SCENIC: Semantic-Conditioned Edge-Aware Neural Framework for Structured IoT Command Generation
Pith reviewed 2026-06-26 11:20 UTC · model grok-4.3
The pith
Pruned INT8 encoder-decoder models reach 91% exact match on smart-home command generation while cutting exported size by 25%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
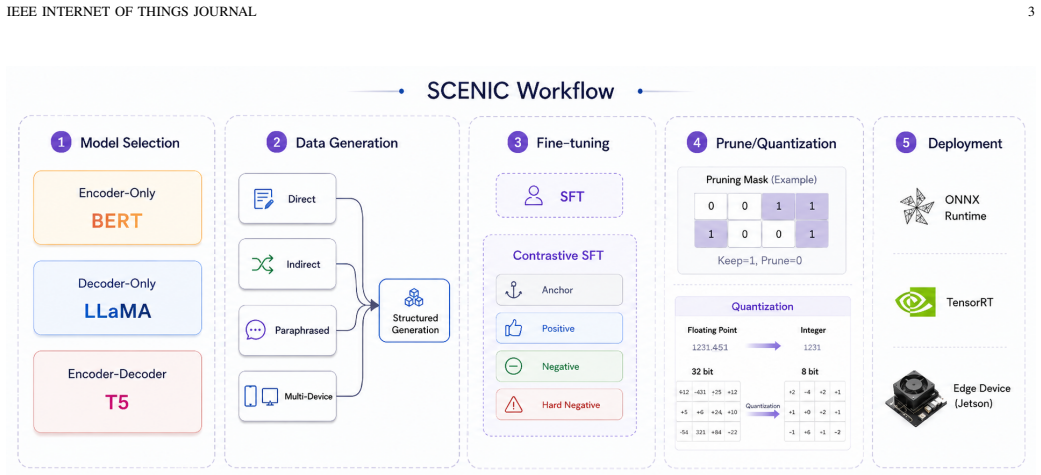
SCENIC is an end-to-end pipeline covering model selection, Smart Home Instruct data generation for the many-to-one mapping, triplet-loss contrastive supervised fine-tuning, pruning, quantization, and export; on the resulting benchmark the strongest dense decoder-only model reaches 99.0% EM@1 while a representative pruned INT8 encoder-decoder export preserves 91.0% EM@1 and 99.0% EM@5 with a 25.38% reduction in exported size and up to 1.8x encoder speedup under TensorRT profiling.
What carries the argument
The many-to-one structured output task, in which multiple natural-language instructions are mapped to one canonical command string through semantic-conditioned contrastive training followed by compression.
If this is right
- Dense decoder-only models under 0.2B parameters can reach 99.0% EM@1 on the benchmark.
- Encoder-decoder architectures retain stronger accuracy under high sparsity after pruning.
- INT8 quantized and pruned exports preserve 99.0% EM@5 while reducing model size.
- Component-level TensorRT acceleration yields up to 1.8x speedup on the encoder portion.
Where Pith is reading between the lines
- The same many-to-one framing and compression recipe may transfer to other constrained structured-output settings such as industrial control or medical device commands.
- Hardware-specific kernel fusions beyond the reported component profiling could further improve end-to-end latency on target edge chips.
- Collecting a small real-user validation set would directly test whether the synthetic data distribution matches deployed ambiguity.
Load-bearing premise
The synthetic Smart Home Instruct data generation process and its many-to-one mapping assumption accurately reflect the variety and ambiguity of real user instructions in deployed smart-home environments.
What would settle it
Running the exported pruned model on a collection of authentic, independently gathered smart-home user utterances that were never used to synthesize the training data and measuring exact-match rates.
Figures


read the original abstract
Edge Internet of Things (IoT) agents are often constrained by memory capacity, privacy requirements, communication latency, and recurring inference cost. Current smart-home assistants commonly rely on API-level command interfaces or cloud-based language models that remain difficult to deploy on edge devices. This paper addresses edge IoT command generation as a many-to-one structured output task, where multiple natural-language instructions map to the same canonical command string for deterministic smart-home parsing. To support this setting, we propose Semantic-Conditioned Edge-Aware Neural Framework for Structured IoT Command Generation (SCENIC), an end-to-end framework covering model architecture selection, Smart Home Instruct data generation, triplet-loss contrastive supervised fine-tuning, pruning and quantization, and deployment-oriented export. We evaluate sub-0.2B-scale transformer backbones, which are, to the best of our knowledge, among the smallest language-model backbones studied for edge IoT structured command generation. On Smart Home Instruct-Bench, the strongest dense decoder-only row reaches 99.0% EM@1, while the encoder-decoder model retains stronger high-sparsity behavior. A representative pruned INT8 encoder-decoder export preserves 91.0% EM@1 and 99.0% EM@5 while reducing exported model size by 25.38%. TensorRT profiling of the NVIDIA 2:4 sparse encoder export further shows up to 1.8x encoder-component speedup, indicating that the selected encoder-decoder deployment path can retain structured command accuracy under edge-oriented compression while hardware acceleration evidence remains component-level. The SCENIC code and experimental artifacts are open sourced to support reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SCENIC, an end-to-end framework for structured IoT command generation on edge devices. It covers synthetic data generation for the Smart Home Instruct-Bench benchmark (under an explicit many-to-one mapping from natural-language instructions to canonical command strings), selection of sub-0.2B transformer backbones, triplet-loss contrastive supervised fine-tuning, pruning/quantization, and deployment-oriented export. Reported results on the benchmark include 99.0% EM@1 for the strongest dense decoder-only model and, for a representative pruned INT8 encoder-decoder export, 91.0% EM@1, 99.0% EM@5, and 25.38% model-size reduction, with TensorRT profiling indicating up to 1.8x encoder-component speedup on 2:4 sparse exports. The code and artifacts are open-sourced.
Significance. If the results hold, the work would demonstrate that very small language-model backbones can achieve high exact-match accuracy on deterministic structured-output tasks after aggressive compression, which is relevant for memory- and latency-constrained edge IoT deployments. The open-sourcing of code and experimental artifacts is a clear strength that supports reproducibility. The significance is limited by the exclusive use of synthetic data.
major comments (1)
- [Abstract (paragraph on task definition)] Abstract (paragraph on task definition): the central claim that the pruned INT8 encoder-decoder export 'retains structured command accuracy under edge-oriented compression' is evaluated exclusively on synthetically generated data that enforces deterministic canonical mappings; no external validation against real user logs or more ambiguous instructions is shown, which is load-bearing for any assertion of deployable robustness in smart-home environments.
minor comments (1)
- [Abstract] The abstract states that the evaluated backbones are 'among the smallest language-model backbones studied for edge IoT structured command generation' but provides no citations to prior work on the topic.
Simulated Author's Rebuttal
We thank the referee for highlighting the distinction between synthetic benchmark performance and real-world validation. We address the major comment below by agreeing to revise the abstract for precision.
read point-by-point responses
-
Referee: Abstract (paragraph on task definition): the central claim that the pruned INT8 encoder-decoder export 'retains structured command accuracy under edge-oriented compression' is evaluated exclusively on synthetically generated data that enforces deterministic canonical mappings; no external validation against real user logs or more ambiguous instructions is shown, which is load-bearing for any assertion of deployable robustness in smart-home environments.
Authors: We agree that the evaluation, including the reported 91.0% EM@1 for the pruned INT8 export, is performed exclusively on the synthetic Smart Home Instruct-Bench with its explicit many-to-one deterministic mappings, as described in the manuscript. The abstract's phrasing regarding 'retains structured command accuracy under edge-oriented compression' refers specifically to benchmark results rather than a claim of broad real-world robustness. To prevent any implication of deployable robustness in actual smart-home settings, we will revise the abstract to explicitly qualify that all accuracy and compression results are demonstrated on the synthetic benchmark. This is a wording clarification only; the paper's scope remains focused on edge compression techniques for structured output on this benchmark. revision: yes
Circularity Check
No circularity; purely empirical evaluation on synthetic benchmark
full rationale
The paper contains no equations, derivations, fitted parameters presented as predictions, or self-citation chains. All reported results are direct empirical metrics (EM@1, EM@5, model size, speedup) measured on the internally generated Smart Home Instruct-Bench. While the benchmark construction relies on a many-to-one mapping assumption, this is an explicit modeling choice rather than a reduction of any claimed derivation to its own inputs. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, vol. 30, 2017. [Online]. Available: https://arxiv.org/abs/1706.03762
Pith/arXiv arXiv 2017
-
[2]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” 2020. [Online]. Available: https://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2020
-
[3]
A review on edge large language models: Design, execution, and applications,
Y . Zheng, Y . Chen, B. Qian, X. Shi, Y . Shu, and J. Chen, “A review on edge large language models: Design, execution, and applications,” ACM Computing Surveys, vol. 57, no. 8, 2025. [Online]. Available: https://doi.org/10.1145/3719664
-
[4]
HomeBench: Evaluating LLMs in smart homes with valid and invalid instructions across single and multiple devices,
S. Li, Y . Guo, J. Yao, Z. Liu, and H. Wang, “HomeBench: Evaluating LLMs in smart homes with valid and invalid instructions across single and multiple devices,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. Vienna, Austria: Association for Computational Linguistics, 2025, pp. 12 230–12 250. [Online]. Available:...
2025
-
[5]
BERT: Pre- training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, MN, USA: Association for Computational Linguistics, 2019, pp. 4...
2019
-
[6]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of Machine Learning Research, vol. 21, no. 140, pp. 1–67, 2020. [Online]. Available: https://jmlr.org/papers/v21/20-074.html
2020
-
[7]
Encoder-Chinese-SLM: An encoder-only Chinese small language model training codebase,
Luke Z. Hu, “Encoder-Chinese-SLM: An encoder-only Chinese small language model training codebase,” GitHub repository, 2026, version 0.1.0, released 2026-06-07. [Online]. Available: https: //github.com/huluk98/Encoder-Chinese-SLM
2026
-
[8]
Decoder-Chinese-SLM: A decoder-only Chinese small language model training codebase,
Luke Z. Hu, “Decoder-Chinese-SLM: A decoder-only Chinese small language model training codebase,” GitHub repository, 2026, version 0.1.0, released 2026-05-20. [Online]. Available: https: //github.com/huluk98/Decoder-Chinese-SLM
2026
-
[9]
A small Chinese chat language model with 0.2b parameters based on T5,
C. Chen, “A small Chinese chat language model with 0.2b parameters based on T5,” GitHub repository, 2023, accessed: 2026-05-18. [Online]. Available: https://github.com/charent/ChatLM-mini-Chinese
2023
-
[10]
LLaMA: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” 2023. [Online]. Available: https://arxiv.org/abs/2302.13971
Pith/arXiv arXiv 2023
-
[11]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, and Z. Qi...
Pith/arXiv arXiv 2024
-
[12]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, B. Hui, L. Ji, M. Li, J. Lin, R. Lin, D. Liu, G. Liu, C. Lu, K. Lu, J. Ma, R. Men, X. Ren, X. Ren, C. Tan, S. Tan, J. Tu, P. Wang, S. Wang, W. Wang, S. Wu, B. Xu, J. Xu, A. Yang, H. Yang, J. Yang, S. Yang, Y . Yao, B. Yu, H. Yuan, Z. Yuan, J. Zhang, X. Zhang, Y . Zhang, ...
Pith/arXiv arXiv 2023
-
[13]
Qwen2 technical report,
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, C. Zhou, C. Li, C. Li, D. Liu, F. Huang, G. Dong, H. Wei, H. Lin, J. Tang, J. Wang, J. Yang, J. Tu, J. Zhang, J. Ma, J. Yang, J. Xu, J. Zhou, J. Bai, J. He, J. Lin, K. Dang, K. Lu, K. Chen, K. Yang, M. Li, M. Xue, N. Ni, P. Zhang, P. Wang, R. Peng, R. Men, R. Gao, R. Lin, S. Wang, S. Bai, S. Tan, T. Zhu, T. Li, T...
-
[14]
Available: https://arxiv.org/abs/2407.10671
[Online]. Available: https://arxiv.org/abs/2407.10671
-
[15]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
Pith/arXiv arXiv 2025
-
[16]
ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools,
Team GLM, A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhao, H. Lai, H. Yu, H. Wang, J. Sun, J. Zhang, J. Cheng, J. Gui, J. Tang, J. Zhang, J. Sun, J. Li, L. Zhao, L. Wu, L. Zhong, M. Liu, M. Huang, P. Zhang, Q. Zheng, R. Lu, S. Duan, S. Zhang, S. Cao, S. Yang, W. L. Tam, W. Zhao, X. Liu, X. Xia, X. Zhang, X. Gu, X. Lv, X. Li...
Pith/arXiv arXiv 2024
-
[17]
On-device LLMs for Home Assistant: Dual role in intent detection and response generation,
R. Birkmose, N. M. Reece, E. H. Norvin, J. Bjerva, and M. Zhang, “On-device LLMs for Home Assistant: Dual role in intent detection and response generation,” 2025. [Online]. Available: https://arxiv.org/abs/2502.12923
arXiv 2025
-
[18]
Large language models in the IoT ecosystem: A survey on security challenges and applications,
K. Khatiwada, J. Hopper, J. Cheatham, A. Joshi, and S. Baidya, “Large language models in the IoT ecosystem: A survey on security challenges and applications,” 2025. [Online]. Available: https://arxiv.org/abs/2505.17586
arXiv 2025
-
[19]
Analysis of IFTTT Recipes to Study How Humans Use Internet-of-Things (IoT) Devices , url=
H. Yu, J. Hua, and C. Julien, “Analysis of IFTTT recipes to study how humans use internet-of-things (IoT) devices,” in Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems. ACM, 2021, pp. 537–541. [Online]. Available: https://doi.org/10.1145/3485730.3494115
-
[20]
SAGE: Smart home agent with grounded execution,
D. Rivkin, F. Hogan, A. Feriani, A. Konar, A. Sigal, S. Liu, and G. Dudek, “SAGE: Smart home agent with grounded execution,” 2023. [Online]. Available: https://arxiv.org/abs/2311.00772
arXiv 2023
-
[21]
Home Assistant requests dataset,
acon96, “Home Assistant requests dataset,” Hugging Face Datasets, 2024, accessed: 2026-05-18. [Online]. Available: https://huggingface.co/ datasets/acon96/Home-Assistant-Requests
2024
-
[22]
Supervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 18 661–18 673. [Online]. Available: https://arxiv.org/abs/2004.11362
arXiv 2020
-
[23]
A contrastive framework for neural text generation,
Y . Su, T. Lan, Y . Wang, D. Yogatama, L. Kong, and N. Collier, “A contrastive framework for neural text generation,” 2022. [Online]. Available: https://arxiv.org/abs/2202.06417
arXiv 2022
-
[24]
Contrastive instruction tuning,
T. Yan, F. Wang, J. Y . Huang, W. Zhou, F. Yin, A. Galstyan, W. Yin, and M. Chen, “Contrastive instruction tuning,” inFindings of the Association for Computational Linguistics: ACL 2024. Bangkok, Thailand: Association for Computational Linguistics, 2024, pp. 10 288–10 302. [Online]. Available: https://aclanthology.org/2024.findings-acl.613/
2024
-
[25]
SCENIC: Consolidated code for compact Chinese smart-home command generation under edge IoT constraints,
Luke Z. Hu, “SCENIC: Consolidated code for compact Chinese smart-home command generation under edge IoT constraints,” GitHub repository, 2026, version 0.1.0, commit 7e8484ac589147d935323678c4a227743048bde0. [Online]. Available: https://github.com/huluk98/SCENIC
2026
-
[26]
0.5-1.5 m height, 30-60 cm spread
E. B. Wilson, “Probable inference, the law of succession, and statistical inference,”Journal of the American Statistical Association, vol. 22, no. 158, pp. 209–212, 1927. [Online]. Available: https: //doi.org/10.1080/01621459.1927.10502953
-
[27]
Learning both weights and connections for efficient neural network,
S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural network,” in IEEE INTERNET OF THINGS JOURNAL 9 Advances in Neural Information Processing Systems, vol. 28, 2015. [Online]. Available: https://papers.nips.cc/paper_files/paper/2015/file/ ae0eb3eed39d2bcef4622b2499a05fe6-Paper.pdf
2015
-
[28]
Importance estimation for neural network pruning,
P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz, “Importance estimation for neural network pruning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11 264–11 272. [Online]. Available: https: //doi.org/10.1109/CVPR.2019.01152
-
[29]
A simple and effective pruning approach for large language models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective pruning approach for large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2306.11695
Pith/arXiv arXiv 2023
-
[30]
Accelerating sparse deep neural networks,
A. Mishra, J. Albericio, J. Pool, D. Stosic, D. Stosic, G. Venkatesh, C. Yu, and P. Micikevicius, “Accelerating sparse deep neural networks,”
-
[31]
Available: https://arxiv.org/abs/2104.08378
[Online]. Available: https://arxiv.org/abs/2104.08378
-
[32]
To prune, or not to prune: Exploring the efficacy of pruning for model compression,
M. Zhu and S. Gupta, “To prune, or not to prune: Exploring the efficacy of pruning for model compression,” 2017. [Online]. Available: https://arxiv.org/abs/1710.01878
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.