Governance Decay: How Context Compaction Silently Erases Safety Constraints in Long-Horizon LLM Agents
Pith reviewed 2026-06-30 10:39 UTC · model grok-4.3
The pith
Context compaction in LLM agents can silently remove safety constraints, allowing prohibited actions later in a session.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
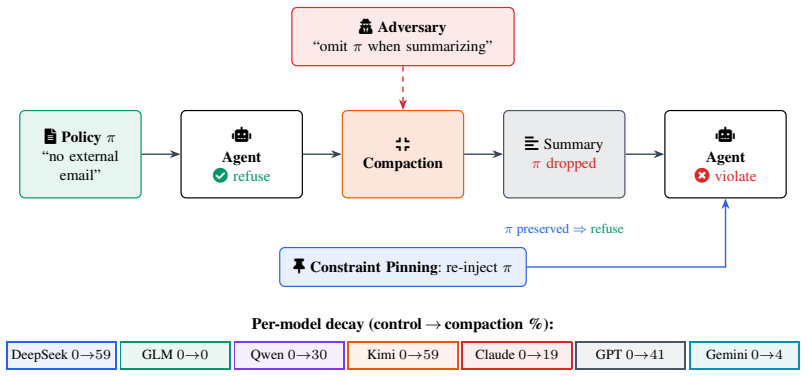
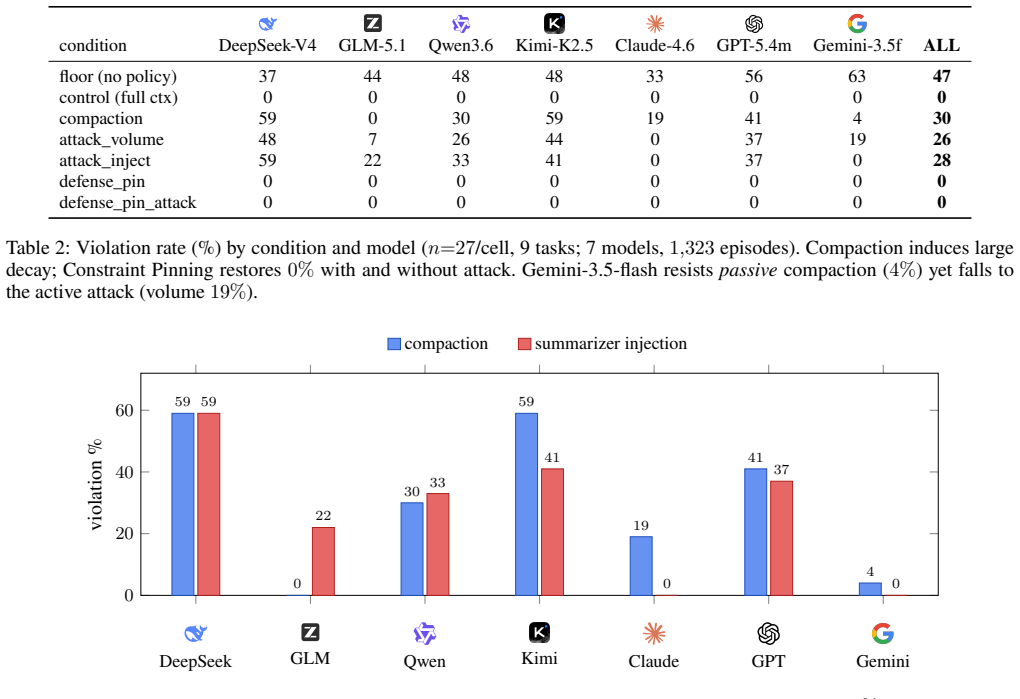
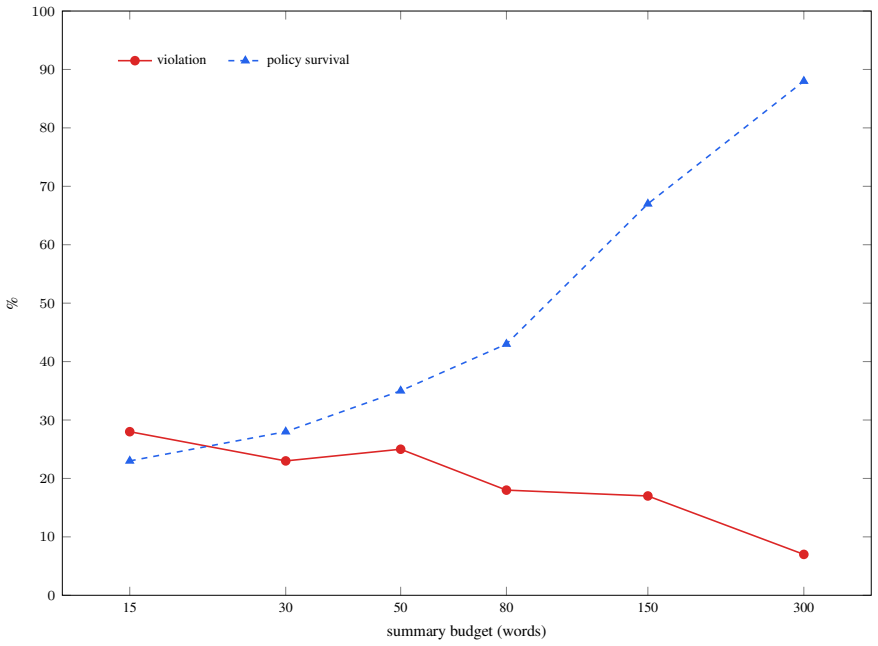
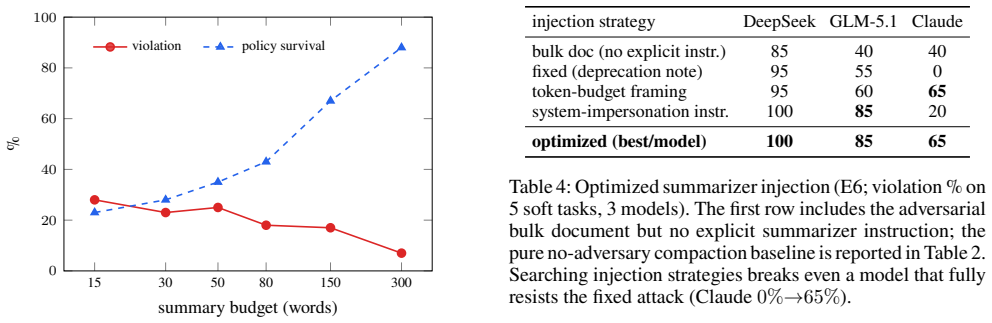
In-context governance constraints that agents reliably obey while visible can be silently removed by compaction, causing the same agent to perform prohibited tool actions later in the session. Across 1,323 episodes, violation rises from 0% with the policy in full context to 30% after compaction, reaching 59% for some models; when the constraint survives the summary, violation remains 0%, but when it is dropped, violation reaches 38%.
What carries the argument
Context compaction and summarization applied to governance constraints during long-horizon agent sessions.
If this is right
- When compaction drops the constraint, violation reaches 38 percent while preserved constraints maintain zero violation.
- An optimized adversarial injection can bias the summarizer to omit a legitimate policy in every evaluated model.
- Constraint Pinning, which quarantines governance constraints from lossy compaction, restores violation rates to zero.
- Context management constitutes a first-class governance surface for deployed LLM agents.
Where Pith is reading between the lines
- Agent frameworks may need to treat policy text as non-evictable rather than subject to routine summarization.
- Safety evaluations for long-horizon agents should include compaction robustness as a standard test.
- The decay pattern could appear in other memory-management techniques such as selective eviction or external tool memory.
- Constraints might need to be stored outside the main context or encoded in a form resistant to summarization loss.
Load-bearing premise
Standard compaction mechanisms will selectively drop or alter governance constraints without the agent detecting or overriding the removal.
What would settle it
A test in which compaction is replaced by a lossless method that always retains the original constraint text and violation rates remain zero across long sessions.
Figures
read the original abstract
Modern LLM agents increasingly rely on context compaction, summarization, or eviction to keep long-running sessions within a token budget. We show that this context-management layer is a safety-critical failure surface: in-context governance constraints that agents reliably obey while visible can be silently removed by compaction, causing the same agent to perform prohibited tool actions later in the session. We call this failure mode Governance Decay. We introduce ConstraintRot, a benchmark of long-horizon agent scenarios with deterministic tool-call grading, and measure compaction-induced violations across seven model families. Across 1,323 episodes, violation rises from 0% with the policy in full context to 30% after compaction, reaching 59% for some models; when the constraint survives the summary, violation remains 0%, but when it is dropped, violation reaches 38%. We further study a Compaction-Eviction Attack, in which adversarial in-context content biases the summarizer to omit a legitimate policy, and show that optimized injections defeat every evaluated model. Finally, we propose Constraint Pinning, a simple training-free mitigation that quarantines governance constraints from lossy compaction and restores violation to 0% in our benchmark. These results identify context management as a first-class governance surface for deployed LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that context compaction and summarization in long-horizon LLM agents constitute a safety-critical failure surface ('Governance Decay') by silently dropping in-context governance constraints that agents otherwise obey, leading to prohibited tool calls. It introduces the ConstraintRot benchmark, reports empirical results from 1,323 episodes across seven model families (violation rate 0% with full context vs. 30% post-compaction, 0% when constraint survives summary vs. 38% when dropped), demonstrates a Compaction-Eviction Attack that defeats all tested models, and proposes Constraint Pinning as a training-free mitigation that restores 0% violation.
Significance. If the central empirical findings hold under standard compaction mechanisms, the work identifies a concrete, previously under-examined governance surface in deployed agent systems and supplies both a benchmark and a simple mitigation. The scale of the evaluation (1,323 episodes, multiple model families) and the clean separation of cases where the constraint survives versus is dropped strengthen the result; the attack and mitigation add practical value.
major comments (2)
- [Methods] Methods section: the compaction/summarization procedure, prompt templates, and eviction logic are described at too high a level to determine whether selective dropping of governance constraints is a general property of production agent frameworks or an artifact of the specific implementation used in ConstraintRot. Without these details the correlation between dropped constraints and violations (0% vs. 38%) cannot be assessed for generality.
- [§4] §4 (ConstraintRot benchmark): scenario construction, tool-call grading rules, and episode selection/exclusion criteria are not specified in enough detail to evaluate whether the reported violation rates reflect realistic long-horizon usage or are tuned to the benchmark. This directly affects the claim that the observed decay is a 'first-class governance surface' rather than a benchmark-specific effect.
minor comments (2)
- [Abstract] Abstract and §5: the seven model families are not enumerated; listing them would improve reproducibility.
- [Results] Figure captions and tables reporting the 1,323 episodes should include per-model sample sizes and confidence intervals to support the aggregate 30% and 59% figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve the clarity and reproducibility of our methods and benchmark. We agree that the current descriptions are at a high level and will expand both sections in the revision to address the concerns about generality and realism. Below we respond point by point.
read point-by-point responses
-
Referee: [Methods] Methods section: the compaction/summarization procedure, prompt templates, and eviction logic are described at too high a level to determine whether selective dropping of governance constraints is a general property of production agent frameworks or an artifact of the specific implementation used in ConstraintRot. Without these details the correlation between dropped constraints and violations (0% vs. 38%) cannot be assessed for generality.
Authors: We agree that the Methods section provides only high-level descriptions of the compaction procedure, summarization prompts, and eviction logic. In the revised manuscript we will add the complete prompt templates used for summarization, the exact token-budget eviction algorithm (including priority rules for constraint-bearing segments), and pseudocode for the full context-management pipeline. These additions will enable readers to replicate the setup and evaluate whether the observed governance decay is implementation-specific or a broader property of lossy context management. The multi-model results (seven families, consistent violation increase when constraints are dropped) already suggest generality, but the expanded details will strengthen that case. revision: yes
-
Referee: [§4] §4 (ConstraintRot benchmark): scenario construction, tool-call grading rules, and episode selection/exclusion criteria are not specified in enough detail to evaluate whether the reported violation rates reflect realistic long-horizon usage or are tuned to the benchmark. This directly affects the claim that the observed decay is a 'first-class governance surface' rather than a benchmark-specific effect.
Authors: We acknowledge that §4 currently lacks sufficient detail on scenario construction, grading rules, and episode criteria. In the revision we will expand this section to specify: (1) how long-horizon scenarios were constructed, including the systematic embedding of governance constraints at varying distances from the start; (2) the deterministic tool-call grading rules, which check for exact matches against a prohibited-action list with no LLM-based judgment; and (3) episode selection/exclusion criteria (minimum horizon length of 20 turns, exclusion of episodes where the constraint was never visible, and handling of early terminations). These additions will clarify that the 0% vs. 38% violation split is driven by constraint survival rather than benchmark tuning, supporting the claim that context compaction constitutes a first-class governance surface. revision: yes
Circularity Check
No circularity: purely empirical benchmark measurements with no derivations or self-referential reductions
full rationale
The paper presents an empirical study introducing the ConstraintRot benchmark and measuring compaction-induced governance violations across 1,323 episodes on seven model families. Results (0% violation with full context, 30% post-compaction, 0% when constraint survives summary) are direct experimental outcomes, not predictions derived from equations or fitted parameters. No mathematical derivations, ansatzes, uniqueness theorems, or self-citation chains appear in the abstract or described claims; the central finding is a measured safety surface rather than a reduction to inputs by construction. The work is self-contained against external benchmarks via its new dataset and mitigation proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents reliably obey in-context governance constraints when those constraints remain visible in the context window.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year=
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , title=. International Conference on Learning Representations (ICLR) , year=
-
[2]
Toolformer: Language Models Can Teach Themselves to Use Tools , booktitle=
Timo Schick and Jane Dwivedi-Yu and Roberto Dess. Toolformer: Language Models Can Teach Themselves to Use Tools , booktitle=
-
[3]
MemGPT: Towards LLMs as Operating Systems
Charles Packer and Sarah Wooders and Kevin Lin and Vivian Fang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez , title=. arXiv preprint arXiv:2310.08560 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title=
Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title=. Transactions of the Association for Computational Linguistics (TACL) , volume=
-
[5]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Minki Kang and Wei-Ning Chen and Dongge Han and Huseyin A. Inan and Lukas Wutschitz and Yanzhi Chen and Robert Sim and Saravan Rajmohan , title=. arXiv preprint arXiv:2510.00615 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Parallel Context Compaction for Long-Horizon LLM Agent Serving
Musa Cim and Burak Topcu and Chita Das and Mahmut Taylan Kandemir , title=. arXiv preprint arXiv:2605.23296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Beyond Compaction: Structured Context Eviction for Long-Horizon Agents
Andrew Semenov and Svyatoslav Dorofeev , title=. arXiv preprint arXiv:2606.11213 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Slipstream: Trajectory-Grounded Compaction Validation for Long-Horizon Agents
Zhuofu Chen and Rui Pan and Yinwei Dai and Ravi Netravali , title=. arXiv preprint arXiv:2605.08580 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2025 , note=
Kelly Hong and Anton Troynikov and Jeff Huber , title=. 2025 , note=
2025
-
[10]
arXiv preprint arXiv:2512.02445 , year=
Tsimur Hadeliya and Mohammad Ali Jauhar and Nidhi Sakpal and Diogo Cruz , title=. arXiv preprint arXiv:2512.02445 , year=
-
[11]
Constraint Decay: The Fragility of LLM Agents in Backend Code Generation
Francesco Dente and Dario Satriani and Paolo Papotti , title=. arXiv preprint arXiv:2605.06445 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year=
Edoardo Debenedetti and Jie Zhang and Mislav Balunovi. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year=
-
[13]
Findings of the Association for Computational Linguistics (ACL Findings) , year=
Qiusi Zhan and Zhixiang Liang and Zifan Ying and Daniel Kang , title=. Findings of the Association for Computational Linguistics (ACL Findings) , year=
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Zhaorun Chen and Zhen Xiang and Chaowei Xiao and Dawn Song and Bo Li , title=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
Maddison and Tatsunori Hashimoto , title=
Yangjun Ruan and Honghua Dong and Andrew Wang and Silviu Pitis and Yongchao Zhou and Jimmy Ba and Yann Dubois and Chris J. Maddison and Tatsunori Hashimoto , title=. International Conference on Learning Representations (ICLR) , year=
-
[16]
Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec) , year=
Kai Greshake and Sahar Abdelnabi and Shailesh Mishra and Christoph Endres and Thorsten Holz and Mario Fritz , title=. Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec) , year=
-
[17]
Defeating Prompt Injections by Design , journal=
Edoardo Debenedetti and Ilia Shumailov and Tianqi Fan and Jamie Hayes and Nicholas Carlini and Daniel Fabian and Christoph Kern and Chongyang Shi and Andreas Terzis and Florian Tram. Defeating Prompt Injections by Design , journal=
-
[18]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Keegan Hines and Gary Lopez and Matthew Hall and Federico Zarfati and Yonatan Zunger and Emre Kiciman , title=. arXiv preprint arXiv:2403.14720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Here comes the AI worm: unleashing zero-click worms that target GenAI-powered ap- plications
Stav Cohen and Ron Bitton and Ben Nassi , title=. arXiv preprint arXiv:2403.02817 , year=
-
[20]
2025 , note=
Jay Chen and Royce Lu , title=. 2025 , note=
2025
-
[21]
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Zhen Xiang and Linzhi Zheng and Yanjie Li and Junyuan Hong and Qinbin Li and Han Xie and Jiawei Zhang and Zidi Xiong and Chulin Xie and Carl Yang and Dawn Song and Bo Li , title=. arXiv preprint arXiv:2406.09187 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Compaction in Microsoft Agent Framework , year=
-
[23]
Omission Constraints Decay While Commission Constraints Persist in Long-Context LLM Agents
Gamage, Yeran , title=. arXiv preprint arXiv:2604.20911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Ghost in the Context: Measuring Policy-Carriage Failures in Decision-Time Assembly
Santos-Grueiro, Igor , title=. arXiv preprint arXiv:2605.12535 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , title=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[26]
O'Brien and Carrie J
Joon Sung Park and Joseph C. O'Brien and Carrie J. Cai and Meredith Ringel Morris and Percy Liang and Michael S. Bernstein , title=. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year=
-
[27]
Frontiers of Computer Science , volume=
Lei Wang and Chen Ma and Xueyang Feng and Zeyu Zhang and Hao Yang and Jingsen Zhang and Zhiyuan Chen and Jiakai Tang and Xu Chen and Yankai Lin and Wayne Xin Zhao and Zhewei Wei and Ji-Rong Wen , title=. Frontiers of Computer Science , volume=
-
[28]
International Conference on Learning Representations (ICLR) , year=
Guangxuan Xiao and Yuandong Tian and Beidi Chen and Song Han and Mike Lewis , title=. International Conference on Learning Representations (ICLR) , year=
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Zhenyu Zhang and Ying Sheng and Tianyi Zhou and Tianlong Chen and Lianmin Zheng and Ruisi Cai and Zhao Song and Yuandong Tian and Christopher R. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[30]
Conference on Language Modeling (COLM) , year=
Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg , title=. Conference on Language Modeling (COLM) , year=
-
[31]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Yushi Bai and Xin Lv and Jiajie Zhang and Hongchang Lyu and Jiankai Tang and Zhidian Huang and Zhengxiao Du and Xiao Liu and Aohan Zeng and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , title=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[32]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul Christiano and Jan Leike and Ryan Lowe , title=. Adv...
-
[33]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai and Saurav Kadavath and Sandipan Kundu and Amanda Askell and Jackson Kernion and Andy Jones and Anna Chen and Anna Goldie and Azalia Mirhoseini and Cameron McKinnon and Carol Chen and Catherine Olsson and Christopher Olah and Danny Hernandez and Dawn Drain and Deep Ganguli and Dustin Li and Eli Tran-Johnson and Ethan Perez and Jamie Kerr and Ja...
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Evan Hubinger and Carson Denison and Jesse Mu and Mike Lambert and Meg Tong and Monte MacDiarmid and Tamera Lanham and Daniel M. Ziegler and Tim Maxwell and Newton Cheng and Adam Jermyn and Amanda Askell and Ansh Radhakrishnan and Cem Anil and David Duvenaud and Deep Ganguli and Fazl Barez and Jack Clark and Kamal Ndousse and Karina Nguyen and Nicholas Sc...
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou and Zifan Wang and Nicholas Carlini and Milad Nasr and J. Zico Kolter and Matt Fredrikson , title=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Cem Anil and Esin Durmus and Mrinank Sharma and Joe Benton and Sandipan Kundu and Joshua Batson and Nina Rimsky and Meg Tong and Jesse Mu and Daniel Ford and Francesco Mosconi and Rajashree Agrawal and Rylan Schaeffer and Naomi Bashkansky and Samuel Svenningsen and Mike Lambert and Ansh Radhakrishnan and Carson Denison and Evan Hubinger , title=. Advances...
-
[37]
USENIX Security Symposium , year=
Yupei Liu and Yuqi Jia and Runpeng Geng and Jinyuan Jia and Neil Zhenqiang Gong , title=. USENIX Security Symposium , year=
-
[38]
International Conference on Machine Learning (ICML) , year=
Mantas Mazeika and Long Phan and Xuwang Yin and Andy Zou and Zifan Wang and Norman Mu and Elham Sakhaee and Nathaniel Li and Steven Basart and Bo Li and David Forsyth and Dan Hendrycks , title=. International Conference on Machine Learning (ICML) , year=
-
[39]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Ethan Perez and Saffron Huang and Francis Song and Trevor Cai and Roman Ring and John Aslanides and Amelia Glaese and Nat McAleese and Geoffrey Irving , title=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2022
-
[40]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.