On the Expressive Power of Weight Quantization in Large Language Models
Pith reviewed 2026-06-26 11:51 UTC · model grok-4.3
The pith
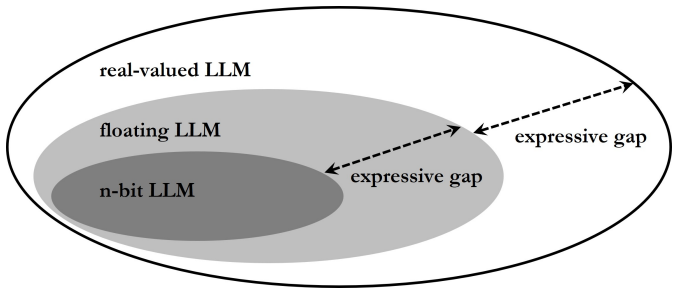
Weight quantization in large language models loses universal approximation ability below 1.58 bits per weight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
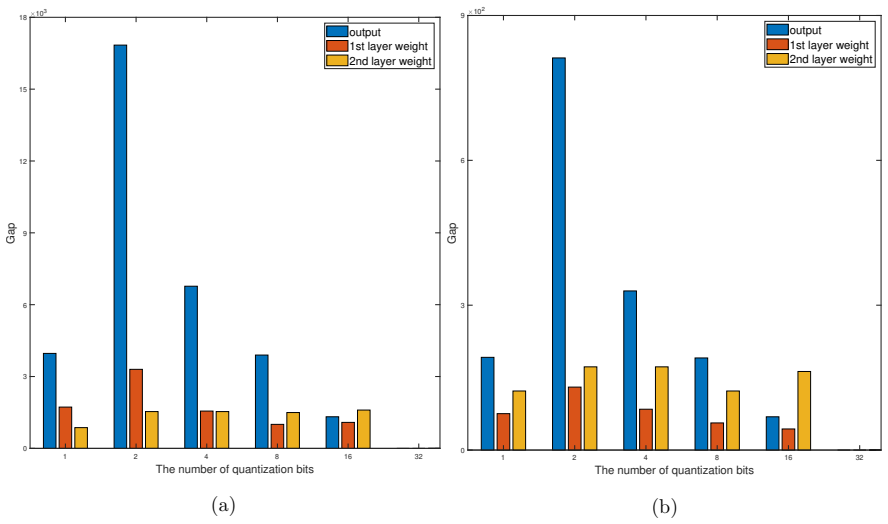
The paper establishes that 1.58-bit is the limiting precision for weight quantization by proving universal approximation holds for weight-quantized models above this level and expressive collapse occurs below it, while also showing that expressive capacity degrades polynomially with decreasing bit count.
What carries the argument
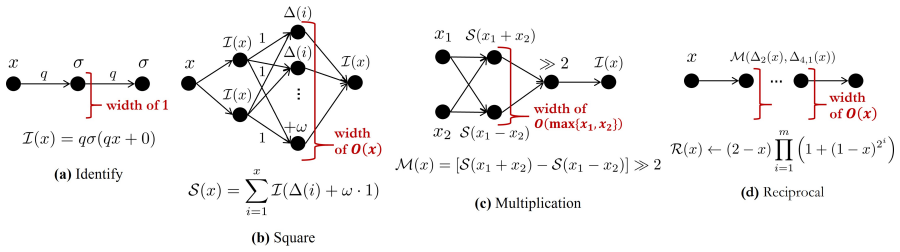
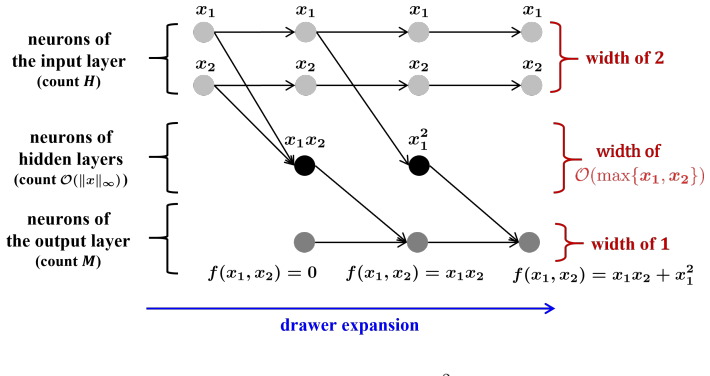
Restriction of network weights to finite discrete sets whose cardinality is governed by the bit precision, combined with analysis of the resulting function class's approximation properties.
If this is right
- Models using fewer than 1.58 bits per weight cannot serve as universal approximators regardless of width or depth.
- Expressive capacity scales polynomially downward with each reduction in bit precision.
- Quantization-aware scaling laws must incorporate this precision-dependent degradation term.
- Compression and acceleration techniques gain a theoretical floor below which further bit reduction yields qualitatively different models.
Where Pith is reading between the lines
- The 1.58-bit threshold aligns with ternary weight sets such as {-1, 0, 1}, suggesting those representations sit at the boundary between full and collapsed expressivity.
- Empirical tests measuring approximation error on simple function classes could directly observe the predicted polynomial rate.
- Similar discrete-set arguments might apply to activation quantization or mixed-precision schemes.
- The framework could be extended to quantify how quantization interacts with specific architectural choices like attention heads.
Load-bearing premise
Expressive power is defined such that the number of distinct quantization levels directly determines whether universal approximation is possible, with a sharp change at exactly three levels.
What would settle it
A construction of a 1-bit quantized network family that can still approximate any continuous function on a compact domain to arbitrary accuracy would disprove the claimed collapse threshold.
Figures
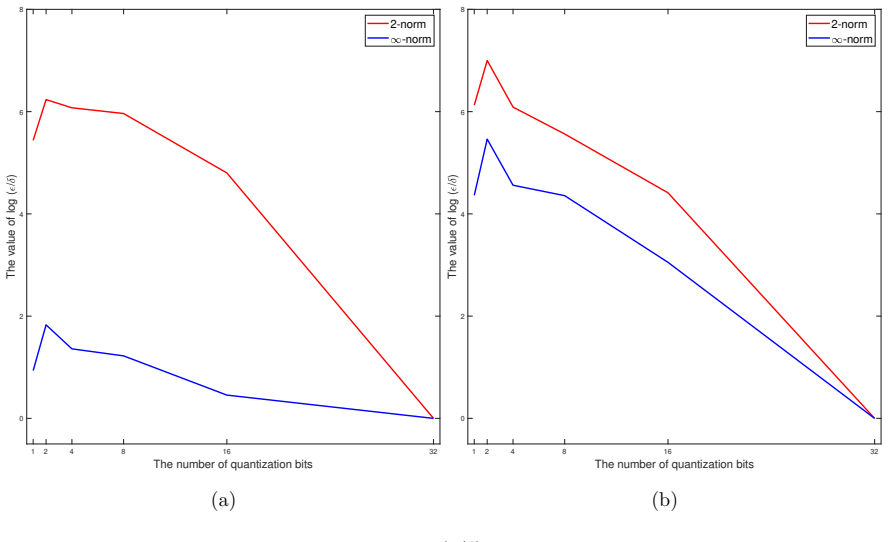
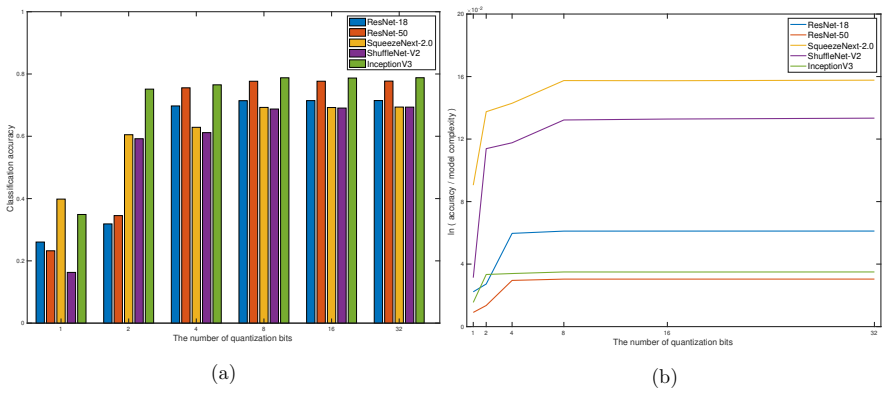

read the original abstract
In recent years, weight quantization that encodes the learnable parameters of large language models in an $n$-bit format has garnered significant attention due to its potential for model compression and inference acceleration. Many practical techniques have been developed; however, the theoretical understanding of many aspects, especially the approximation and degradation of expressive power as the number of quantization bits decreases, remains unclear. In this paper, we provide a theoretical investigation into the expressive capability of large language models relative to the number of quantization bits. We argue that 1.58-bit is the limiting precision for weight quantization by establishing the universal approximation and expressive collapse properties of weight-quantized models with respect to the number of quantization bits. Additionally, we confirm that weight quantization leads to expressive degradation, in which the expressive capacity of weight-quantized models degrades polynomially as the number of quantization bits decreases. These theoretical findings provide a solid foundation for advancing weight quantization in the context of scaling laws and shed insights for future research in model compression and inference acceleration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that 1.58 bits is the limiting precision for weight quantization in large language models. It establishes universal approximation and expressive collapse properties with respect to the number of quantization bits, and shows that expressive capacity degrades polynomially as the number of bits decreases. These results are positioned as providing a theoretical foundation for quantization in scaling laws.
Significance. If the central claims are rigorously derived, the identification of a sharp threshold at log2(3) bits and the polynomial degradation rate would supply a concrete theoretical limit that could inform practical quantization choices and scaling analyses for model compression.
major comments (2)
- [Abstract] Abstract: the claim of a sharp 1.58-bit threshold for universal approximation and expressive collapse is load-bearing for the entire contribution, yet no definition of expressive power, no statement of the network class (e.g., ReLU networks with finite weights), and no proof sketch or cardinality argument are supplied; without these the threshold cannot be verified and may be an artifact of an implicit modeling choice that equates |Q| = 2^b directly with functional span.
- [Abstract] Abstract: the polynomial degradation statement is presented as a derived result, but no functional form, no dependence on network depth or width, and no supporting derivation or theorem statement appear; this prevents assessment of whether the rate is independent of other modeling assumptions.
minor comments (1)
- [Abstract] Abstract: the term 'large language models' is used throughout, but the stated properties appear to apply to general feed-forward networks; clarify whether the results rely on transformer-specific structure or hold more broadly.
Simulated Author's Rebuttal
We thank the referee for the comments on the abstract. We address each point below, noting that the abstract summarizes results whose details appear in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a sharp 1.58-bit threshold for universal approximation and expressive collapse is load-bearing for the entire contribution, yet no definition of expressive power, no statement of the network class (e.g., ReLU networks with finite weights), and no proof sketch or cardinality argument are supplied; without these the threshold cannot be verified and may be an artifact of an implicit modeling choice that equates |Q| = 2^b directly with functional span.
Authors: The abstract is a concise summary. The manuscript defines expressive power via the universal approximation property for continuous functions on compact sets and specifies the network class as ReLU networks whose weights are drawn from a finite quantization set Q with cardinality 2^b. The threshold at log2(3) follows from a cardinality argument establishing that the representable function class becomes strictly smaller than the target class for b < log2(3), producing collapse; this is shown in the main theorems and is independent of equating |Q| directly with functional span. We will expand the abstract with a one-sentence definition of expressive power and the network class. revision: yes
-
Referee: [Abstract] Abstract: the polynomial degradation statement is presented as a derived result, but no functional form, no dependence on network depth or width, and no supporting derivation or theorem statement appear; this prevents assessment of whether the rate is independent of other modeling assumptions.
Authors: The polynomial degradation result is derived in the manuscript, with the functional form depending polynomially on 2^b and with explicit dependence on depth and width appearing in the exponent. The supporting theorem and proof are given in the body. We will add a parenthetical reference to the relevant theorem in the abstract to improve traceability. revision: yes
Circularity Check
No circularity; claims presented as derived theoretical properties without reduction to inputs by construction
full rationale
The abstract frames the 1.58-bit limit and polynomial expressive degradation as results obtained by establishing universal approximation and expressive collapse properties of weight-quantized models. No equations, self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would make any central claim equivalent to its inputs by construction. The derivation is positioned as independent from external approximation theory benchmarks, consistent with a self-contained analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expressive power of a neural network can be rigorously quantified such that quantization to a discrete weight set of cardinality 3 preserves universal approximation while cardinality 2 triggers collapse.
Reference graph
Works this paper leans on
- [1]
-
[2]
Llama 3 model card
AI@Meta. Llama 3 model card. URL https://github.com/meta-llama/llama3/blob/ main/MODEL CARD.md., 2024
2024
-
[3]
A. G. Anderson and C. P. Berg. The high-dimensional geometry of binary neural networks. arXiv:1705.07199, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Y. Bisk, R. Zellers, J. Gao, and Y. Choi. PIQA: Reasoning about physical commonsense in natural language. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, pages 7432–7439, 2020
2020
-
[5]
R. R. Bunel, I. Turkaslan, P. Torr, P. Kohli, and P. K. Mudigonda. A unified view of piecewise linear neural network verification. In Advances in Neural Information Processing Systems 31, pages 4795–4804, 2018
2018
-
[6]
Chatterjee and L
A. Chatterjee and L. R. Varshney. Towards optimal quantization of neural networks. In Pro- ceedings of the 2017 IEEE International Symposium on Information Theory, pages 1162–1166, 2017
2017
- [7]
-
[8]
Cheng, T
J. Cheng, T. Lin, Z. Shen, and Q. Li. A unified framework for establishing the universal approxi- mation of transformer-type architectures. In Advances in Neural Information Processing Systems 38, 2025
2025
-
[9]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
C. Clark, K. Lee, M.-W. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv:1905.10044, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Courbariaux, Y
M. Courbariaux, Y. Bengio, and J.-P. David. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems 28, pages 3123–3131, 2015
2015
-
[12]
Courbariaux, Y
M. Courbariaux, Y. Bengio, and J.-P. David. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems 28, pages 3123–3131, 2015. 30
2015
-
[13]
J. Deng, W. Dong, S. Richard, L.-J. Li, K. Li, and F.-F. Li. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
2009
-
[14]
Y. Ding, J. Liu, J. Xiong, and Y. Shi. On the universal approximability and complexity bounds of quantized ReLU neural networks. In Proceedings of the 7-th International Conference on Learning Representations, 2019
2019
-
[15]
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer. A survey of quantization methods for efficient neural network inference. arxiv:2103.13630, 2021
-
[16]
Gonon, N
A. Gonon, N. Brisebarre, R. Gribonval, and E. Riccietti. Approximation speed of quantized versus unquantized ReLU neural networks and beyond. IEEE Transactions on Information Theory, 69 (6):3960–3977, 2023
2023
-
[17]
D. Gope, G. Dasika, and M. Mattina. Ternary hybrid neural-tree networks for highly constrained IoT applications. Proceedings of Machine Learning and Systems, 1:190–200, 2019
2019
-
[18]
Y. Guo. A survey on methods and theories of quantized neural networks. arXiv:1808.04752, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[20]
Hornik, M
K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approx- imators. Neural Networks, 2(5):359–366, 1989
1989
-
[21]
E. B. Hunt. Artificial Intelligence. Academic Press, 2014
2014
- [22]
-
[23]
Kidger and T
P. Kidger and T. Lyons. Universal approximation with deep narrow networks. In Proceedings of the 33rd Annual Conference on Learning Theory, pages 2306–2327, 2020
2020
- [24]
-
[25]
H. Li, S. De, Z. Xu, C. Studer, H. Samet, and T. Goldstein. Training quantized nets: A deeper understanding. In Advances in Neural Information Processing Systems 30, 2017
2017
- [26]
-
[27]
Z. Liu, C. Zhao, F. Iandola, C. Lai, Y. Tian, I. Fedorov, Y. Xiong, E. Chang, Y. Shi, R. Kr- ishnamoorthi, L. Lai, and V. Chandra. MobileLLM: Optimizing sub-billion parameter language models for on-device use cases. In Proceedings of the 41st International Conference on Machine Learning, pages 32431–32454, 2024
2024
-
[28]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
N. Ma, X. Zhang, H.-T. Zheng, and J. Sun. Shufflenet V2: Practical guidelines for efficient CNN architecture design. In Proceedings of the 2018 European Conference on Computer Vision, pages 116–131, 2018
2018
- [30]
-
[31]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher. Pointer sentinel mixture models. arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Mertens and A
S. Mertens and A. Engel. Vapnik-chervonenkis dimension of neural networks with binary weights. Physical Review E, 55:4478–4488, 1997
1997
-
[33]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv:1809.02789, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [34]
-
[35]
Sakaguchi, R
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021
2021
-
[36]
M. Sap, H. Rashkin, D. Chen, R. LeBras, and Y. Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv:1904.09728, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[37]
X. Shen, P. Dong, L. Lu, Z. Kong, Z. Li, M. Lin, C. Wu, and Y. Wang. Agile-quant: Activation- guided quantization for faster inference of LLMs on the edge. In Proceedings of the 38th AAAI Conference on Artificial Intelligence, pages 18944–18951, 2024
2024
-
[38]
Szegedy, V
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, pages 2818–2826, 2016
2016
-
[39]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. In Advances in Neural Information Processing Systems 30, pages 6000–6010, 2017. 32
2017
-
[40]
Voigtlaender
F. Voigtlaender. The universal approximation theorem for complex-valued neural networks. Ap- plied and Computational Harmonic Analysis, 64:33–61, 2023
2023
- [41]
-
[42]
Z. Yang, Y. Wang, K. Han, C. Xu, C. Xu, D. Tao, and C. Xu. Searching for low-bit weights in quantized neural networks. In Advances in Neural Information Processing Systems 33, pages 4091–4102, 2020
2020
- [43]
-
[44]
C. Yun, S. Bhojanapalli, A. S. Rawat, S. Reddi, and S. Kumar. Are transformers universal approx- imators of sequence-to-sequence functions? In Proceedings of the 7th International Conference on Learning Representations, 2019
2019
-
[45]
HellaSwag: Can a Machine Really Finish Your Sentence?
R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. Hellaswag: Can a machine really finish your sentence? arXiv:1905.07830, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[46]
S.-H. Zhang, W.-C. Tang, C. Wu, P. Hu, N. Li, L.-J. Zhang, Q. Zhang, and S.-Q. Zhang. TernaryCLIP: Efficiently compressing vision-language models with ternary weights and distilled knowledge. arXiv:2510.21879, 2025
-
[47]
Zhang and Z.-H
S.-Q. Zhang and Z.-H. Zhou. Theoretically provable spiking neural networks. In Advances in Neural Information Processing Systems 35, pages 19345–19356, 2022
2022
-
[48]
A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen. Incremental network quantization: Towards lossless cnns with low-precision weights. arXiv:1702.03044, 2017. 33
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.