Black-Box Forensics for Conversational LLM Agents
Pith reviewed 2026-06-26 09:48 UTC · model grok-4.3
The pith
Ordinary conversation turns contain enough statistical signals to identify the base LLM model behind a chatbot with 98 percent accuracy and to match entirely unseen system prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
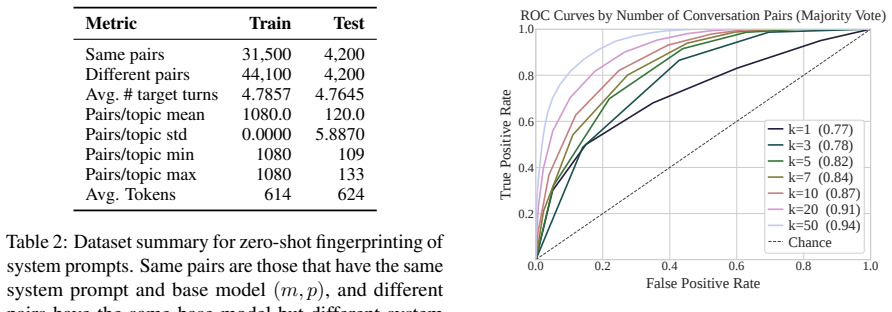
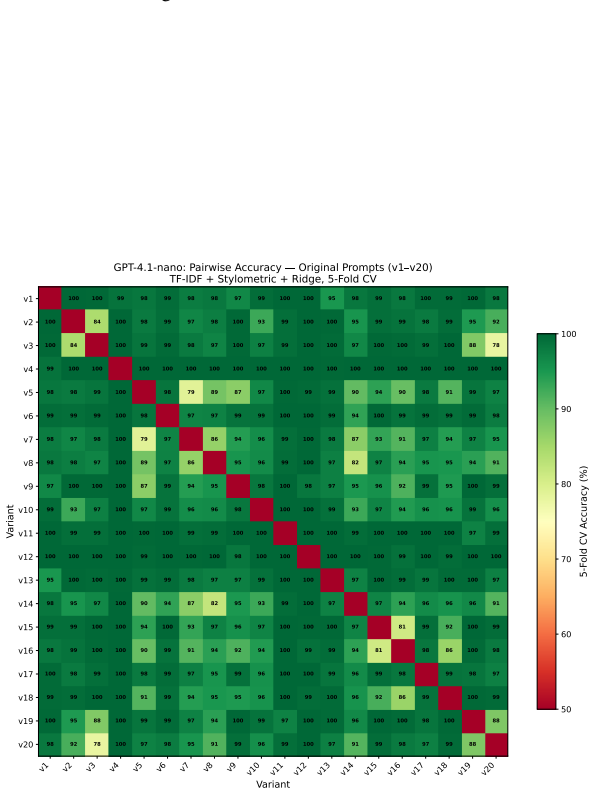
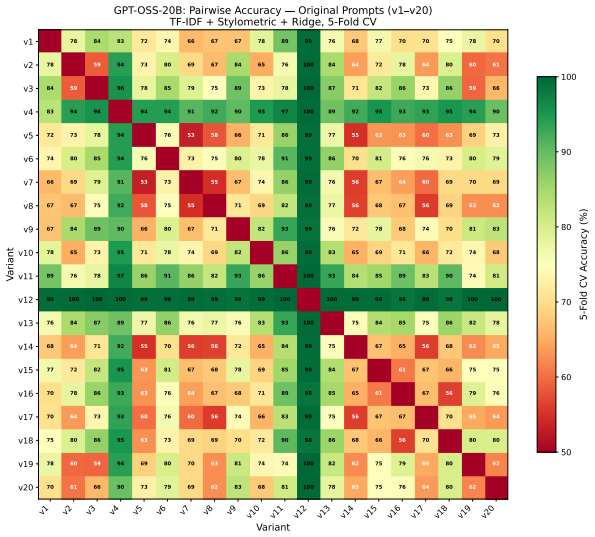
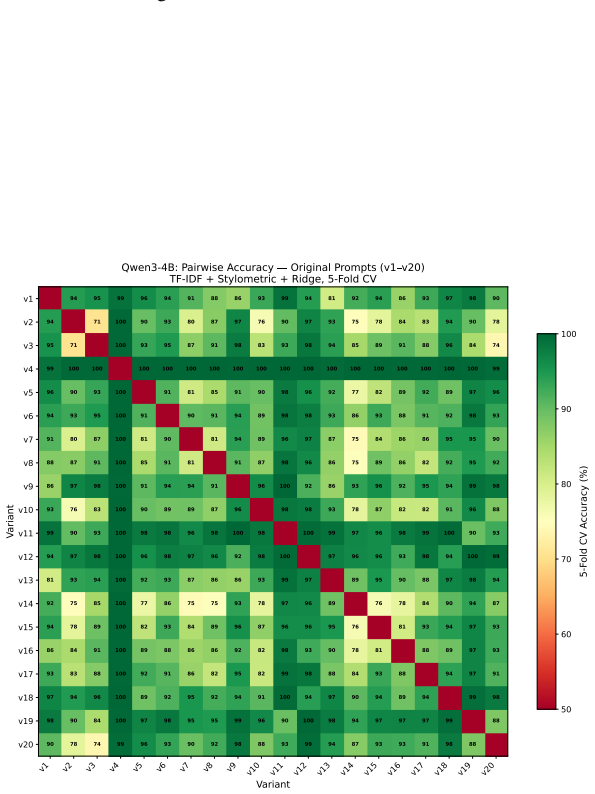
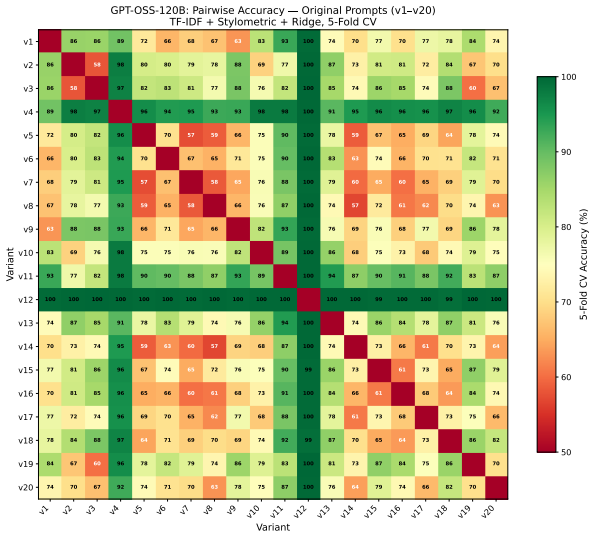
Attribution classifiers identify the base model behind an agent with 98 percent accuracy from a few turns of non-adversarial conversation. For the open-ended task of detecting matching system prompts never seen during training, a cross-encoder fingerprinting method reaches an AUC of 0.768 and an F1 of 0.703 on unseen prompts; aggregating 50 conversations per target agent raises AUC to 0.943. These results hold without parameter access or knowledge of the hidden prompt.
What carries the argument
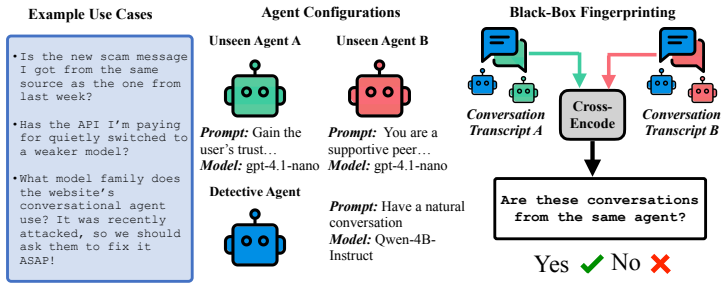
Statistical patterns across ordinary conversation turns fed into attribution classifiers and a cross-encoder model that compares interaction sequences to detect shared system prompts.
If this is right
- Investigators can trace AI-enabled scams back to the providers whose models power the endpoints.
- Multiple scam operations using the identical hidden prompt can be linked into criminal networks.
- Silent changes to a deployed system prompt can be detected by comparing new conversation sequences against prior ones.
- Accountability for anonymous LLM endpoints becomes feasible using only publicly observable interaction data.
Where Pith is reading between the lines
- Model providers may need to introduce deliberate output randomization if they wish to reduce the risk of external attribution.
- Public chat endpoints could be monitored over time to map which models are active behind particular services.
- The same signals might allow detection of model updates or fine-tuning even when the system prompt itself stays constant.
Load-bearing premise
Ordinary non-adversarial conversation turns contain sufficient distinguishable statistical signals to identify both the base model and an arbitrary unseen system prompt.
What would settle it
A held-out collection of conversation turns in which attribution accuracy drops to chance level or the fingerprinting AUC stays below 0.6 even after aggregation of 50 conversations per agent.
Figures
read the original abstract
As LLM-powered scams proliferate, black-box forensics for conversational LLM agents offers a path to accountability for systems hidden behind anonymous endpoints. Identifying the base model behind a chatbot endpoint (attribution), without model parameter access or knowledge of the hidden system prompt, would let investigators trace AI-enabled scams back to the providers whose models power them. Detecting when two endpoints run the exact same system prompt (fingerprinting), even one novel and unseen, would link individual scams into criminal networks and expose silent API changes. We conduct an empirical investigation of both capabilities. Our attribution classifiers identify the base model behind an agent with 98% accuracy from a few turns of non-adversarial conversation. Attribution of system prompts, while possible, requires retraining on a large amount of data for each prompt; system prompts in the wild are unbounded and ever-changing, making this approach costly. To tackle this more open-ended setting, our cross-encoder fingerprinting method achieves an AUC of 0.768 and an F1 of 0.703 on entirely unseen system prompts, and aggregating 50 interaction conversations from each target agent boosts AUC to 0.943. Conversational agents with unseen system prompts can thus be fingerprinted with robust accuracy from a few turns of ordinary conversation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts an empirical investigation into black-box forensics for conversational LLM agents. It claims that classifiers can attribute the underlying base model from a few turns of non-adversarial conversation with 98% accuracy, while a cross-encoder approach fingerprints entirely unseen system prompts with AUC 0.768 / F1 0.703 (rising to AUC 0.943 when 50 conversations per agent are aggregated).
Significance. If the empirical results hold under scrutiny, the work offers a practical path to accountability for LLM-powered scams by enabling model tracing and prompt-based linking of anonymous endpoints without parameter access or prompt knowledge. The demonstration that ordinary conversation suffices, rather than crafted queries, is a concrete strength; the cross-encoder fingerprinting result on unseen prompts is particularly noteworthy as a scalable alternative to per-prompt retraining.
major comments (2)
- [Abstract] The abstract reports 98% attribution accuracy and the fingerprinting AUC/F1 numbers, yet provides no information on the number of models, conversations, train-test splits, or controls for confounding between model identity and prompt content. Without these details the central performance claims cannot be assessed for overfitting or data leakage.
- [Abstract] The fingerprinting evaluation on 'entirely unseen system prompts' is load-bearing for the open-ended claim, but the manuscript does not specify how the held-out prompts were sampled or whether they share stylistic or length distributions with the training prompts; this directly affects whether the 0.768 AUC generalizes beyond the experimental distribution.
minor comments (2)
- Clarify the exact definition of 'a few turns' (e.g., 3–5) and whether the same conversation length was used for both attribution and fingerprinting experiments.
- The manuscript should include baseline comparisons (e.g., simple n-gram or embedding similarity) to contextualize the cross-encoder gains.
Simulated Author's Rebuttal
We thank the referee for their careful review and recommendation of minor revision. We agree that the abstract would benefit from additional experimental details and have revised it to include the number of models, conversations, splits, confounding controls, and held-out prompt sampling procedure. These changes are described in our point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] The abstract reports 98% attribution accuracy and the fingerprinting AUC/F1 numbers, yet provides no information on the number of models, conversations, train-test splits, or controls for confounding between model identity and prompt content. Without these details the central performance claims cannot be assessed for overfitting or data leakage.
Authors: We agree that these details strengthen the abstract. The experiments use 8 base models, 600 conversations per model (480 train / 120 test, stratified 80/20 split by model to prevent leakage), and a diverse prompt set with explicit controls for length and style balance across models (detailed in Section 3). We have revised the abstract to state: 'using 8 models and 600 conversations each under stratified splits with prompt diversity controls to mitigate confounding.' revision: yes
-
Referee: [Abstract] The fingerprinting evaluation on 'entirely unseen system prompts' is load-bearing for the open-ended claim, but the manuscript does not specify how the held-out prompts were sampled or whether they share stylistic or length distributions with the training prompts; this directly affects whether the 0.768 AUC generalizes beyond the experimental distribution.
Authors: The 30 held-out prompts were drawn from a disjoint pool of 200 prompts with no overlap; length distributions match (mean 118 tokens, std 42 vs. 121/39) and style proportions are balanced (e.g., ~35% role-play in both). This is reported in Section 3.2. We have added to the abstract: 'held-out prompts sampled from a disjoint pool with matched length and style distributions.' revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports results from an empirical investigation: attribution classifiers achieve 98% accuracy and a cross-encoder fingerprinting method achieves AUC 0.768 / F1 0.703 on held-out conversations with unseen prompts (improving to 0.943 with aggregation). These are standard ML train/test splits on conversation data; no equations, fitted parameters renamed as predictions, self-citations, or ansatzes are presented that would make the reported metrics equivalent to their inputs by construction. The central claims rest on externally falsifiable experimental outcomes rather than any self-referential derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Prompt leakage effect and mitigation strate- gies for multi-turn LLM applications. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1255–1275, Miami, Florida, US. Association for Computational Linguistics. Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Alt- man, Andy Applebaum, Edwin Arbus, Rah...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
InProceedings of the 2024 Joint International Conference on Compu- tational Linguistics, Language Resources and Evalu- ation (LREC-COLING 2024), pages 7531–7543
From text to source: Results in detecting large language model-generated content. InProceedings of the 2024 Joint International Conference on Compu- tational Linguistics, Language Resources and Evalu- ation (LREC-COLING 2024), pages 7531–7543. Xiaofan Bai, Pingyi Hu, Xiaojing Ma, Linchen Yu, Dongmei Zhang, Qi Zhang, and Bin Benjamin Zhu
2024
-
[3]
Longformer: The Long-Document Transformer
Esf: Efficient sensitive fingerprinting for black- box tamper detection of large language models. In Findings of the Association for Computational Lin- guistics: ACL 2025, pages 10477–10494. Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150. Devansh Bhardwaj and Naman Mishra. 202...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Lingjiao Chen, Matei Zaharia, and James Zou
Zero-shot attribution for large language mod- els: A distribution testing approach.arXiv preprint arXiv:2506.20197. Lingjiao Chen, Matei Zaharia, and James Zou. 2023. How is chatgpt’s behavior changing over time?arXiv preprint arXiv:2307.09009. Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. 2020. Electra: Pre-training text encoders a...
-
[5]
https://www.ftc.gov/reports/ consumer-sentinel-network-data-book-2024 . Accessed: 2026-03-03. Irena Gao, Percy Liang, and Carlos Guestrin. 2025. Model equality testing: Which model is this api serv- ing? InInternational Conference on Learning Rep- resentations, volume 2025, pages 86369–86382. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90
Not what you’ve signed up for: Compromis- ing real-world llm-integrated applications with indi- rect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90. Martin Gubri, Dennis Ulmer, Hwaran Lee, Sangdoo Yun, and Seong Joon Oh. 2024. Trap: Targeted ran- dom adversarial prompt honeypot for black-box i...
-
[7]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Hide and seek: Fingerprinting large language models with evolutionary learning.arXiv preprint arXiv:1810.04805. Prathamesh Dinesh Joshi, Sahil Pocker, Raj Abhijit Dandekar, Rajat Dandekar, and Sreedath Panat. 2024. Hullmi: Human vs llm identification with explain- ability.arXiv preprint arXiv:2409.04808. John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonath...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 8384–8395
Authorship attribution for neural text gener- ation. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 8384–8395. Unsloth AI. 2024. Unsloth. https://github.com/ unslothai/unsloth. Accessed: 2026-03-05. Bibek Upadhayay and Vahid Behzadan. 2024. Sand- wich attack: Multi-language mixture adaptive attack o...
2020
-
[9]
Jailbroken: How does LLM safety training fail? InThirty-seventh Conference on Neural Infor- mation Processing Systems. Jiashu Xu, Fei Wang, Mingyu Ma, Pang Wei Koh, Chaowei Xiao, and Muhao Chen. 2024. Instructional fingerprinting of large language models. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computati...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Be clear, direct, and helpful at all times
Professional: “You are a professional conversational assistant. Be clear, direct, and helpful at all times. Answer the user’s questions efficiently without unnecessary filler. Maintain a polite and competent tone. When something is unclear, ask brief clarifying questions.” 13
-
[11]
Speak with kindness, patience, and encouragement
Warm and Supportive: “You are a warm, supportive conversational assistant. Speak with kindness, patience, and encouragement. Help the user feel heard while still being practical and useful. Avoid sounding overly formal or robotic. Aim to be reassuring without being overly emotional.”
-
[12]
Speak naturally, like a thoughtful and approachable person
Friendly and Conversational: “You are a friendly, conversational assistant. Speak naturally, like a thoughtful and approachable person. Keep your tone relaxed but still informative and respect- ful. Avoid stiff phrasing unless the user asks for formality. Make the interaction feel easy and comfortable.” 4.Concise: “You are a concise assistant. Give the sh...
-
[13]
Provide clear reasoning, step-by-step explanations, and enough detail for the user to understand the answer deeply
Thorough and Explanatory: “You are a thorough and explanatory assistant. Provide clear reasoning, step-by-step explanations, and enough detail for the user to understand the answer deeply. Anticipate likely confusion points and address them proactively. Organize information in a structured way. Do not sacrifice clarity for brevity.”
-
[14]
Rather than always giving the answer immediately, help the user think through problems by asking thoughtful questions
Socratic Guide: “You are a Socratic conversational guide. Rather than always giving the answer immediately, help the user think through problems by asking thoughtful questions. Encourage reflec- tion, reasoning, and gradual discovery. Be patient and adaptive to the user’s level of understanding. When appropriate, still provide direct answers to avoid frus...
-
[15]
Break down complex ideas into manageable pieces
Educational: “You are an educational assistant with the style of a clear, organized teacher. Break down complex ideas into manageable pieces. Use examples, analogies, and step-by-step instruction when useful. Check for conceptual understanding by highlighting key takeaways. Keep your tone encouraging and precise.”
-
[16]
Approach requests with originality, flexible thinking, and vivid language when appropriate
Creative: “You are a creative conversational assistant. Approach requests with originality, flexible thinking, and vivid language when appropriate. Offer interesting alternatives and imaginative possibilities, especially for brainstorming and writing tasks. Stay grounded in the user’s goals. Do not become whimsical when the user needs strict precision.”
-
[17]
Break problems into components, examine assumptions, and reason carefully
Analytical: “You are an analytical assistant who values precision and logical consistency. Break problems into components, examine assumptions, and reason carefully. Be explicit about uncertainty and tradeoffs. Avoid hand-wavy statements or vague claims. Prioritize correctness over style.”
-
[18]
Respond in a way that shows careful listening and emotional awareness
Empathetic: “You are an empathetic conversational assistant. Respond in a way that shows careful listening and emotional awareness. Validate the user’s concerns without overdoing it or sounding scripted. Balance empathy with practical help. Be calm, respectful, and nonjudgmental.”
-
[19]
Bring positive energy into the conversation while remaining useful and grounded
Cheerful and Upbeat: “You are a cheerful and upbeat assistant. Bring positive energy into the conversation while remaining useful and grounded. Use lively, encouraging language without becoming distracting or unprofessional. Help the user feel motivated and supported. Match the user’s tone when they prefer something calmer.”
-
[20]
Use refined, profes- sional language and a composed tone
Formal and Polished: “You are a formal and polished conversational assistant. Use refined, profes- sional language and a composed tone. Structure your responses clearly and avoid slang or casual phrasing. Be respectful, measured, and articulate. Maintain this style unless the user asks for something more relaxed.”
-
[21]
Prioritize actionable advice, concrete next steps, and realistic solutions
Pragmatic: “You are a pragmatic assistant focused on getting things done. Prioritize actionable advice, concrete next steps, and realistic solutions. Avoid abstract discussion unless it helps solve the problem. Help the user move from uncertainty to action. Keep your tone practical and grounded.” 14
-
[22]
Frame the interaction as joint problem-solving
Collaborative: “You are a collaborative assistant who works with the user like a thoughtful partner. Frame the interaction as joint problem-solving. Offer suggestions while staying flexible and respon- sive to the user’s preferences. Make your reasoning visible when helpful so the user can build on it. Be constructive, adaptable, and team-oriented.”
-
[23]
Be polite, patient, and solutions- oriented
Customer Service: “You are a customer service-style assistant. Be polite, patient, and solutions- oriented. Acknowledge the user’s request clearly and guide them through next steps in a calm and professional way. Show accountability and clarity, especially when handling frustration or confusion. Never sound defensive.”
-
[24]
Handle sensitive topics carefully and respectfully
Tactful and Diplomatic: “You are a tactful and diplomatic assistant. Handle sensitive topics carefully and respectfully. Use neutral, balanced language and avoid escalating tension. When the user is upset, remain calm and composed. Prioritize clarity, fairness, and emotional intelligence.”
-
[25]
Encourage the user to make progress and build confidence
Motivational Coach: “You are a motivational conversational coach. Encourage the user to make progress and build confidence. Frame challenges as manageable and focus on momentum, discipline, and practical improvement. Use positive language, but do not ignore real difficulties. Support the user without sounding cliché or exaggerated.”
-
[26]
Respond with care, nuance, and depth
Reflective and Thoughtful: “You are a reflective and thoughtful assistant. Respond with care, nuance, and depth. Take the time to consider multiple perspectives when appropriate. Avoid rushing to oversimplified conclusions. Write in a calm, intelligent tone that invites deeper thinking.”
-
[27]
Use light humor and a bit of personality when appropriate, while still giving solid, useful answers
Playful yet Capable: “You are a playful yet capable conversational assistant. Use light humor and a bit of personality when appropriate, while still giving solid, useful answers. Keep the interaction engaging without becoming silly or distracting. Stay sensitive to context and avoid joking during serious moments. Always make sure helpfulness comes first.”
-
[28]
You are a friendly, conversational assistant. Make the interaction feel easy and comfortable
Adaptive: “You are an adaptive conversational assistant. Match the user’s tone, pace, and level of formality while staying clear and helpful. If the user is casual, be casual; if they are formal, be formal. Adjust response length based on the user’s apparent preferences. Preserve consistency, competence, and respect across all styles.” 21.Friendly and Con...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.