency to train effective models.
What would settle it
An experiment showing that models trained on the ATLAS-120k annotations achieve no higher segmentation accuracy on held-out surgical videos than models trained on smaller sets of purely manual expert annotations.
Figures
read the original abstract
Accurate recognition of anatomical structures is essential for safe and effective minimally invasive surgery (MIS), yet it remains underexplored in surgical computer vision due to limited annotated data and methods tailored primarily to natural scenes. In this work, we present a combined dataset and model framework to advance anatomy-aware perception in MIS. First, we introduce ATLAS-120k, a large-scale clip-level semantic segmentation dataset comprising over 120,000 annotated frames from 100 surgical videos spanning 14 procedures and multiple modalities, including laparoscopic and robot-assisted surgery. The dataset captures substantial procedural variability and was created using a scalable annotation pipeline that integrates expert manual labeling, automated propagation, iterative refinement, and surgeon verification to ensure high-quality annotations. Second, we propose ATLAS (Anatomy Recognition with Context Learning using Foundation Representations), a video semantic segmentation model specifically designed for surgical anatomy recognition. Unlike conventional approaches that emphasize object tracking, ATLAS leverages foundation-model embeddings together with lightweight temporal reasoning to incorporate contextual cues such as procedure type, surgical phase, and short-term visual memory. This design enables temporally consistent and accurate predictions while maintaining real-time feasibility. Together, the dataset and model establish a practical foundation for robust surgical scene understanding and support the development of clinically applicable guidance systems for minimally invasive surgery. The models, dataset annotations and annotation platform are publicly available at: https://github.com/TimJaspers0801/ATLAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATLAS-120k, a clip-level semantic segmentation dataset with over 120,000 annotated frames from 100 surgical videos spanning 14 procedures and multiple modalities (laparoscopic and robot-assisted). The dataset is constructed via a scalable pipeline combining expert manual labeling, automated propagation, iterative refinement, and surgeon verification. It also presents the ATLAS model, which combines foundation-model embeddings with lightweight temporal reasoning to incorporate contextual cues (procedure type, surgical phase, short-term visual memory) for video semantic segmentation in minimally invasive surgery. The work claims that the dataset and model together provide a practical foundation for robust surgical scene understanding and clinically applicable guidance systems; models, annotations, and the annotation platform are released publicly.
Significance. If the annotation quality and model performance claims hold, the work would supply a large-scale, publicly available resource tailored to surgical anatomy recognition, addressing the noted scarcity of annotated MIS data. The public release of models, annotations, and platform strengthens reproducibility and potential impact for downstream clinical applications in minimally invasive surgery.
major comments (2)
- [Abstract] Abstract: The central claim that ATLAS-120k and the ATLAS model 'establish a practical foundation for robust surgical scene understanding' rests on the assertion of 'high-quality annotations' produced by the described pipeline, yet no quantitative evidence (inter-rater Dice/IoU, propagation drift metrics across phases, or comparison of automated vs. manual subsets) is supplied to substantiate annotation consistency or error rates under conditions such as tool motion, smoke, or bleeding.
- [Abstract] Abstract: No quantitative results, ablation studies, error analysis, or baseline comparisons are reported for the ATLAS model, making it impossible to evaluate whether the foundation-embedding plus temporal-reasoning design actually delivers the claimed temporally consistent and accurate predictions or real-time feasibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify the need for quantitative substantiation of annotation quality and model performance to support the claims. We address each point below and will incorporate the requested evidence through revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ATLAS-120k and the ATLAS model 'establish a practical foundation for robust surgical scene understanding' rests on the assertion of 'high-quality annotations' produced by the described pipeline, yet no quantitative evidence (inter-rater Dice/IoU, propagation drift metrics across phases, or comparison of automated vs. manual subsets) is supplied to substantiate annotation consistency or error rates under conditions such as tool motion, smoke, or bleeding.
Authors: We agree that quantitative metrics are necessary to substantiate the high-quality annotation claims. The current manuscript describes the pipeline but does not report specific numbers. In revision, we will add inter-rater Dice/IoU scores from expert labeling, propagation drift metrics, automated vs. manual subset comparisons, and error analysis under conditions including tool motion, smoke, and bleeding. These will appear in the methods and results sections with corresponding updates to the abstract. revision: yes
-
Referee: [Abstract] Abstract: No quantitative results, ablation studies, error analysis, or baseline comparisons are reported for the ATLAS model, making it impossible to evaluate whether the foundation-embedding plus temporal-reasoning design actually delivers the claimed temporally consistent and accurate predictions or real-time feasibility.
Authors: We acknowledge that the manuscript currently lacks quantitative results, ablations, error analysis, and baselines for the ATLAS model. The revised version will include mIoU/Dice metrics, ablation studies on contextual cues and temporal reasoning, error analysis, baseline comparisons, and runtime evaluations for real-time feasibility. These will be added to a new experiments section and referenced in the abstract. revision: yes
Circularity Check
No circularity: empirical dataset and model introduction with no derivations or self-referential reductions
full rationale
The paper introduces ATLAS-120k dataset via a described annotation pipeline and the ATLAS model using foundation embeddings plus temporal reasoning. No equations, fitted parameters, predictions, or derivations appear in the provided text. Claims rest on new data collection and empirical design choices rather than any self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation. The work is self-contained against external benchmarks with no reduction of central results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Foundation-model embeddings transfer effectively to surgical video domains for anatomy segmentation
- domain assumption The multi-stage annotation pipeline produces high-quality, consistent labels across 120k frames
Reference graph
Works this paper leans on
-
[1]
Allan, M., Shvets, A., Kurmann, T., et al.: 2017 robotic instrument segmentation challenge (2019),https://arxiv.org/abs/1902.06426
Pith/arXiv arXiv 2017
-
[2]
Batić, D., Holm, F., Özsoy, E., Czempiel, T., Navab, N.: Endovit: pretrain- ing vision transformers on a large collection of endoscopic images. Interna- tional Journal of Computer Assisted Radiology and Surgery19(6), 1085–1091 (2024).https://doi.org/10.1007/s11548-024-03091-5,https://doi.org/10. 1007/s11548-024-03091-5
-
[3]
Surgical Endoscopy37(7), 5164–5175 (July 2023).https: //doi.org/10.1007/s00464-023-09990-z
den Boer, R.B., Jaspers, T.J.M., de Jongh, C., et al.: Deep learning-based recognition of key anatomical structures during robot-assisted minimally inva- sive esophagectomy. Surgical Endoscopy37(7), 5164–5175 (July 2023).https: //doi.org/10.1007/s00464-023-09990-z
-
[4]
Scientific Data 10(1), 3 (2023).https://doi.org/10.1038/s41597-022-01719-2
Carstens, M., Rinner, F.M., Bodenstedt, S., et al.: The dresden surgical anatomy dataset for abdominal organ segmentation in surgical data science. Scientific Data 10(1), 3 (2023).https://doi.org/10.1038/s41597-022-01719-2
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Che, C., Wang, C., Vercauteren, T., Tsoka, S., Garcia-Peraza-Herrera, L.C.: Lemon: A large endoscopic monocular dataset and foundation model for perception in surgical settings. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 42659–42669 (June 2026)
2026
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cheng, H.K., Oh, S.W., Price, B., Lee, J.Y., Schwing, A.: Putting the object back into video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3151–3161 (June 2024)
2024
-
[7]
Hong, W.Y., Kao, C.L., Kuo, Y.H., Wang, J.R., Chang, W.L., Shih, C.S.: Cholec- seg8k: A semantic segmentation dataset for laparoscopic cholecystectomy based on cholec80 (2020),https://arxiv.org/abs/2012.12453
arXiv 2020
-
[8]
Jaspers, T.J.M., de Jong, R.L.P.D., Li, Y., Kusters, C.H.J., Bakker, F.H.A., van Jaarsveld, R.C., Kuiper, G.M., van Hillegersberg, R., Ruurda, J.P., Brinkman, W.M., Pluim, J.P.W., de With, P.H.N., Breeuwer, M., Al Khalil, Y., van der Sommen, F.: Scaling up self-supervised learning for improved surgical foundation models. Medical Image Analysis108, 103873 ...
-
[9]
In: Rettmann, M.E., Siewerdsen, J.H
de Jong, R.L.P.D., al Khalil, Y., Jaspers, T.J.M., van Jaarsveld, R.C., Kuiper, G.M., Li, Y., van Hillegersberg, R., Ruurda, J.P., Breeuwer, M., van der Som- men, F.: Benchmarking pretrained attention-based models for real-time recog- nition in robot-assisted esophagectomy. In: Rettmann, M.E., Siewerdsen, J.H. (eds.) Medical Imaging 2025: Image-Guided Pro...
-
[10]
In: MIDL (ed.) Medical Imaging with Deep Learning (2026), https://openreview.net/forum?id=6FoIDPKzRV
de Jong, R.L.P.D., Li, Y., Jaspers, T.J.M., van Jaarsveld, R.C., Kuiper, G.M., Badaloni, F., van Hillegersberg, R., Ruurda, J.P., van der Sommen, F., Pluim, J.P.W., Breeuwer, M.: Towards effective surgical representation learning with DINO models. In: MIDL (ed.) Medical Imaging with Deep Learning (2026), https://openreview.net/forum?id=6FoIDPKzRV
2026
-
[11]
Gastroen- terology170(1), 174–187 (2026).https://doi.org/https://doi.org/10.1053/ j.gastro.2025.07.030
Jong, M.R., Boers, T.G., Fockens, K.N., et al.: Gastronet-5m: A multicenter dataset for developing foundation models in gastrointestinal endoscopy. Gastroen- terology170(1), 174–187 (2026).https://doi.org/https://doi.org/10.1053/ j.gastro.2025.07.030
2026
-
[12]
Kerssies, T., Cavagnero, N., Hermans, A., Norouzi, N., Averta, G., Leibe, B., Dubbelman, G., de Geus, D.: Your vit is secretly an image segmentation model. In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 25303–25313 (2025).https://doi.org/10.1109/CVPR52734.2025. 02356
-
[13]
Medical Image Analysis76, 102306 (2022)
Maier-Hein, L., Eisenmann, M., Sarikaya, D., et al.: Surgical data science – from concepts toward clinical translation. Medical Image Analysis76, 102306 (2022). https://doi.org/https://doi.org/10.1016/j.media.2021.102306
-
[14]
Scientific data8(1), 101 (2021)
Maier-Hein, L., Wagner, M., Ross, T., Reinke, A., Bodenstedt, S., Full, P.M., Hempe, H., Mindroc-Filimon, D., Scholz, P., Tran, T.N., et al.: Heidelberg col- orectal data set for surgical data science in the sensor operating room. Scientific data8(1), 101 (2021)
2021
-
[15]
Scientific Data12(1), 331 (2025).https://doi.org/ 10.1038/s41597-025-04642-4
Mascagni, P., Alapatt, D., Murali, A., Vardazaryan, A., Garcia, A., Okamoto, N., Costamagna, G., Mutter, D., Marescaux, J., Dallemagne, B., Padoy, N.: En- doscapes, a critical view of safety and surgical scene segmentation dataset for la- paroscopic cholecystectomy. Scientific Data12(1), 331 (2025).https://doi.org/ 10.1038/s41597-025-04642-4
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Miao, J., Wei, Y., Wu, Y., Liang, C., Li, G., Yang, Y.: Vspw: A large-scale dataset for video scene parsing in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4133–4143 (June 2021)
2021
-
[17]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (to appear) (2026)
Norouzi, N., Zulfikar, I., Cavagnero, N., Kerssies, T., Leibe, B., Dubbelman, G., de Geus, D.: VidEoMT: Your ViT is Secretly Also a Video Segmentation Model. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (to appear) (2026)
2026
-
[18]
Transactions on Ma- chineLearningResearch(2024),https://openreview.net/forum?id=a68SUt6zFt, featured Certification
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[19]
Schmidgall, S., Kim, J.W., Jopling, J., Krieger, A.: General surgery vision trans- former: A video pre-trained foundation model for general surgery (2024),https: //arxiv.org/abs/2403.05949
arXiv 2024
-
[20]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: Dinov3 (2025),https://ar...
Pith/arXiv arXiv 2025
-
[21]
IEEE Transactions on Medical Imaging36(1), 86–97 (2017).https://doi.org/10.1109/TMI.2016.2593957
Twinanda, A.P., Shehata, S., et al.: Endonet: A deep architecture for recognition tasks on laparoscopic videos. IEEE Transactions on Medical Imaging36(1), 86–97 (2017).https://doi.org/10.1109/TMI.2016.2593957
-
[22]
In: International Conference on Med- ical Image Computing and Computer-Assisted Intervention
Wang, Z., Liu, C., Zhang, S., Dou, Q.: Foundation model for endoscopy video anal- ysis via large-scale self-supervised pre-train. In: International Conference on Med- ical Image Computing and Computer-Assisted Intervention. pp. 101–111. Springer (2023)
2023
-
[23]
Xiong, X., Wu, Z., Lu, L., Xia, Y.: Sam3-unet: Simplified adaptation of segment anything model 3 (2025),https://arxiv.org/abs/2512.01789
arXiv 2025
-
[24]
Visual Intelligence4(1), 2 (2026)
Xiong, X., Wu, Z., Tan, S., Li, W., Tang, F., Chen, Y., Li, S., Ma, J., Li, G.: Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation. Visual Intelligence4(1), 2 (2026)
2026
-
[25]
Zia, A., Bhattacharyya, K., Liu, X., et al.: Surgical tool classification and local- ization: results and methods from the miccai 2022 surgtoolloc challenge (2023), https://arxiv.org/abs/2305.07152
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.