OASIS: Observation-Aware Simulation-Based Inference via Distributional Matching
Pith reviewed 2026-06-26 09:49 UTC · model grok-4.3
The pith
OASIS builds a pseudo-posterior by reweighting prior samples to match the full distribution of observed data after embedding measurement errors and selection effects inside the simulator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
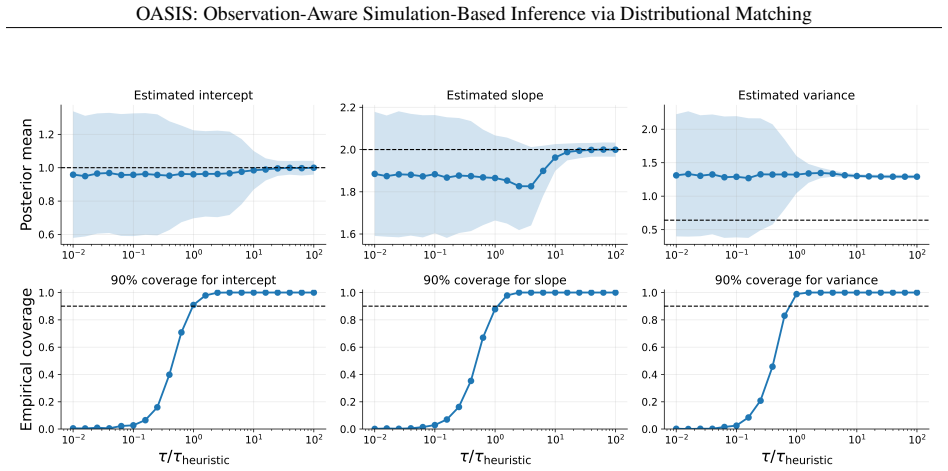
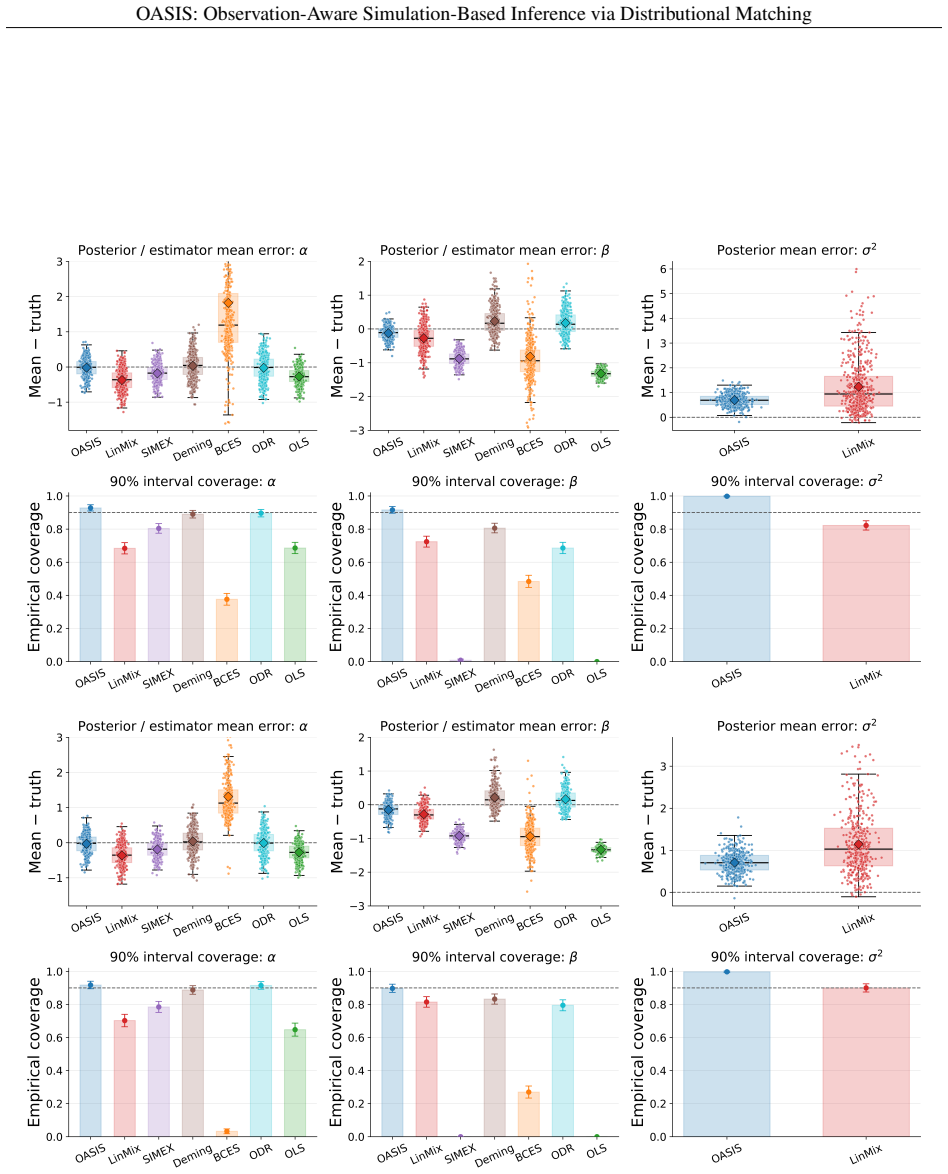
OASIS constructs a pseudo-posterior by reweighting prior samples according to a maximum mean discrepancy loss between the empirical distributions of the observed data and forward-simulated observations that include the full observation model. It supplies theoretical guarantees of Monte Carlo consistency, convergence of the empirical pseudo-posterior to its population version, and posterior concentration on the MMD-identified parameter set, with consistency for the true parameter when the model is correctly specified and identifiable. In controlled experiments it recovers parameters robustly under heterogeneous non-Gaussian noise, and it is demonstrated on galaxy cluster data linked by nonlin
What carries the argument
Maximum mean discrepancy loss applied to empirical distributions of real observations versus forward-simulated observations that embed the full observation model, used to reweight prior samples into a pseudo-posterior.
If this is right
- Parameter recovery remains robust under heterogeneous and non-Gaussian measurement noise without requiring summary statistics.
- The method produces well-calibrated uncertainty estimates in settings with nonlinear scaling relations and incomplete data coverage.
- Theoretical guarantees ensure the empirical pseudo-posterior converges to the population version and concentrates on the MMD-identified set.
- Inference occurs directly at the level of observed-data distributions, avoiding both handcrafted summaries and neural network surrogates.
Where Pith is reading between the lines
- The same reweighting approach could be tested in domains such as particle physics or medical imaging where simulators can incorporate analogous measurement pipelines.
- Performance may depend on kernel choice in the MMD; adaptive or learned kernels could be explored as an extension for high-dimensional data.
- Because the method yields a weighted sample rather than a density estimate, it may integrate naturally with downstream tasks that require posterior samples for propagation of uncertainty.
Load-bearing premise
The complete observation model including all measurement errors, selection functions, and survey transformations can be accurately embedded inside the simulator so that simulated observations are statistically comparable to real data.
What would settle it
Run a controlled simulation where a known selection function is deliberately omitted from the embedded observation model and check whether the resulting pseudo-posterior concentrates away from the true parameter values.
Figures
read the original abstract
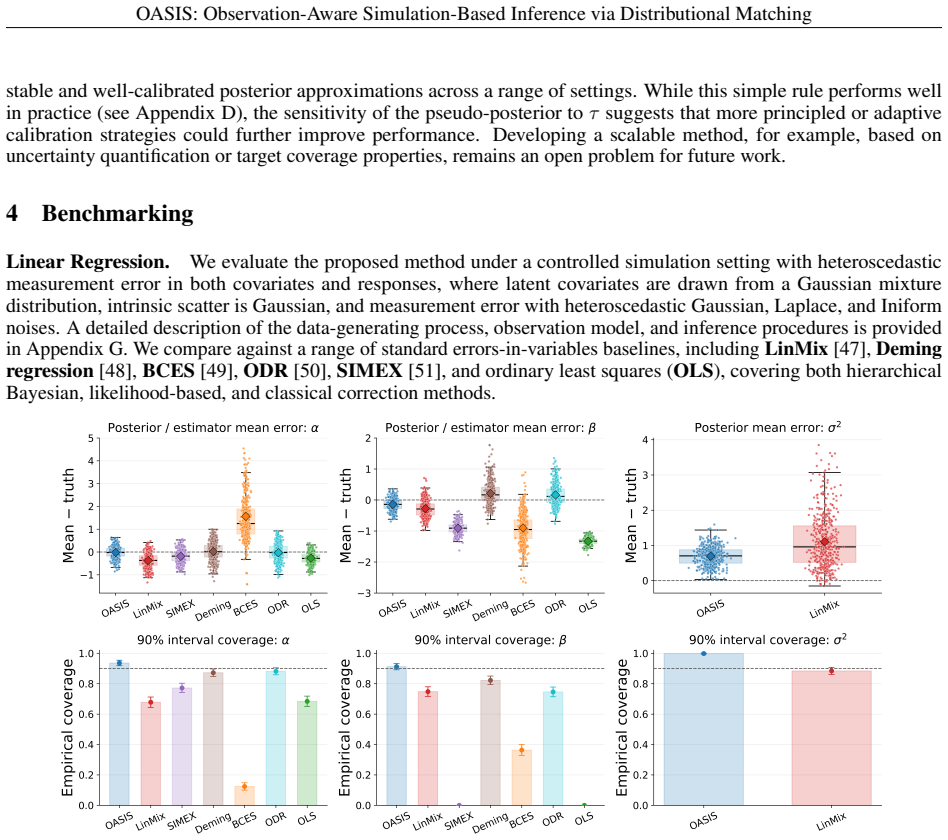
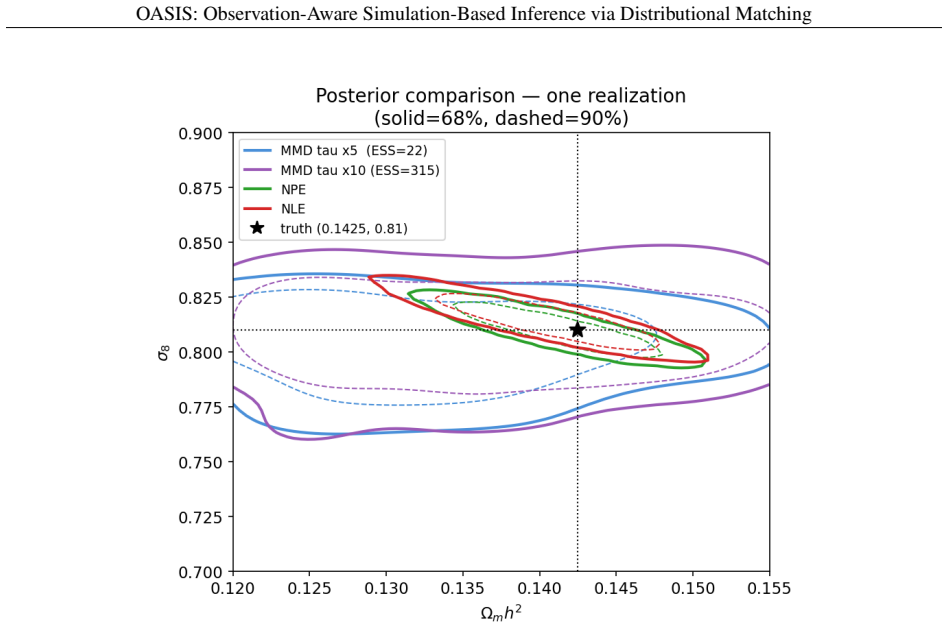
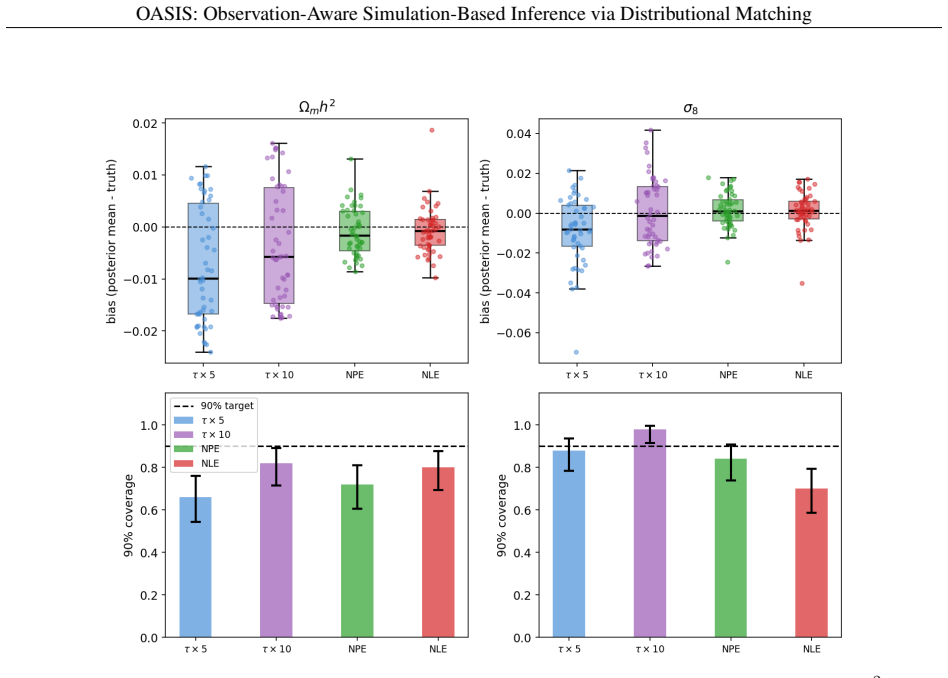
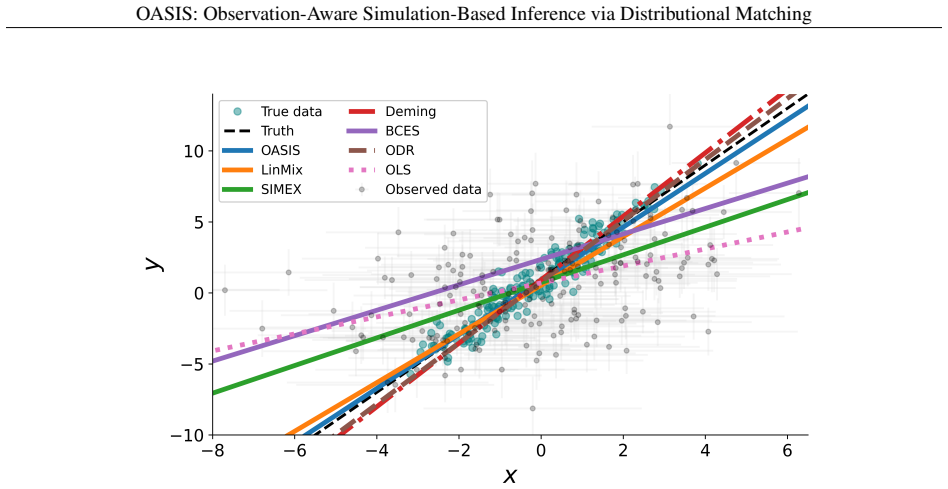
We introduce OASIS, a simulation-based inference framework for scientific settings where observations are distorted by measurement error, selection effects, and other survey-specific transformations. In many real applications, simulators generate latent, noiseless quantities, while the data are observed only after passing through a complex observational pipeline. Standard simulation-based inference methods often ignore this distinction, comparing observations to idealized simulator outputs or relying on low-dimensional summaries that can miss important structure. OASIS addresses this mismatch by explicitly embedding the observation model into the simulator and performing inference directly at the level of observed-data distributions. The method constructs a pseudo-posterior by reweighting prior samples according to a maximum mean discrepancy (MMD) loss between the empirical distributions of the observed data and forward-simulated observations, thereby avoiding both handcrafted summaries and learned neural surrogates. We provide theoretical guarantees for Monte Carlo consistency, convergence of the empirical pseudo-posterior to its population counterpart, and posterior concentration on the MMD-identified parameter set, with consistency for the true parameter under correct specification and identifiability. In controlled errors-in-variables regression experiments, OASIS delivers robust parameter recovery and well-calibrated uncertainty under heterogeneous and non-Gaussian measurement noise. We then demonstrate the method on a realistic cosmological application involving galaxy cluster observations across multiple wavelengths, in which latent physical properties are linked to observables through nonlinear scaling relations, heteroscedastic errors, selection functions, and incomplete coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OASIS, a simulation-based inference framework that embeds the full observation model (measurement error, selection functions, survey transformations) into the simulator and constructs a pseudo-posterior by reweighting prior samples according to an MMD loss between the empirical distribution of the real observations and the forward-simulated observations. It states theoretical guarantees for Monte Carlo consistency, convergence of the empirical pseudo-posterior to its population version, and posterior concentration on the MMD-identified parameter set (with consistency for the true parameter under correct specification and identifiability). The approach is illustrated on errors-in-variables regression with heterogeneous non-Gaussian noise and on a realistic multi-wavelength galaxy-cluster cosmology example involving nonlinear scaling relations, heteroscedastic errors, and incomplete coverage.
Significance. If the stated guarantees hold, the work is significant for domains that rely on simulators producing latent quantities while data are subject to complex observational pipelines. By operating directly at the level of observed-data distributions via MMD reweighting, the method avoids both handcrafted summaries and neural density estimators while supplying explicit consistency results under standard kernel and identifiability conditions. The cosmological demonstration, which incorporates realistic selection and scaling effects, illustrates practical utility.
minor comments (3)
- [Method section] The description of the MMD estimator (including choice of kernel and bandwidth) should be stated explicitly in the main text rather than deferred to supplementary material, as this choice directly affects the finite-sample behavior of the reweighting step.
- [Experiments section] In the regression experiments, the reported recovery metrics would be strengthened by including a direct comparison against at least one standard SBI baseline (e.g., ABC or neural posterior estimation) on the same simulated data sets.
- Notation for the empirical versus population MMD should be introduced once and used consistently; occasional reuse of the same symbol for both quantities can be confusing on first reading.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, including the recognition of its significance for simulation-based inference in settings with complex observational pipelines, and for the recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity identified
full rationale
The paper constructs a pseudo-posterior by reweighting prior samples with an MMD loss between empirical observed and forward-simulated distributions after embedding the observation model in the simulator. Theoretical guarantees for Monte Carlo consistency, empirical convergence, and posterior concentration on the MMD-identified set are stated explicitly under the assumptions of correct specification and identifiability, without any equation or step reducing these results to a quantity fitted from the same data, a self-definitional loop, or a load-bearing self-citation chain. The approach uses standard distributional matching and does not rename known results or smuggle ansatzes via prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The observation model can be accurately embedded inside the simulator
- domain assumption The MMD identifies the parameter set under correct specification and identifiability
Reference graph
Works this paper leans on
-
[1]
Physics- informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics- informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[2]
Chapman and Hall/CRC, 2006
Raymond J Carroll, David Ruppert, Leonard A Stefanski, and Ciprian M Crainiceanu.Measurement error in nonlinear models: a modern perspective. Chapman and Hall/CRC, 2006
2006
-
[3]
John Wiley & Sons, 2009
Wayne A Fuller.Measurement error models. John Wiley & Sons, 2009
2009
-
[4]
The frontier of simulation-based inference.Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020
Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference.Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020
2020
-
[5]
Approximate bayesian computation in population genetics.Genetics, 162(4):2025–2035, 2002
Mark A Beaumont, Wenyang Zhang, and David J Balding. Approximate bayesian computation in population genetics.Genetics, 162(4):2025–2035, 2002
2025
-
[6]
CRC press, 2018
Scott A Sisson, Yanan Fan, and Mark Beaumont.Handbook of approximate Bayesian computation. CRC press, 2018
2018
-
[7]
Sequential neural likelihood: Fast likelihood-free inference with autoregressive flows
George Papamakarios, David Sterratt, and Iain Murray. Sequential neural likelihood: Fast likelihood-free inference with autoregressive flows. InThe 22nd international conference on artificial intelligence and statistics, pages 837–848. PMLR, 2019
2019
-
[8]
Kernel bayes’ rule.Advances in neural information processing systems, 24, 2011
Kenji Fukumizu, Le Song, and Arthur Gretton. Kernel bayes’ rule.Advances in neural information processing systems, 24, 2011
2011
-
[9]
K2-abc: Approximate bayesian computation with kernel embeddings
Mijung Park, Wittawat Jitkrittum, and Dino Sejdinovic. K2-abc: Approximate bayesian computation with kernel embeddings. InArtificial intelligence and statistics, pages 398–407. PMLR, 2016
2016
-
[10]
Kyle Cranmer, Juan Pavez, and Gilles Louppe. Approximating likelihood ratios with calibrated discriminative classifiers.arXiv preprint arXiv:1506.02169, 2015
Pith/arXiv arXiv 2015
-
[11]
Fast ε-free inference of simulation models with bayesian conditional density estimation.Advances in neural information processing systems, 29, 2016
George Papamakarios and Iain Murray. Fast ε-free inference of simulation models with bayesian conditional density estimation.Advances in neural information processing systems, 29, 2016
2016
-
[12]
Likelihood-free inference with emulator networks
Jan-Matthis Lueckmann, Giacomo Bassetto, Theofanis Karaletsos, and Jakob H Macke. Likelihood-free inference with emulator networks. InSymposium on advances in approximate Bayesian inference, pages 32–53. PMLR, 2019
2019
-
[13]
Likelihood-free mcmc with amortized approximate ratio estimators
Joeri Hermans, V olodimir Begy, and Gilles Louppe. Likelihood-free mcmc with amortized approximate ratio estimators. InInternational conference on machine learning, pages 4239–4248. PMLR, 2020
2020
-
[14]
Neural methods for amortized inference
Andrew Zammit-Mangion, Matthew Sainsbury-Dale, and Raphaël Huser. Neural methods for amortized inference. Annual Review of Statistics and Its Application, 12(1):311–335, 2025
2025
-
[15]
A crisis in simulation-based inference? beware, your posterior approximations can be unfaithful.Transactions on Machine Learning Research, 2022
Joeri Hermans, Arnaud Delaunoy, François Rozet, Antoine Wehenkel, V olodimir Begy, and Gilles Louppe. A crisis in simulation-based inference? beware, your posterior approximations can be unfaithful.Transactions on Machine Learning Research, 2022
2022
-
[16]
A kernel method for the two-sample-problem.Advances in neural information processing systems, 19, 2006
Arthur Gretton, Karsten Borgwardt, Malte Rasch, Bernhard Schölkopf, and Alex Smola. A kernel method for the two-sample-problem.Advances in neural information processing systems, 19, 2006
2006
-
[17]
Ritwik Vashistha, Jeff M Phillips, Abhra Sarkar, and Arya Farahi. Convolutional maximum mean discrepancy for inference in noisy data.arXiv preprint arXiv:2604.12022, 2026
Pith/arXiv arXiv 2026
-
[18]
Stochastic relaxation, gibbs distributions, and the bayesian restoration of images.IEEE Transactions on pattern analysis and machine intelligence, (6):721–741, 1984
Stuart Geman and Donald Geman. Stochastic relaxation, gibbs distributions, and the bayesian restoration of images.IEEE Transactions on pattern analysis and machine intelligence, (6):721–741, 1984. 10 OASIS: Observation-Aware Simulation-Based Inference via Distributional Matching
1984
-
[19]
Gibbs posterior for variable selection in high-dimensional classification and data mining.The Annals of Statistics, pages 2207–2231, 2008
Wenxin Jiang and Martin A Tanner. Gibbs posterior for variable selection in high-dimensional classification and data mining.The Annals of Statistics, pages 2207–2231, 2008
2008
-
[20]
A general framework for updating belief distributions.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(5):1103–1130, 2016
Pier Giovanni Bissiri, Chris C Holmes, and Stephen G Walker. A general framework for updating belief distributions.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(5):1103–1130, 2016
2016
-
[21]
Arya Farahi, Jonah Rose, and Paul Torrey. Simulation-based inference via regression projection and batched discrepancies.arXiv preprint arXiv:2602.03613, 2026
arXiv 2026
-
[22]
Cosmological parameters from observations of galaxy clusters.Annual Review of Astronomy and Astrophysics, 49(1):409–470, 2011
Steven W Allen, August E Evrard, and Adam B Mantz. Cosmological parameters from observations of galaxy clusters.Annual Review of Astronomy and Astrophysics, 49(1):409–470, 2011
2011
-
[23]
Proper rounding of the measurement results under normality assumptions.Measurement Science and Technology, 11:1659, 2000
Gejza Wimmer, Viktor Witkovsk`y, and Tomas Duby. Proper rounding of the measurement results under normality assumptions.Measurement Science and Technology, 11:1659, 2000
2000
-
[24]
A large sample of calibration stars for Gaia: log g from Kepler and CoRoT fields.Monthly Notices of the Royal Astronomical Society, 431:2419–2432, 2013
OL Creevey, F Thévenin, S Basu, WJ Chaplin, L Bigot, Y Elsworth, D Huber, MJPFG Monteiro, and A Serenelli. A large sample of calibration stars for Gaia: log g from Kepler and CoRoT fields.Monthly Notices of the Royal Astronomical Society, 431:2419–2432, 2013
2013
-
[25]
Calibration concordance for astronomical instruments via multiplicative shrinkage.Journal of the American Statistical Association, 114(527):1018–1037, 2019
Yang Chen, Xiao-Li Meng, Xufei Wang, David A van Dyk, Herman L Marshall, and Vinay L Kashyap. Calibration concordance for astronomical instruments via multiplicative shrinkage.Journal of the American Statistical Association, 114(527):1018–1037, 2019
2019
-
[26]
Henry W Leung and Jo Bovy. Simultaneous calibration of spectro-photometric distances and the gaia dr2 parallax zero-point offset with deep learning.Monthly Notices of the Royal Astronomical Society, 489:2079–2096, 2019
2079
-
[27]
Kinematics in young star clusters and associations with gaia dr2.The Astrophysical Journal, 870:32, 2019
Michael A Kuhn, Lynne A Hillenbrand, Alison Sills, Eric D Feigelson, and Konstantin V Getman. Kinematics in young star clusters and associations with gaia dr2.The Astrophysical Journal, 870:32, 2019
2019
-
[28]
Beyond the yard line: Accommodating rounded sports data in statistical models.The American Statistician, pages 1–10, 2026
Amanda K Glazer, Layla Parast, and Mevin B Hooten. Beyond the yard line: Accommodating rounded sports data in statistical models.The American Statistician, pages 1–10, 2026
2026
-
[29]
A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
2012
-
[30]
Asymptotic normality, concentration, and coverage of generalized posteriors.Journal of Machine Learning Research, 22(168):1–53, 2021
Jeffrey W Miller. Asymptotic normality, concentration, and coverage of generalized posteriors.Journal of Machine Learning Research, 22(168):1–53, 2021
2021
-
[31]
Robust bayesian inference via coarsening.Journal of the American Statistical Association, 2019
Jeffrey W Miller and David B Dunson. Robust bayesian inference via coarsening.Journal of the American Statistical Association, 2019
2019
-
[32]
Assigning a value to a power likelihood in a general bayesian model
Chris C Holmes and Stephen G Walker. Assigning a value to a power likelihood in a general bayesian model. Biometrika, 104(2):497–503, 2017
2017
-
[33]
Direct gibbs posterior inference on risk minimizers: Construction, concentration, and calibration
Ryan Martin and Nicholas Syring. Direct gibbs posterior inference on risk minimizers: Construction, concentration, and calibration. InHandbook of Statistics, volume 47, pages 1–41. Elsevier, 2022
2022
-
[34]
Asymptotic properties of approximate bayesian computation.Biometrika, 105(3):593–607, 2018
David T Frazier, Gael M Martin, Christian P Robert, and Judith Rousseau. Asymptotic properties of approximate bayesian computation.Biometrika, 105(3):593–607, 2018
2018
-
[35]
Statistical inference for noisy nonlinear ecological dynamic systems.Nature, 466(7310):1102– 1104, 2010
Simon N Wood. Statistical inference for noisy nonlinear ecological dynamic systems.Nature, 466(7310):1102– 1104, 2010
2010
-
[36]
Bayesian synthetic likelihood.Journal of Computational and Graphical Statistics, 27(1):1–11, 2018
Leah F Price, Christopher C Drovandi, Anthony Lee, and David J Nott. Bayesian synthetic likelihood.Journal of Computational and Graphical Statistics, 27(1):1–11, 2018
2018
-
[37]
Bayesian indirect inference using a parametric auxiliary model.Statistical Science, 30(1):72–95, 2015
Christopher C Drovandi, Anthony N Pettitt, and Anthony Lee. Bayesian indirect inference using a parametric auxiliary model.Statistical Science, 30(1):72–95, 2015
2015
-
[38]
Abc and indirect inference
Christopher C Drovandi. Abc and indirect inference. InHandbook of Approximate Bayesian Computation, pages 179–209. Chapman and Hall/CRC, 2018
2018
-
[39]
Mmd-bayes: Robust bayesian estimation via maximum mean discrepancy
Badr-Eddine Chérief-Abdellatif and Pierre Alquier. Mmd-bayes: Robust bayesian estimation via maximum mean discrepancy. InSymposium on Advances in Approximate Bayesian Inference, pages 1–21. PMLR, 2020
2020
-
[40]
Approximate bayesian computation with the wasserstein distance.Journal of the Royal Statistical Society Series B: Statistical Methodology, 81(2):235–269, 2019
Espen Bernton, Pierre E Jacob, Mathieu Gerber, and Christian P Robert. Approximate bayesian computation with the wasserstein distance.Journal of the Royal Statistical Society Series B: Statistical Methodology, 81(2):235–269, 2019
2019
-
[41]
Approximate bayesian computation with the sliced-wasserstein distance
Kimia Nadjahi, Valentin De Bortoli, Alain Durmus, Roland Badeau, and Umut ¸ Sim¸ sekli. Approximate bayesian computation with the sliced-wasserstein distance. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5470–5474. IEEE, 2020. 11 OASIS: Observation-Aware Simulation-Based Inference via Distribu...
2020
-
[42]
Anirban Chatterjee, Ziang Niu, and Bhaswar B Bhattacharya. A kernel-based conditional two-sample test using nearest neighbors (with applications to calibration, regression curves, and simulation-based inference).arXiv preprint arXiv:2407.16550, 2024
arXiv 2024
-
[43]
Cambridge university press, 2000
Aad W Van der Vaart.Asymptotic statistics, volume 3. Cambridge university press, 2000
2000
-
[44]
Gibbs posterior convergence and the thermodynamic formalism.The Annals of Applied Probability, 32(1):461–496, 2022
Kevin McGoff, Sayan Mukherjee, and Andrew B Nobel. Gibbs posterior convergence and the thermodynamic formalism.The Annals of Applied Probability, 32(1):461–496, 2022
2022
-
[45]
Bayes posterior convergence for loss functions via almost additive thermodynamic formalism.Journal of Statistical Physics, 186(3):35, 2022
Artur O Lopes, Silvia RC Lopes, and Paulo Varandas. Bayes posterior convergence for loss functions via almost additive thermodynamic formalism.Journal of Statistical Physics, 186(3):35, 2022
2022
-
[46]
Modern bayesian asymptotics.Statistical Science, pages 111–117, 2004
Stephen G Walker. Modern bayesian asymptotics.Statistical Science, pages 111–117, 2004
2004
-
[47]
Some aspects of measurement error in linear regression of astronomical data.The Astrophysical Journal, 665(2):1489–1506, 2007
Brandon C Kelly. Some aspects of measurement error in linear regression of astronomical data.The Astrophysical Journal, 665(2):1489–1506, 2007
2007
-
[48]
Statistical adjustment of data
William Edwards Deming. Statistical adjustment of data. 1943
1943
-
[49]
Linear regression for astronomical data with measurement errors and intrinsic scatter.Astrophysical Journal, 470:706, 1996
Michael G Akritas and Matthew A Bershady. Linear regression for astronomical data with measurement errors and intrinsic scatter.Astrophysical Journal, 470:706, 1996
1996
-
[50]
Orthogonal distance regression.Contemporary Mathematics, 112:183–194, 1990
Paul T Boggs and Janet E Rogers. Orthogonal distance regression.Contemporary Mathematics, 112:183–194, 1990
1990
-
[51]
Simulation-extrapolation estimation in parametric measurement error models.Journal of the American Statistical Association, 89:1314–1328, 1994
John R Cook and Leonard A Stefanski. Simulation-extrapolation estimation in parametric measurement error models.Journal of the American Statistical Association, 89:1314–1328, 1994
1994
-
[52]
The aemulus project
Thomas McClintock, Eduardo Rozo, Matthew R Becker, Joseph DeRose, Yao-Yuan Mao, Sean McLaughlin, Jeremy L Tinker, Risa H Wechsler, and Zhongxu Zhai. The aemulus project. ii. emulating the halo mass function. The Astrophysical Journal, 872(1):53, 2019
2019
-
[53]
The mira-titan universe
Sebastian Bocquet, Katrin Heitmann, Salman Habib, Earl Lawrence, Thomas Uram, Nicholas Frontiere, Adrian Pope, and Hal Finkel. The mira-titan universe. iii. emulation of the halo mass function.The Astrophysical Journal, 901(1):5, 2020
2020
-
[54]
Locuss: scaling relations between galaxy cluster mass, gas, and stellar content.Monthly Notices of the Royal Astronomical Society, 484(1):60–80, 2019
Sarah L Mulroy, Arya Farahi, August E Evrard, Graham P Smith, Alexis Finoguenov, Christine O’Donnell, Daniel P Marrone, Zubair Abdulla, Hervé Bourdin, John E Carlstrom, et al. Locuss: scaling relations between galaxy cluster mass, gas, and stellar content.Monthly Notices of the Royal Astronomical Society, 484(1):60–80, 2019
2019
-
[55]
Detection of anti-correlation of hot and cold baryons in galaxy clusters.Nature Communications, 10(1):2504, 2019
Arya Farahi, Sarah L Mulroy, August E Evrard, Graham P Smith, Alexis Finoguenov, Hervé Bourdin, John E Carlstrom, Chris P Haines, Daniel P Marrone, Rossella Martino, et al. Detection of anti-correlation of hot and cold baryons in galaxy clusters.Nature Communications, 10(1):2504, 2019
2019
-
[56]
Optical selection bias and projection effects in stacked galaxy cluster weak lensing.Monthly Notices of the Royal Astronomical Society, 515(3):4471–4486, 2022
Hao-Yi Wu, Matteo Costanzi, Chun-Hao To, Andrés N Salcedo, David H Weinberg, James Annis, Sebastian Bocquet, Maria Elidaiana da Silva Pereira, Joseph DeRose, Johnny Esteves, et al. Optical selection bias and projection effects in stacked galaxy cluster weak lensing.Monthly Notices of the Royal Astronomical Society, 515(3):4471–4486, 2022
2022
-
[57]
Spt clusters with des and hst weak lensing
S Bocquet, S Grandis, LE Bleem, M Klein, JJ Mohr, M Aguena, A Alarcon, S Allam, SW Allen, O Alves, et al. Spt clusters with des and hst weak lensing. i. cluster lensing and bayesian population modeling of multiwavelength cluster datasets.Physical Review D, 110(8):083509, 2024
2024
-
[58]
Sebastian Grandis, Sebastian Bocquet, Joseph J Mohr, Matthias Klein, and Klaus Dolag. Calibration of bias and scatter involved in cluster mass measurements using optical weak gravitational lensing.Monthly Notices of the Royal Astronomical Society, 507(4):5671–5689, 2021
2021
-
[59]
sbi: A toolkit for simulation-based inference.The Journal of Open Source Software, 5(52), 2020
Alvaro Tejero-Cantero, Jan Boelts, Michael Deistler, Jan-Matthis Lueckmann, Conor Durkan, Pedro J Gonçalves, David S Greenberg, and Jakob H Macke. sbi: A toolkit for simulation-based inference.The Journal of Open Source Software, 5(52), 2020
2020
-
[60]
Ltu-ili: An all-in-one framework for implicit inference in astrophysics and cosmology.The Open Journal of Astrophysics, 7, 2024
Matthew Ho, Deaglan J Bartlett, Nicolas Chartier, Carolina Cuesta-Lazaro, Simon Ding, Axel Lapel, Pablo Lemos, Christopher C Lovell, T Lucas Makinen, Chirag Modi, et al. Ltu-ili: An all-in-one framework for implicit inference in astrophysics and cosmology.The Open Journal of Astrophysics, 7, 2024
2024
-
[61]
A unified bayesian framework for modeling measurement error in multinomial data.Bayesian Analysis, 21(1):453–483, 2026
Matthew D Koslovsky, Andee Kaplan, Victoria A Terranova, and Mevin B Hooten. A unified bayesian framework for modeling measurement error in multinomial data.Bayesian Analysis, 21(1):453–483, 2026
2026
-
[62]
Asymptotic statistics.Cambridge series in statistical and probabilistic mathematics, 1998
AW vd Vaart. Asymptotic statistics.Cambridge series in statistical and probabilistic mathematics, 1998. 12 OASIS: Observation-Aware Simulation-Based Inference via Distributional Matching
1998
-
[63]
Constraints on the Mass-Richness Relation from the Abundance and Weak Lensing of SDSS Clusters.The Astrophysical Journal, 854:120, February 2018
Ryoma Murata, Takahiro Nishimichi, Masahiro Takada, Hironao Miyatake, Masato Shirasaki, Surhud More, Ryuichi Takahashi, and Ken Osato. Constraints on the Mass-Richness Relation from the Abundance and Weak Lensing of SDSS Clusters.The Astrophysical Journal, 854:120, February 2018
2018
-
[64]
Myles, D
J. Myles, D. Gruen, A. B. Mantz, S. W. Allen, R. G. Morris, E. Rykoff, M. Costanzi, C. To, J. DeRose, R. H. Wechsler, E. Rozo, T. Jeltema, E. R. Carrasco, A. Kremin, and R. Kron. Spectroscopic Quantification of Projection Effects in the SDSS redMaPPer Galaxy Cluster Catalogue.Monthly Notices of the Royal Astronomical Society, 505(1):33–44, May 2021
2021
-
[65]
Myles, D
J. Myles, D. Gruen, T. Jeltema, A. Mantz, S. Allen, S. Fu, A. Kremin, J. Aguilar, S. Ahlen, D. Bianchi, D. Brooks, F. J. Castander, T. Claybaugh, A. de la Macorra, Arjun Dey, P. Doel, S. Ferraro, J. E. Forero-Romero, E. Gaztañaga, S. Gontcho A Gontcho, G. Gutierrez, K. Honscheid, M. Ishak, R. Kehoe, D. Kirkby, T. Kisner, O. Lahav, M. Landriau, L. Le Guill...
2080
-
[66]
Zhang, T
Y . Zhang, T. Jeltema, D. L. Hollowood, S. Everett, E. Rozo, A. Farahi, A. Bermeo, S. Bhargava, P. Giles, A. K. Romer, R. Wilkinson, E. S. Rykoff, A. Mantz, H. T. Diehl, A. E. Evrard, C. Stern, D. Gruen, A. von der Linden, M. Splettstoesser, X. Chen, M. Costanzi, S. Allen, C. Collins, M. Hilton, M. Klein, R. G. Mann, M. Manolopoulou, G. Morris, J. Mayers,...
2019
-
[67]
Kelly, J
P. Kelly, J. Jobel, O. Eiger, A. Abd, T. E. Jeltema, P. Giles, D. L. Hollowood, R. D. Wilkinson, D. J. Turner, S. Bhargava, S. Everett, A. Farahi, A. K. Romer, E. S. Rykoff, F. Wang, S. Bocquet, D. Cross, R. Faridjoo, J. Franco, G. Gardner, M. Kwiecien, D. Laubner, A. McDaniel, J. H. O’Donnell, L. Sanchez, E. Schmidt, S. Sripada, A. Swart, E. Upsdell, A. ...
2023
-
[68]
T. N. Varga, J. DeRose, D. Gruen, T. McClintock, S. Seitz, E. Rozo, M. Costanzi, B. Hoyle, N. MacCrann, A. A. Plazas, E. S. Rykoff, M. Simet, A. von der Linden, R. H. Wechsler, J. Annis, S. Avila, E. Bertin, D. Brooks, E. Buckley-Geer, D. L. Burke, A. Carnero Rosell, M. Carrasco Kind, J. Carretero, C. E. Cunha, C. B. D’Andrea, L. N. da Costa, J. De Vicent...
2019
-
[69]
J. S. Sanders, A. C. Fabian, H. R. Russell, and S. A. Walker. Hydrostatic Chandra X-ray analysis of SPT-selected galaxy clusters - I. Evolution of profiles and core properties.Monthly Notices of the Royal Astronomical Society, 474:1065–1098, February 2018
2018
-
[70]
Bulbul, A
E. Bulbul, A. Liu, M. Kluge, X. Zhang, J. S. Sanders, Y . E. Bahar, V . Ghirardini, E. Artis, R. Seppi, C. Garrel, M. E. Ramos-Ceja, J. Comparat, F. Balzer, K. Böckmann, M. Brüggen, N. Clerc, K. Dennerl, K. Dolag, M. Freyberg, S. Grandis, D. Gruen, F. Kleinebreil, S. Krippendorf, G. Lamer, A. Merloni, K. Migkas, K. Nandra, F. Pacaud, P. Predehl, T. H. Rei...
2024
-
[71]
The Mira-Titan Universe
Sebastian Bocquet, Katrin Heitmann, Salman Habib, Earl Lawrence, Thomas Uram, Nicholas Frontiere, Adrian Pope, and Hal Finkel. The Mira-Titan Universe. III. Emulation of the Halo Mass Function.The Astrophysical Journal, 901:5, September 2020. A Assumptions Here, we state all the regularity conditions used throughout this work. Assumption A.1(Parameter spa...
2020
-
[72]
+ (1−π)N(µ 2, s2 2),(114) with π= 0.55 , (µ1, µ2) = (−1.2,1.0) , and (s1, s2) = (0.95,0.95) . This induces a mildly multimodal and overlapping distribution, ensuring that the latent covariate distribution is non-Gaussian and cannot be captured by simple parametric assumptions. Conditional onx true i , the latent response is generated via a linear model, y...
-
[73]
the Poisson abundance term, which constrains the overall normalization of the halo population, and
-
[74]
the normalized observable distribution, which constrains the shape of the detected population in mass, redshift, and observable space. The NPE and NLE baselines considered in this work use hand-designed summary statistics that explicitly include cluster-count information, marginal histograms, and redshift-richness distributions. Consequently, these method...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.